

经过一些实验,我们对 Transformers 智能体构建智能体系统的性能印象深刻,因此我们想看看它有多好!我们使用一个
用库构建的代码智能体 https://github.com/aymeric-roucher/GAIA
什么是智能体?
一句话: 智能体是基于大语言模型 (LLM) 的系统,可以根据当前用例的需要调用外部工具,也可以不调用,并根据 LLM 的输出进行后续步骤的迭代。工具可以包括从 Web 搜索 API 到 Python 解释器的任何东西。
LLM judge https://hf.co/papers/2310.17631
下面是两个执行
检索增强生成 https://hf.co/learn/cookbook/en/rag_zephyr_langchain

智能体系统赋予大语言模型 (LLM) 超能力。详情请阅读
我们早期关于 Transformers Agents 2.0 发布的博客 https://hf.co/blog/agents
GAIA https://hf.co/datasets/gaia-benchmark/GAIA
以下是一个棘手问题的例子:
你可以看到这个问题涉及几个难点:
以约束格式回答。 多模态能力,需要从图像中读取水果。 需要收集多个信息,有些信息依赖于其他信息: 图片中的水果 用作《最后的航程》漂浮道具的海洋班轮的身份 上述海洋班轮 1949 年 10 月的早餐菜单 上述内容迫使正确的解决路径使用几个链式步骤。
解决这个问题需要高水平的计划能力和严格的执行力,这恰恰是 LLM 难以应对的两个领域。
因此,它是测试智能体系统的绝佳测试集!
在 GAIA 的
公开排行榜 https://hf.co/spaces/gaia-benchmark/leaderboard
下面让我们继续 🥊

我们使用了三种主要工具来解决 GAIA 问题:
a. 网页浏览器
对于网页浏览,我们主要复用了Browser 类,以及几个用于网页导航的工具,如 visit_page 、page_down 或 find_in_page 。这个工具返回当前视口的 Markdown 表示。与其他解决方案 (如截屏并使用视觉模型) 相比,使用 Markdown 极大地压缩了网页信息,这可能会导致一些遗漏。然而,我们发现该工具整体表现良好,且使用和编辑都不复杂。
Autogen 团队的提交 https://github.com/microsoft/autogen/tree/gaia_multiagent_v01_march_1st/samples/tools/autogenbench/scenarios/GAIA/Templates/Orchestrator
注意: 我们认为,将来改进这个工具的一个好方法是使用 selenium 包加载页面,而不是使用 requests。这将允许我们加载 JavaScript (许多页面在没有 JavaScript 的情况下无法正常加载) 并接受 cookies 以访问某些页面。
b. 文件检查器
许多 GAIA 问题依赖于各种类型的附件文件,如 .xls 、.mp3 、.pdf 等。这些文件需要被正确解析。我们再次使用了 Autogen 的工具,因为它们非常有效。
非常感谢 Autogen 团队开源他们的工作。使用这些工具使我们的开发过程加快了几周!🤗
c. 代码解释器
我们不需要这个工具,因为我们的智能体自然会生成并执行 Python 代码: 详见下文。
如
考虑他们论文中给出的这个例子:
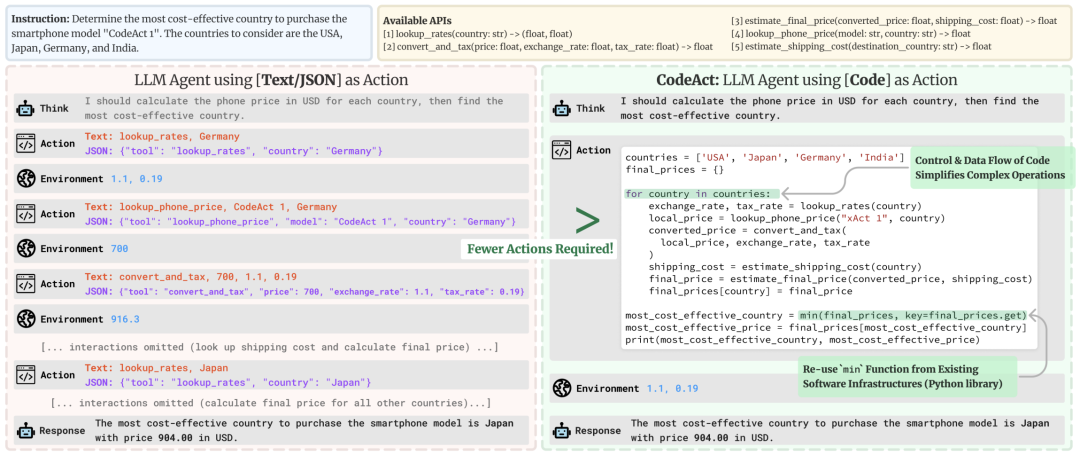
它突出了使用代码的几个优点:
代码操作比 JSON 简洁得多。 需要运行 4 个并行的 5 个连续操作流?在 JSON 中,你需要生成 20 个 JSON blob,每个在其独立的步骤中; 而在代码中,这只需 1 步。 平均而言,论文显示代码操作需要比 JSON 少 30% 的步骤,这相当于生成的 tokens 减少了 30%。由于 LLM 调用通常是智能体系统的主要成本,这意味着你的智能体系统运行成本减少了约 30%。 代码允许重用常见库中的工具 使用代码在基准测试中表现更好,原因有二: 它是一种更直观的表达操作的方式 LLM 的训练数据中有大量代码,这可能使它们在编写代码方面比编写 JSON 更流畅。
我们在
在我们最近的构建 Transformers 智能体的实验中,我们还观察到了一些额外的优势:
在代码中存储一个命名变量要容易得多。例如,需要存储一个由工具生成的岩石图像以供以后使用? 在代码中没有问题: 使用 “rock_image = image_generation_tool(“A picture of a rock”)” 将变量存储在你的变量字典中的 “rock_image” 键下。之后 LLM 可以通过再次引用 “rock_image” 来在任何代码块中使用其值。 在 JSON 中,你需要做一些复杂的操作来创建一个名称来存储这个图像,以便 LLM 以后知道如何再次访问它。例如,将图像生成工具的任何输出保存为 “image_{i}.png”,并相信 LLM 稍后会理解 image_4.png 是内存中之前调用工具的输出?或者让 LLM 也输出一个 “output_name” 键来选择存储变量的名称,从而使你的操作 JSON 的结构复杂化? 智能体日志可读性大大提高。
LLM 生成的代码直接执行可能非常不安全。如果你让 LLM 编写和执行没有防护措施的代码,它可能会产生任何幻觉: 例如,它可能认为所有你的个人文件需要被《沙丘》的传说副本覆盖,或者认为你唱《冰雪奇缘》主题曲的音频需要分享到你的博客上!
所以对于我们的智能体,我们必须使代码执行安全。通常的方法是自上而下: “使用一个功能齐全的 Python 解释器,但禁止某些操作”。
为了更安全,我们选择了相反的方法, 从头开始构建一个 LLM 安全的 Python 解释器。给定 LLM 提供的 Python 代码块,我们的解释器从 Python 模块
Python ast 库文档 https://docs.python.org/3/library/ast.html 抽象语法树表示 https://en.wikipedia.org/wiki/Abstract_syntax_tree
例如,一个 import 语句首先会检查导入是否在用户定义的 authorized_imports 列表中明确提及: 如果没有,则不执行。我们包括了一份默认的 Python 内置标准函数列表,如 print 和 range 。任何在此列表之外的内容都不会执行,除非用户明确授权。例如, open (如 with open("path.txt", "w") as file: ) 不被授权。
遇到函数调用 ( ast.Call ) 时,如果函数名是用户定义的工具之一,则工具会被调用并传递调用参数。如果是先前定义并允许的其他函数,则正常运行。
我们还做了几个调整以帮助 LLM 使用解释器:
我们限制执行操作的数量以防止 LLM 生成的代码中出现无限循环: 每次操作时计数器增加,如果达到一定阈值则中断执行。 我们限制打印输出的行数,以避免用垃圾填满 LLM 的上下文长度。例如,如果 LLM 读取一个 100 万行的文本文件并决定打印每一行,那么在某个点上这个输出会被截断,以防止智能体内存爆炸。
网页浏览是一项非常上下文丰富的活动,但大多数检索到的上下文实际上是无用的。例如,在上面的 GAIA 问题中,唯一重要的信息是获取画作《乌兹别克斯坦的刺绣》的图像。周围的内容,比如我们找到它的博客内容,通常对解决更广泛的任务无用。
为了解决这个问题,使用多智能体步骤是有意义的!例如,我们可以创建一个管理智能体和一个网页搜索智能体。管理智能体应解决高级任务,并分配具体的网页搜索任务给网页搜索智能体。网页搜索智能体应仅返回有用的搜索结果,以避免管理智能体被无用信息干扰。
我们在工作流程中创建了这种多智能体协调:
顶级智能体是一个
ReactCodeAgent 。它天生处理代码,因为它的操作是用 Python 编写和执行的。它可以访问以下工具:informational_web_searchpage_downfind_in_page…… (完整列表 在这行 )file_inspector读取文本文件,带有一个可选的question参数,以便根据内容只返回对特定问题的答案,而不是整个文件内容。visualizer专门回答有关图像的问题。search_agent浏览网页。更具体地说,这个工具只是一个网页搜索智能体的包装器,这是一个 JSON 智能体 (JSON 在严格的顺序任务中仍然表现良好,比如网页浏览,其中你向下滚动,然后导航到新页面,等等)。这个智能体可以访问网页浏览工具:ReactCodeAgent https://hf.co/docs/transformers/main/en/main_classes/agent#transformers.ReactCodeAgent 完整工具列表 https://github.com/aymeric-roucher/GAIA/blob/a66aefc857d484a051a5eb66b49575dfaadff266/gaia.py#L107
将智能体作为工具嵌入是一种简单的多智能体协调方法,但我们想看看它能走多远——结果它能走得相当远!
目前有
我们已知或可以从上下文中推导出的事实摘要和需要发现的事实 基于新观察和上述事实摘要,逐步制定解决任务的计划
可以调整参数 N 以在目标用例中获得更好的性能: 我们为管理智能体选择了 N=2,为网页搜索智能体选择了 N=5。
一个有趣的发现是,如果我们不提供计划的先前版本作为输入,得分会提高。直观的解释是,LLM 通常对上下文中任何相关信息有强烈的偏向。如果提示中存在先前版本的计划,LLM 可能会大量重复使用它,而不是在需要时重新评估方法并重新生成计划。
然后,将事实摘要和计划用作额外的上下文来生成下一步操作。规划通过在 LLM 面前展示实现目标的所有步骤和当前状态,鼓励 LLM 选择更好的路径。
我们在验证集上得到了 44.2% 的成绩: 这意味着 Transformers 智能体的 ReactCodeAgent 现在总体排名第一,比第二名高出 4 分!在测试集中,我们得到了 33.3% 的成绩,排名第二,超过了微软 Autogen 的提交,并且在硬核的第 3 级问题中获得了最高平均分。
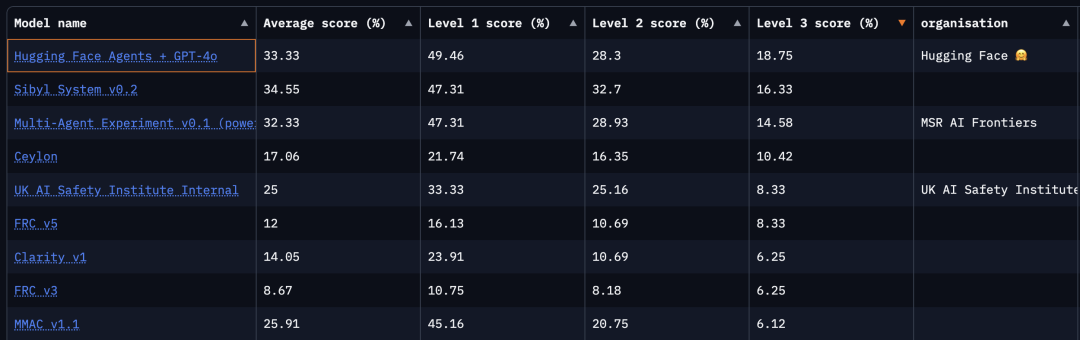
这是一个支持
据我们所知,LangChain 和 LlamaIndex 不支持代码操作,微软的 Autogen 对代码操作有一些支持 (在
希望你喜欢阅读这篇博客!工作才刚刚开始,我们将继续改进 Transformers Agents,从多个方面入手:
LLM 引擎: 我们的提交使用了 GPT-4o (不幸的是), 没有任何微调。我们的假设是,使用经过微调的 OS 模型可以消除解析错误,并获得更高的分数! 多智能体协调: 我们的协调方式较为简单,通过更无缝的协调,我们可能会取得更大的进展! 网页浏览器工具: 使用 selenium包,我们可以拥有一个通过 cookie 横幅并加载 JavaScript 的网页浏览器,从而读取许多当前无法访问的页面。进一步改进规划: 我们正在进行一些消融测试,采用文献中的其他选项,看看哪种方法效果最好。我们计划尝试现有组件的替代实现以及一些新组件。当我们有更多见解时,会发布我们的更新!
请在未来几个月关注 Transformers Agents!🚀
现在我们已经建立了智能体的内部专业知识,欢迎随时联系我们的用例,我们将很乐意提供帮助!🤝
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢