

新智元报道
新智元报道
【新智元导读】Build大会召开两周之后,微软更新了Phi-3系列模型的技术报告。不仅加入最新的基准测试结果,而且对小模型、高性能的实现机制做出了适当的揭示。
这个月的微软Build大会上,微软正式官宣了Phi-3家族新成员:Phi-3-vision、Phi-3-small,Phi-3-medium。
此外,还有上个月就发布技术报告的Phi-3-mini,刚推出时,就让许多开发者印象深刻。
比如,Xenova基于Phi-3-mini开发了一个完全在本地运行的浏览器聊天应用WebGPU,demo看起来的效果像是经过加速的视频:
结果Xenova还要特意出来声明:视频没加速,部署的模型就是这么快,平均每秒生成69.85个token。
在人人追求LLM的大环境下,微软却始终没有放弃SLM这条路。
从去年6月Phi-1面世,到Phi-1.5、Phi-2,再到如今Phi-3,微软小模型已经完成四次迭代升级。
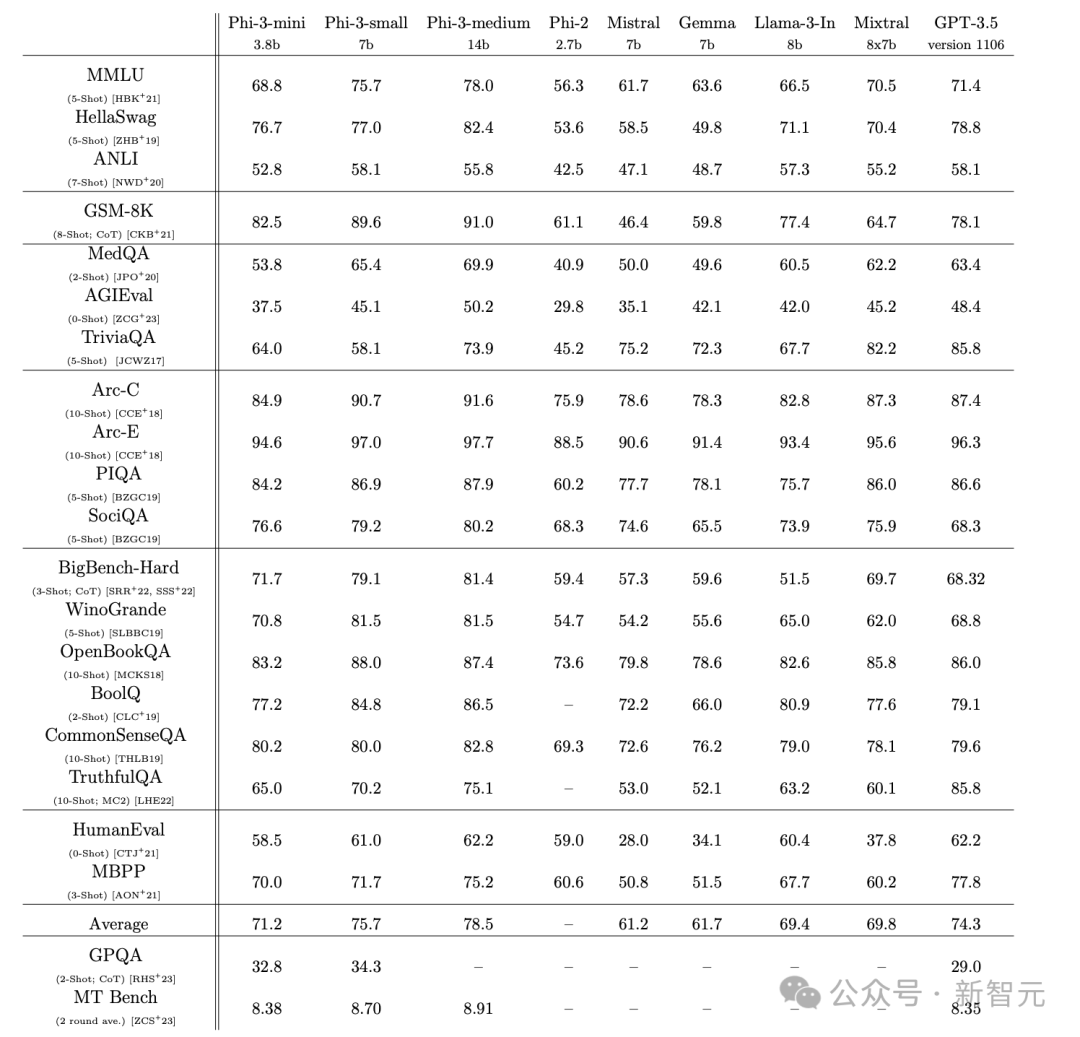
这次3.8B参数的Phi-3-mini、7B的small和14B的medium,相比规模更大的模型,都展现出了更强的能力。
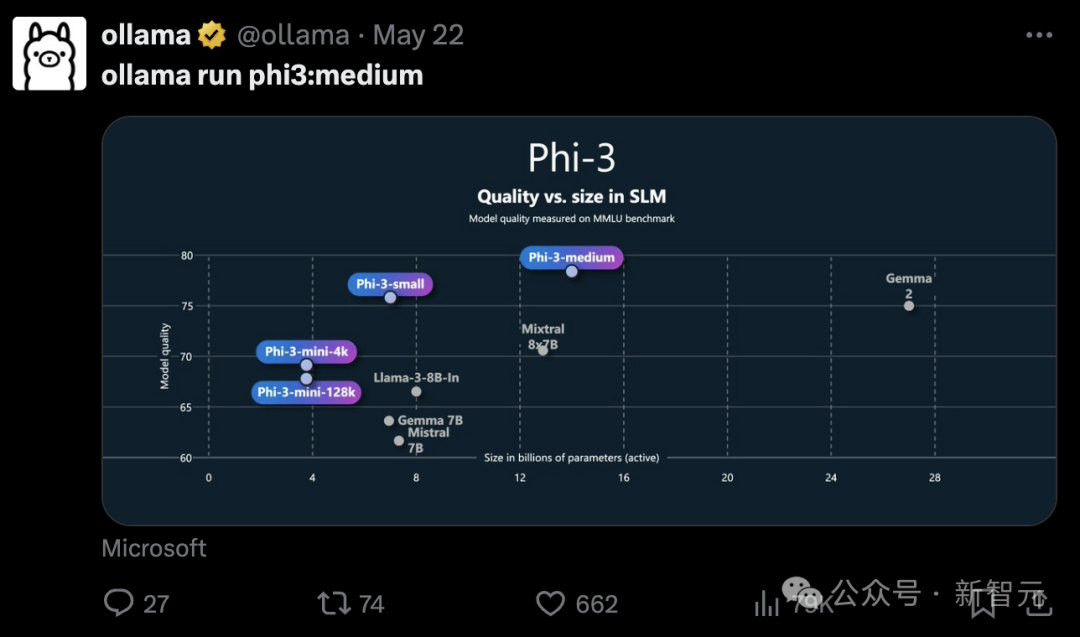
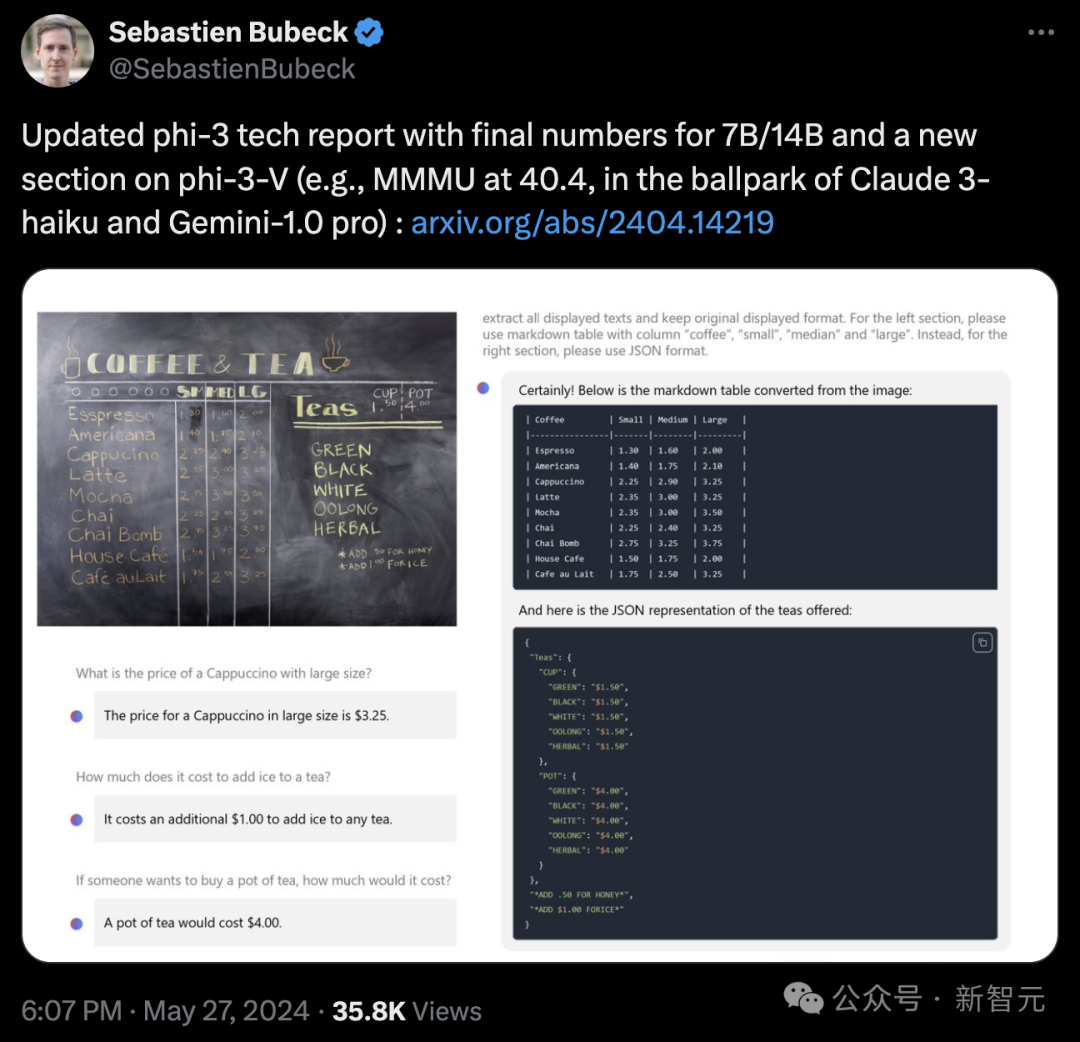
在评论区,网友们尽情抒发对Phi-3这种开源且强大的小模型的喜爱之情。

或许,微软在SLM这条路上真的赌对了?让有强大能力的模型真正落地、渗透到各种应用中,才能带来真正的变革。
Phi-3语言模型:小而美
Phi-3-mini与small都使用了标准的纯解码器Transformer架构。
为了最大程度方便开源社区,Phi-3-mini使用了和Llama 2相同的分词器和类似的块结构,这就意味着所有部署在Llama 2上的软件包都可以无缝迁移。
small版模型则使用OpenAI的tiktoken分词器,更适合多语言任务,此外为了实现高效的训推,也在模型架构上做了许多改进:
用GEGLU激活函数代替GELU

使用最大更新参数化策略(Maximal Update Parameterization)在代理模型上调整超参数,保证模型训练时的参数稳定
采用分组查询注意力
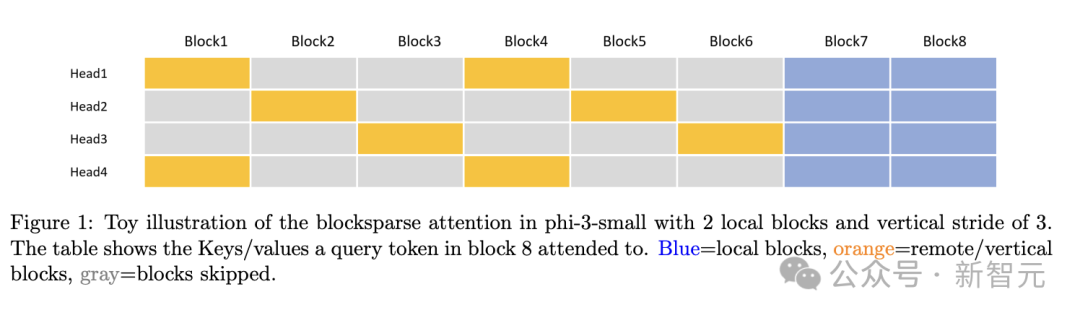
设计了块稀疏注意力模块(blocksparse attention module),用较少的KV缓存处理更长的上下文
为训练和推理分别实现不同的kernel,真正发挥块稀疏机制的优势,实现部署后的模型加速
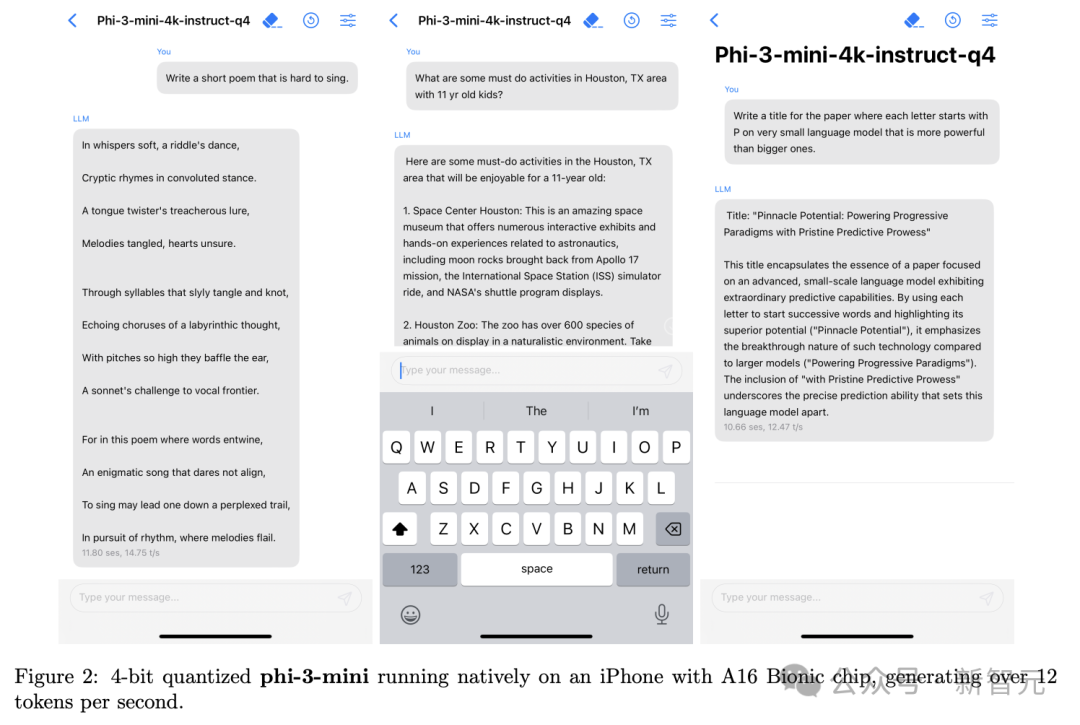
Phi-3-V依旧坚持了语言模型的「小参数」策略,参数量仅有4.2B,可以接受图像或文本提示作为输入,然后生成文本输出。
模型架构也非常简洁,包含图像编码器CLIP ViT-L以及文本解码器Phi-3-mini-128K-instruct。
预训练过程总共涉及0.5T token的数据,包含纯文本、表格、图表以及图像和文本相交错的数据,预训练后同样进行了SFT和DPO微调,也是多模态任务和纯文本任务同时进行。
通过完全相同的pipeline生成的结果,技术报告将Phi-3-Vision与通义千问、Claude、Gemini 1.0 Pro和GPT-4V Turbo等模型进行了对比。
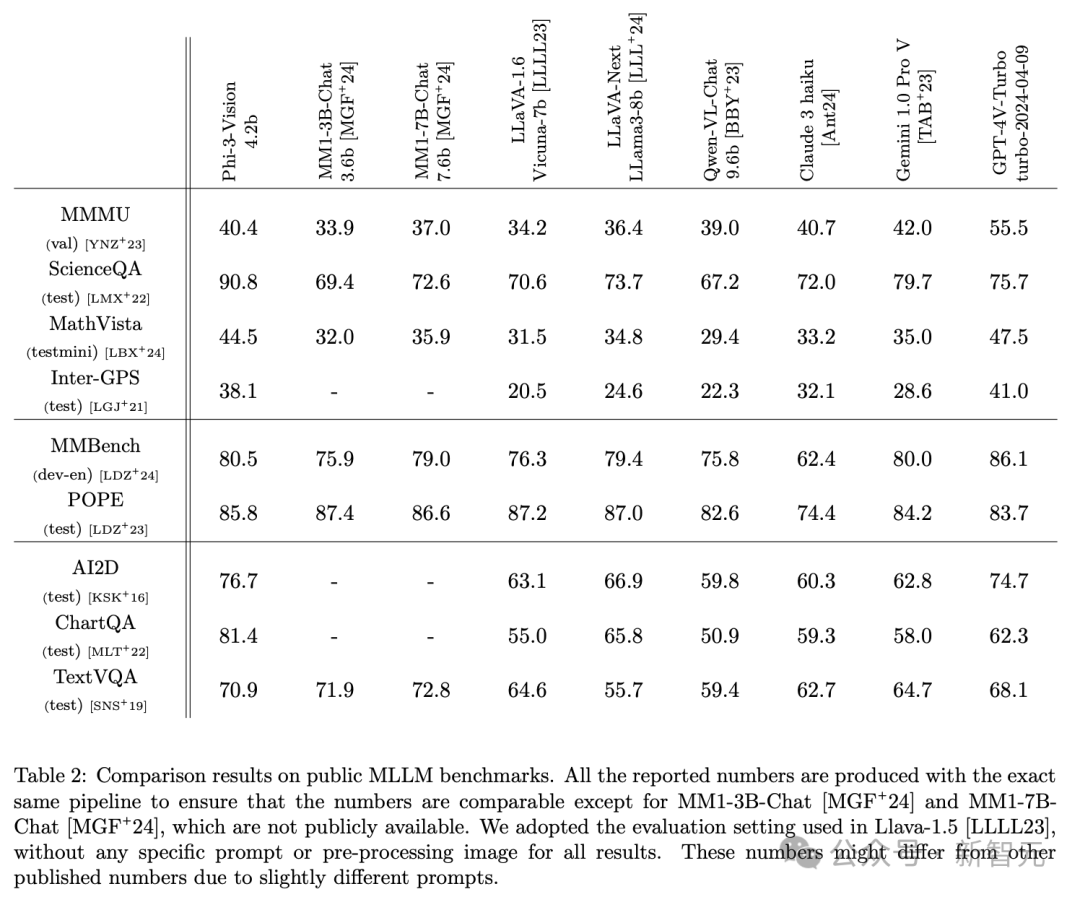
在总共12个基准测试中,在ScienceQA、POPE、AI2D、ChartQA和TextVQA这5个任务上,Phi-3-V都取得了比GPT-4V-Turbo更高的分数。
其中图表问答任务ChartQA中,Phi-3相较GPT-4V提升了19分,ScienceQA则领先15分达到了90.8分。
而在其他任务上,虽然分数不敌GPT-4V,但也可以高到与Claude 3和Gemini 1.0 Pro对打,甚至超过这些更大的模型。
比如MathVista和Inter-GPS上,都领先Gemini约10分左右。
Phi-3-Vision在图像理解和推理方面的能力
数据换参数
Phi-3为什么能用较少的参数得到强大的能力?技术报告从侧面揭示了答案。
微软在Phi系列模型的探索中发现了一种训练数据「配方」,可以在小模型中实现更大模型才有的性能。
这种配方就是LLM过滤后的公开网络数据,与LLM合成数据相结合。这可以启发我们,数据内容与质量到底能在多大程度上影响模型性能。

这完全是通过更改训练数据实现的...开发出一种更紧凑的语言模型,可以与ChatGPT的能力媲美,同时能在手机上运行,这证明了数据启动的机器学习的力量。通过精心策划并优化训练数据集,可以在不影响性能的情况下显著缩小模型规模。
Phi-1模型就是用「教科书质量」的数据,首次实现了SLM的性能突破。

技术报告将这种数据驱动的方法称为「数据最优机制」(Data Optimal Regime)。在给定规模的情况下,尝试「校准」训练数据,使其更接近SLM的「数据最佳」状态。
这意味着在样本级别进行数据的筛选,不仅要包含正确的「知识」,还要能最大程度提升模型的推理能力。
而Phi-3-medium在提升7B参数后性能没有明显进步,一方面可能由于架构与参数规模不适配,另一方面也可能缘于「数据混合」的工作没有达到14B模型的最佳状态。
然而,天下没有免费的午餐,即使有架构和训练策略的改进,参数的缩小也不是没有代价的。
比如,没有多余的参数来隐式存储太多「事实知识」,这可能导致了Phi-3语言模型在TriviaQA上的低分,视觉模型的推理能力也被局限。
虽然团队在数据、训练和红队工作上付出了大量努力,也看到了显著成效,但模型的幻觉和偏见问题依旧有很大改进空间。
此外,训练和基准测试主要用英语进行,SLM的多语言能力还有待探索。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢