

AI 崛起,能够自主规划并执行多个步骤的 Agents,正成为用户的接口,也成为开发者的核心着力点。
近期美国风投 Madrona 合伙人 John Turow 发表了一篇行业洞察《The Rise of AI Agent Infrastructure》,分享了 agent 领域的观察和思考,他谈到尽管当前 Agent 存在明显局限,但丝毫不影响 Agent 激增的势头,并推动着新的基础设施不断发展。本文希望通过盘点文章中出现的项目,窥探 Agent 基础设施发展现状以及突出的项目情况。
Agent 领域的研究进展可观,在一些技术细节上有了初步共识。
从 MRKL、ReAct、BabyAGI 和 AutoGPT 等工作开始,开发者们意识到链式的提示和响应可以使大模型将任务拆解成小任务并执行;
LangChain、Griptap 等框架展示了 Agents 通过代码与 API 交互的能力。Toolformer 和 Goriila 等研究表明,基础模型可以有效使用 API。
微软(autogen)、斯坦福(AgentSims)和腾讯的研究里揭示了 Agents 协同工作能带来比单 Agent 工作更好的效果。
不可否认的说,今天的 Agents 还有很多局限性,例如经常出错、需要指导,在带宽、成本、延迟和用户体验上都还有很大的优化空间。这些局限反映了 LLM 本身与基础设施的局限性,开发者们努力通过工程能力来弥补这一点,并随之加速着 Agents 基础设施的搭建。

01
支撑 Agents 的基础设施
在 AI Agents 基础设施的早期时代,多数 Agents 是直接构建完成的。通常需要用于管理 agent 的云主机、存储记忆与状态的数据库、从外部来源获取上下文的连接器,以及用于调用外部 API 的能力。
 早期 AI Agent Infra 情况
早期 AI Agent Infra 情况
在当前,我们仍处于手工制作 Agents 的时代。对开发人员来说,短期内最有效的方式是构建一个基础设施,满足开发人员手工制作 Agents 网络的需求。随着时间推移,前沿模型将引导更多的工作流程,开发人员可以专注于产品和数据。
有人说,在模型成熟之前,构建应用仿佛在流沙上搭建城堡,而这些基础设施可能为应用或代理创建者提供了一层缓冲带,用于灵活适配并保持底层基础设施的相对稳定和持续迭代。

AI Agent Infra 现状
整体来说,目前 AI Agent 技术栈分为平台、记忆、规划与编排、执行和应用 5 个板块,我们将通过后文逐一介绍。
AI Agent 分层概念图
02
平台层
Agent 开发框架
开发框架是用于构建、部署和管理 agent 综合平台。提供模块化的组件、集成接口和工作流设计,简化了开发者创建复杂AI应用的过程。支持数据处理、任务调度、上下文管理等功能,帮助实现高效、安全和可扩展的 AI 解决方案。
LangChain
LangChain 是一个围绕 LLM 构建的框架,适用于构建聊天机器人、生成式问答( GQA ) 、摘要等应用。
优势:多语言支持、模块化设计、丰富的组件和集成结构、完善的生态系统;
劣势:学习曲线陡峭、依赖外部 AI 服务和 API,可能增加集成和维护成本;
适合:多语言支持和模块化设计的应用开发;
LlamaIndex
LlamaIndex 前身为 GPT-Index,是一个创新的数据框架,旨在简化外部知识库和大型语言模型的集成,包括各种文件格式,例如 PDF 和 PowerPoint,以及 Notion 和 Slack 等应用程序,甚至 Postgres 和 MongoDB 等数据库。
 LlamaIndex
LlamaIndex
优势:数据检索方面深度优化、支持多种数据结构;
劣势:功能单一、社区和资源支持相对较少;
适合:数据索引和检索优化场景;
Semantic Kernel
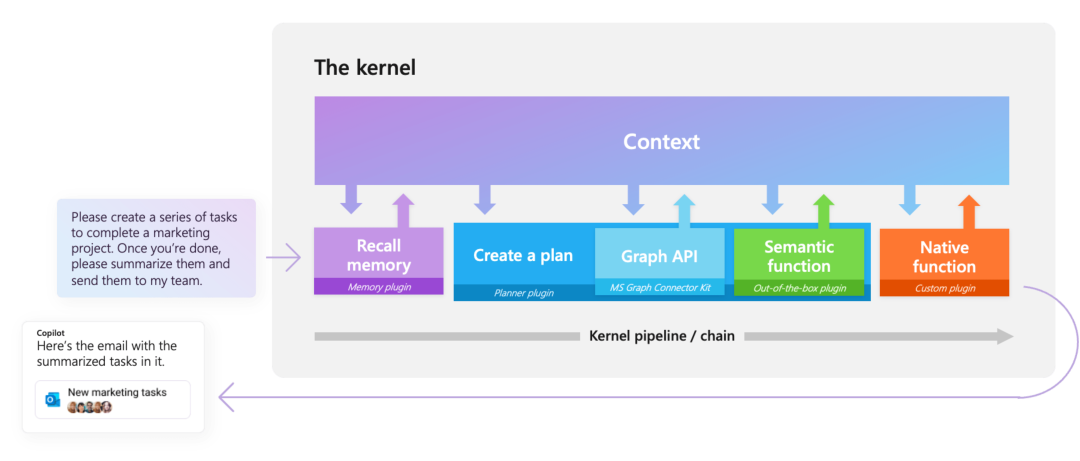
Semantic Kernel 是一个集成了 OpenAI、Azure OpenAI、Huggingface的SDK,特别之处在于它能够自动与 AI 协调插件,借助 Semantic Kernel 规划器,实现用户独特目标的计划。
Semantic Kernel
优势:企业级支持、强大的自动化和扩展性,通过插件和计划生成器执行计划;
劣势:初始设置复杂、依赖微软生态;
适合:企业级应用,需高度可扩展性和稳定性的场景;
早期 AI Agent Infra 情况
在当前,我们仍处于手工制作 Agents 的时代。对开发人员来说,短期内最有效的方式是构建一个基础设施,满足开发人员手工制作 Agents 网络的需求。随着时间推移,前沿模型将引导更多的工作流程,开发人员可以专注于产品和数据。
有人说,在模型成熟之前,构建应用仿佛在流沙上搭建城堡,而这些基础设施可能为应用或代理创建者提供了一层缓冲带,用于灵活适配并保持底层基础设施的相对稳定和持续迭代。
AI Agent Infra 现状
整体来说,目前 AI Agent 技术栈分为平台、记忆、规划与编排、执行和应用 5 个板块,我们将通过后文逐一介绍。
AI Agent 分层概念图
02
平台层
Agent 开发框架
开发框架是用于构建、部署和管理 agent 综合平台。提供模块化的组件、集成接口和工作流设计,简化了开发者创建复杂AI应用的过程。支持数据处理、任务调度、上下文管理等功能,帮助实现高效、安全和可扩展的 AI 解决方案。
LangChain
LangChain 是一个围绕 LLM 构建的框架,适用于构建聊天机器人、生成式问答( GQA ) 、摘要等应用。
优势:多语言支持、模块化设计、丰富的组件和集成结构、完善的生态系统;
劣势:学习曲线陡峭、依赖外部 AI 服务和 API,可能增加集成和维护成本;
适合:多语言支持和模块化设计的应用开发;
LlamaIndex
LlamaIndex 前身为 GPT-Index,是一个创新的数据框架,旨在简化外部知识库和大型语言模型的集成,包括各种文件格式,例如 PDF 和 PowerPoint,以及 Notion 和 Slack 等应用程序,甚至 Postgres 和 MongoDB 等数据库。
LlamaIndex
优势:数据检索方面深度优化、支持多种数据结构;
劣势:功能单一、社区和资源支持相对较少;
适合:数据索引和检索优化场景;
Semantic Kernel
Semantic Kernel 是一个集成了 OpenAI、Azure OpenAI、Huggingface的SDK,特别之处在于它能够自动与 AI 协调插件,借助 Semantic Kernel 规划器,实现用户独特目标的计划。
Semantic Kernel
优势:企业级支持、强大的自动化和扩展性,通过插件和计划生成器执行计划;
劣势:初始设置复杂、依赖微软生态;
适合:企业级应用,需高度可扩展性和稳定性的场景;
Griptape
Griptape 是一个模块化 Python 框架,用于构建 AI 驱动的应用程序,包含结构、记忆、任务、工具等多个模块。
优势:结构化工作流确保操作的可预测性和可靠性、模块化设计、安全和性能优化好;
劣势:初始学习曲线较陡、社区和资源支持较少;
适合:构建复杂 AI 工作流和代理,注重可预测性、安全性和性能的场景;
Agent 托管
Agent Hosting 是指在服务器或云基础设施上部署和运行 AI Agent。托管这些代理需要提供所需的计算资源、安全性和拓展性,以及能够高效可靠的运行。
Ollama,是这个方向最受关注的项目之一。提供了一整套用于下载、运行和管理 LLMs 的工具和服务,用户可以在本地设备上高效部署和操作 agent。适合需要快速部署和管理 AI 服务的中小型企业和独立开发者。
LangServe,将 AI 链(模型和工作流)作为 REST API 进行部署,简化了将复杂 AI 模型集成到生成环境中的过程,提供稳定可拓展的 API 接口。适用于需要将 AI 功能通过 API 提供服务的企业和应用。
E2B,开源的安全云环境,专门为 AI 应用和 AI Agent 提供运行时环境。它通过提供隔离的沙箱环境,使 AI 代理和应用能够在云中安全地执行代码。适合用于构建和部署需要安全运行环境的 AI 代理和应用,特别是在代码执行和数据处理方面。
Agent 评估
用于评估 AI Agent 性能和质量的工具。通常通过 Agent 响应的准确性、检索数据与问题的相关性、响应的性能、安全性和用户反馈等方式来进行评估。
AgentOps 和 BrainTrust强调全生命周期的代理管理和评估,注重自动化和安全性。
Context专注于对话系统的评估,提升用户体验和对话质量。
LangSmith 和 LangFuse ,提供了全面的评估和调试工具,适用于需要详细追踪和分析 LLM 应用的团队。
WhyLabs强调实时监控和异常检测,适用于需要确保模型在生产环境中稳定运行的场景。
 LangSmith
LangSmith
Developer Tools
Developer Tools 提供了多样化的解决方案,帮助开发者高效地创建、管理和优化 AI Agent。无论是全面自动化的开发助手(Morph)、分步编程和调试工具(FlowPlay AI),还是支持自然语言编程的创新 IDE(Wordware),这些工具都为不同需求和场景提供了有力支持。
03
记忆层
个性化(记忆)
指根据用户的历史行为、偏好和特定需求,动态调整和定制 AI 代理的响应和功能。这有助于提升用户体验,使得 AI 代理更具相关性和响应性。
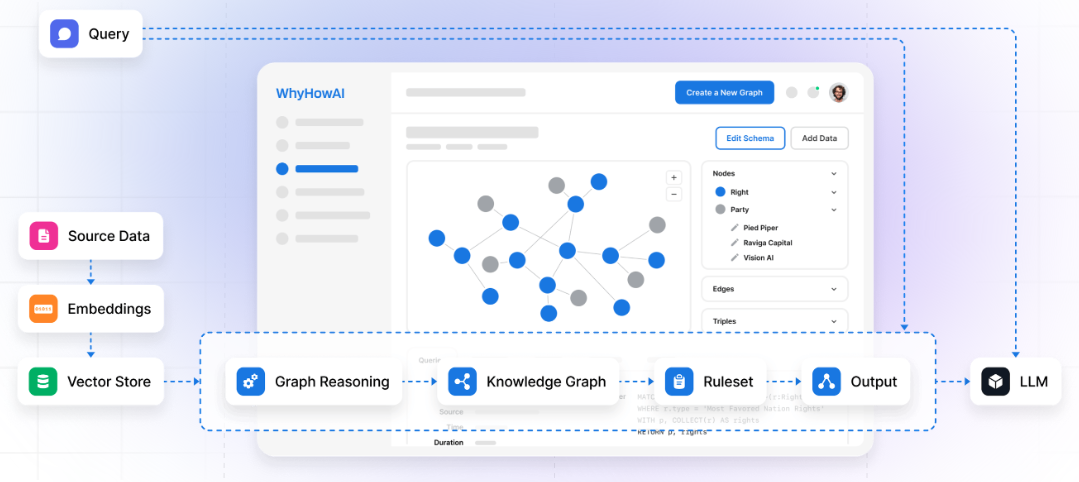
WhyHowAI:提供个性化推荐和响应优化。借助 WhyHow,开发人员可以自动创建知识图谱并将其与现有工作流程集成,构建有效的 RAG 解决方案。
Cognee:通过分析用户交互数据,提供个性化服务。
Graphlit:利用用户数据进行个性化推荐。
LangMem:专注于个性化记忆功能,使 AI 代理能够记住用户的偏好和历史交互。
MemGPT:结合 GPT 模型进行个性化响应生成。MemGPT 代表 Memory-GPT,是一种旨在通过引入更先进的内存管理方案来提高大型语言模型 (LLM) 性能的系统,有助于克服固定上下文窗口带来的挑战。
 WhyHowAI
WhyHowAI
存储
存储是指为 Agent 提供高效、可靠的数据存储解决方案。这些存储系统需要能够处理大量的数据,并支持快速的读写操作,以确保 AI 模型的高效运行。
Pinecone:专注于高性能的向量数据库,支持快速的数据检索。
Chroma:提供高效的数据存储解决方案,开源的向量数据库,专为AI和嵌入式应用设计。
Weaviate:开源的向量数据库,支持基于内容的检索和存储。
MongoDB:流行的 NoSQL 数据库,提供灵活的存储和检索功能。
上下文(Context)
指 AI Agent 能够理解和利用对话或任务中的上下文信息,以提供更加准确和相关的响应。这一层次的技术确保了 Agent 能够保持连贯性,并理解更复杂的用户需求。
Unstructure:开源项目,致力于提供强大的上下文管理功能,使 AI 代理能够理解和利用对话或任务中的上下文信息,从而提供更加连贯和智能的响应。
04
规划和编排层
持久化
数据在系统长期保存和可用性,这包括将重要数据(如用户交互、任务状态和执行日志)安全地保存到数据库或其他存储介质,以便在需要时能够可靠地检索和使用。
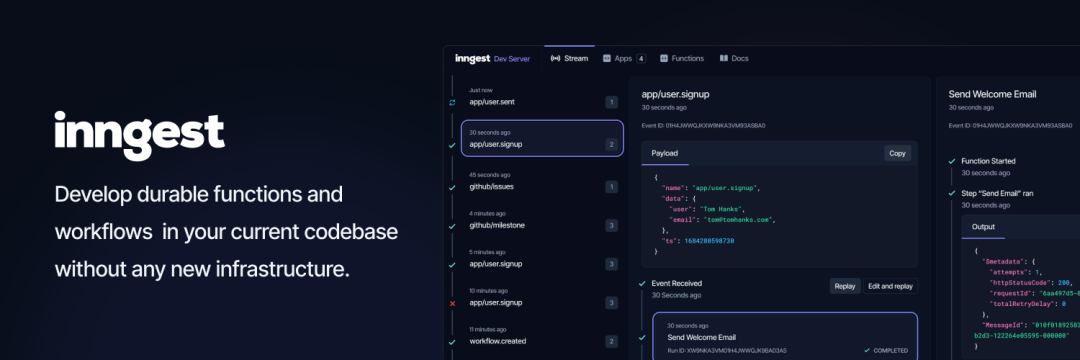
Inngest:事件驱动的持久化工作流引擎,支持在任何平台上运行。提供 SDK 在现有代码库中编写持久函数和工作流,可通过 HTTP 端点进行调用,无需额外的基础设施管理。该项目获得了 a16z 领投的 610 万美金。
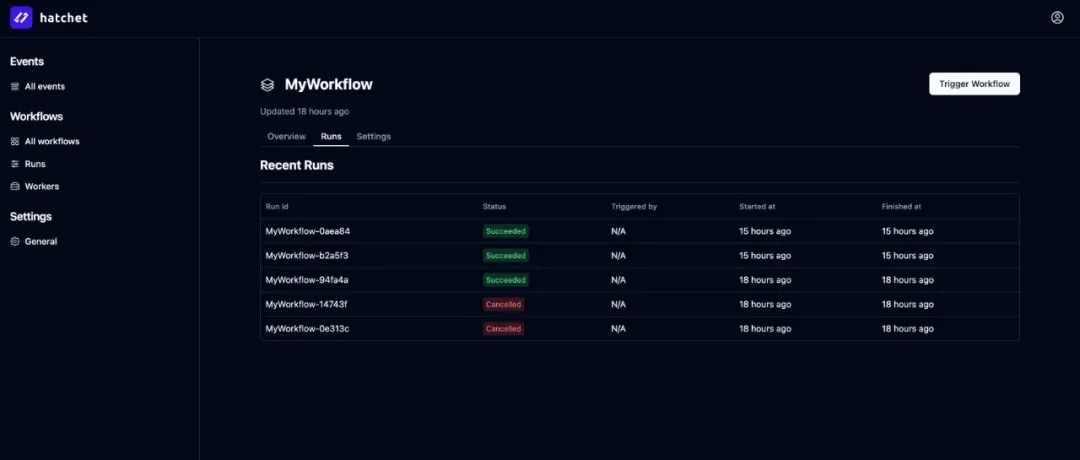
Hatchet:一个端到端的任务编排平台,支持分布式、容错任务队列,旨在解决并发、公平性和速率限制等扩展问题,支持复杂任务编排和可视化 DAG(有向无环图)工作流设计,以确保工作流的组织和可预测性。YC W24 布局了该项目,其愿景是在后台使用异步任务运行缓慢的 OpenAI 请求,将复杂的任务串联到工作流中,并设置重试和超时以从故障中恢复。
Temporal:一个开源的工作流和编排系统,支持任务的持久化存储,确保任务的可靠执行和恢复能力。
Trigger.dev:通过事件驱动的方式,提供任务和工作流的持久化管理,帮助开发者更好地管理复杂任务。
编排
编排是指协调和管理不同 AI 组件和服务,以确保它们在预定的流程中高效地协同工作。
DSPy:通过模块化和声明式的方法,DSPy 的核心是引入一种结构化的、以编程为中心的方法,取代传统的提示工程,允许用户以更清晰和高效的方式构建和优化复杂的 AI 系统。该架构由斯坦福的研究人员开发,目前在 Github 获得 1.4 万颗星。
AutoGen:微软开发的开源框架,自动生成和管理 AI 模型及其相关的工作流,简化了模型开发和部署的过程。AutoGen 提供多代理对话框架作为高级抽象。
Sema4.ai:提供智能编排解决方案,用于优化和自动化机器学习和 AI 项目中的各个步骤。
LangGraph:LangChain 框架的扩展,旨在通过图形化的方法创建多代理工作流。能够处理有状态、循环和多角色的应用,适合构建需要多个代理协同工作的复杂 AI 系统。
Griptape:提供灵活的编排框架,使开发者能够轻松定义、管理和执行复杂的 AI 工作流。
CrewAI:一个多代理系统平台,旨在通过简单有效的方式实现复杂工作流的自动化。
Fixpoint:提供可靠的编排工具,确保 AI 和数据工作流的高效运行和管理,适用于多种 AI 和数据密集型应用。
05
执行层
AgentLabs
Tool Usage 工具使用
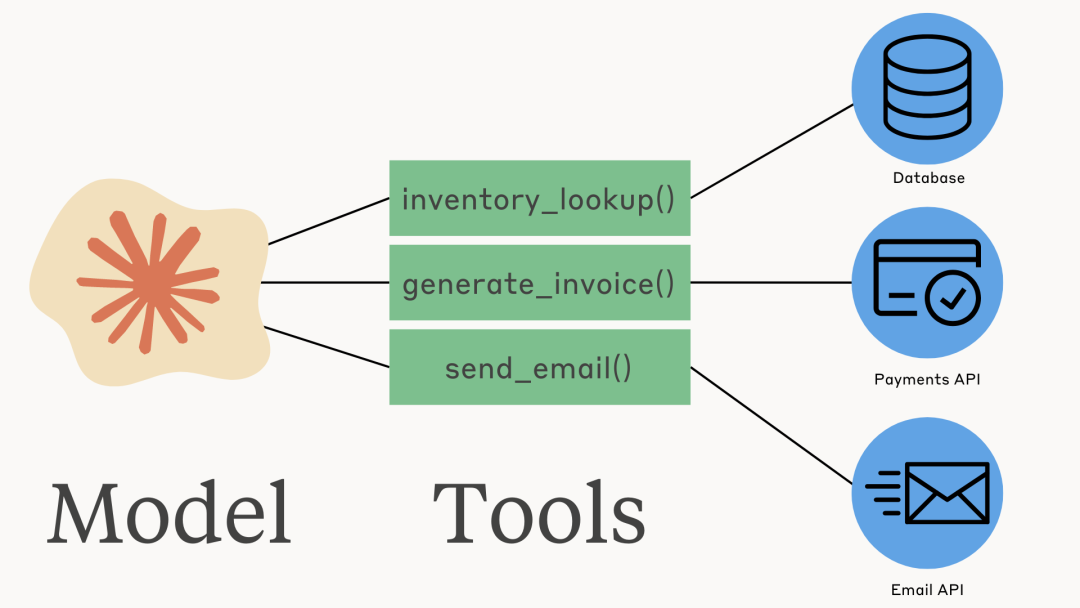
Anthropic
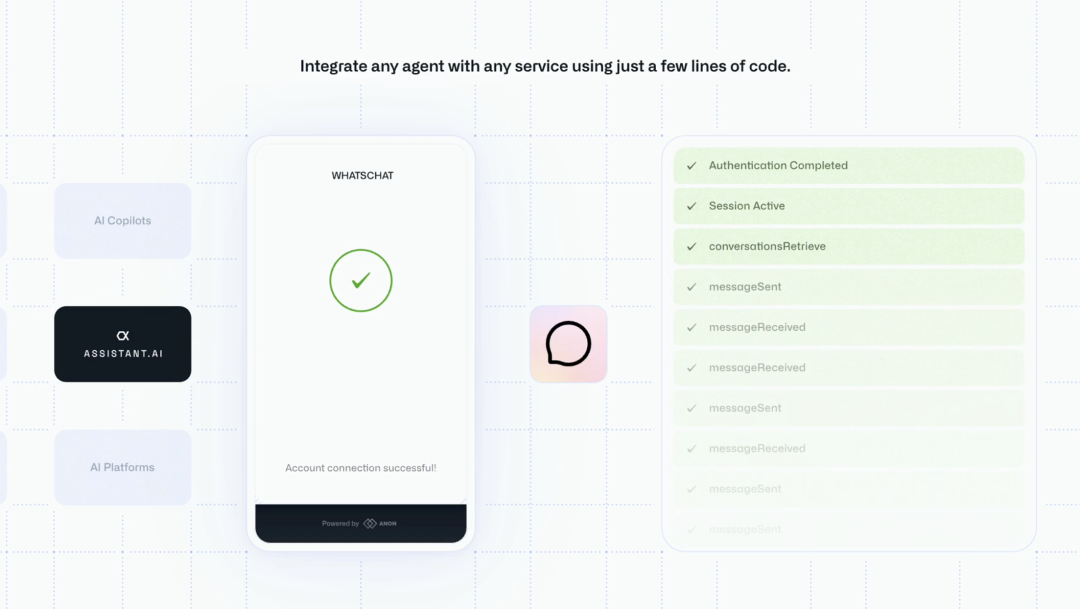 ANON自动授权
ANON自动授权
Reworkd

Browserbase
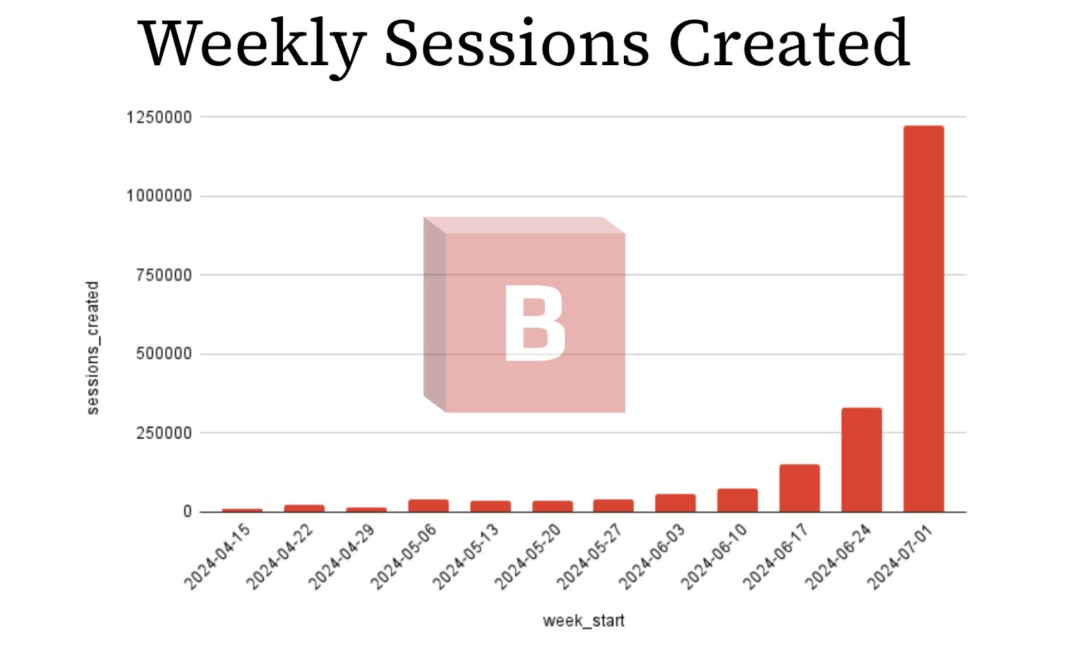
Browserbase连续四周获得100%的增长
06
应用层
今年开始,国内的大量AI应用也开始初见产品价值,从 ToB 延伸到 ToC,从生产力和效率延伸到综合的社交娱乐和其他的多模态等各个领域。Agentic applicaitons 发展呈现出多元化、深入化的趋势。
参考材料
https://www.madrona.com/the-rise-of-ai-agent-infrastructure/
文章涉及项目链接见:https://zhuanlan.zhihu.com/p/707504322
更多阅读
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢