


关键词:三维人体网格估计 扩散模型 概率性方法

导 读
本文是对发表于计算机视觉领域顶级会议 CVPR 2024 的论文 ScoreHypo: Probabilistic Human Mesh Estimation with Hypothesis Scoring 的解读。该论文由北京大学王亦洲课题组与上海交通大学乔宇课题组合作完成。
该工作提出了名为 ScoreHypo 的单视角三维人体网格估计的概率性方法框架,可以对单张图片生成多样化且合理的网格假设并对假设进行评估,从中得到高质量的估计结果。实验结果显示,ScoreHypo 在两个数据集上的表现优于现有最先进的方法,同时其假设评估模块具有强大的泛化能力,能够显著提升现有概率性方法的性能。
https://openaccess.thecvf.com/content/CVPR2024/papers/Xu_ScoreHypo_Probabilistic_Human_Mesh_Estimation_with_Hypothesis_Scoring_CVPR_2024_paper.pdf
https://github.com/xy02-05/ScoreHypo
https://xy02-05.github.io/ScoreHypo
https://www.youtube.com/watch?v=LhHQ1ZlpKe0
01
背景介绍
单视角三维人体网格估计是一个基础且具有挑战性的研究课题,具有重要的研究意义。现有的确定性方法通过单张图片生成单一确定性的人体网格,尽管在一定程度上能够提供精确估计,但这些方法忽视了 2D 到 3D 映射过程中固有的深度歧义和遮挡问题。由于同一 2D 图像可能对应多个合理的 3D 人体网格,这导致确定性方法在高不确定性场景下表现不佳。
为了解决这些不确定性,概率性方法被提出以对单张图片生成多个假设。例如,ProHMR[1]和 HuManiFlow[2]使用归一化流技术生成可能的 3D 网格。然而,目前的概率性方法虽然能够生成多个可能假设,但在选择高质量估计方面重视程度有限。选择机制通常仅涉及选择与给定的地面真实数据误差最小的估计[1, 2],或对所有生成的估计进行简单的平均处理[3]。这些方法缺乏强大且可靠的选择机制,导致在处理现实世界的复杂场景时实用性大打折扣。
为了解决上述问题,本文提出了一个创新且多功能的框架——ScoreHypo。该框架包括两个主要组件:HypoNet 和 ScoreNet。HypoNet 通过多尺度图像特征和交叉注意机制生成多个 3D 网格假设,而 ScoreNet 则对这些假设进行评估,从中选择最优的估计结果。ScoreHypo 整合了生成和选择过程,提供了一种新的方法框架来解决从 2D 图像到 3D 网格的不确定性问题。

图1. ScoreHypo 框架的示意图
02
方法概览
ScoreHypo 框架包括两个主要组件:HypoNet 和 ScoreNet,我们首先通过 HypoNet 对单张图像生成多个合理的假设,随后通过评估网络 ScoreNet 对多个假设进行评分,最后根据评分得到最终的估计。
HypoNet 将单视角三维人体网格估计问题建模为基于图像特征的条件扩散模型的逆向去噪过程[4]。为了确保生成的网格与输入的 2D 图像高度吻合,HypoNet 引入了多尺度图像特征,这些特征通过卷积神经网络(CNN)提取,并通过交叉注意力机制与 3D 网格估计进行有效对齐,提高了生成结果的多样性和合理性。
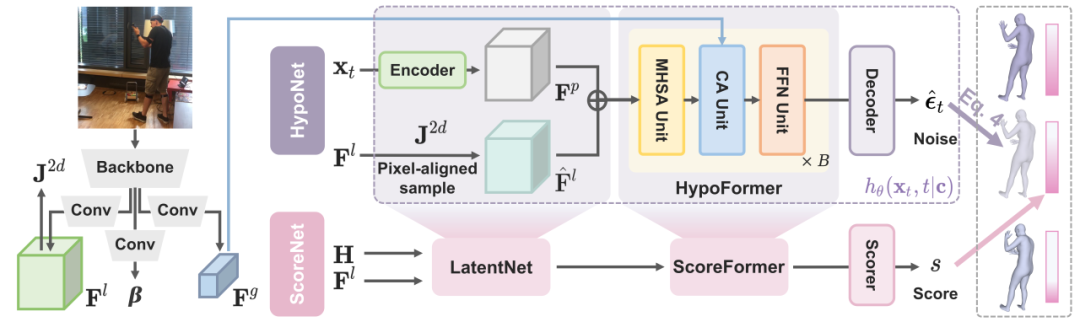
图2. ScoreHypo 模型架构图
在 HypoNet 生成多个假设之后,ScoreNet 负责对这些假设进行评估和选择。我们使用可微分的排序损失函数[5],让 ScoreNet 学习假设之间相对质量差异的概率分布,并使用常见的人体网格评估指标 MPJPE 与 MPVE 作为质量的衡量标准。通过这种方式,ScoreNet 能够对质量更高的假设给予更高的评分。在推理阶段,ScoreNet 根据提取的图像特征,对每个假设输出相应的分数,并通过排序选择得分最高的K个假设进行聚合,得到最终的结果。
03
实验结论
本工作在两个基准数据集上评估了本文的方法,ScoreHypo 均达到了最佳水平并且具有强大的泛化能力。表1展示了在 H3.6M 和 3DPW 两个数据集上的表现,评价指标是预测关节点与真实关节点的平均误差值(MPJPE,Mean Per Joint Position Error)、经过 Procrustes 对齐的平均关节位置误差(PA-MPJPE,Procrustes Aligned Mean Per Joint Position Error)和预测网格与真实网格的平均格点误差值(MPVE,Mean Per Vertex Error),单位为毫米。
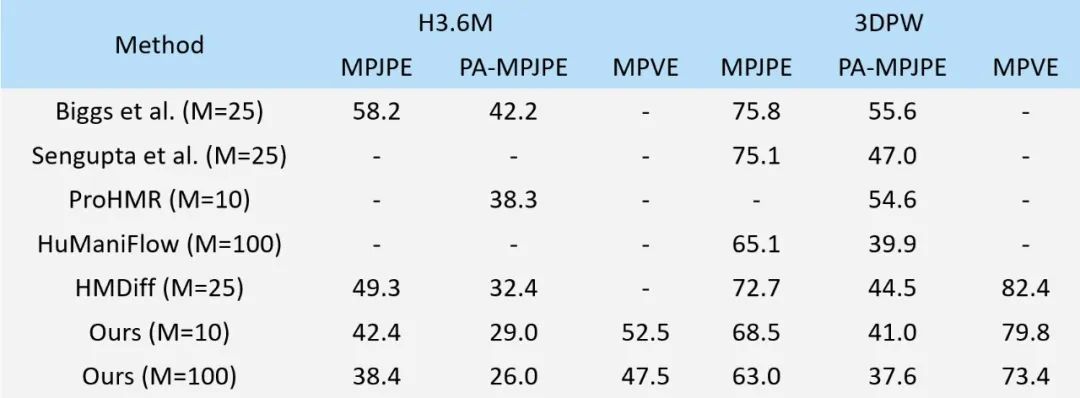
表1. 本工作的方法与现有工作在 H3.6M 和 3DPW 两个数据集上的定量误差结果(越小越好)
表2展示了在 3DPW 数据集上不同选择策略的消融研究。在策略 (a) 和 (b) 中,输出结果分别是从随机的高斯噪声和零噪声开始生成的样本。在策略 (c) 中,我们简单地将 HypoNet 生成的多假设的平均作为最终输出。在策略 (d) 中,我们使用我们训练好的 ScoreNet 从 HypoNet 生成的假设中选择。最右侧列显示了我们框架的结果,表明我们的 ScoreNet 可以有效地选择更高质量的假设,优于所有其他选择策略。此外,ScoreNet 还显示出了出色的鲁棒性和泛化能力,能够有效地改善包括 ProHMR[1]和 HuManiFlow[2]在内的概率性方法的性能,无需进行微调。
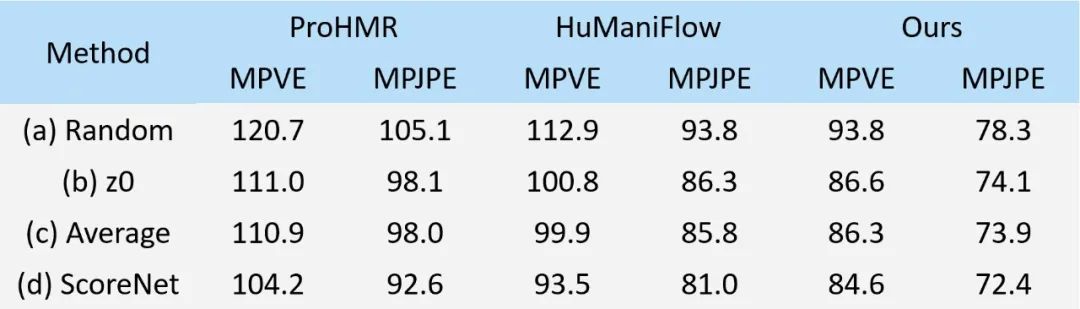
表2. ScoreNet 在 3DPW 数据集上的有效性评估
图3展示了本方法的可视化结果,可以看到,HypoNet 能够生成与 2D 图像可见部分对齐且在 3D 空间中具有合理多样性的假设,展现了 HypoNet 的强大生成能力。同时,ScoreNet 选择的结果在 2D 图像上的对齐度更高,并且在 3D 空间中也更加合理。

图3. 具有挑战性的野外图像的结果: 黄色和蓝色的网格是 HypoNet 生成的结果,而绿色的网格是 ScoreNet 选定的最终结果
下面展示了更多的本方法在真实自然场景下的可视化效果:
04
总 结
本工作提出了 ScoreHypo,一种结合概率性网格估计与假设选择的概率性方法框架,HypoNet 利用多尺度图像特征生成多个与 2D 图像高度吻合的 3D 人体网格估计,ScoreNet 则能够有效评估并选择高质量的结果。在应对复杂现实场景时,我们的方法能够提供准确且可靠的解决方案。此外,ScoreNet 显著提高了现有概率性方法的性能,展示了其强大的泛化能力。
参考文献
[1] Nikos Kolotouros, Georgios Pavlakos, Dinesh Jayaraman, and Kostas Daniilidis. Probabilistic modeling for human mesh recovery. In ICCV 2021.
[2] Akash Sengupta, Ignas Budvytis, and Roberto Cipolla. Humaniflow: Ancestor-conditioned normalising flows on so(3) manifolds for human pose and shape distribution estimation. In CVPR 2023.
[3] Lin Geng Foo, Jia Gong, Hossein Rahmani, and Jun Liu. Distribution-aligned diffusion for human mesh recovery. In ICCV 2023.
[4] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS 2020.
[5] Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. Learning to rank using gradient descent. In ICML 2005.

图文 | 许苑
Computer Vision and Digital Art (CVDA)
About CVDA
The Computer Vision and Digital Art (CVDA) research group was founded in 2007 within the National Engineering Laboratory for Video Technology at Peking University led be Prof. Yizhou Wang. The group focuses on developing computational theories and models to solve challenging computer vision problems in light of biologically plausible evidences of visual perception and cognition. The primary goal of CVDA is to establish a mathematical foundation of understanding the computational aspect of the robust and efficient mechanisms of human visual perception, cognition, learning and even more. We also believe that the marriage of science and art will stimulate exciting inspirations on producing creative expressions of visual patterns.
CVDA近期科研动态


— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

点击“阅读原文”转论文地址
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢