尽管有很多初创公司试图用人工智能驱动的搜索来取代当下的搜索引擎,但一家名为 Exa 的初创公司有一个不同的想法:为人工智能打造一个谷歌。创始人 Jeff Wang 和 Will Bryk 认为 Google 为人类做了什么,他们就希望通过 Exa 为 AI 做类似的事情。
Exa 正在构建的工具,能够用 AI 模型来执行类似于网络搜索的操作,但采用了特别为人工智能设计的技术和方法(AI-native twist)。他们认为并不是人类迫切需要一种新型搜索引擎,相反,随着 AI 在企业和消费者生活中的日益普及,AI 将比人类更多地搜索网络,AI 必须定期到互联网上搜索信息并返回真实的答案。但类似 Google 这样的搜索引擎是针对人类的,因此 Exa 是第一个针对 AI 构建的搜索引擎。7 月 15 日,EXA 宣布完成了一轮 1700 万美元的 A 轮融资。这次是由 Lightspeed 领投,英伟达的和 YC 跟投。加上之前的 500 万美元种子资金,Exa 现在总共筹集了 2200 万美元。
01
创业源起:
人类不需要新搜索,AI 需要
该团队在 ChatGPT 推出的前一年成立,两位创立者是在哈佛大学结识的好朋友:CEO Will Bryk(现年 27 岁)和联合创始人 Jeff Wang(26 岁)。

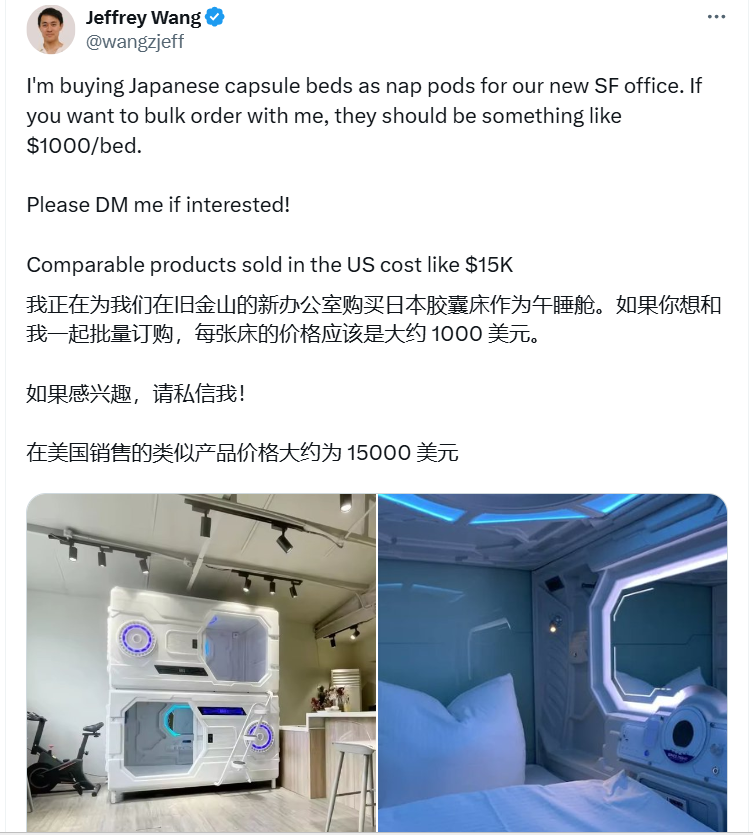
Exa 联合创始人,从左到右是 Jeff Wang 和 Will BrykExa 公司位于旧金山,在那里的科技行业里,工作-小睡的文化氛围依然活跃。正如 TechCrunch 报道的那样,当 Jeff Wang 在推特上发文,想要寻找其他公司一起订购办公室午睡舱时,推文走红,反响非常热烈。Exa 之前的名字是 Metaphor,今年 1 月份宣布更名为 Exa。官方对此的解释是:Exa 的意思是 10^18 次方,而 Google 的意思是 10^100 次方。Google 的目标是展示所有信息,而 Exa 的目标是将所有信息过滤成有组织的知识。当涉及到有组织的知识时,10^18 大于 10^100。
Exa 创始人认为,人类并不是迫切需要一种新型搜索引擎。相反,随着 AI 在企业与消费者生活中日益占据主导地位,人工智能需要能够自主地访问互联网,搜索相关信息,并提供真实可靠的答案,而不是虚假或误导性的信息。而且,人工智能平台不能再像人类那样简单地利用文字来查询结果。
Exa 想要做的就是真正从所有信息里过滤掉嘈杂的信息,进而组织真正的知识,这也是其使命:整合世界知识(Organize the world's knowledge)。02
搜索机制:
根据内容搜索互联网而不是关键词
Will Bryk 此前曾在推特发文,认为人们需要在超级智能之前拥有超级知识。智能是对问题的推理,知识需要从数据存储库中检索。ChatGPT 具有高智能,但令人惊讶的是知识有限。例如,GPT-4 可以解决任何高中物理问题,但如果你要求它检索某个市的物理博士名单——一个相对简单的请求,却极其困难。
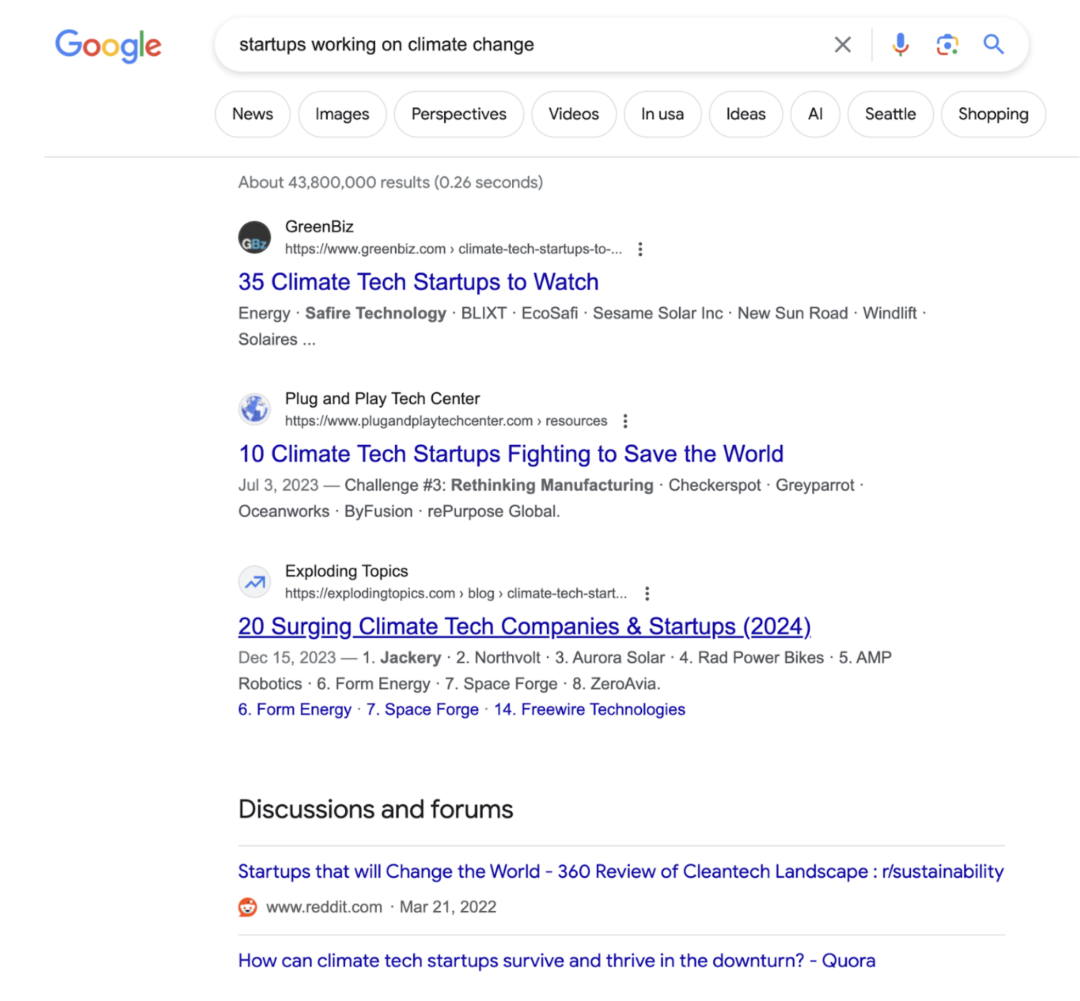
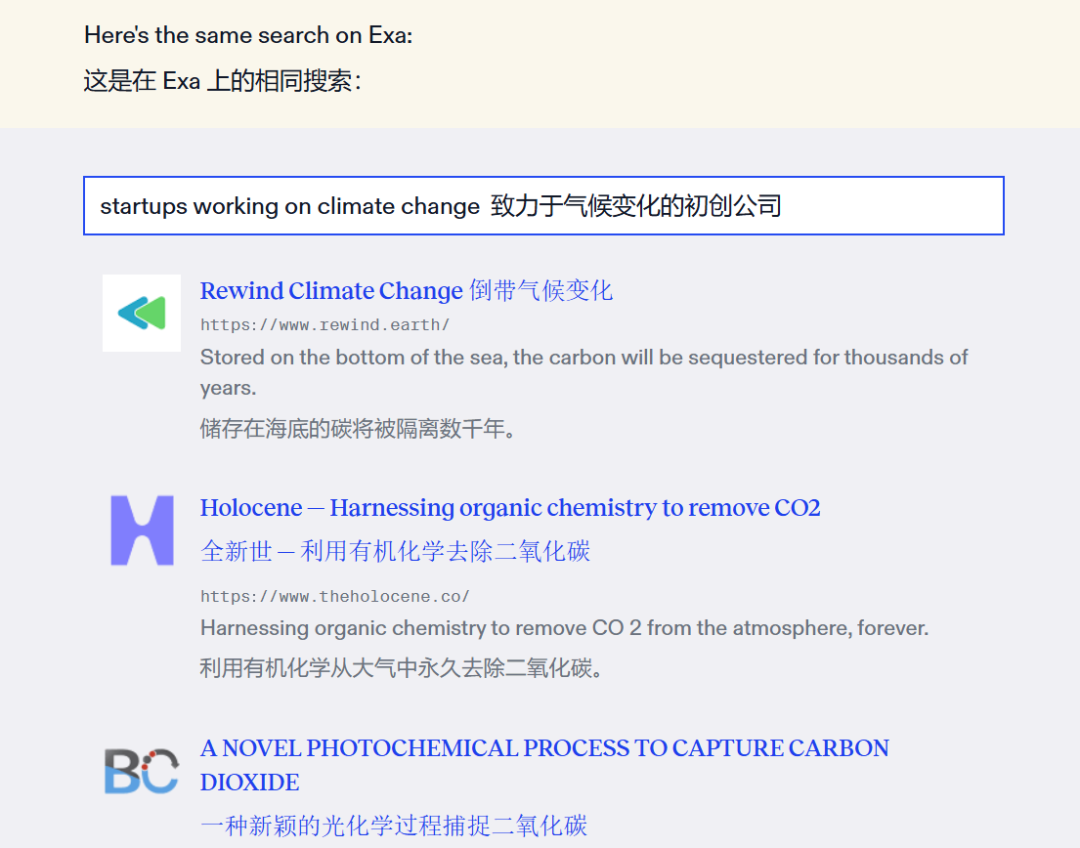
超级智能是一个可以处理极其复杂的推理请求的系统,而超级知识是一个可以处理极其复杂的检索请求的系统,它让每个人都能以最快的速度获得对任何事物的全面了解。互联网包含了人类集体的知识产出——所有伟大的艺术和文学作品、数百万篇论文、数亿篇研究论文、数十亿张图片和视频、数万亿的想法散布在推文和论坛中。使用搜索引擎,应该像是在知识的图书馆中导航,人们可以在不同文化、行业和时间维度之间编织洞见。但今天的感觉并非如此,现在上网搜索内容,更像是在垃圾场中航行。例如,在谷歌上搜索「致力于气候变化的初创公司」,得到了 4380 万条结果。但实际知识有多少?看到很多列表文章的结果,但难以找到真正在解决气候变化的初创公司。这是因为谷歌仍然使用基于关键词的算法。关键词作为一种过滤机制可能在 1998 年有效,但它们对于拥有千倍内容的互联网以及致力于破解关键词的 SEO 行业来说并不起作用。Exa 与之相反,是首个网络规模的神经搜索引擎。其算法端到端使用 transformer 架构,这和构建 ChatGPT 的技术相同。这使我们能够根据意义过滤互联网,而不是根据关键词。网页检索的质量对于 LLMs 来说尤其重要。如果检索返回的是垃圾信息,LLM 将输出垃圾内容。如果检索足够强大,能够过滤互联网以获取正确的知识,LLM 将输出尽可能高质量的内容。Exa 便是一个为AI Agent 构建的嵌入式搜索引擎,为 AI agents 专门设计和构建网络基础设施。「Transformer 模型通常被用来预测文本中的下一个词。我们训练我们的搜索引擎直接去预测下一个链接,CEO Will Bryk 说。」人们在网页上分享链接,我们使用这些数据作为我们模型的训练数据集,训练模型去预测下一个链接。所以这是一个新颖的搜索算法。「就像 LLM 会通过提供最可能的下一个词来完成句子一样,Exa 的系统通过提供最有可能的链接(或者 10 个链接)来完成搜索任务。但与普通搜索引擎不同,它没有那些常见的搜索引擎优化(SEO)垃圾内容和由人工智能生成的无关信息,正是这些内容污染了当前的普通搜索引擎。相比 Perplexity,Exa 一开始更像是面向 B 端企业和开发者的一个研究 AI,而非搜索引擎。在 ChatGPT 席卷科技界之后,AI 公司就开始向 Exa 请求他们搜索引擎的 API,以便将其集成到他们的模型中。现在不少 AI 公司已经成为该公司的主要客户。Exa 搜索引擎的使用案例涵盖广泛,AI 聊天机器人在回答访客问题时查找互联网上的信息,公司用来寻找训练 AI 的数据,很多 VC 用它来帮助自己搜索投资标的等等。例如,Databricks 是 Exa 的主要客户,创始人表示,它使用 Exa 来寻找大型训练集,以支持其自身的模型训练计划。今天,Exa 表示它正在为数千名开发者提供服务——尽管值得指出的是,Exa 有一个免费计划,允许任何人以有限的方式尝试其搜索引擎,另外还有多个分层收费套餐。创始人们没有透露收入,其官方博客表示,目前已经有数千家公司和开发者集成了 Exa,其收入在过去几个月中增加了两倍。有趣的是,除了运行自己的 GPU 集群外,Exa 还将其产品托管在 AWS 上,而不是 AI 优先的 Google Cloud。尽管目前团队的目标并不是要颠覆谷歌的搜索业务,但如果 AI 真的如所预期的那样,成为解决所有问题的终极技术,那么专门为人工智能机器人设计的搜索引擎,可能会成为对现有搜索市场霸主地位的意外挑战。03
为什么投资 Exa:
我们需要一个面向 AI 的新搜索
本轮投资的领投机构 Lightspeed 在 7 月 16 日发表了一篇文章,详细解释了他们为什么会投资 Exa,以及看好 Exa 的原因。
最近,我们深入思考了即将到来的代理网络,也就是说,专门为 AI Agent 及其功能提供支持的新型网络基础设施。这将改变互联网现状,因为 AI Agent 的理想基础设施与为人类用户设计的理想基础设施是不同的。
首先,AI Agent 需要获取最新、准确的信息来完成它们的任务。大型语言模型虽然存储了大量数据,但这些数据很快就会变得过时,且难以可靠地检索。检索增强生成(RAG)已经成为一种关键模式,使大型语言模型能够处理训练数据之外的信息,但目前大多数实现都集中在私有或内部信息上。理想情况下,AI Agent 应能够通过 API 访问整个公共互联网上的信息,这是他们工具箱中的一个重要工具。这就需要建立新的基础设施——代理网络。首先,现有的网络基础设施由于竞争的激励而逐渐「退化」,这些激励更倾向于满足广告商的需求而非用户。传统的搜索引擎更注重广告点击和展示,而不是提供对用户请求有帮助的答案。此外,一些精明的网站所有者已经开始逆向工程了主要搜索引擎用来排名网站的极致,导致了「SEO」行业的兴起,这种优化使网站更迎合搜索引擎而非访客,结果便是,充斥着低质量的内容农场。事实证明,内容并不总是最重要的。现代搜索引擎无法区分你真正在寻找的东西和仅仅是提及你在寻找的东西的内容。这种细微的区别听起来可能不太明显,但对于 AI Agent 来说,获取最佳信息进行推理至关重要。例如,搜索「精通 Go 语言的软件工程师」时,理想的情况是返回这些工程师的个人网站或社交媒体资料,而不是那些讨论 Go 语言的页面。换句话说,理想的搜索引擎应该能够理解「实体」的概念,而不仅仅是讨论一般主题的内容。AI Agent 与人类有不同的需求:AI 发出的搜索查询的最佳响应并不一定与人类相同。AI Agent 不需要看到广告,他们需要的是结果。他们不仅需要看到前几页——他们需要所有相关的结果,以便利用不断扩大的上下文窗口。如果有一个专门为 AI Agent 设计的搜索基础设施,这将不是问题。不幸的是,人类和 AI 都被迫使用相同的搜索结果。这是「一刀切的做法,是所有可能中最不理想的情况。。这正是 Exa 发挥作用的地方。Exa 是一个为 AI Agent 设计的基于嵌入的搜索引擎。Exa 获取并索引来自网络的最新内容,并通过由他们自己的新颖「链接预测」基础模型驱动的搜索 API,将这些数据提供给基于大语言模型的应用程序,该模型特别调整为理解搜索查询并返回其索引中相关的链接。重要的是,Exa 理解「实体」的概念——例如,一个查询「顶级开源 AI 模型」实际上会返回 Mistral、Llama 等模型的链接,而同样的查询在 Google 上则返回的是讨论开源 AI 的网站,而不是这些具体的模型本身。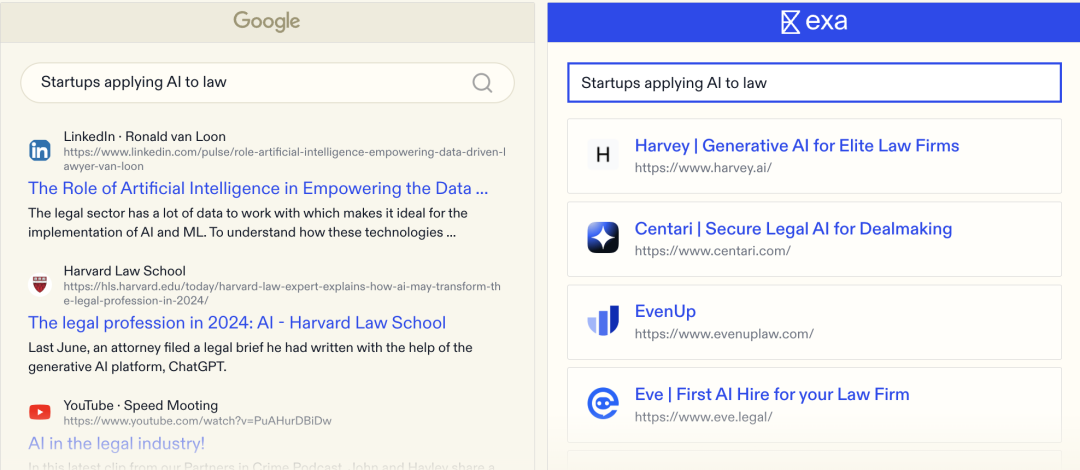
Exa 精确地返回你所要求的——真正的初创公司链接Exa 团队开发并优化了自己的网络爬虫系统,从互联网上收集信息并不断扩展其索引库。Exa 的爬虫能够从海量的网络数据中筛选出最优质的内容。除了他们自己研发的基础模型,Exa 还开发了独特的 Rust 语言编写的向量数据库,这个数据库能够处理数以亿计的文档查询,同时保持极低的延迟。Exa 的联合创始人 Will Bryk 和 Jeff Wang 完全有能力应对这一挑战。他们在哈佛大学学习计算机科学时就结下了深厚的友谊,经常一起熬夜解决技术难题。Will 后来加入了 Cresta,成为了一名早期工程师,他以学习能力强和解决问题的创造力著称。Jeff 在 Plaid 工作期间,以其惊人的工程效率和为新项目找到市场定位的能力而闻名。Exa 让互联网再次焕发出新鲜感和兴奋感。它让我们回想起那个没有被时间积累的杂乱信息所覆盖的旧互联网。AI 需要一次更新。我们很高兴能与 Nvidia Ventures 和 Y Combinator 一起主导 Exa 的 1700 万美元 A 轮融资。Exa 正在做一件不可思议的大任务,那就是为 AI 重塑互联网。参考文章:
https://techcrunch.com/2024/07/16/exa-raises-17m-lightspeed-nvidia-ycombinator-google-ai-models/
https://lsvp.com/stories/exa-redesigning-search-for-ai/
https://x.com/WilliamBryk/status/1811844938977706027
https://exa.ai/blog/announcing-exa
https://exa.ai/blog/series-a
更多阅读
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢