

引言
最近,⼤型语⾔模型(LLMs)的成功已逐渐扩展到多模态领域,通过整合视觉编码器和有效的跨模态对⻬策略,多模态⼤模型(LMMs)已能处理图像和⽂本的复合任务。然⽽,尽管LMMs在各种场景任务中展现出了强⼤的潜⼒,但它们在复杂任务上的表现依然受限于传统的单步推理范式,⽆法有效完成多步推理才能解决的任务。⽐如GPT-4V,在处理涉及空间关系和多物体交互的复杂推理任务时,往往⼒不从⼼。我们认为这主要是源于(1)这是因为当前的模型难以在单⼀的预测步骤中理解和分析多个物体的动态关系,缺乏合适的范式帮助模型利⽤多模态信息构建有效的推理过程;(2)模型内部的跨模态信息理解能⼒不⾜,⽆法有效将⽂本grounding到对应的视觉信息,往往会导致幻觉的产⽣,给⻓序列的推理带来了不可靠性。
为了应对这⼀挑战,复旦⼤学数据智能与社会计算实验室(DISC)提出了⼀种解决⽅案叫做 “VoCoT(Visually grounded object-centric Chain-of-Thought)”,⼀种专⻔针对多模态⼤模型设计的、视觉引导的物体中⼼链式思维(Chain-of-Thought,CoT)推理框架。VoCoT的关键在于两点:(1)围绕物体作为跨模态共享信息,建⽴有效的推理路径,并以物体为推理锚点构建跨模态的联系;(2)以visually-grounded的形式表示物体,即<⽂本描述,视觉坐标,视觉特征>三元组,其中的坐标要求模型显式地将物体对⻬到视觉信号,每个物体的视觉特征则由本⽂提出的⼀种名为RefBind的机制⾼效地基于坐标得到,帮助模型类似⼈类在推理过程中不断参考(refer)物体对应的视觉信息。最终,VoCoT能够构建多模态信息交错的推理路径,并在路径中引⼊跨模态对⻬的锚点信息。

图1:VolCano 输出Case与 GPT-4V 对⽐
⽬前代码、数据和模型都已开源:
论⽂地址:https://arxiv.org/abs/2405.16919
代码地址https://github.com/RupertLuo/VoCoT
VoCoT-Instruct-80K:https://huggingface.co/datasets/luoruipu1/VoCoT
VolCano-7b:https://huggingface.co/luoruipu1/Volcano-7b
方法介绍
“
VoCoT 数据形式
纯⽂本的CoT要求多模态⼤模型模型(LMMs)基于提供的上下⽂进⾏逐步推理。为了在多模态上下⽂中构建有效且可靠的推理路径,VoCoT定义了两个关键特征:
1. 物体为中⼼:图像中的物体是基本的语义单元,可以作为锚点来连接多模态上下⽂信息。因此,VoCoT需要包含重要物体,并随后提取并分析相关的信息
2. 视觉定位:VoCoT中包含的关键物体应由“<⽂本描述, 视觉坐标, 视觉物体特征>”的元组表示。模型在推理过程中要求⽣成对应的坐标来显式定位图像中的物体,⽽视觉表示则增强了跨模态推理路径的相关性。
“
构建VoCoT数据集
当前主流的多模态指令微调数据集,如LLaVA-Instruct-150K等,均不符合VoCoT数据形式的要求,即:(1)对⼈类指令的回答需包含多步推理过程;(2)回答需包含视觉定位的物体中⼼信息,即具有对应坐标的物体。本节将介绍从三种不同类型数据源构建符合VoCoT格式数据集的流程。
1. Type 1:GQA源

图2: 类型1 VoCoT数据样例
2. Type 2:基于VQA的源
另⼀种直观的构建⽅法是在问题到答案的过程中补充多步推理过程,形成VoCoT格式的数据。借助GPT-4V的能⼒,在图像、问题、答案及图像内物体信息的基础上⽣成推理路径。⽂中通过in-context learning 的⽅式控制输出格式。

图3: 类型2 VoCoT 数据样例
3. Type 3:仅图像源
尽管前两种构建⽅法有效,但⽣成的数据受限于现有问题。⽂中介绍为了增强问题和推理逻辑的丰富性,该⼯作利⽤GPT-4V强⼤的⽣成能⼒扩展数据集。通过设计准确详细的提示以及in-context样例,仅输⼊GPT-4V图⽚和图⽚中所有物体的框,让其⽣成复杂的问题,以及VoCoT格式的推理路径和答案。

图4: 类型3 VoCoT数据样例
最终三种类型的数据组成了VoCoT-Instruct-80K。更多关于数据集构建过程的细节,包括基于规则的转换⽅法、GPT-4V的提示和质量控制⽅法等,请参考论⽂中的细节。
“
VolCano模型
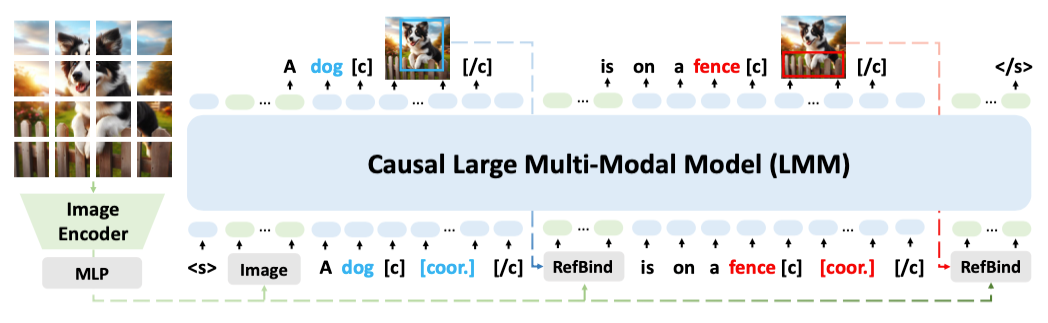
RefBind机制

模型训练阶段
实验部分
“
实验设定
训练⽅⾯,VolCano的训练采⽤AdamW优化器,bfloat16精度,峰值学习率为1e-5,使⽤8个NVIDIA A100 GPU,每个阶段的训练时间分别为12⼩时、48⼩时和30⼩时。输⼊图像分辨率为336*336。
评测⽅⾯,作者考虑了综合的VQA数据集(GQA,SEED,MMBench)以及明确需要多步推理的任务:空间推理(Embspatial,VSR),复合型任务(VStar,CLEVR,Winoground)。进⼀步为了检测VoCoT是否能减少幻觉,作者在POPE和AMBER上评估了VolCano的幻觉问题。
Baseline 考虑了单图输⼊的模型和多图增强分辨率输⼊的模型。并且加⼊了VolCano-SE作为严格对照组:使⽤相同的设定和数据(去除VoCoT部分),并且只进⾏单步推理。
“
主实验
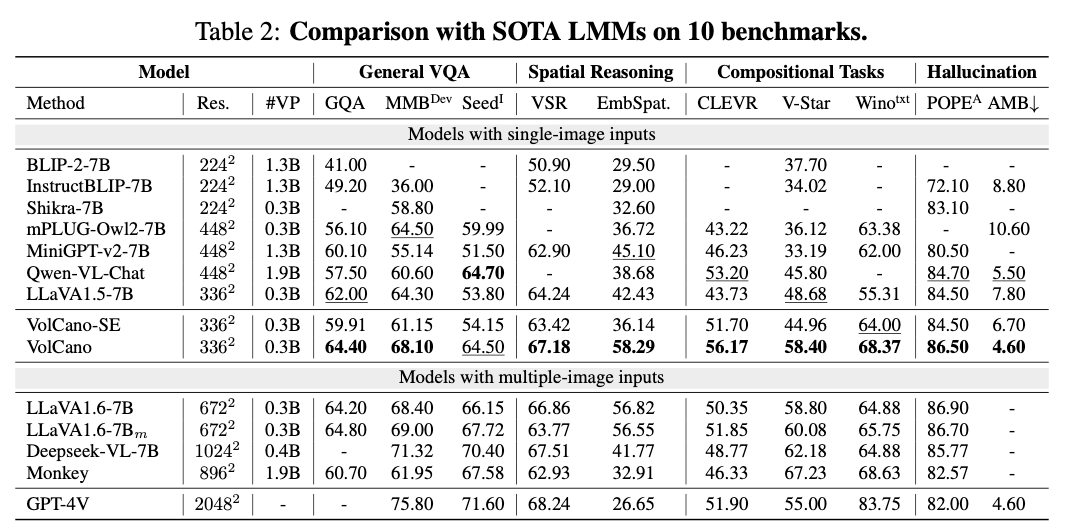
“
补充实验
VoCoT形式的作⽤
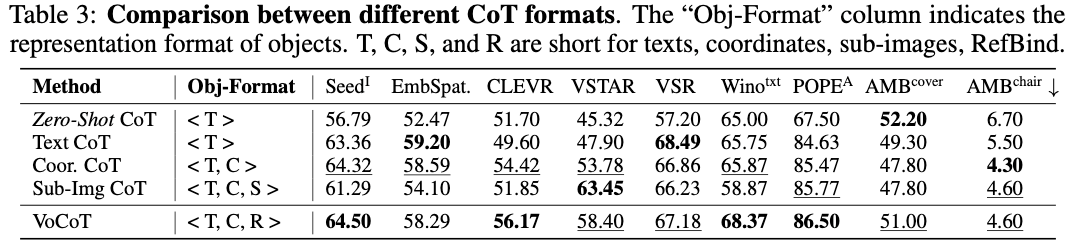
4. RefBind得到的视觉特征能够帮助多个任务,⽽基于⼦图(Sub-Img CoT)的⽅法如之前2.2.2节提到的,会引⼊冗余信息,反⽽降低性能。
VoCoT数据的作⽤
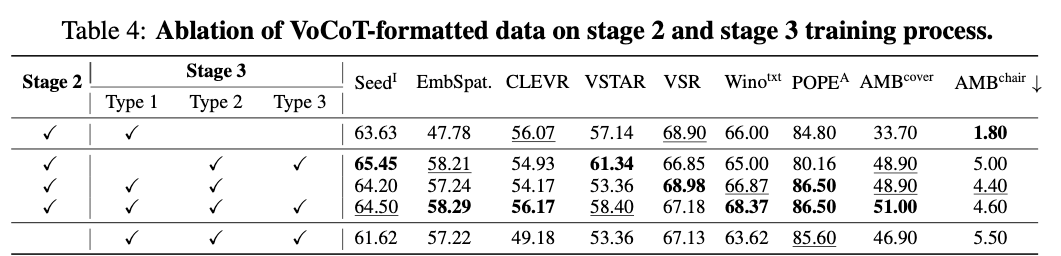
作者还探究了VoCoT的不同部分的数据的作⽤,从表4可以看出:
1. 第⼆阶段使⽤的多模态交错数据很重要;
2. Type 1 GQA数据最为准确,模型幻觉最少,但是其形式有限,不能很好地泛化到不同任务上;
3. Type 2和Type 3的数据都在Type 1的基础上提⾼了模型对于不同形式问题的泛化性,但如果完全不使⽤Type 1的数据,则会有明显的幻觉的⻛险。
推理难度的影响
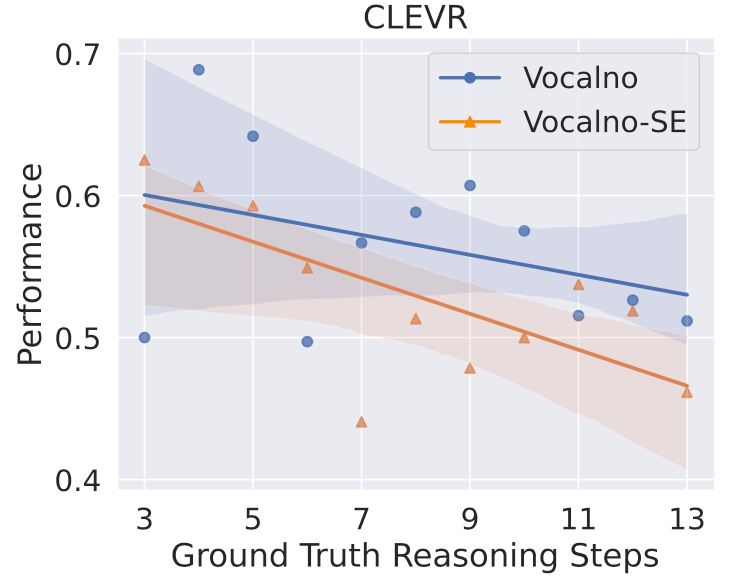
图7:不同推理难度下的模型表现
VolCano的grounding能⼒
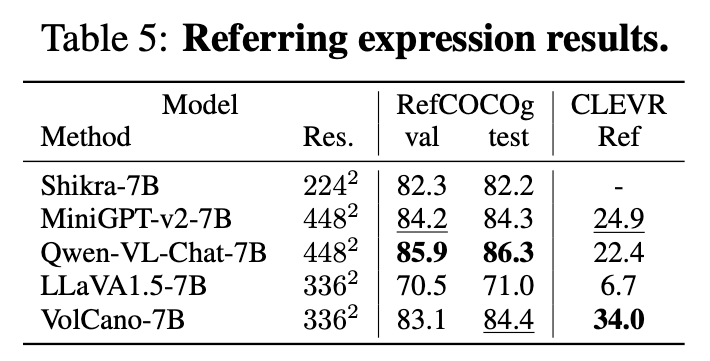
VolCano的推理能⼒拆解

3. 强⼤的语⾔基座对VoCoT影响很⼤,也体现了VoCoT在更强基座上应⽤的潜⼒。
结语
本⽂⾥作者提出了VoCoT来帮助在多模态语境下进⾏有效可靠的多步推理,基于VoCoT的设定,作者构建了VoCoT-Instruct数据集来⽀持训练模型习得VoCoT推理的能⼒,并且得到的VolCano模型在多个任务上展现了相⽐于单步推理的优势。
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区计算中心

点击“阅读原文”跳转至论文地址
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢