

新智元报道
新智元报道
【新智元导读】Meta的GenAI团队在最新研究中介绍了Meta 3D Gen模型:可以在不到1分钟的时间内从文本直接端到端生成3D资产。
在图像生成和视频生成这两个赛道上,大模型仅用了两年多的时间就卷得如火如荼。
即使是效果堪比Sora的Gen-3、Luma等模型发布,也很难引起曾经的轰动反应。
你可能会疑惑,AI还能玩出新花样吗?
Meta放出的最新研究告诉你——能!
不管是图像还是视频,即使能做出3D效果,终究只是二维空间中的像素组成的。
Meta最近发布的3D Gen模型,则能实现1分钟内的端到端生成,从文本直出高质量3D资产。
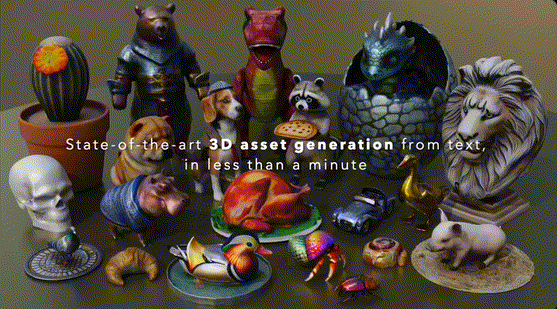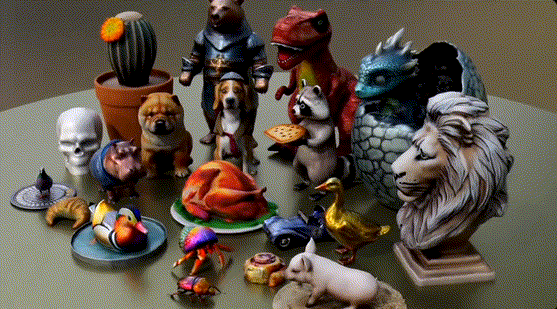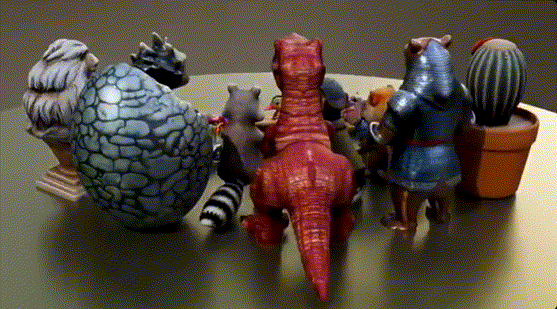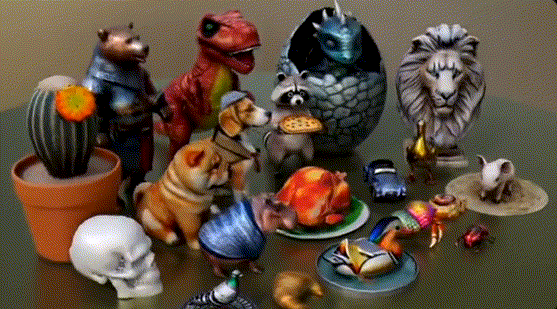
不仅纹理清晰、形态逼真自然,而且生成速度比其他替代方案加快了3-60倍。
目前,模型还没有开放试用API以及相应的代码,官方消息中也没有透露下一步的发布时间。

只能看到官方demo但没法试用,已经让很多网友心痒难耐了。
「把这些可爱的小东西3D打印出来该有多好。」

但好在,Meta放出了技术报告,让我们可以细致观摩一下技术原理。

Meta 3D Gen
在电影特效、AR/VR、视频游戏等领域中,创作3D内容是最耗时,也是最具挑战性的环节之一,需要很高的专业技能和陡峭的学习曲线。
这件事对人类困难,对AI来说也同样困难。
相比于图像、视频等形式,生产级的3D内容有更多方面的严格要求,不仅包括生成速度、艺术质量、分辨率,还包括3D网格的结构和拓扑质量、UV图结构以及纹理清晰度。
此外,3D生成还面临数据方面的挑战。
虽然有数十亿张图像和视频可供学习,但其中适合训练的3D内容量却少了3~4个数量级。因此,模型只能学习这些非3D的视觉内容,并从二维的观察中推断出三维信息。
3D Gen模型则克服了这些困难,在领域内迈出了第一步。
模型最大的亮点在于支持基于物理的渲染(PBR,physically-based rendering),这对于在应用场景中实现3D资产的重新照明非常必要。
此外,经过专业艺术家的评估,3D Gen在生成同等质量,甚至更优内容的同时,缩短了生成时间,提升了指令跟随性能。
生成出3D对象后,模型还支持对其纹理进行进一步的编辑和定制,20s内即可完成。

方法
这种更加高效的优质生成,离不开模型pipeline的精心设计。
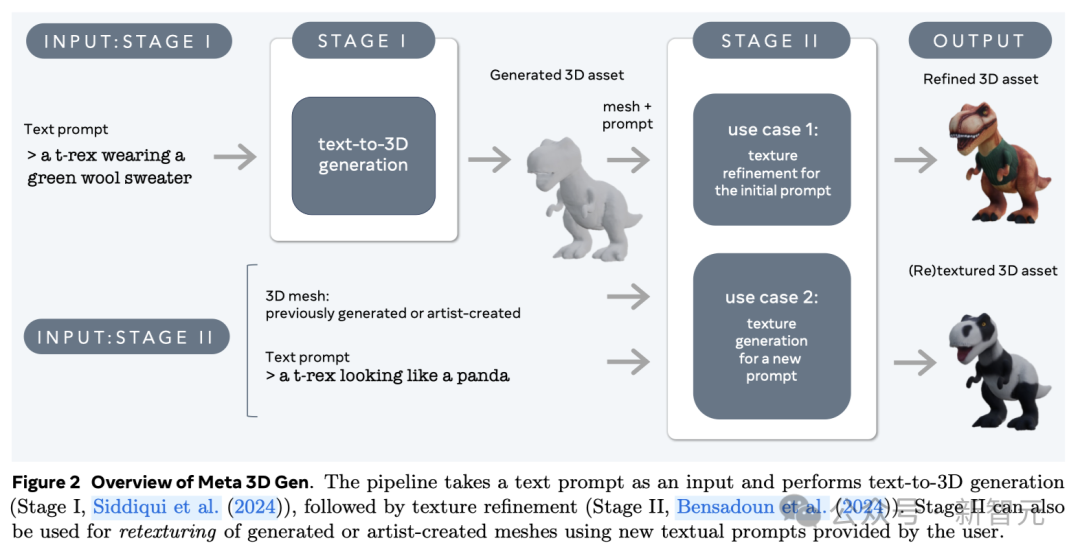
3D Gen的生成主要分为两步,由两个组件分别完成——文本到3D对象生成器AssetGen和文本到纹理生成器TextureGen。
第一阶段:3D资产生成。根据用户提供的文本提示,使用3D AssetGen模型创建初始3D资产,即带有纹理和PBR材质图的3D网格,大约花费30s。
第二阶段:纹理生成。根据第一阶段生成的3D资产和用户文本提示,使用3D TextureGen模型生成更高质量的纹理和PBR图,大约花费20s。
其中,第二阶段的TextureGen也可以单独拿出来使用。如果有一个之前生成的,或者艺术家自己创作的无纹理3D网格,提供描述外观的文本提示后,模型也能在20s左右的时间中为它从头生成纹理。
AssetGen和TextureGen这两个模型有效地结合了3D对象的三种高度互补的表示:视图空间(物体图像)、体积空间(3D形状和外观)以及UV空间(纹理)。

给定文本描述,AssetGen首先利用一个多视角、多通道版本的图像生成器生成多张图像,随后生成物体的一致视图。
据此,AssetGen中的重建网络在体积空间中提取出物体的初始版本,并进行网格提取,确立其3D形状和初始纹理。
最后,TextureGen利用视图空间和UV空间的生成结果,对纹理进行重生成,在保持指令忠实度的同时提升纹理质量。


不同于许多SOTA方法,AssetGen和TextureGen都是前馈生成器,因此能实现快速、高效的部署。
将3D生成任务以这种方式划分为两个阶段,并在同一个模型中集成对象的多个表示空间,这种pipeline的组合是Meta重要的创新。
实验证明,不仅AssetGen和TextureGen两个部件都能分别取得更好的效果,它们结合后形成的3D Gen也能以68%的胜率超过其他模型。
实验
针对文本到3D资产生成的任务,论文将3D Gen与其他公开可用的常用方法进行了对比,并从用户调研、定性实验两个方面进行了评估。
定性结果
从生产结果上直观来看,3D Gen能够应对不同范畴、不同类别物体的生成任务,而且指令跟随的忠实度甚至好过很多文生图模型。
比如让吉娃娃穿蓬蓬裙、让腊肠犬穿热狗装这样人类都很难想象的场景,3D Gen也按照要求生成了合理的结果。

生成结果的多样性也非常惊艳。比如提示模型只生成Llama(羊驼),他就能给出下图中的13种不同结果,风格、形状、纹理各异,可以说想象力很丰富了。

图6、7、8则对比了3D Gen和其他模型对同一文本提示的生成结果。
对于一些比较有挑战性的提示,3D Gen的细节效果有时逊色于Meshy v3等模型,但这涉及到一个权衡问题:要展现纹理中的高频细节,代价就是有时会出现视觉失真。

下面这个多物体的复杂场景任务中,你觉得哪个模型的表现更好?

虽然成功的案例很多,但对目前的模型来说,翻车依旧时常发生,而且每个模型都有自己独特的翻法。
比如CSM Cube经常在物体几何上出问题,前后视角不一致,或者干脆生成了「双头大猩猩」;Tripo 3D的光照效果会出现「一眼假」;Rodin Gen 1和Meshy 3.0有时缺少物体细节的渲染。
至于Meta的3D Gen,在放出来的案例中就出现了物体几何结构不完整、纹理接缝、指令不跟随(最右侧的海象没有叼烟斗)等多方面的问题。

虽然没人能在Meta的报告中战胜Meta,但被拿来当「靶子」的作者,还是站出来为自己工作辩护了一番。

用户调研
对于模型的文本到3D生成,人类评审将从两方面进行评估:提示忠实度、视觉质量。
按不同的背景,评审被分成了两组:(1)普通用户,没有3D方面的专业知识,(2)专业的3D艺术家、设计师和游戏开发者。
评估采用了DreamFusion引入的404个经过去重的文本提示,并根据内容复杂性分为三类:物体(156个),角色(106个)和物体角色组合(141个)。
每个3D生成结果都会以360度全景视频的方式呈现给评审者,不同模型进行分别测试或者随机的A/B测试。
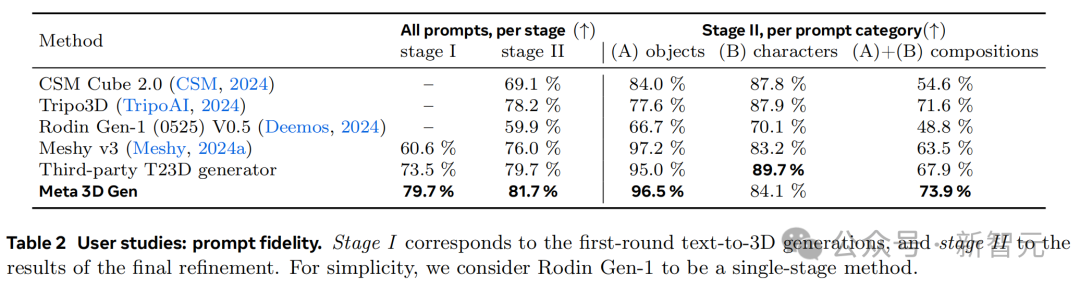
表2展示了提示忠实度方面的的评估结果。在这一指标上,3DGen在两个阶段的得分都优于其他行业方法,紧随其后的是T23D生成器。
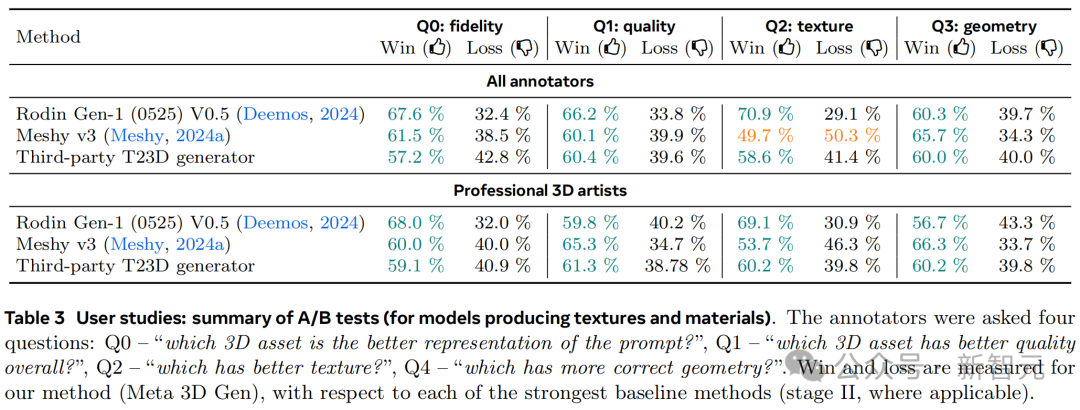
如表3所示,A/B测试中还添加了对几何视觉质量以及纹理细节的评测。
作者发现,普通用户更倾向于喜欢那些纹理更锐利、生动、逼真且细节详实的3D结果,但对较明显的纹理和几何伪影不是很关注。专业的3D艺术家则会更重视几何与纹理的准确性。
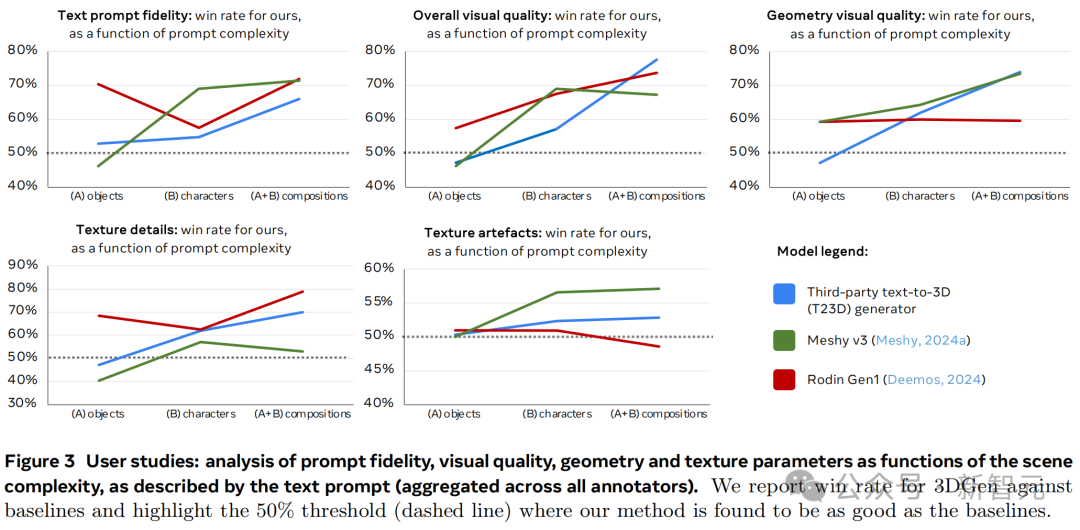
在图3中,作者分析了视觉质量、几何、纹理细节和纹理伪影的表现率等指标,如何随着文本提示描述的场景复杂度发生变化。
图表显示,虽然基准模型在简单提示下的表现与3D Gen相当,甚至更优,但随着提示复杂度逐渐增加,3D Gen开始反超,这也与图7描述的定型结果一致。
结论
作为一个统一的流程,3DGen整合了Meta的基础生成模型,用于文本到3D生成,具备纹理编辑和材料生成能力。
通过结合AssetGen和TextureGen的优势,3DGen能够在不到一分钟的时间内根据文本提示生成高质量的3D对象。
在专业3D艺术家的评估中,3DGen的输出在大多数情况下更受青睐,尤其是在复杂提示下,而且速度快3到60倍。
虽然Meta目前对AssetGen和TextureGen的整合比较直接,但它开创了一个非常有前景的研究方向,基于两个方面:(1)在视图空间和UV空间中的生成,(2)纹理和形状生成的端到端迭代。
如同Sora的出现会深刻影响短视频、电影、流媒体等众多行业一样,3D Gen也具有同样巨大的潜力。
毕竟,小扎还是心心念念他的元宇宙。而AI驱动的3D生成,对于在元宇宙中构建无限大的虚拟世界也非常重要。
https://ai.meta.com/research/publications/meta-3d-gen/?utm_source=threads&utm_medium=organic_social&utm_content=carousel&utm_campaign=research



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢