

新智元报道
新智元报道
【新智元导读】MoE已然成为AI界的主流架构,不论是开源Grok,还是闭源GPT-4,皆是其拥趸。然而,这些模型的专家,最大数量仅有32个。最近,谷歌DeepMind提出了全新的策略PEER,可将MoE扩展到百万个专家,还不会增加计算成本。


背景与介绍
Transformer架构中,每个块内都包含注意力层和前馈层(FFW),注意力层用于计算序列中token之间的关系,FFW网络则负责存储模型知识。 我们当然希望LLM能在参数中隐式存储更多知识,但FFW的计算成本和激活内存会随之线性增加。稠密模型中,FFW层已经占据了总参数量的2/3,是扩展的主要瓶颈之一。 MoE模型虽然参数量也很大,但每次推理时不会动用整个模型的能力,而是将数据路由到小型且专门的「专家模块」,因此能在LLM参数增加的同时,让推理所需的计算成本基本不变。 那么专家数量(即MoE模型的「粒度」)是不是越多越好? 这要考虑多个因素,包括模型参数总量、训练token数量和算力的预算。 2022年的一项研究认为,模型总参数量不变时,存在一个能达到最优性能的「最佳粒度」。专家数量超过这个与之后,模型性能就会进入「平台期」。

Unified Scaling Laws for Routed Language Models

百万MoE所系
PEER层设计
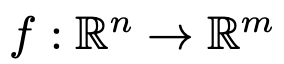 ,包含如下三部分:
,包含如下三部分: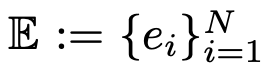
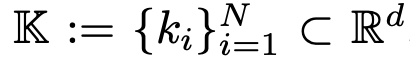
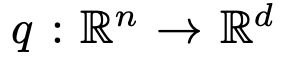



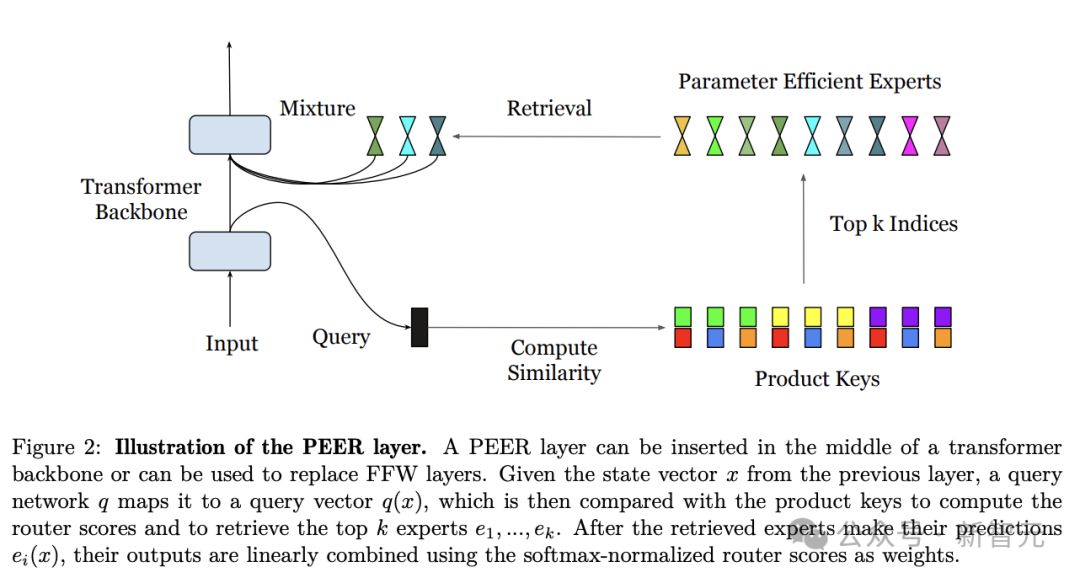
乘积键检索
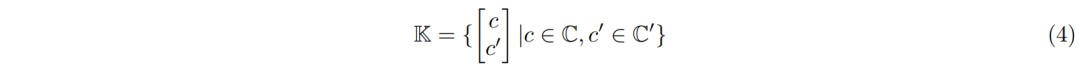

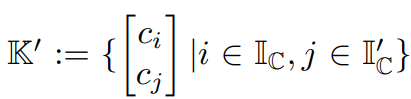 ,在数学上,这可以保证从K中与q(x)最相似的k个键在这个候选集合中。
,在数学上,这可以保证从K中与q(x)最相似的k个键在这个候选集合中。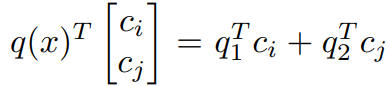 。
。参数高效专家和多头检索
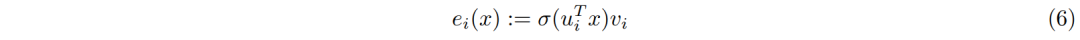
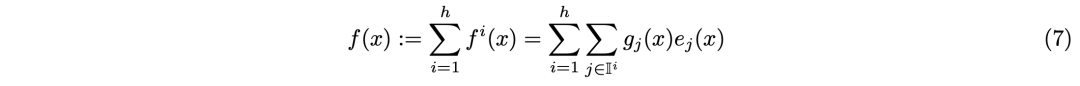
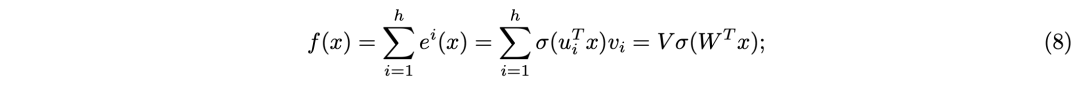

为什么用大量的小专家
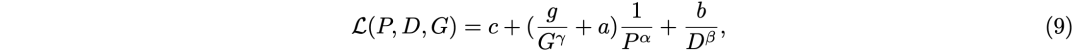
实验
预训练isoFLOP分析
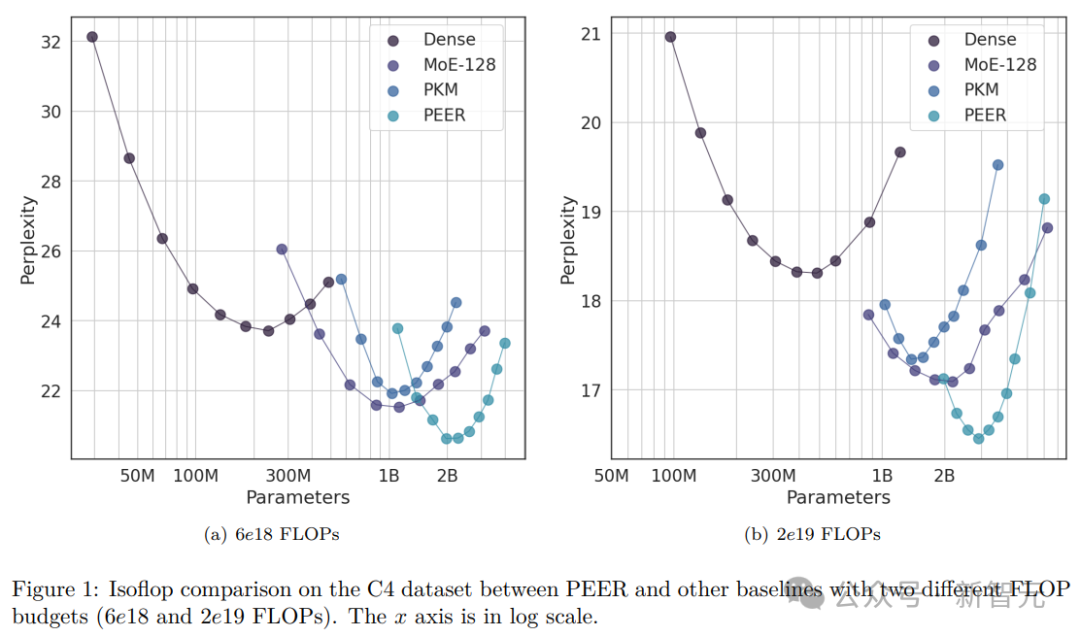
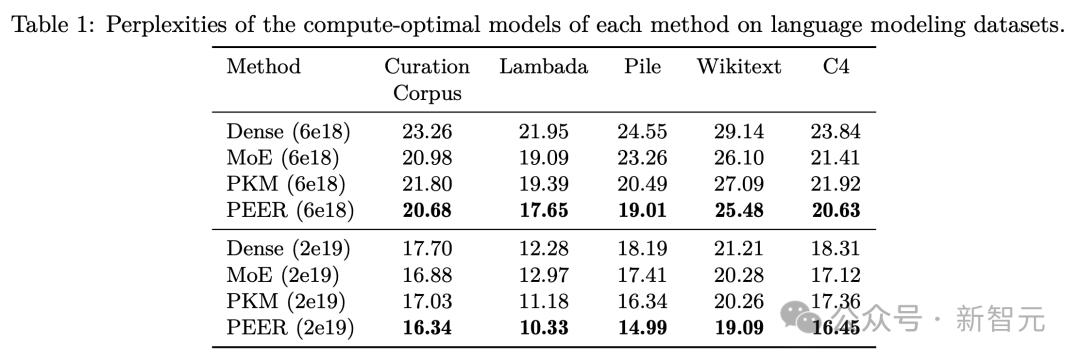
语言建模数据集评估
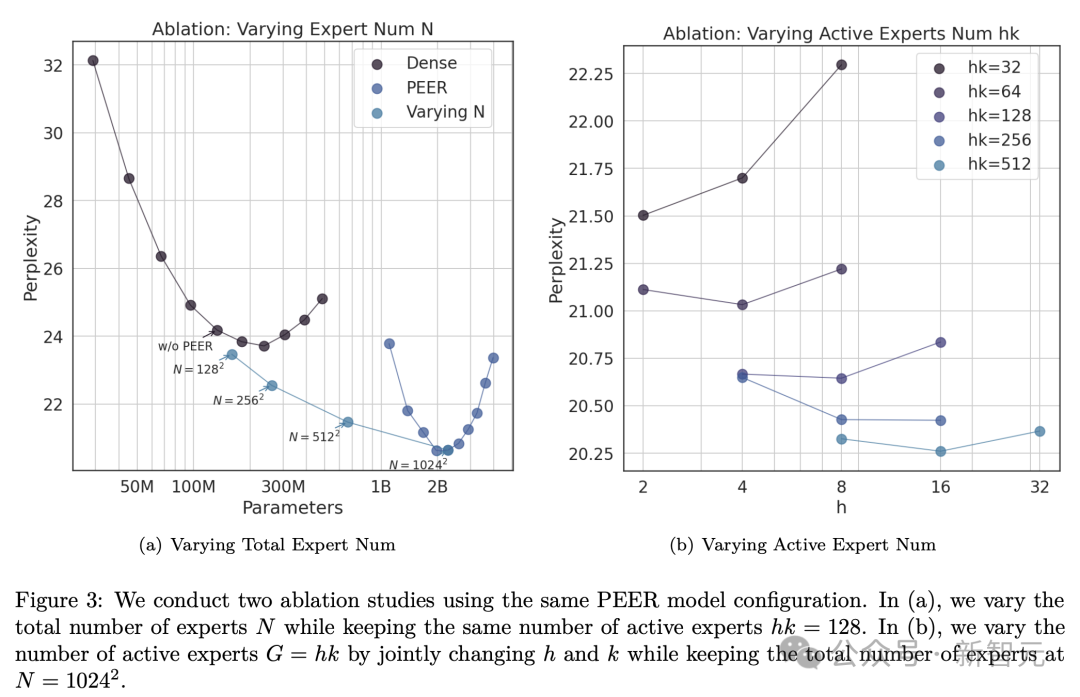
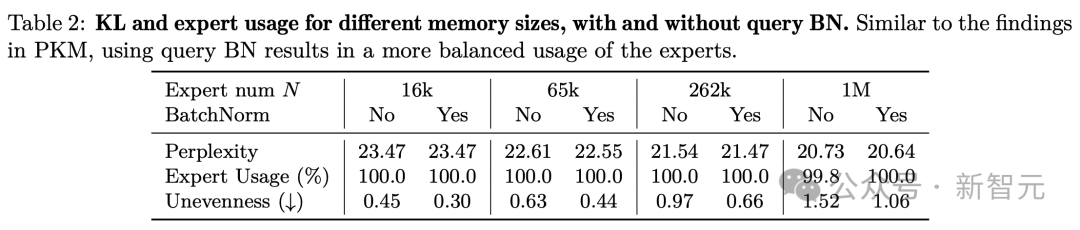
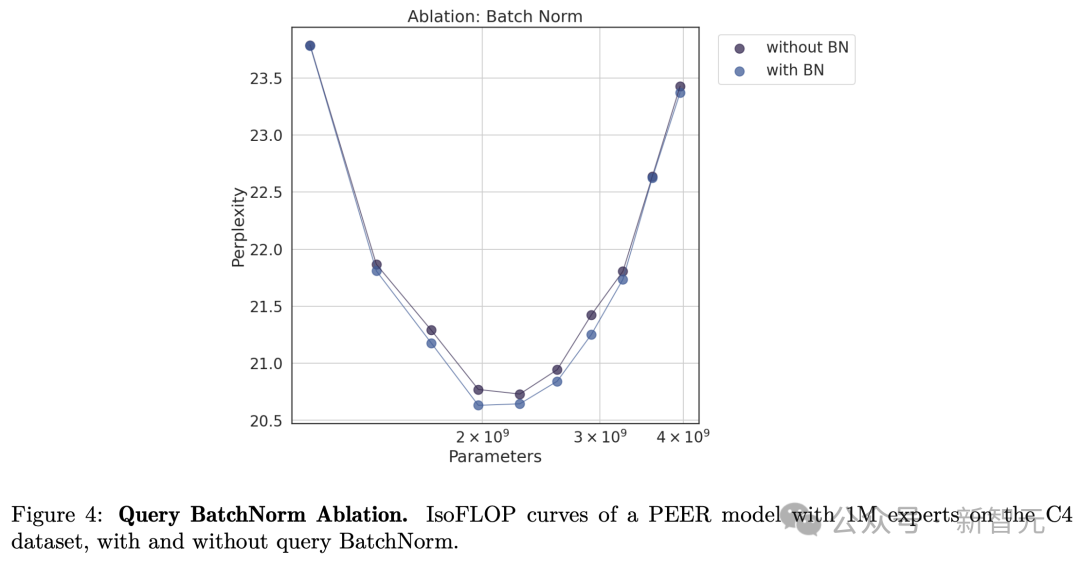
消融实验
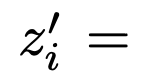
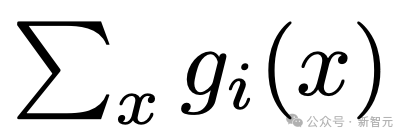 。
。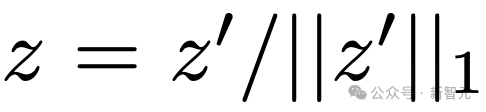 。
。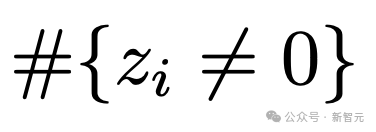
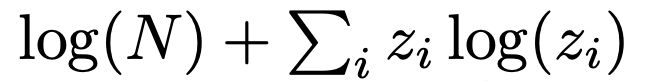
作者介绍




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢