

arXiv:https://arxiv.org/abs/2403.02713
Github: https://github.com/IMNearth/CoAT
1
动机
GUI导航是指通过图形用户界面(GUI)进行系统操作和任务执行的过程。在这一过程中,智能体通过点击、滑动、输入等方式与界面上的各种控件(如按钮、图标、文本框等)进行交互,以完成特定任务或达到特定目的。现有的GUI智能体依赖于大型语言模型(LLMs)来理解用户输入的自然语言指令,通常直接输出预测的动作。这种方式忽略了屏幕操作中包含的语义信息,降低了动作预测的准确率。
为了解决这一问题,我们提出了“行动思维链”(CoAT)框架。CoAT通过结合上一步动作的详细描述、当前的屏幕描述和对所选操作的思考,增强了动作预测过程中对GUI上下文的全面理解,提升了智能体捕捉用户意图和做出一致决策的能力。我们在超大规模的多模态语言模型中验证了CoAT的上下文建模有效性。为了将这种复杂上下文建模迁移到较小的语言模型中,我们构建了一个新的由CoAT驱动数据的数据集“Android-In-The-Zoo”(AITZ)。实验结果表明,在AITZ数据集上微调一个1B模型可以达到与CogAgent-Chat-18B相当的性能。
2
方法
//Chain-of-Action-Thought (CoAT)
在手机屏幕上进行操作往往包含一系列步骤,例如首先观察屏幕上的内容,思考要点击何种页面元素、采取行动并获得结果。因此,我们定义了行动思维链(CoAT),作为理解导航过程中交互动态的框架。CoAT包括以下几个部分:
屏幕描述:当前屏幕的文本上下文,包含屏幕类型、屏幕的主要功能、屏幕上显示的主要应用程序或组件等。
操作思考:分析用户查询和当前屏幕的关联,结合历史信息推断可能的操作。
下一个操作描述:描述正在操作的UI元素或屏幕功能,形成可读的操作历史。
操作结果:描述操作的结果,通过连接当前屏幕和下一个操作与未来的观察,确保历史的连续性和一致性。
每个CoAT组件都携带有用的语义信息,可以根据使用的语言模型自由组合。
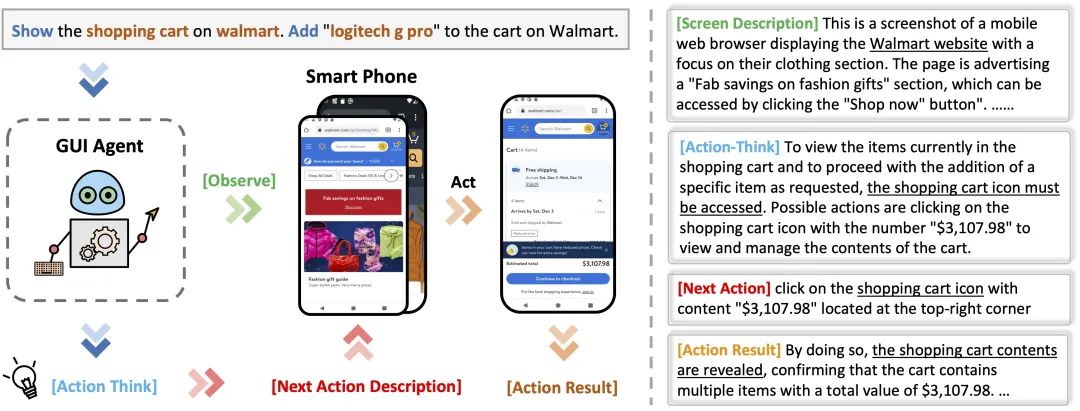
图1: CoAT的工作流程和内容组件
我们首先进行了一个验证试验,证明了所提出的CoAT框架的有效性。具体而言,我们从AITW数据集中随机抽取了50个操作序列。我们将现有的三个SOTA多模态大模型GPT-4V、Gemini-Pro-Vision和Qwen-VL-Max作为GUI智能体,并应用了不同的提示方法来预测动作。
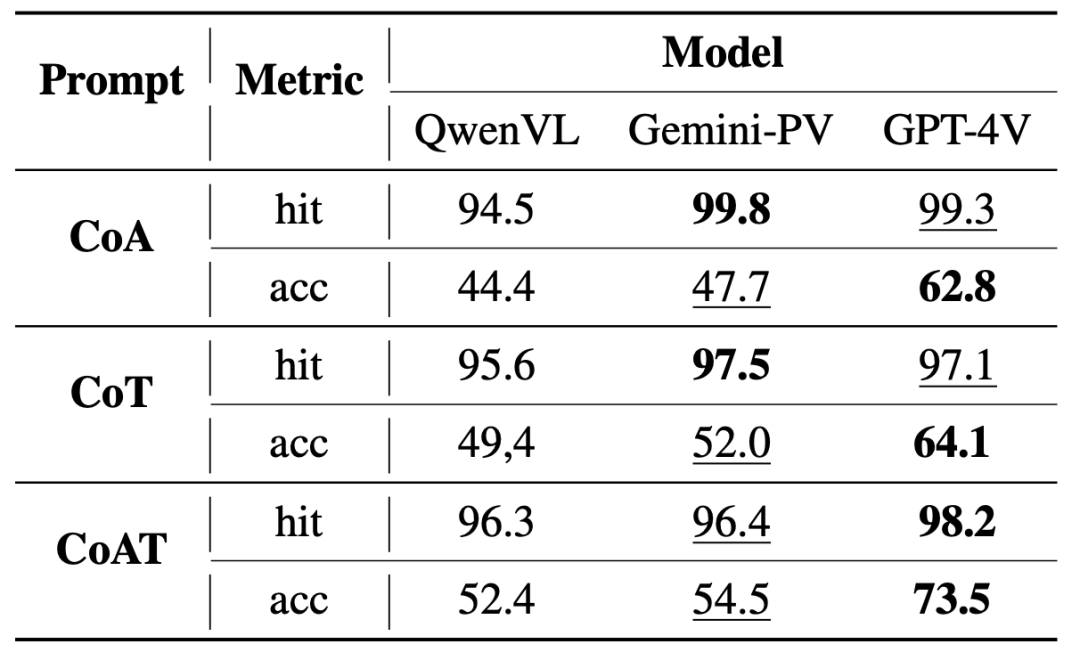
表1: 三种上下文建模方法的比较。其中hit代表格式匹配率,acc代表动作预测准确率
表1说明,使用CoAT的智能体在各项指标上均优于CoA和CoT。此外,综合性能GPT-4V表现最佳。
//Android in the Zoo (AITZ)
由于缺乏CoAT范式所捕捉到的包含底层语义的导航数据,较小的语言模型无法获得这种思维能力。因此,我们提出构建一个新的、高质量和全面的数据集来填补这一空白。“Android-In-The-Zoo”(AITZ)是第一个将页面UI元素感知与动作决策过程的认知相结合的数据集。
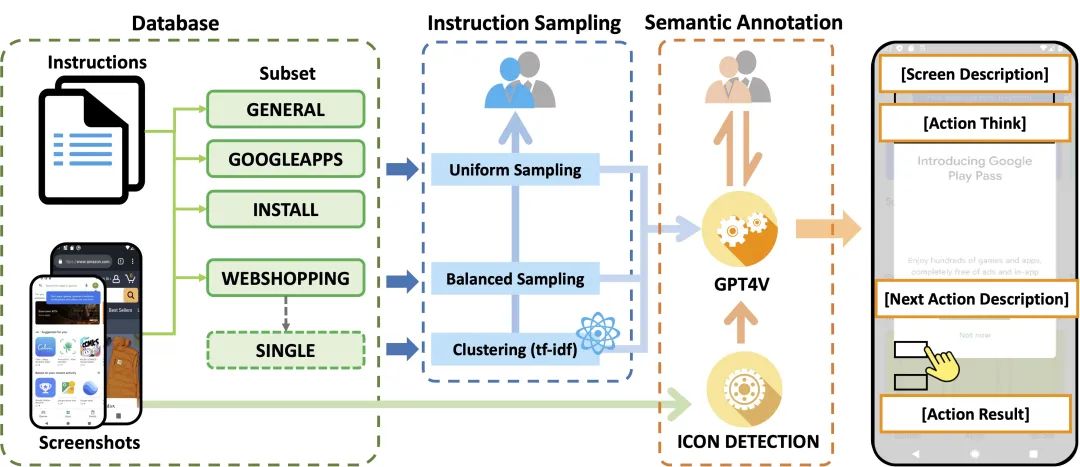
图2: AITZ数据集的收集流程。在采样过程中,人类标注者首先验证聚类结果,然后检查采样的序列是否成功完成用户指令。在标注过程中,人类标注者检查并更正GPT生成的语义描述
数据集的收集主要分为两个步骤。
指令采样:由于原始数据集AITW数据集中存在大量模版重复的指令,以及存在操作序列和指令不匹配的情况。因此,我们对指令和操作序列进行采样以减少冗余,然后使用人工标注对指令和操作序列的匹配度进行验证。
语义注释:我们采用一个人工标注与机器标注相结合的标注方法,首先让GPT-4V作为导航专家生成语义标注,然后让人类专家对GPT4V的标注进行验证。注意,由于已经检验过操作序列的正确性,因此人类专家只需要检验GPT4V的标注是否与正确的操作相一致并进行纠正。
这样收集获得的AITZ数据集包括2,504条独特指令和18,643个屏幕-操作对,覆盖了约70多个安卓应用。
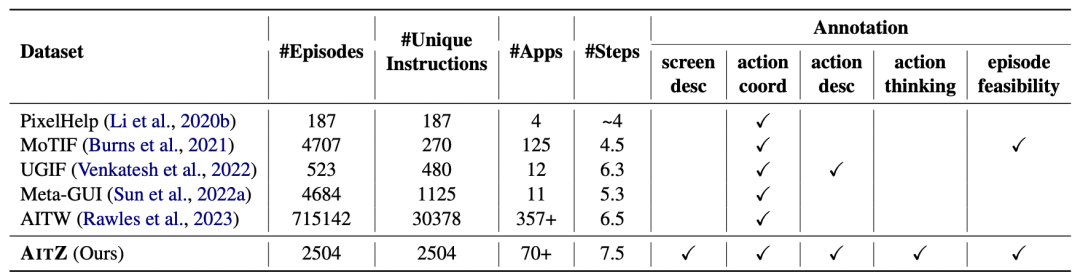
表2: AITZ与现有Android GUI数据集的比较
3
实验
我们首先进行了零样本评估,以研究直接使用AiTZ数据集提供的动作语义作为输入的效果。这里我们选择CogAgent为例,因为该模型经过GUI专项任务的预训练并在AITW数据集上进行过微调。此外,其基础语言模型CogVLM-7B应该具备一定的泛化能力。我们通过将操作思考添加到CogAgent的提示输入中,以验证CoAT的影响。
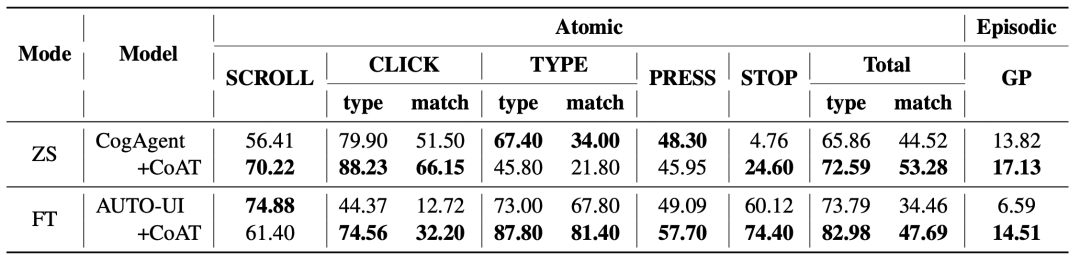
表3: CogAgent和AUTO-UI在AITZ数据集上的主要结果。ZS和FT分别是零样本和微调评估的缩写。SCROLL、CLICK、TYPE、PRESS、STOP为动作类型,Total代表五种动作类型的平均。如无特殊指明,本表格中默认指标为动作预测匹配分数(match)。对于更复杂的“CLICK”和“TYPE”动作,我们还报告了动作类型预测的准确率(type)。GP代表目标进度。
上表显示,CoAT显著提高了CogAgent整体的性能。此外,表3中的第一行和最后一行表明,通过在1B大小的模型(即AUTO-UI-base)上微调CoAT,可以获得与大语言模型相当的性能,这展示了CoAT在GUI任务中的强大潜力。
为了进一步评估CoAT各个组件的影响,我们进行了消融实验。我们将CoAT的4个组件分为“输入”和“输出”两组,表示模型训练过程中额外信息的来源。具体来说,我们将屏幕描述和前一步操作结果作为额外输入信息,因为它们不会直接帮助当前操作决策。操作思考和下一步操作描述添加到输出中,以便智能体学习这种思考过程。
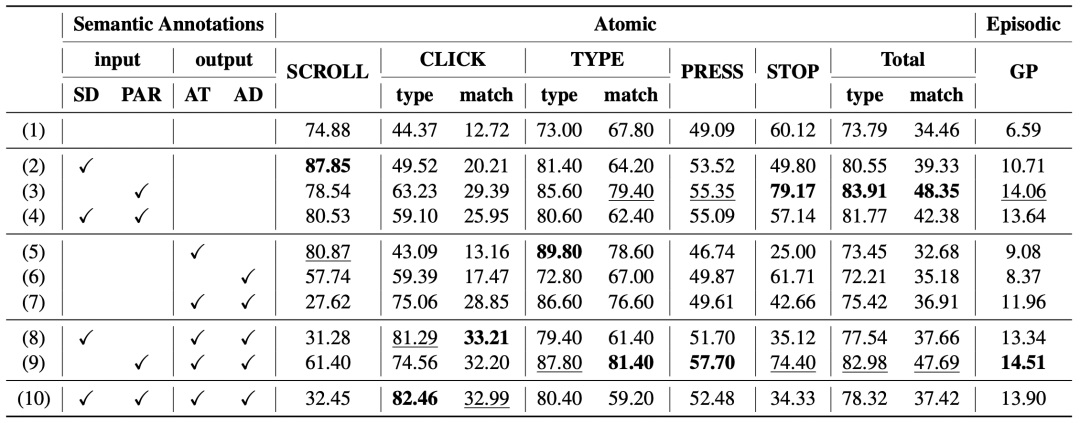
表4: 消融实验结果
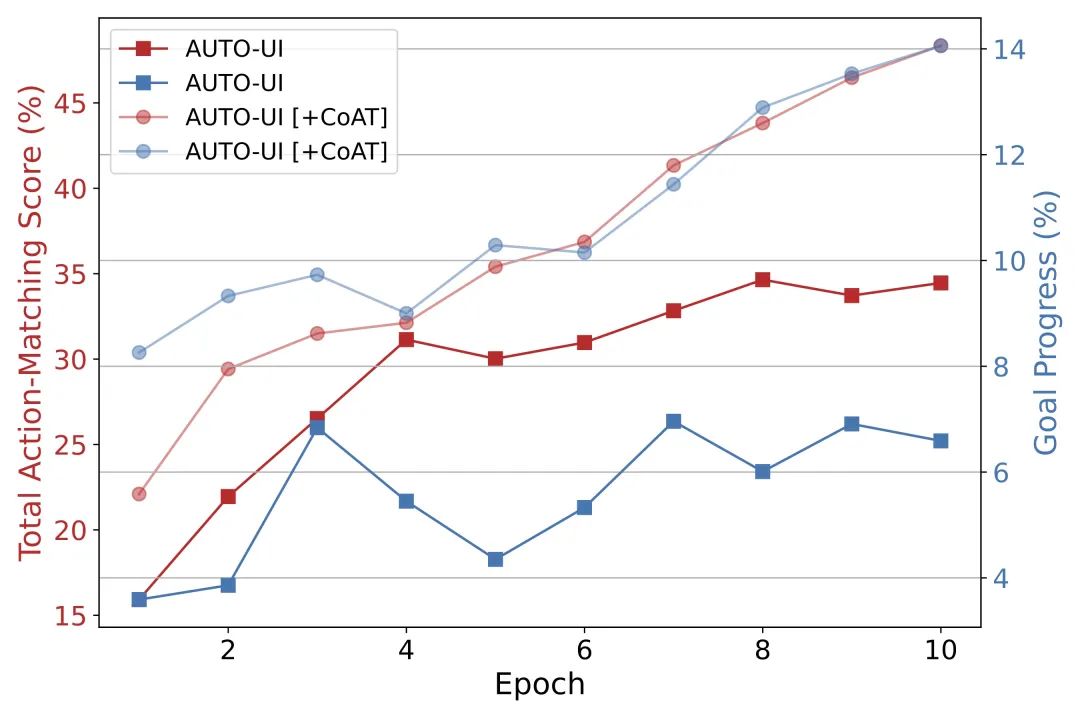
图3: 评价指标与训练轮数的关系
从表4中可以看出,前一步操作结果,特别是与操作思考和操作描述结合使用时,显著提高了AUTO-UI的整体操作预测准确性。由于决策过程的连贯性通过在输入中增加前一步操作结果得到增强,对STOP动作的预测准确率显著增加(从60.12到79.17)。实验5-7表明,在不增加额外输入的情况下,进行操作思考的学习是有挑战性的。然而,当屏幕描述和/或先前操作结果添加到输入中时,AUTO-UI的性能立即提高,尤其是在预测CLICK操作方面。这验证了这些语义注释的必要性和有效性。图3进一步说明了在我们的AITZ数据上训练能显著提高训练效率。
4
结论
我们的工作旨在提升基于LLM的GUI智能体的导航能力。通过分析人类导航过程,我们提出了行动思维链(CoAT)。我们首先验证了CoAT优于三种典型上下文建模方法。为了将CoAT的思维能力注入现有GUI智能体中,我们进一步通过人类专家和GPT-4V的合作生成了一套高质量的CoAT驱动数据,即“Android-In-The-Zoo”(AITZ)数据集。AITZ桥接了感知与认知,丰富了这一领域的细粒度数据,为GUI导航智能体的有效训练和可靠评估提供了便利。
复旦大学数据智能与社会计算实验室
Fudan DISC

点击“阅读原文”跳转至Githup
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢