

表征学习是现代人工智能的核心。在计算机视觉中,像ImageNet这样的标记图像数据集已经成为表示学习的标准选择。尽管在经验上是成功的,但由于标签成本,这种方法的规模是昂贵的。此外,表示质量受到数据集及其相关标签本体的大小和多样性的限制。
研究探索在计算机视觉中使用自然语言监督。使用自然语言使我们能够超越固定的标签本体,并扩展到更一般的来源,如互联网数据。为了实现这一目标,论文探讨了四个问题:
(1)学习表征: 提出了语言监督视觉学习的第一种方法之一,它使用图像字幕作为训练目标,与imagenet训练的方法相比,它在下游任务(如对象检测和分割)上的有效性。
(2)扩展数据: 探索社交媒体作为高质量图像描述的丰富来源,并在确保负责任的策展实践的同时,管理1200万图像-文本对的数据集。
(3)理解数据: 很难理解数百万图像-文本对中存在的视觉概念的多样性。我假设图像和文本自然地组织成树状的层次结构,并提出了一种学习表征的方法,使用双曲几何中的工具捕获这种层次结构。
(4)向下游任务的迁移: 大型视觉语言模型在分类和检索等图像级任务上表现出令人印象深刻的零迁移能力。然而,它们在像素级任务(如对象检测和分割)上的可移植性依赖于昂贵的标记掩码注释。提出了一个对象检测器,它可以有效地将预训练的视觉模型转移到视觉对象的分割和分类,而无需任何微调,不像现有的检测器使用数量级更多的标记掩模来训练以实现高性能。
总之,研究肯定了使用语言监督可以推动计算机视觉的下一个飞跃,并且在实际应用中具有巨大的效用。

论文题目:Language Supervision for Computer Vision
作者:Karan P. Desai
类型:2024年博士论文
学校:University of Michigan(美国密西根大学)
下载链接:
链接: https://pan.baidu.com/s/1kvF0FWTtkCF14LlTvZZWfg?pwd=71tj
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
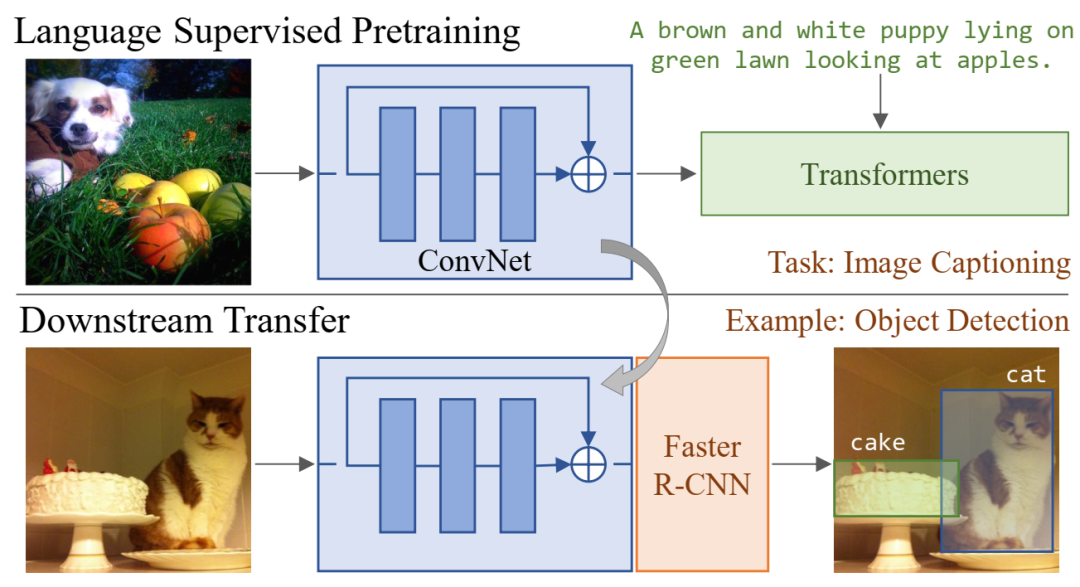
使用语言监督进行视觉表征学习:我们使用图像-字幕对联合训练 ConvNet 和 Transformers,以完成图像字幕任务。然后,我们将学习到的 ConvNet 迁移到视觉任务,例如物体检测。
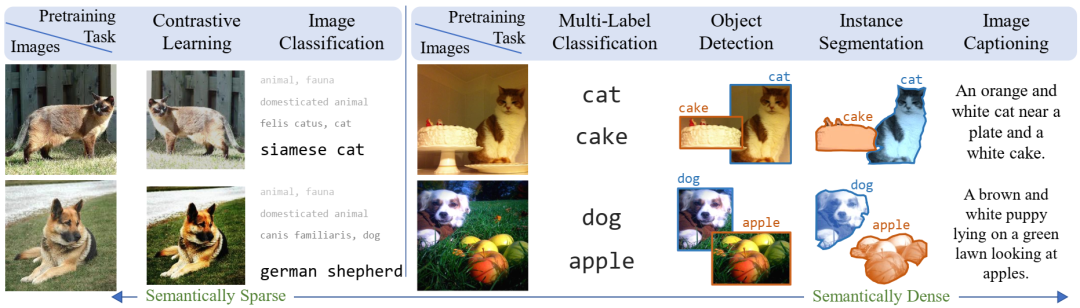 学习视觉表征的预训练任务比较:对比学习方法使用语义稀疏的学习信号,鼓励图像的不同视图具有相似的特征。图像分类将图像与单个语义概念配对,提供中等语义密度。多标签分类、对象检测和实例分割通过标记和定位多个对象来增加语义密度。标题描述多个对象、它们的属性、关系和动作,给出语义密集的学习信号。借助 VirTex,我们旨在从这些语义密集的标题中提取丰富的监督。
学习视觉表征的预训练任务比较:对比学习方法使用语义稀疏的学习信号,鼓励图像的不同视图具有相似的特征。图像分类将图像与单个语义概念配对,提供中等语义密度。多标签分类、对象检测和实例分割通过标记和定位多个对象来增加语义密度。标题描述多个对象、它们的属性、关系和动作,给出语义密集的学习信号。借助 VirTex,我们旨在从这些语义密集的标题中提取丰富的监督。
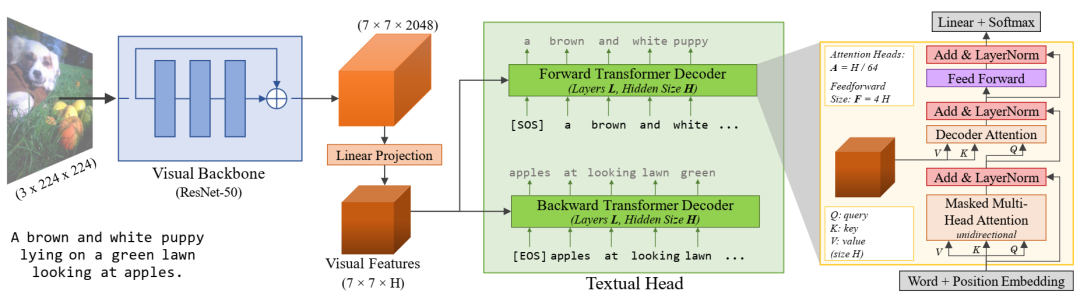
VirTex 设置:我们的模型由一个视觉主干(ResNet-50)和一个文本头(两个单向 Transformers)组成。视觉主干提取图像特征,文本头通过双向语言建模(双向字幕)预测字幕。Transformers 对字幕特征执行掩蔽多头自注意力,对图像特征执行多头注意力。我们的模型是从头开始端到端训练的。经过预训练后,视觉主干被转移到下游视觉识别任务。
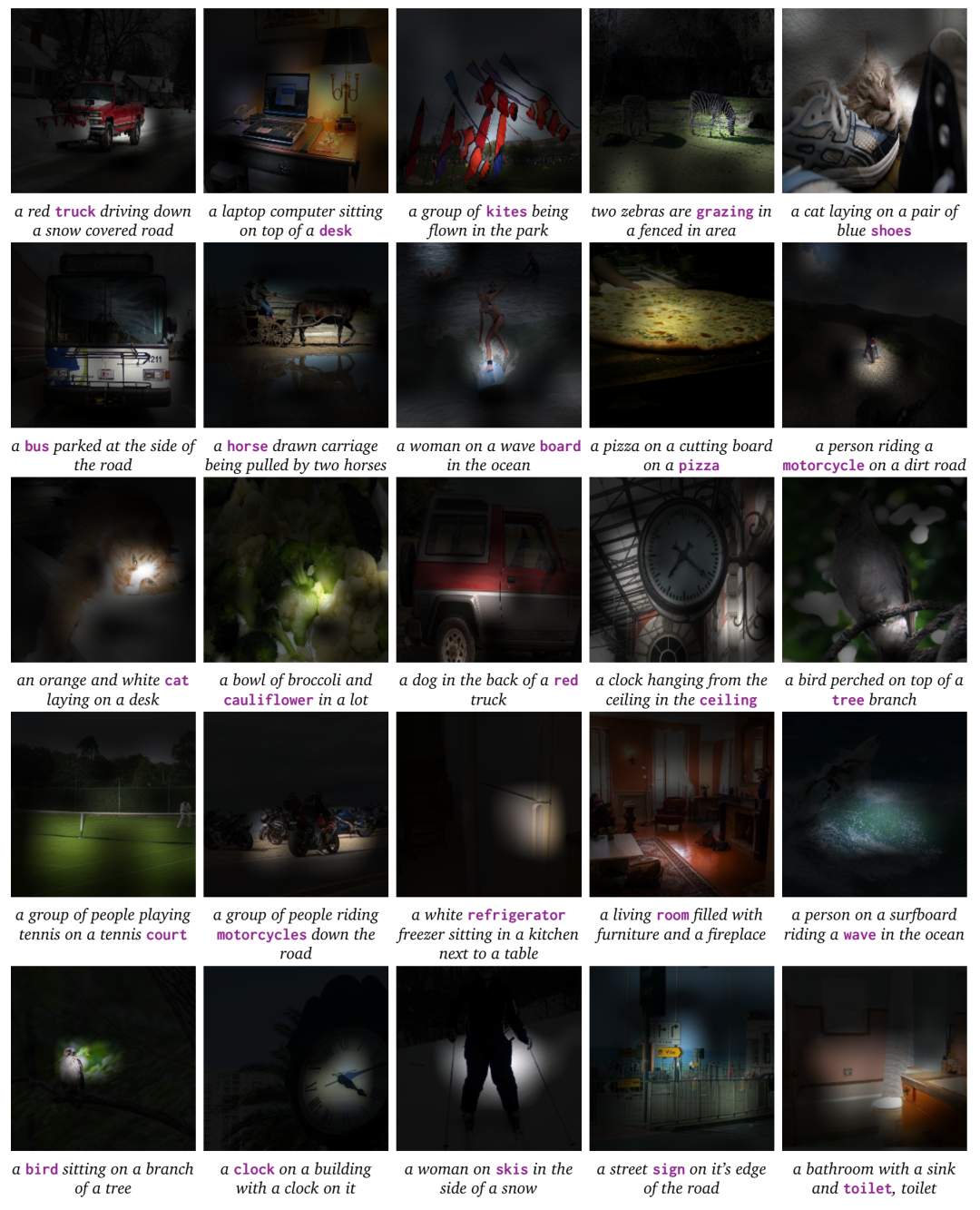
我们使用波束搜索从 L = 1;H = 512 VirTex模型的前向变换器解码字幕。对于突出显示的单词,我们将叠加在输入图像上的解码器注意力权重可视化。

Reddit 图片帖预览:我们通过从 Reddit 图片帖下载图像和相关元数据(以橙色突出显示)来收集 RedCaps 数据集。

使用在 CC-3M 和 RedCaps 上训练的 VirTex-v2 进行图像字幕制作。三名众包工作者观察了这些字幕(没有 subreddit 名称),并投票选出更有可能由人类撰写的字幕。大多数工作者投票的字幕都带有下划线。大多数投票的字幕都是由 RedCaps 训练的模型预测的。这些字幕提及(上行):有机参考(小家伙与动物)、妙语(雪雕)和具体提及(新加坡)。
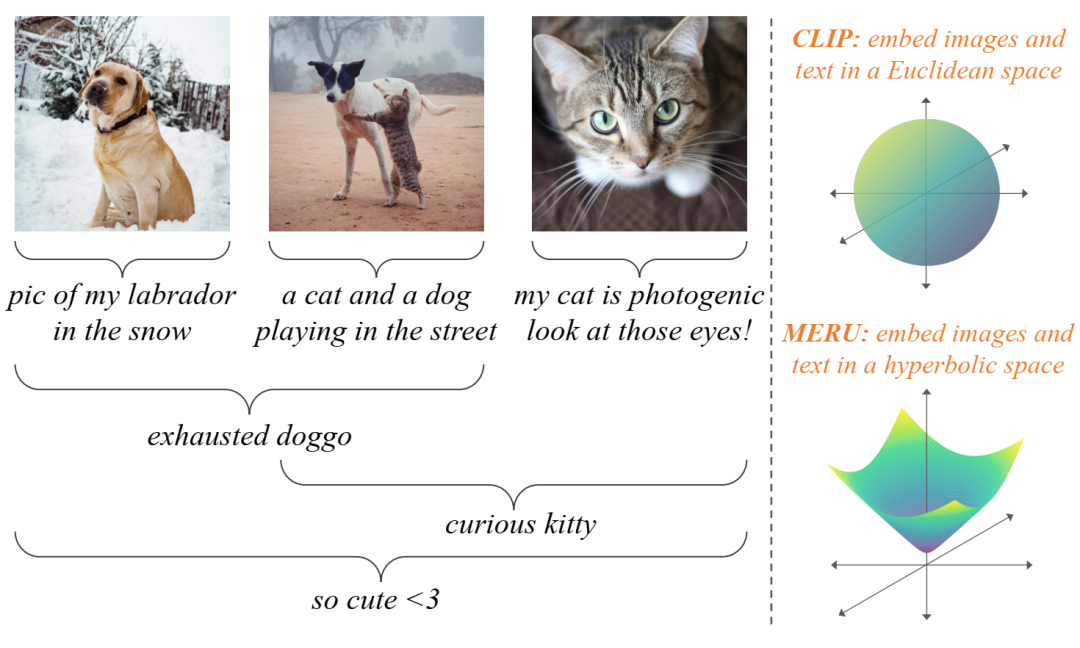
双曲图像文本表示。左图:图像和文本描述概念并且可以在视觉语义层次结构中联合查看,其中文本“精疲力竭的狗狗”比图像(可能包含更多细节,如猫或雪)更通用。我们的方法 MERU 将图像和文本嵌入双曲空间中,非常适合嵌入树状数据。右图:CLIP(超球面)和 MERU(双曲面)的表示流形以 3D 形式显示。MERU 假设原点表示最通用的概念,并将文本嵌入到比图像更靠近原点的位置。
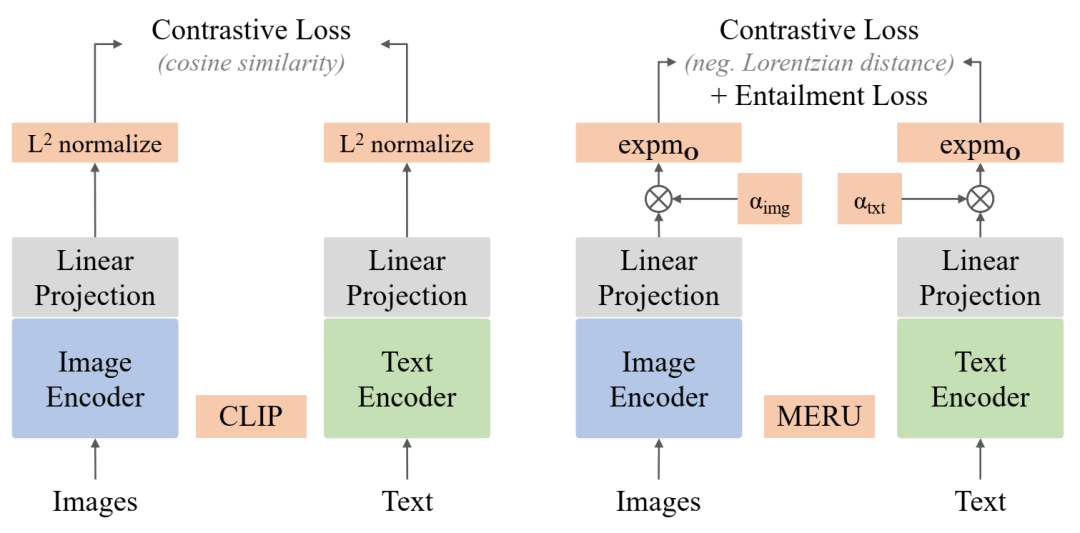
MERU 模型设计:MERU 包含与 CLIP 等标准图像文本对比模型类似的架构组件。CLIP 将嵌入投影到单位超球面,而 MERU 使用指数映射将它们提升到 Lorentz 双曲面上。对比损失使用 Lorentzian 距离的负数作为相似度度量,而蕴涵损失则在表示空间中强制执行“文本蕴涵图像”的偏序。
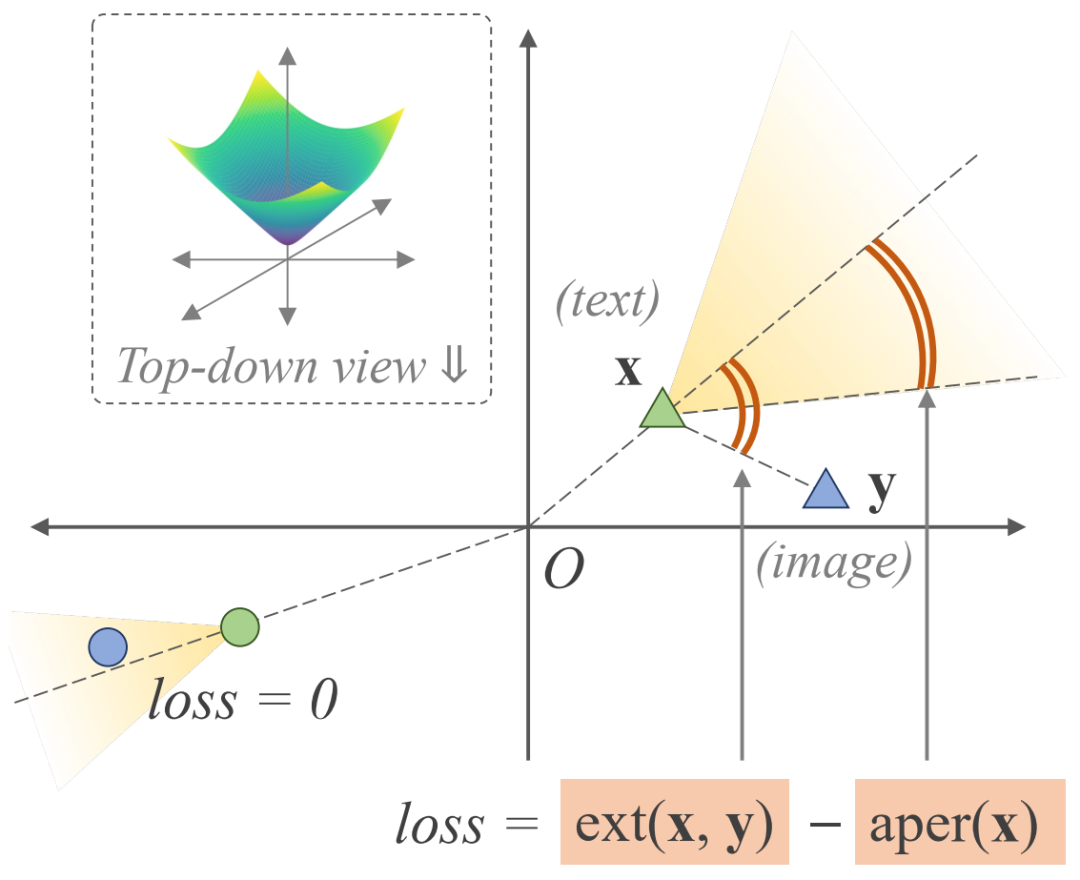
蕴涵损失(以 L2 为例):此损失将图像嵌入 y推入由成对的文本嵌入 x 投影的假想锥体内,并以外角 \Oxy 与锥体半孔径之差的形式实现。如果图像嵌入已位于锥体内(左象限),则损失为零。
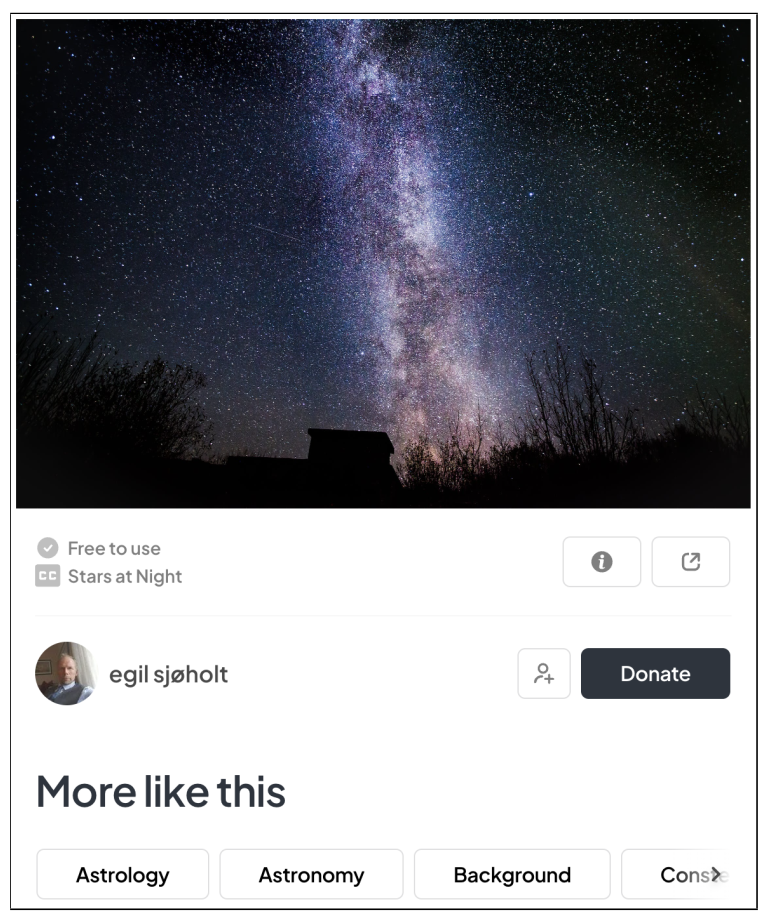
pexels.com 网页。我们从该网站收集图像和相关文本元数据(隐藏字幕、CC 和相关关键字、‘更多类似内容’),以创建用于图像遍历分析的检索集。
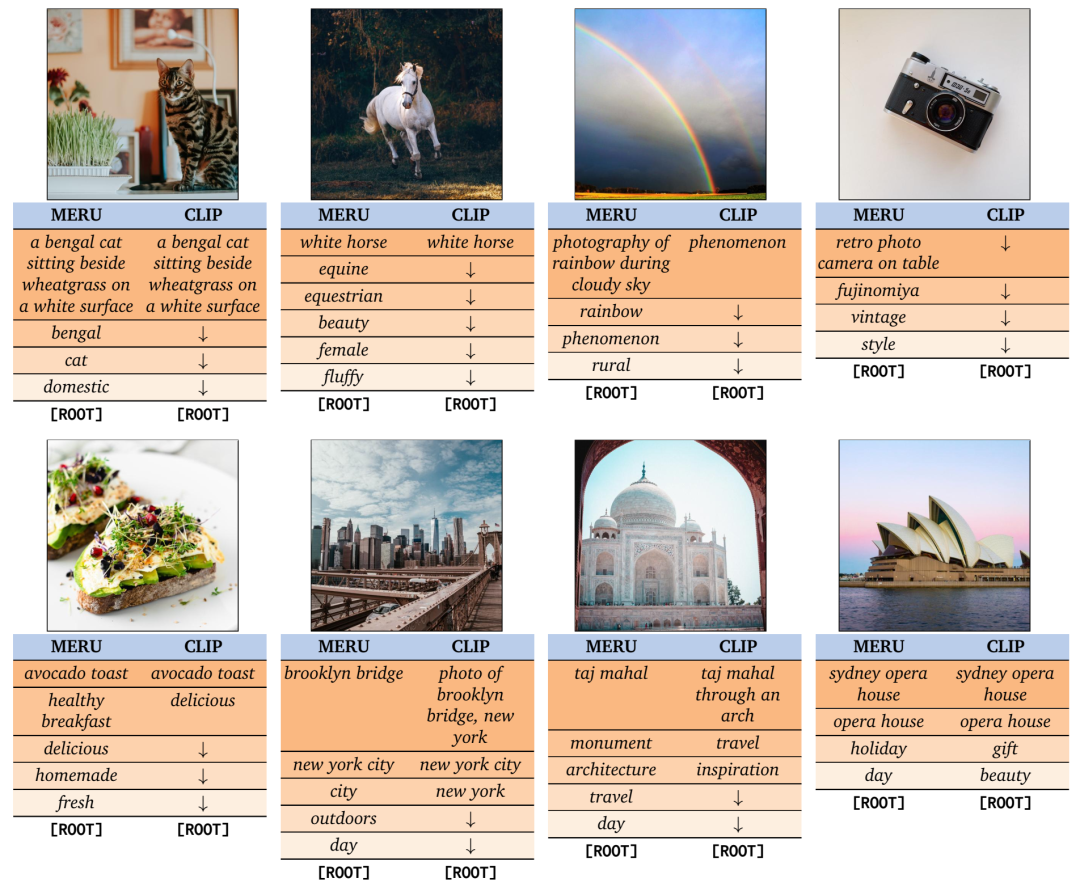
使用 MERU 和 CLIP 进行图像遍历。CLIP 检索到的文本概念总体较少(上行),但在某些情况下,它揭示了一个粗略的层次结构(下行)。MERU 以更详细的细节捕捉层次结构,我们观察到:(1)文本变得更加通用,我们朝着 [ROOT] 移动,例如,白马!马术。(2)MERU 对概念的回忆率高于 CLIP,例如,自制、城市、纪念碑。(3)MERU 显示系统的文本!图像蕴涵,例如,白天蕴涵许多在日光下拍摄的图像。

使用分割和分类任何模型 (SCAM) 进行零样本传输。我们引入了一种通用检测器设计,该设计由专门用于分割 (SAM) 和分类 (CLIP) 的预训练视觉模型组成。我们精心的设计保留了底层模型的功能,可以快速高效地传输到对象检测和实例分割。图中显示了 SCAM 使用 CLIP ConvNeXt-XXL 为来自 OpenImages 和 LVIS 数据集的随机图像预测的高分掩码。SCAM 可以分割新对象,而无需在组成 SAM 和 CLIP 模型的预训练知识极限内进行下游微调。
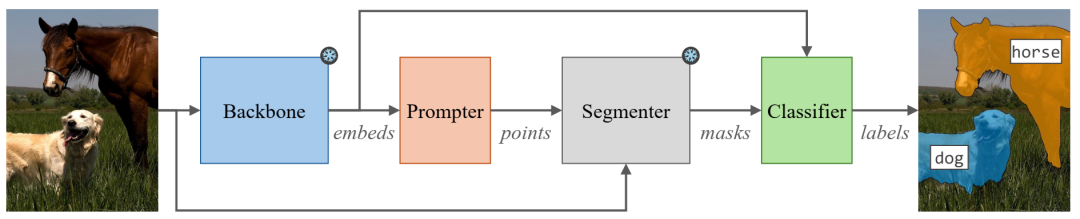
SCAM 设计:图像主干从输入图像中提取嵌入。提示器使用主干嵌入为我们感兴趣的视觉概念提出一组像素位置。分割器使用图像和像素提示来预测一组二进制掩码。最后,分类器使用主干嵌入和来自分割器的掩码执行掩码分类以预测类标签。我们的主干和分割器始终处于冻结状态,同时我们可选择为各种数据方案训练轻量级提示器和分类器。

使用 SCAM 进行零样本迁移:定性结果。使用 CLIP ConvNeXt-XXL 预测的 SCAM 对来自 OpenImages 的随机图像的高分蒙版。SCAM 无需任何下游微调即可分割新物体。



微信群 公众号


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢