- 上海交大、北航、小红书提出 Vript:一段视频胜过千言万语
- 阿里达摩院推出视频大语言模型 VideoLLaMA 2
- Google DeepMind 新研究:当 Transformer 遇见神经算法推理器
- 清华团队推出 DiTFastAttn:解决 DiT 推理三大难题
- 斯坦福团队推出开源视觉-语言-动作模型 OpenVLA
- 港大、TikTok 推出 Depth Anything V2
- PowerInfer-2:智能手机上的快速大语言模型推理
- 英伟达推出 HelpSteer2:用于训练更好奖励模型的开源数据集
- 微软新研究:用于高效无限上下文语言建模的简单混合状态空间模型
- MMWorld:多学科、多方面、多模态视频理解新基准
- 斯坦福团队推出 TextGrad:通过文本自动“区分”
- 微软研究院推出 MedFuzz:探索医学问题解答中大语言模型的鲁棒性
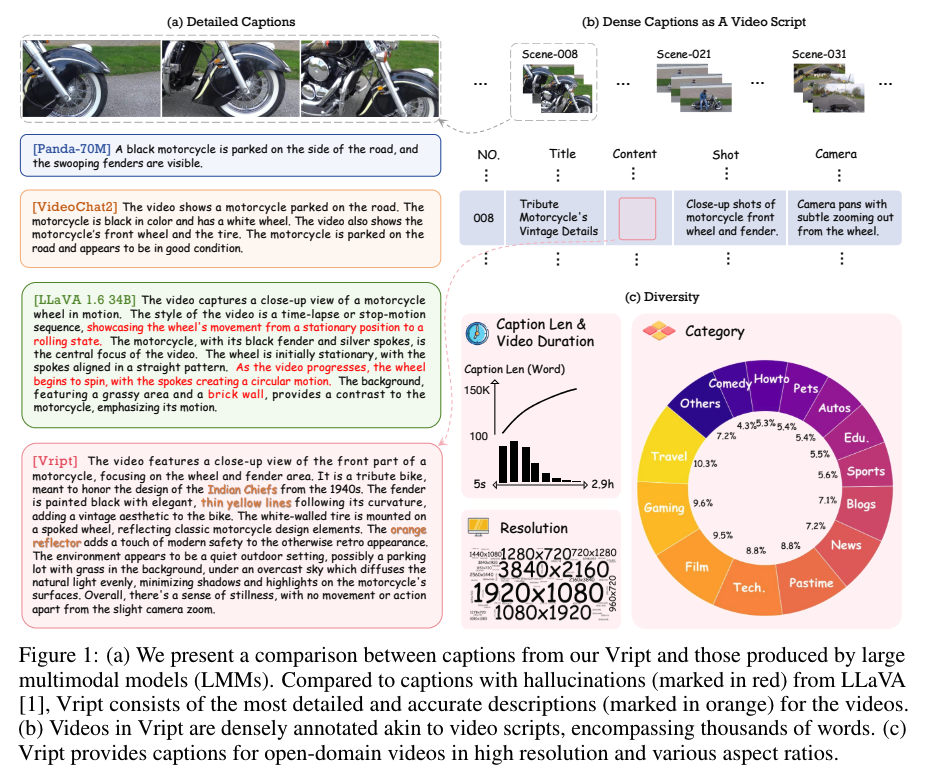
1.上海交大、北航、小红书提出 Vript:一段视频胜过千言万语多模态学习,尤其是视频理解和生成方面的进步,需要高质量的视频文本数据集来提高模型性能。由上海交通大学、北京航空航天大学和小红书研究团队提出的 Vript 通过精心标注的 12000 高分辨率视频语料库解决了这一问题,为超过 42 万个片段提供了详细、密集、类似脚本的字幕。每个片段的字幕约有 145 个单词,比大多数视频文本数据集长 10 倍以上。与以往数据集中仅记录静态内容的字幕不同,他们将视频字幕增强为视频脚本,不仅记录内容,还记录相机的操作,包括 shot 类型(中景、特写等)和相机运动(平移、倾斜等)。通过使用 Vript,他们探索了三种训练范式,使更多文本与视频模态对齐,而不是片段-字幕对齐。这使得 Vriptor 成为开源模型中的 SOTA 视频字幕模型,其性能可与 GPT-4V 相媲美。Vriptor 也是一个功能强大的模型,能够为长视频端到端生成密集而详细的字幕。此外,他们还提出了 Vript-Hard,这是一个由三个视频理解任务组成的基准,比现有基准更具挑战性:Vript-HAL 是首个评估视频 LLM 中的动作和物体幻觉的基准;Vript-RR 将推理与检索相结合,解决了长视频 QA 中的问题模糊性;Vript-ERO 是一项新任务,用于评估对长视频中事件的时间理解,而非之前工作中对短视频中动作的理解。
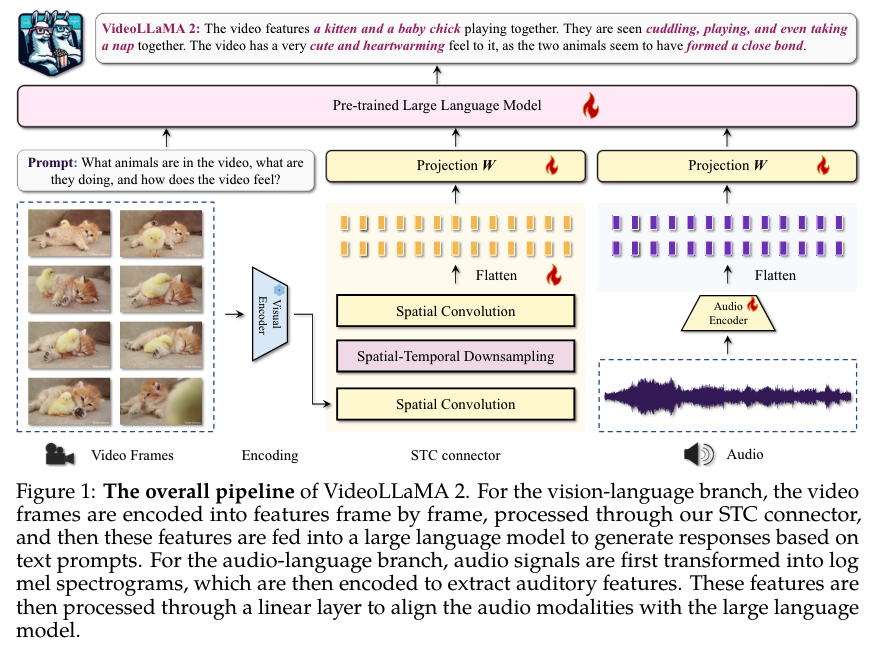
https://arxiv.org/abs/2406.06040https://github.com/mutonix/Vript2.阿里达摩院推出视频大语言模型 VideoLLaMA 2在这项工作中,阿里达摩院团队提出了一套视频大语言模型——VideoLLaMA 2,旨在增强面向视频和音频任务的时空建模和音频理解能力。在其前身的基础上,VideoLLaMA 2 采用了量身定制的时空卷积(STC)连接器,可有效捕捉视频数据错综复杂的时空动态。此外,他们还通过联合训练将音频分支集成到模型中,从而通过无缝集成音频线索来丰富模型的多模态理解能力。在多选视频问题解答(MC-VQA)、开放式视频问题解答(OE-VQA)和视频字幕(VC)任务上进行的综合评估表明,VideoLLaMA 2 在开源模型中始终取得具有竞争力的结果,甚至在几个基准测试中接近某些专有模型。此外,与现有模型相比,VideoLLaMA 2 在纯音频和音频视频问题解答(AQA 和 OE-AVQA)基准测试中表现出合理的改进。
https://arxiv.org/abs/2406.07476https://github.com/DAMO-NLP-SG/VideoLLaMA2
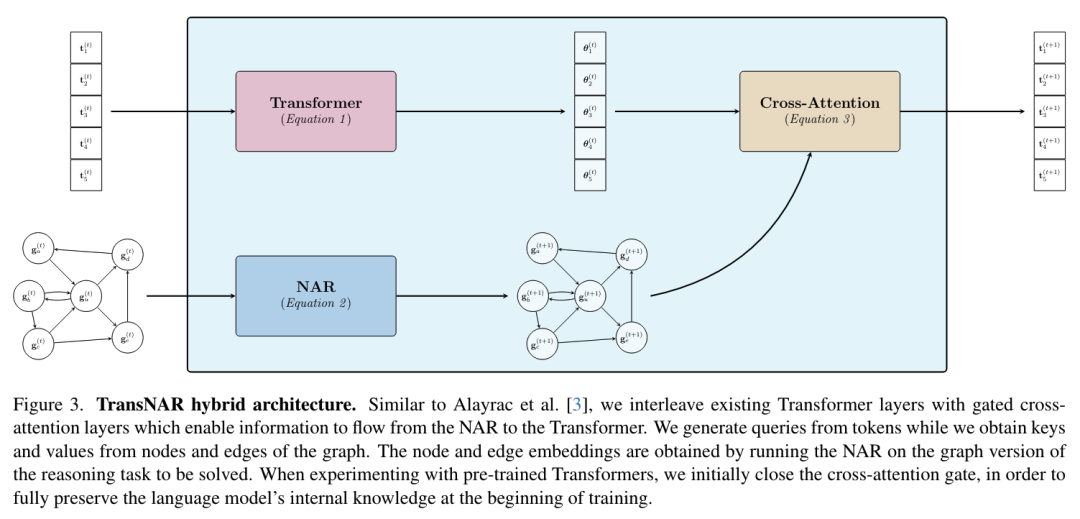
3.Google DeepMind 新研究:当 Transformer 遇见神经算法推理器Transformer 以其简单而有效的架构彻底改变了机器学习。在互联网的海量文本数据集上预先训练 Transformer,为自然语言理解(NLU)任务带来了强大的泛化能力。然而,在执行算法形式的推理任务时,这种语言模型仍然很脆弱,计算必须精确且鲁棒。为了解决这一局限性,来自 Google DeepMind 的研究团队提出了一种新方法,将 Transformer 的语言理解能力与基于图神经网络(GNN)的神经算法推理器(NARs)的鲁棒性结合起来。事实证明,当以图谱的形式指定时,这种 NARs 可以有效地作为算法任务的通用求解器。为了让 Transformer 可以访问它们的嵌入,他们提出了一种具有两阶段训练程序的混合架构,允许语言模型中的 token 与 NAR 中的节点嵌入交叉关注。他们在 CLRS-Text 模型(CLRS-30 基准的文本版本)上评估了产生的 TransNAR 模型,结果表明,在算法推理方面,无论是在发布中还是发布外,这一模型都比纯 Transformer 模型有显著提高。
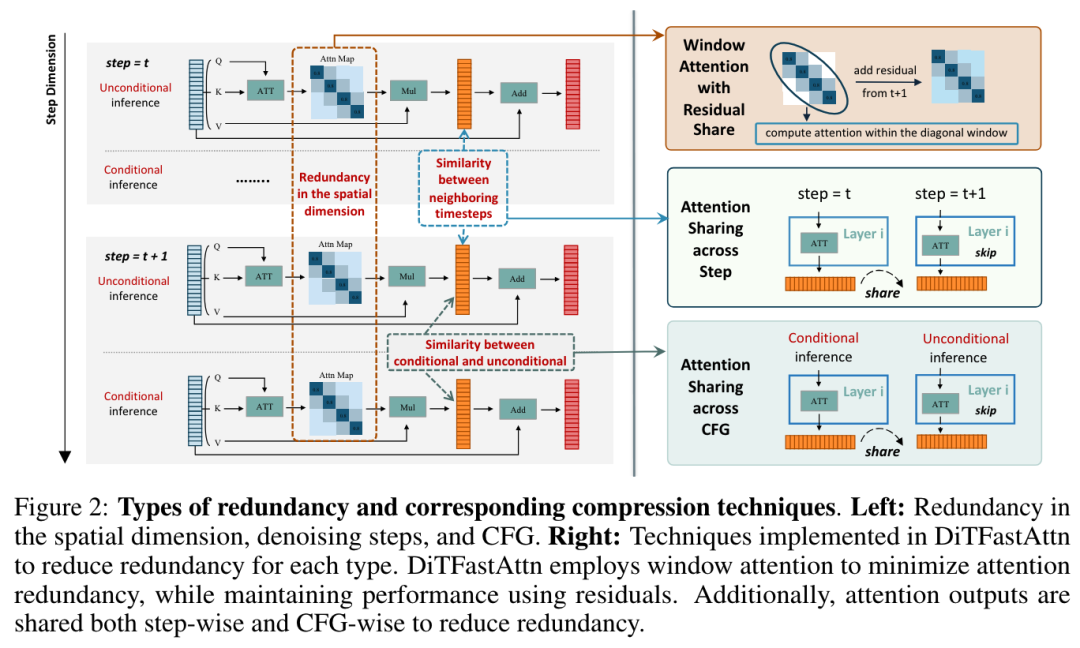
https://arxiv.org/abs/2406.093084.清华团队推出 DiTFastAttn:解决 DiT 推理三大难题扩散 Transformer(DiT)在图像和视频生成方面表现出色,但由于自注意力的二次方复杂性而面临计算挑战。为此,来自清华大学、Infinigence AI、卡内基梅隆大学、上海交通大学的研究团队提出了一种新型后训练压缩方法——DiTFastAttn。他们确定了 DiT 推理过程中注意力计算的三个关键冗余:1)空间冗余,即许多注意力集中在局部信息上;2)时间冗余,即相邻步骤的注意力输出之间具有高度相似性;3)条件冗余,即有条件推论和无条件推论表现出明显的相似性。为了解决这些冗余问题,他们提出了三种技术:1)利用残余缓存的窗口关注来减少空间冗余;2)利用步骤间的相似性实现时间相似性还原;3. 条件冗余消除,在条件生成过程中跳过冗余计算。为了证明 DiTFastAttn 的有效性,他们将其应用于 DiT、PixArt-Sigma(图像生成任务)和 OpenSora(视频生成任务)。评估结果表明,对于图像生成,这一方法最多可减少 88% 的 FLOPs,并在高分辨率生成时实现高达 1.6 倍的速度提升。https://arxiv.org/abs/2406.085525.斯坦福团队推出开源视觉-语言-动作模型 OpenVLA结合互联网规模的视觉语言数据和各种机器人演示进行预训练的大型策略,有可能改变我们教授机器人新技能的方式:我们可以微调这种视觉-语言-动作(VLA)模型,从而获得鲁棒、通用的视觉运动控制策略,而不是从头开始训练新的行为。然而,将视觉-语言-动作模型广泛应用于机器人技术一直是个挑战,因为:1)现有的视觉-语言-动作模型大多是封闭的,公众无法访问;2)先前的工作未能探索针对新任务有效微调视觉-语言-动作模型的方法,而微调是采用视觉-语言-动作模型的关键要素。为了应对这些挑战,来自斯坦福的研究团队及其合作者推出了一个具有 7B 参数的开源 VLA——OpenVLA,其在 97 万真实世界机器人演示的不同集合上进行了训练。OpenVLA 基于 Llama 2 语言模型和视觉编码器,后者融合了 DINOv2 和 SigLIP 的预训练特征。作为新增数据多样性和新模型组件的产物,OpenVLA 在通用操作方面取得了优异成绩,在 29 个任务和多个机器人示例中,OpenVLA 的绝对任务成功率比 RT-2-X(55B)等封闭模型高出 16.5%,而参数却减少到 1/7。他们还进一步证明,可以针对新的环境对 OpenVLA 进行有效的微调,在涉及多个对象和强大语言基础能力的多任务环境中,OpenVLA 的泛化效果很好,比 Diffusion Policy 等从头开始模仿学习方法高出 20.4%。他们还探索了计算效率;他们展示了 OpenVLA 可以通过低阶适应方法在消费级 GPU 上进行微调,并通过量化高效地提供服务,而不会影响下游成功率。最后,他们发布了模型检查点、微调笔记本,以及 PyTorch 代码库,该代码库内置支持在 Open X-Embodiment 数据集上大规模训练 VLA。
https://arxiv.org/abs/2406.09246https://openvla.github.io/
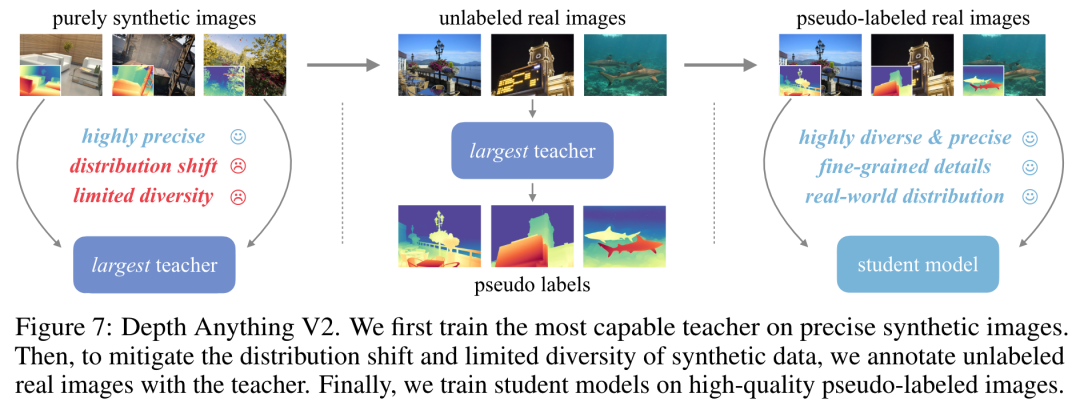
6.港大、TikTok 推出 Depth Anything V2在这项工作中,来自香港大学和 TikTok 的研究团队提出了 Depth Anything V2。与 V1 相比,V2 通过三个关键实践,产生了更精细、更鲁棒的深度预测:1)用合成图像替换所有标注的真实图像;2)扩大教师模型的容量;3)通过大规模伪标注真实图像的桥梁教授学生模型。与建立在 Stable Diffusion 基础上的模型相比,Depth Anything V2 明显更高效(快 10 倍以上)、更准确。为支持广泛的应用场景,他们提供了不同规模的模型(从 2500 万到 1300 亿参数不等)。得益于其强大的泛化能力,他们利用度量深度标签对其进行了微调,从而获得了度量深度模型。此外,考虑到当前测试集的有限多样性和频繁出现的噪声,他们还构建了一个具有精确注释和多样化场景的多功能评估基准,从而促进未来的研究。
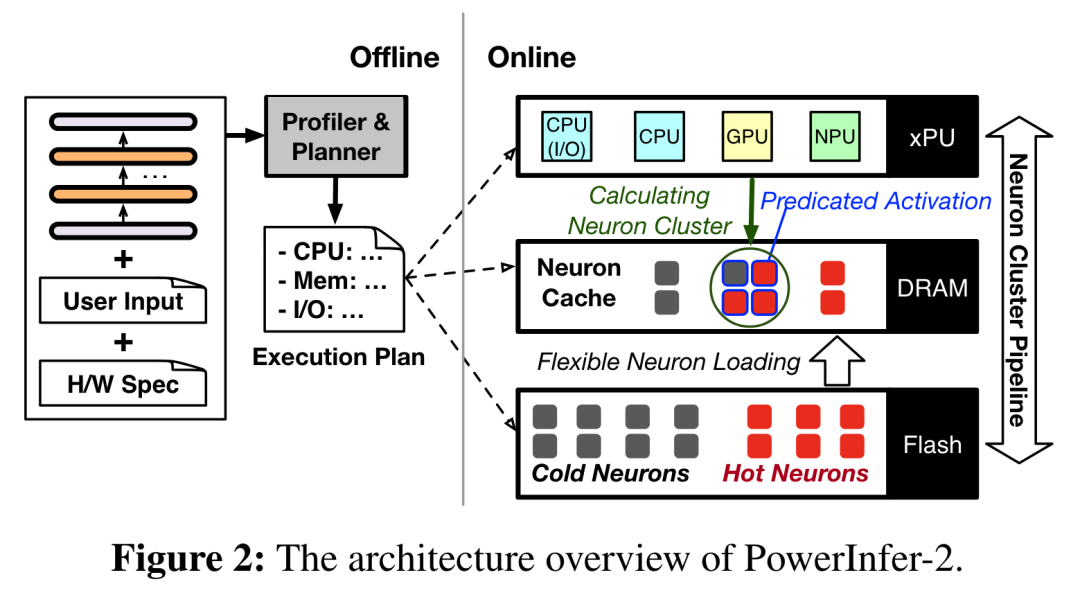
https://arxiv.org/abs/2406.094147.PowerInfer-2:智能手机上的快速大语言模型推理上海交通大学团队提出了一个专为在智能手机上高速推断大语言模型(LLM)而设计的框架——PowerInfer-2,该框架尤其适用于规模超过设备内存容量的模型。PowerInfer-2 的关键之处在于将传统的矩阵计算分解为细粒度神经元集群计算,从而利用智能手机中的异构计算、内存和 I/O 资源。具体来说,PowerInfer-2 采用多态神经元引擎,可针对 LLM 推断的各个阶段调整计算策略。此外,它还引入了分段神经元缓存和细粒度神经元集群级流水线,有效地减少和隐藏了 I/O 操作造成的开销。PowerInfer-2 的实现和评估证明,它有能力在两款智能手机上支持多种 LLM 模型,与 SOTA 框架相比,速度最多提高了 29.2 倍。值得注意的是,PowerInfer-2 是首个在智能手机上以 11.68 token/s 的生成速度为 TurboSparse-Mixtral-47B 模型提供服务的系统。对于完全适合内存的模型,PowerInfer-2 可以减少约 40% 的内存使用量,同时保持与 llama.cpp 和 MLC-LLM 相当的推理速度。
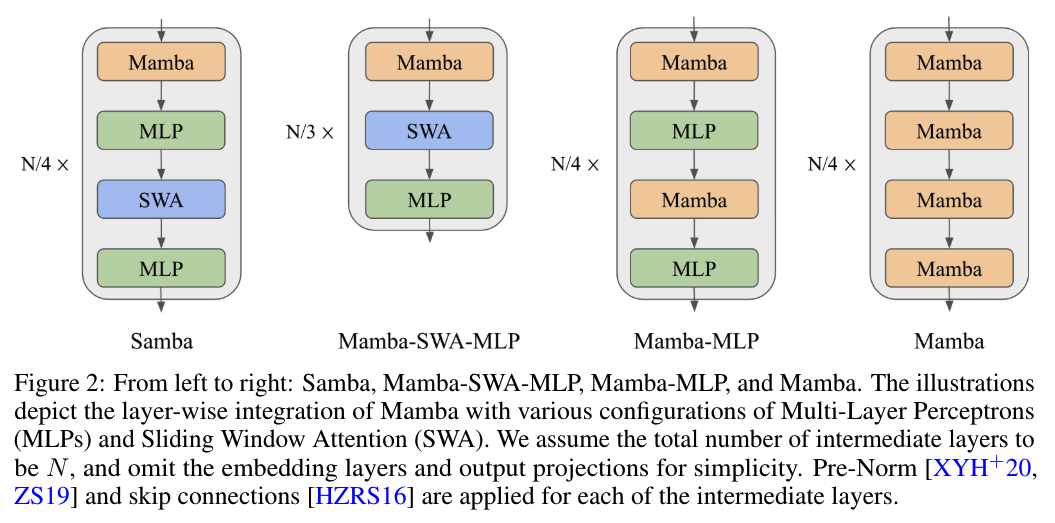
https://arxiv.org/abs/2406.06282http://www.powerinfer.ai/v28.英伟达推出 HelpSteer2:用于训练更好奖励模型的开源数据集高质量的偏好数据集对于训练奖励模型至关重要,这些模型可以有效地指导大语言模型(LLM)生成与人类偏好一致的高质量响应。随着 LLM 变得更强大、更符合人类偏好,Open Assistant、HH-RLHF 和 HelpSteer 等许可偏好数据集也需要更新,从而保持对奖励建模的有效性。从 GPT-4 等专有 LLM 中提炼偏好数据的方法受到模型提供者对商业使用的限制。为了提高生成的响应和属性标签质量,来自英伟达的研究团队推出了 HelpSteer2,这是一个获得许可的偏好数据集(CC-BY-4.0)。利用在 HelpSteer2 上训练的强大内部基础模型,他们能够在 Reward-Bench 的主要数据集上获得 SOTA 分数(92.0%),超过目前列出的开放和专有模型(截至 2024 年 6 月 12 日)。值得注意的是,HelpSteer2 只包含一万个响应对,比现有的偏好数据集(如 HH-RLHF)低一个数量级,这使得它在训练奖励模型时非常高效。大量实验证明,使用 HelpSteer2 训练的奖励模型可以有效地对齐 LLM。他们特别提出了 SteerLM 2.0,这是一种能有效利用奖励模型预测的丰富多属性得分的模型对齐方法。https://arxiv.org/abs/2406.08673https://github.com/NVIDIA/NeMo-Aligner9.微软新研究:用于高效无限上下文语言建模的简单混合状态空间模型如何高效地为具有无限上下文长度的序列建模是一个长期存在的问题。过去的工作要么存在二次计算复杂性问题,要么在长度泛化方面的外推能力有限。在这项工作中,来自微软的研究团队提出了一种简单的混合架构 Samba,它分层结合了选择性状态空间模型(SSM)Mamba 和滑动窗口注意力(SWA)。Samba 可选择性地将给定序列压缩为递归隐藏状态,同时仍能保持利用注意力机制精确调用记忆的能力。他们用 3.2T 个训练 token 将 Samba 扩展到 3.8B 个参数,结果表明,在各种基准测试中,Samba 都优于基于纯注意力或 SSM 的 SOTA 模型。在 4K 长度的序列上进行训练时,Samba 可以有效地推断出 256K 上下文长度,并具有完美的记忆召回能力,同时在高达 100 万上下文长度的情况下,Samba 的 token 预测能力也有所提高。作为一种线性时间序列模型,在处理 128K 长度的用户提示时,Samba 的吞吐量比使用分组查询注意力的 Transformer 高出 3.73 倍;在以无限流生成 64K token 时,Samba 的速度提高了 3.64 倍。
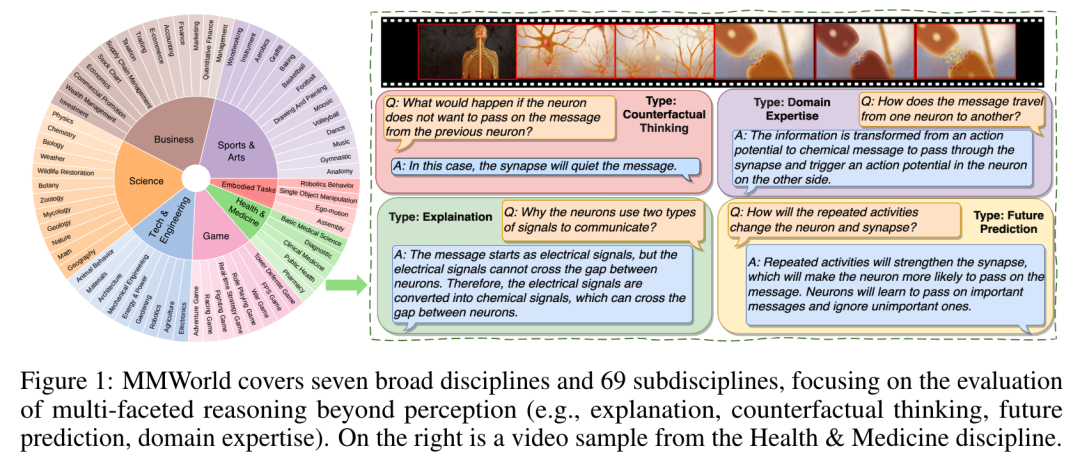
https://arxiv.org/abs/2406.07522https://github.com/microsoft/Samba10.MMWorld:多学科、多方面、多模态视频理解新基准多模态语言模型(MLLM)展示了“世界模型”的新兴能力——对复杂的现实世界动态进行解释和推理。为了评估这些能力,来自加州大学、微软的研究团队认为,视频是理想的媒介,因为视频包含了真实世界动态和因果关系的丰富表征。为此,他们推出了一个多学科、多方面、多模态视频理解的新基准——MMWorld。MMWorld 有别于以往的视频理解基准,它有两个独特的优势:1)多学科,涵盖各种学科,而这些学科往往需要领域专业知识才能全面理解;2)多方面推理,包括解释、反事实思维、未来预测等。MMWorld 由一个人类标注的数据集和一个合成数据集组成,前者用于评估带有整个视频问题的 MLLM,后者用于分析单一感知模态下的 MLLM。MMWorld 共包含 1910 个视频,横跨 7 大学科和 69 个子学科,并配有 6627 个问题-答案对和相关说明。评估包括 2 个专有和 10 个开源 MLLM,这些 MLLM 在 MMWorld 上表现不佳(尽管 GPT-4V 表现最好,但准确率仅为 52.3%),显示出很大的改进空间。进一步的消融研究揭示了其他有趣的发现,比如模型与人类不同的技能组合。
https://arxiv.org/abs/2406.0840711.斯坦福团队推出 TextGrad:通过文本自动“区分”人工智能正在经历范式转变,由多个大语言模型(LLM)和其他复杂组件组成的系统正在实现突破。因此,为复合人工智能系统开发有原则的自动优化方法是最重要的新挑战之一。神经网络在早期也曾面临过类似的挑战,直到反向传播和自动分化技术的出现,才使优化工作变得简单易行,从而改变了这一领域。受此启发,来自斯坦福的研究团队推出了 TextGrad,一个通过文本进行自动“区分”的强大框架。TextGrad 通过反向传播 LLM 提供的文本反馈来改进复合人工智能系统的各个组件。在该框架中,LLMs 提供丰富、通用的自然语言建议,从而优化计算图谱中的变量,范围从代码片段到分子结构。TextGrad 遵循 PyTorch 的语法和抽象,灵活易用。用户只需提供目标函数,无需调整框架的组件或提示,它就能立即执行各种任务。他们在从问题解答、分子优化到放射治疗规划等各种应用中展示了 TextGrad 的有效性和通用性。在不修改框架的情况下,TextGrad 将 Google-Proof Question Answering 中 GPT-4o 的零样本准确率从 51% 提高到了 55%,在优化 LeetCode-Hard 编码问题解决方案时获得了 20% 的相对性能提升,改进了推理提示,设计出了具有理想硅学结合力的新药样小分子,并设计出了具有高特异性的肿瘤放射治疗计划。
https://arxiv.org/abs/2406.0749612.微软研究院推出 MedFuzz:探索医学问题解答中大语言模型的鲁棒性大语言模型(LLM)在医学问题解答基准测试中取得了令人瞩目的成绩。然而,高基准准确率并不意味着其性能可以推广到真实世界的临床环境中。医疗问题解答基准依赖于与量化 LLM 性能一致的假设,但这些假设在开放的临床环境中可能并不成立。然而,LLM 可以学习到广泛的知识,这些知识可以帮助 LLM 在实际条件下进行推广,而无需考虑基准中不切实际的假设。来自微软研究院的研究团队及其合作者试图量化 LLM 医学问题解答基准性能在违反基准假设时的泛化程度。具体来说,他们提出了一种对抗方法——MedFuzz。MedFuzz 尝试以混淆 LLM 的方式修改基准问题。他们通过针对 MedQA 基准中提出的患者特征的强假设来演示这种方法。成功的“攻击”会以不太可能欺骗医学专家的方式修改基准问题,但却会“欺骗”LLM,使其从正确答案变为错误答案。此外,他们还介绍了一种置换测试技术,该技术可确保成功的攻击具有统计学意义。他们展示了如何利用“MedFuzzed”基准的性能以及单个成功的攻击。这些方法有望让我们深入了解 LLM 在更现实的环境中鲁棒运行的能力。https://arxiv.org/abs/2406.06573
内容中包含的图片若涉及版权问题,请及时与我们联系删除








评论
沙发等你来抢