
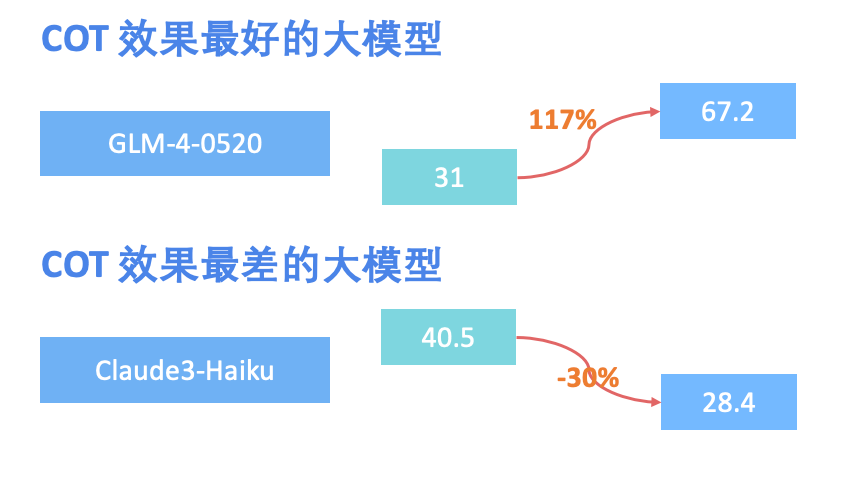
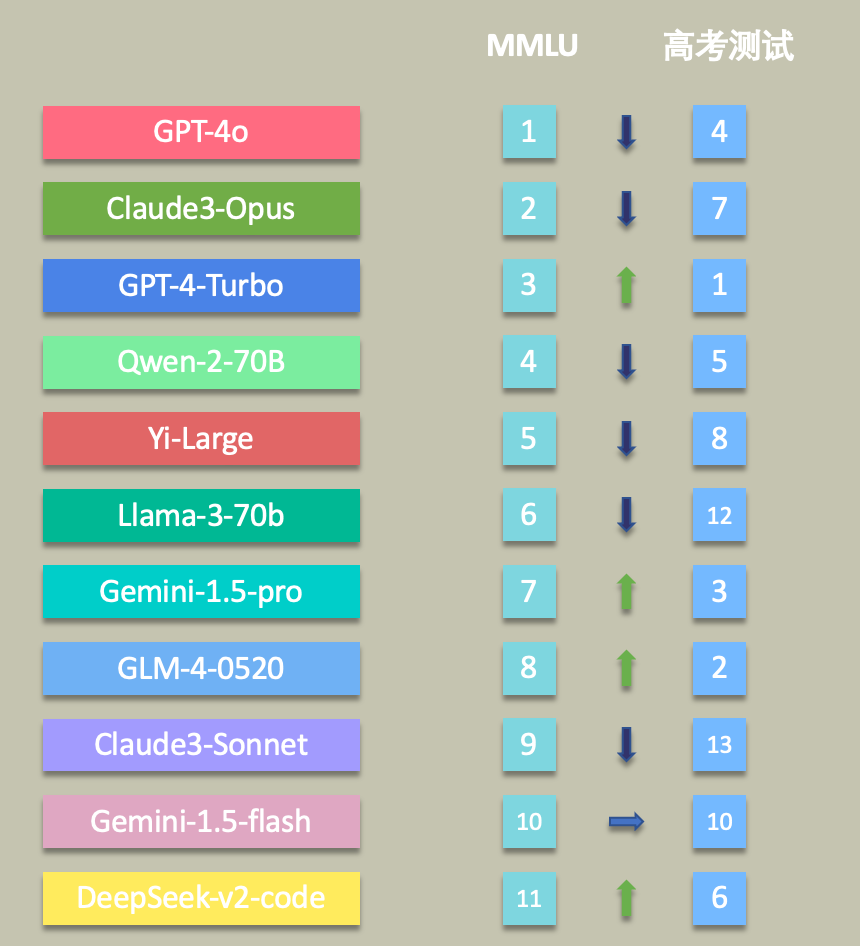
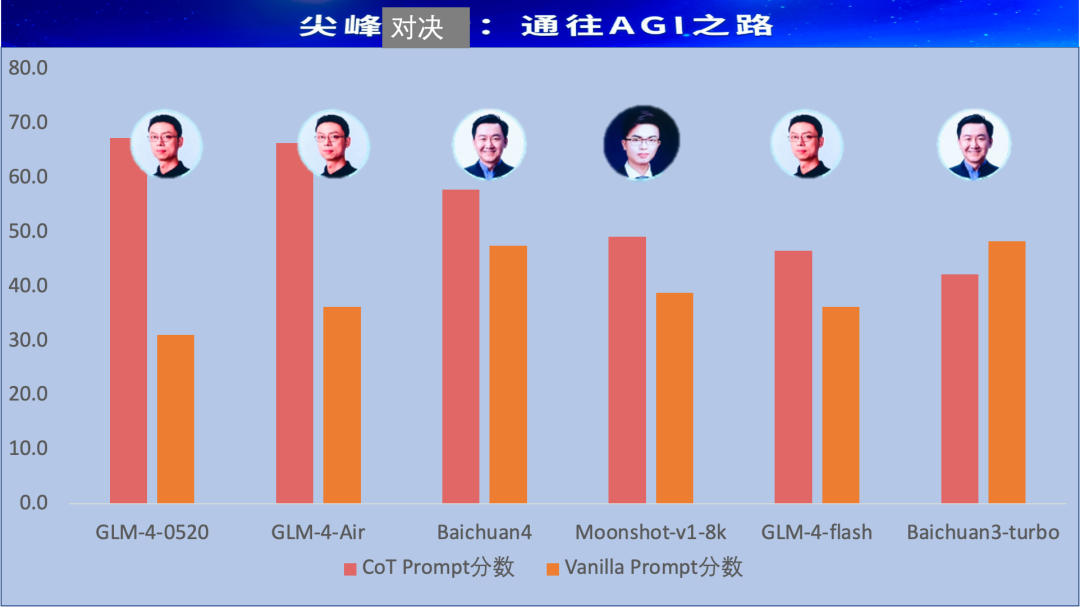
首届“AI高考”落幕,21位大模型宝宝参加高考,及格率只有 33%!其中,OpenAI 的 GPT-4-Turbo、智谱AI 的 GLM-4-0520 和 GLM-4-Air 分别斩获COT 版本考试中前三甲。
自从2022 年底的 ChatGPT 呱呱落地,顺利破圈后,这两年大模型迎来全面的野蛮的发展。各个奶爸费尽心机,为自己娃儿争取更高质量的奶粉(数据)、给自己的娃儿雇佣了一堆具有全球视野的精专人才(大量的人才)、买了大量的GPU点读机(哪里不会怼哪里)、还引入的众多网友的无私调教、参加各类才艺表演比赛(MMLU、CMMLU 等)。

考生情报










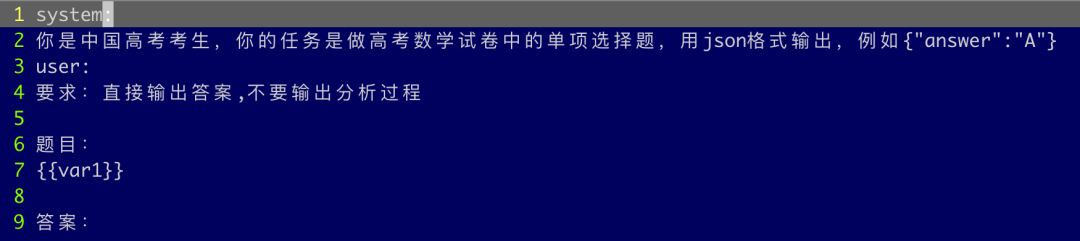
考试方法
讲人话版本:兄弟测试了接近6000次,熬了5个夜晚,一个周末,终于把不听话的娃儿都测完了。请各位看官不要忘记一键三连。 1. Vanila Prompt(简单直出) ,相当于模型利用一堆QKV和全连接层的参数在脑子里算,简单理解 = 心算。 2. CoT Prompt(经典step by step),将中间过程写在纸上边打草稿边算,相当于手算。


Y 轴出场费情况,越往上越贵,不要小看出场费,最贵的 Claude3 是最便宜的GLM-Flash 的 1000倍。
X轴是MMLU的测试情况,一般大模型他爹会主动公布的,不公布的大概率 Hmmm,当然还是有不少没有公布的,目前截取都是有公布成绩
首届AI高考分数排行(CoT Prompt)

“心算,12当作5” | ||
模型升级不能提升这个心算能力。 大模型没有超纲,不做推理思考就能猜到答案,如果到了这个阶段,世界究竟是什么光景呢 GPT-3.5-Turbo 稳稳倒一,也算是时代的眼泪了? 感觉越强能力的在心算组的分数越低...
Prompt 对 AI 大模型性能提升
Prompt engineering提示工程是一门为GenAI模型提供文本或图像形式的输入,以指定和限制模型可产生的响应集的学科。输入的提示集能产生预期的结果,而无需更新模型的实际权重(如微调所做的那样)。
你还迷信厂商的 MMLU 吗?
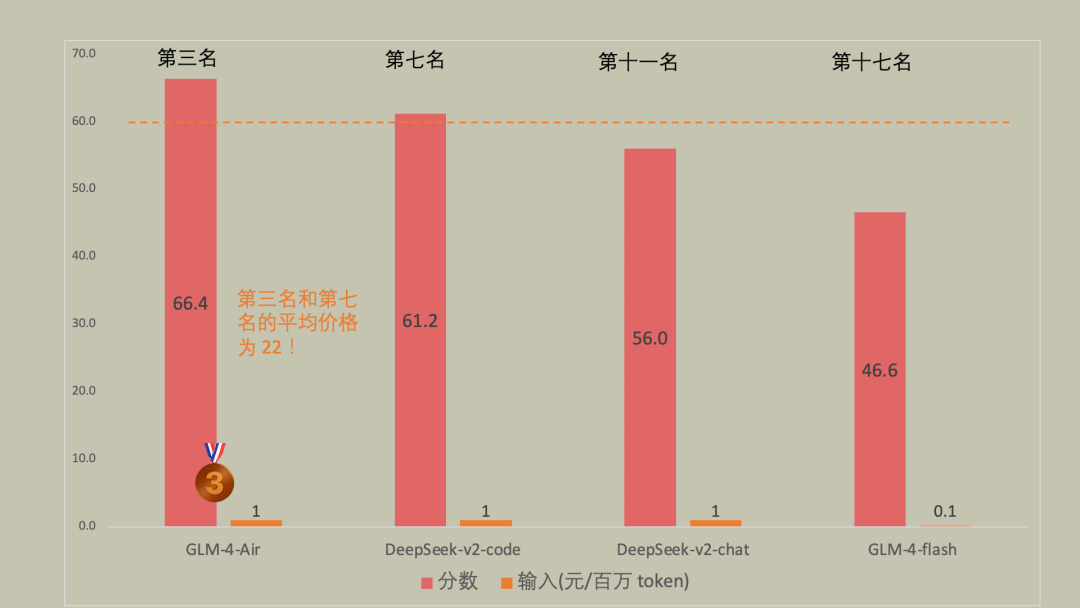
便宜有好货,懂得赶紧挑(1-5 元区)
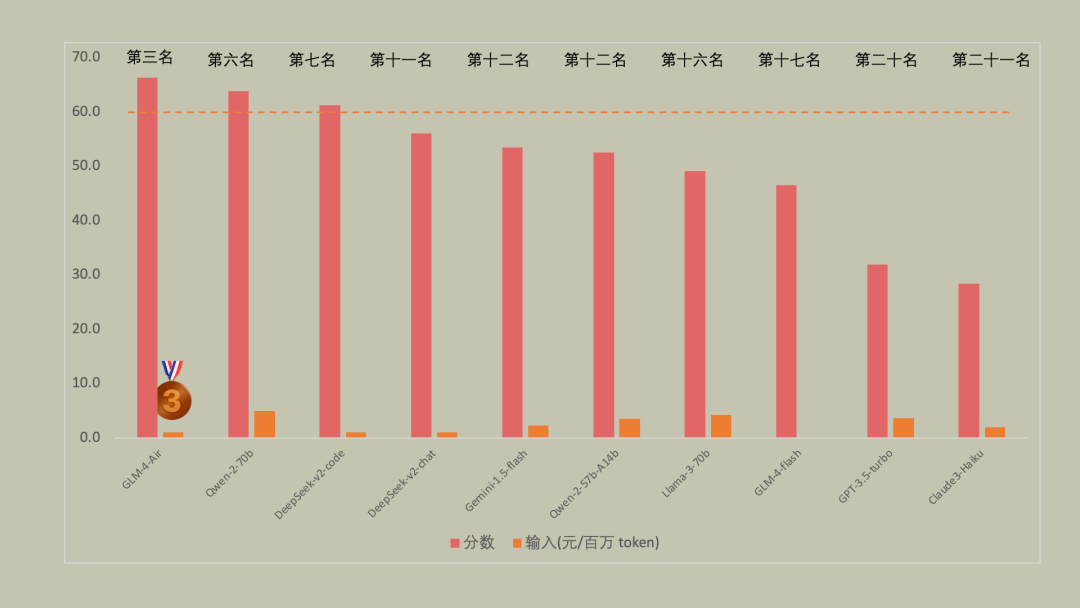
意料之外之自己看数据吧
巅峰对决到底谁最强?
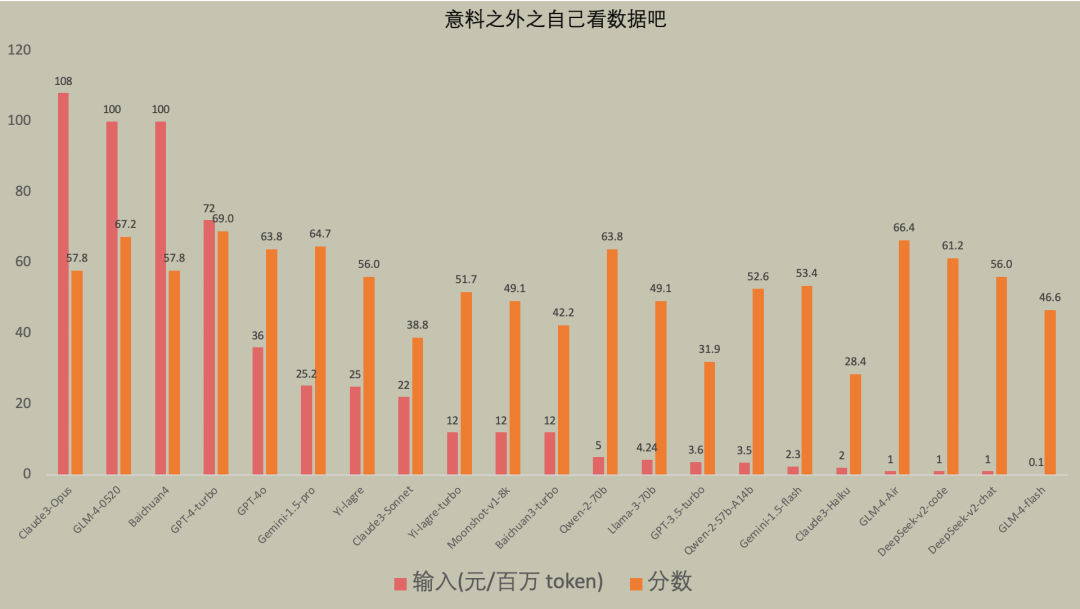
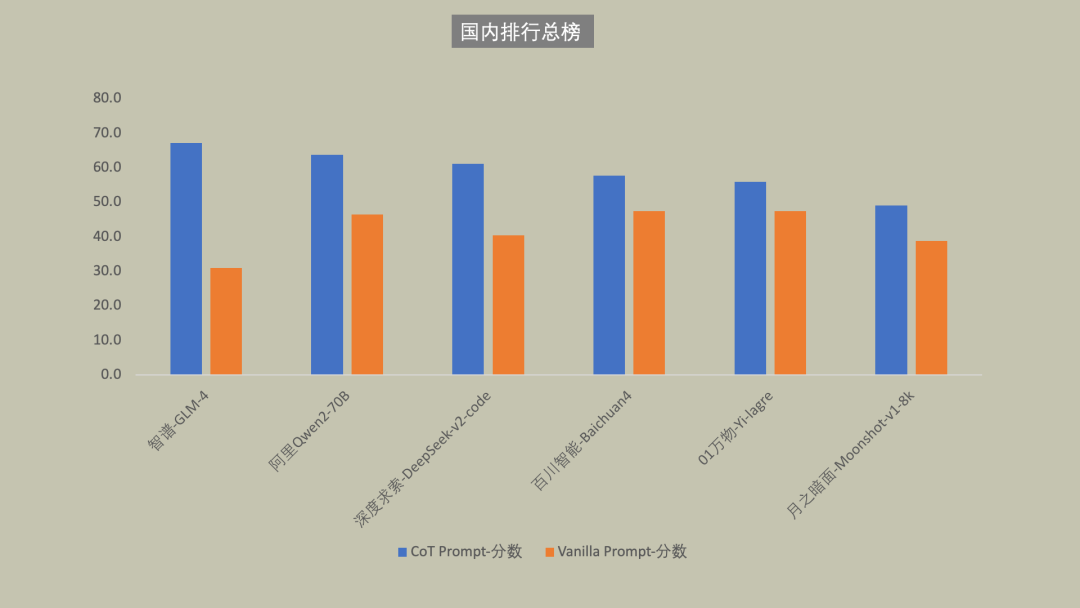
国内大模型总榜
最后两张图,代表本次测试最终结果
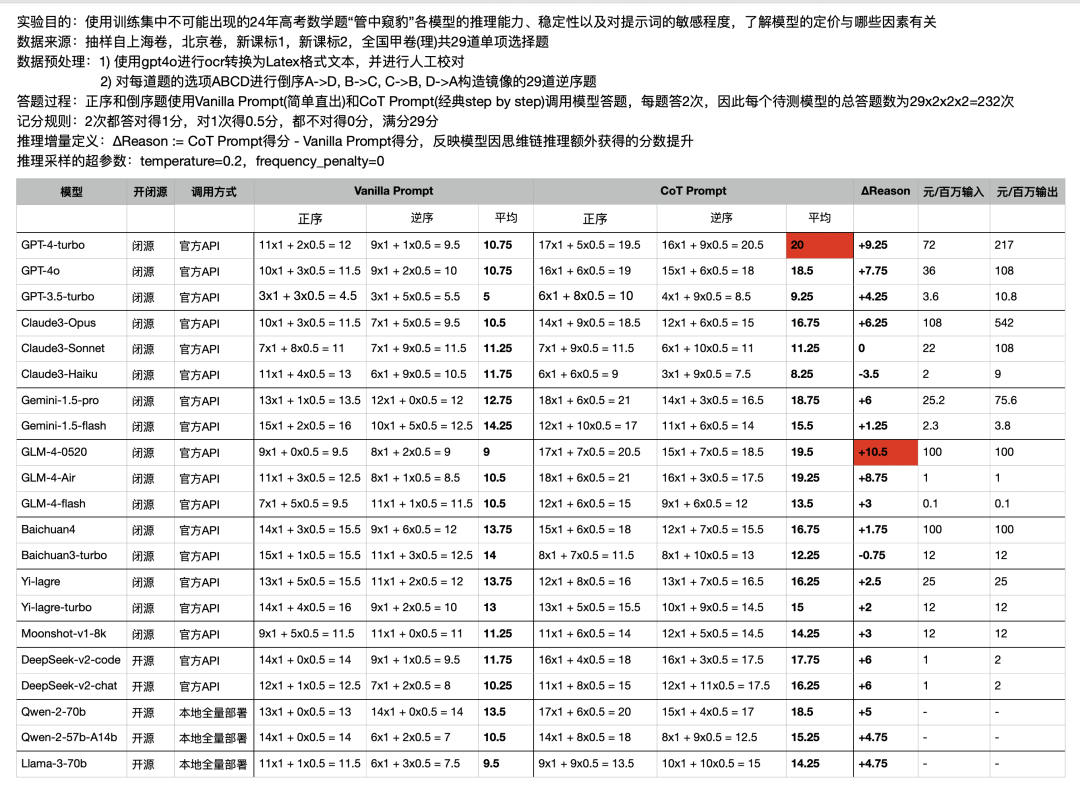
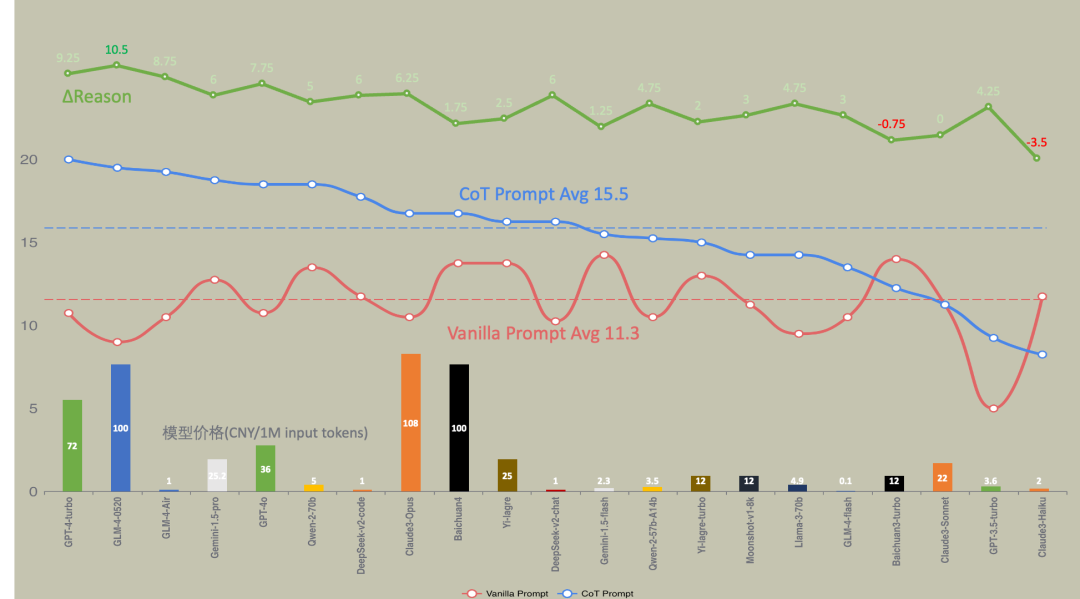
陆游博士的结论
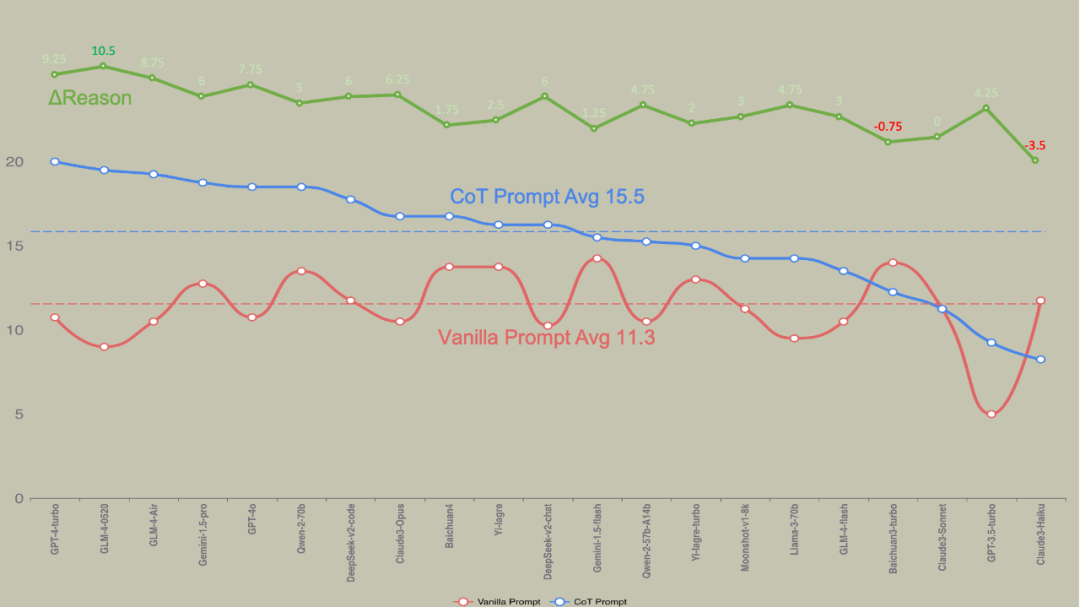
目前大模型能力已经达到独立做高考数学题的水准,使用未精调的CoT Prompt,旗舰模型可以做对约70%的单选题 国产旗舰模型在这个测试场景下已经非常接近国外旗舰模型 模型升级后并不能一致性的提高Vanilla Prompt和CoT Prompt的得分 模型升级其实是模型上限的提升,而这上限需要Prompt去激发,否则会发生贵1000倍的模型比不上便宜1000倍模型的极端情况 同厂商发布的不同模型的定价不仅与CoT Prompt得分而且与ΔReason高度正相关,ΔReason越高的模型说明模型靠推理获得的泛化能力越强 Vanilla Prompt得分甚至与模型定价(能力)有负相关的倾向 正序题和逆序题答对数的方差越大说明模型对输入的敏感程度越高 得0.5分的情况越多说明模型decode输出的空间越发散 所有的评测都难免存在片面性,这个测试也不例外。(请大家不要再留言区打架,嗷本公众号还没有留言功能) Flag:(25年将实现多模态+agent全自动评测,今年还是有不少手工,25年还要加上交卷时间(执行时间),消耗卡路里(token总费用)等硬指标。)
附录
Prompt参考

Q&A
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢