
DRUGAI
今天为大家介绍的是来自Prescient Design, Genentech团队的一篇论文。作者提出了VoxBind,这是一种基于评分的3D分子生成模型,该模型以蛋白质结构为条件。作者的方法将分子表示为3D原子密度网格,并利用3D体素去噪网络进行学习和生成。作者将神经经验贝叶斯的形式扩展到条件设置,并通过两步程序生成基于结构的分子:(i) 使用学习到的评分函数,通过欠阻尼的Langevin MCMC从高斯平滑的条件分布中采样噪声分子,(ii) 通过单步去噪从噪声样本中估计出干净的分子。与当前的最先进技术相比,作者的模型更易于训练,采样速度显著更快,并且在大量的计算基准测试中取得了更好的结果——生成的分子更加多样化,表现出更少的空间碰撞,并且与蛋白质口袋结合的亲和力更高。

基于结构的药物设计(SBDD)的目标是生成与目标生物分子的特定3D结构具有高亲和力的分子。传统的计算方法如虚拟筛选,通过在一个分子库中进行搜索并评分,以识别出与特定目标最匹配的分子。然而,随着分子大小的增加,化学空间呈指数级增长,随机搜索的效率变得非常低下。
最近,许多生成建模方法被提出作为基于搜索的SBDD的替代方案。在这种情况下,目标是开发数据驱动的方法,生成基于3D蛋白质结合位点(即口袋)条件的分子(即配体)。生成模型有望比基于搜索的方法更高效、更有效地探索化学空间。
SBDD生成模型通常将分子表示为离散的体素网格或原子点云。基于体素的方法将原子(或电子密度)表示为连续的密度,并将分子表示为3D空间的体素网格离散化(体素是体积的离散单位)。基于点云的方法将原子视为3D欧几里得空间中的点,并依赖于图神经网络(GNN)架构。当前最先进的数据驱动SBDD方法基于E(3)等变扩散模型,在蛋白质口袋条件下对点云进行操作:它们从高斯先验中采样点,并迭代应用学习到的反向条件扩散过程(在连续坐标和离散原子类型和键上)以生成分子。
在这两种数据表示选择之间存在明显的权衡。一方面,GNN可以比在体素上操作的架构更容易利用SE(3)等变归纳偏置。另一方面,由于消息传递的形式主义,它们被认为不那么具表现力。这些模型的表现力可以通过更高阶的消息传递方案来提高。然而,它们需要额外的计算成本,并且尚未应用于3D生成模型。最近,实验证明,非等变但更具表现力的模型在计算机视觉到分子生成的不同领域中与等变模型竞争。事实上,可以从大量数据和强大的数据增强中学习到等变性。受这些发现的启发,作者提出了一种优先考虑表现力而不是SE(3)等变归纳偏置的SBDD模型。
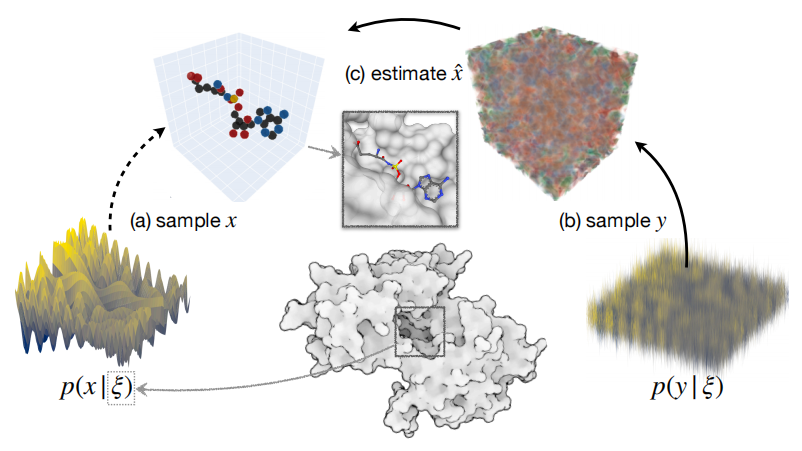
图 1
VoxBind是一种新的基于体素的3D配体生成方法,其条件是口袋结构。该模型通过将神经经验贝叶斯(NEB)框架扩展到结构条件设置来生成分子。如图1所示,给定一个蛋白质口袋ξ,而不是直接从p(x|ξ)采样配体x,作者采用两步程序:(i)从高斯平滑分布p(y|ξ)中采样噪声分子y以及(ii)从y和ξ中估计出干净的配体。作者训练了一个条件去噪器(一个给定噪声版本和其结合口袋预测干净配体的模型)以近似平滑分布的条件评分函数和配体估计器,这是步骤(i)和(ii)所必需的。
模型方法
为了体素化分子,作者将原子表示为3D空间中的球形密度,其密度随到原子中心的平方距离呈指数衰减。通过将原子周围的空间离散化为体素网格来创建体素化分子,每个体素的值表示原子的占据情况。体素的取值范围为0(远离所有原子)到1(在原子中心)。配体和口袋分别表示为边长为L的立方网格。每个配体网格及其对应的口袋网格都以配体的质心为中心。作者假设配体有cx种原子类型,口袋有cξ种原子类型。每种原子类型(元素)用一个不同的网格通道表示(类似于图像的R,G,B通道)。

图 2
如图2所示,作者通过以下架构来构建条件体素去噪器:(i)使用单独的编码器对噪声配体和口袋进行编码,(ii)合并它们的表示,(iii)通过编码器-解码器架构预测干净样本。模型通过最小化所有体素化配体的均方误差进行训练。
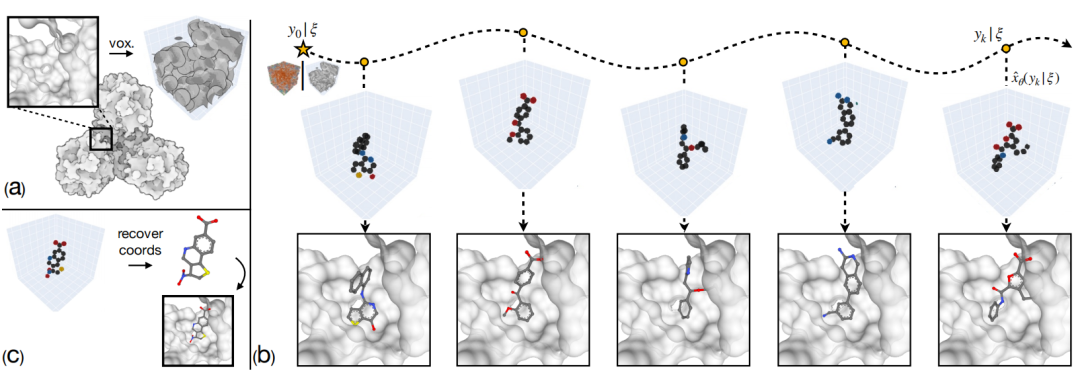
图 3
作者通过条件walk-jump采样(cWJS)从体素化的蛋白质口袋条件下采样体素化配体。图3展示了口袋条件下的行走跳跃采样链的过程。首先,作者对一个给定的蛋白质结合口袋进行体素化。然后,作者用Langevin MCMC对噪声体素化配体(给定口袋)进行采样,并用估计器估计干净样本。最后,作者从体素网格中恢复原子坐标。
实验结果
表 1
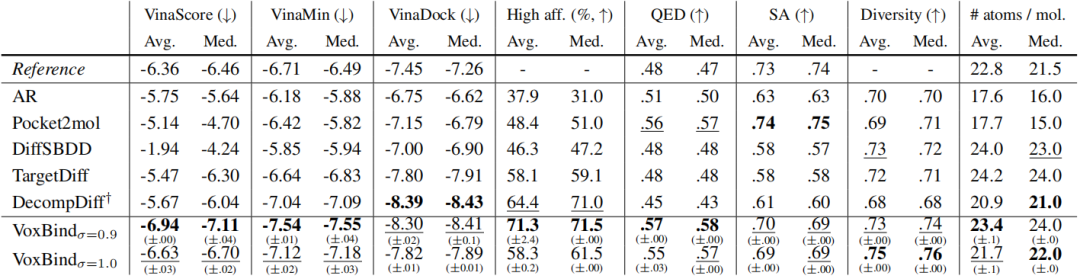
表1比较了在CrossDocked2020测试集上,各模型在结合亲和力和分子性质方面的表现。作者的模型在大多数评估指标上都取得了比TargetDiff(在相同假设下训练的最佳模型)和DecompDiff(依赖不同训练假设)更好的结果。由VoxBindσ=0.9和VoxBindσ=1.0生成的分子具有更好的结合亲和力。特别是,作者的模型生成的分子在对接姿势方面优于其他方法:其生成姿势的对接评分(VinaScore)比能量最小化后的方法(VinaMin)的评分更好或相当。
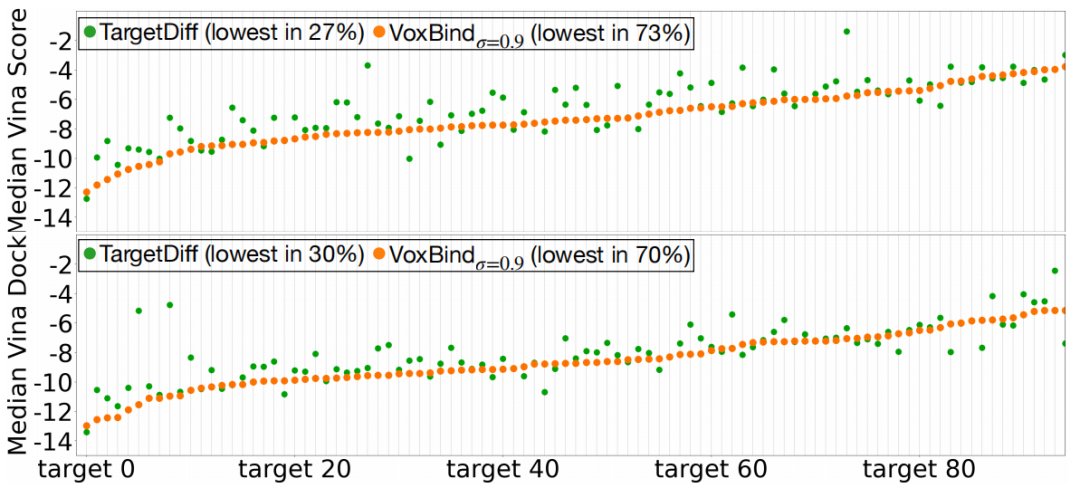
图 5
图5进一步将作者的模型与TargetDiff进行了比较。图中显示了测试集中每个目标的所有生成分子的中位数VinaScore和VinaDock(分别对应生成的姿势和重新对接的姿势)。由VoxBindσ=0.9生成的分子在73%的测试蛋白质口袋上具有更好的(计算)亲和力。
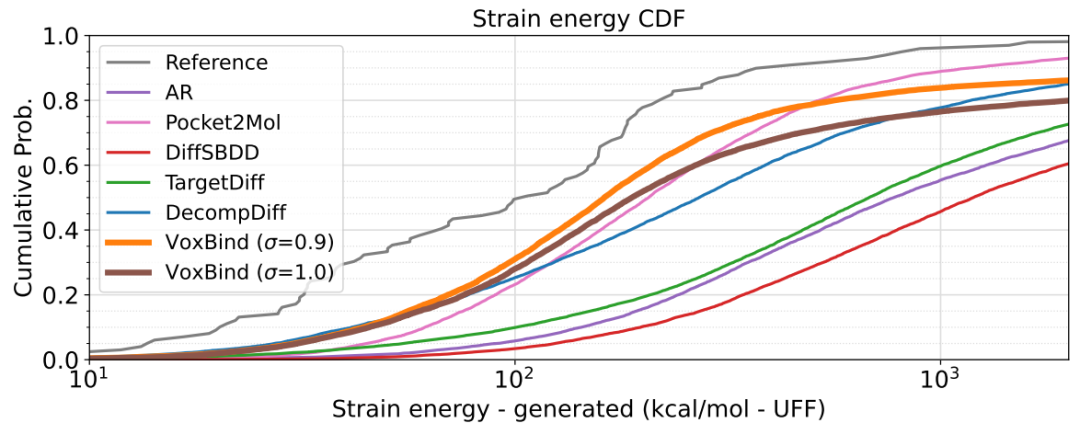
图 6
图6显示了不同模型生成的分子的应变能累积分布函数(CDF)(在原始生成的姿态上)。参考集的中位应变能为102.5 kcal/mol,而表现最好的三个模型,Pocket2Mol、VoxBindσ=0.9和VoxBindσ=1.0的中位应变能分别为205.8、161.9和188.3 kcal/mol。
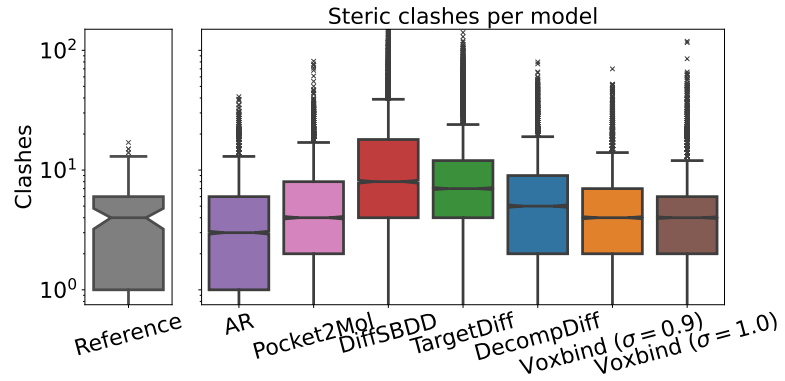
图 7
图7显示了每个配体的空间碰撞数(在其生成的姿态上)。作者的模型生成的配体相比其他方法有更少的碰撞。实际上,VoxBindσ=0.9和VoxBindσ=1.0的平均碰撞评分分别为5.1和5.3,而AR、Pocket2Mol、DiffSBDD、TargetDiff和DecompDiff的平均碰撞评分分别为4.2、5.8、15.4、10.8和7.1。
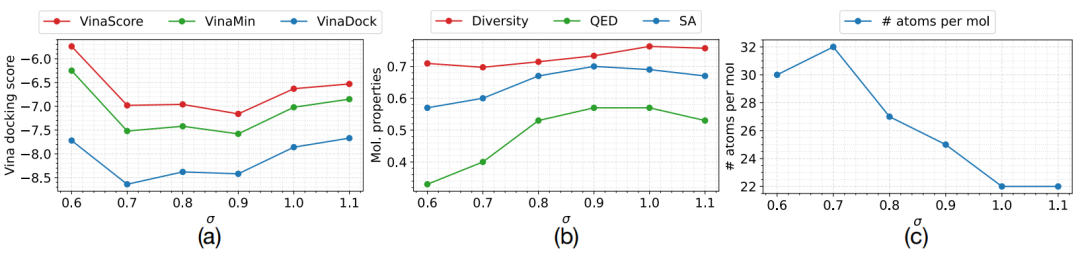
图 8
噪声水平是模型的重要超参数。随着噪声水平的增加,从平滑分布中采样变得更容易,但去噪变得更困难。为了找到最佳的经验噪声水平,作者在不同的噪声水平下训练模型(保持所有其他超参数不变),然后比较了验证集中基于口袋条件的样本质量。图8显示了不同噪声水平下各指标的变化。作者发现,当σ = 0.9和σ = 1.0时,在验证集上取得了最佳结果,因此选择报告这两个水平下的结果。
结论
本文介绍了VoxBind,这是一种基于评分的SBDD生成模型。作者将神经经验贝叶斯形式和walk-jump采样算法扩展到了条件设置,并展示了该模型在许多计算指标上优于以往的工作的同时生成样本的速度更快。
作者的方法非常灵活,可以在不进行额外训练的情况下适应许多实际的SBDD设置。例如,如果以与目标口袋结合的配体开始,可以用该配体的平滑版本而不是噪声来初始化MCMC链。3D U-Net的灵活性和表现力以增加内存消耗为代价。因此,作者在3D空间中可以处理的体积受限于GPU的内存。实验证明,作者的方法在类似药物的分子生成方面效果很好。然而,还需要在数据表示和架构方面进行更多工作,以扩展到更大分子的生成,如核酸和蛋白质。未来的工作还包括更好地建模合成可行性或将口袋动态性整合到生成过程中。
编译 | 于洲
审稿 | 曾全晨
参考资料
Pinheiro P O, Jamasb A, Mahmood O, et al. Structure-based drug design by denoising voxel grids[J]. arXiv preprint arXiv:2405.03961, 2024.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢