
大模型的RAG(Retrieval-Augmented Generation)机制主要分为三个核心阶段:
问题提出:用户输入问题或查询,作为信息检索的起点。
文档检索:高效的搜索系统迅速从海量数据库中检索出与用户问题紧密相关的文档集合。
答案生成:大模型利用这些检索到的文档,智能地生成并返回用户所需的答案。
大模型回答的准确性直接依赖于检索文档与用户问题的匹配度,而响应速度则受到搜索系统效率的影响。为此,我们精心设计了搜索流程,将其分为召回、重排序及大模型精排三个阶段,每个阶段对应不同类型的语义模型,以平衡性能与效果:
召回阶段:采用双塔模型,以其高速特性快速从万级文档中筛选出候选文档,确保处理速度的同时,初步缩小了检索范围。
重排序阶段:引入学习排序(LTR)模型,该模型基于文本特征及语义相似度,对候选文档进行精细排序,进一步剔除不相关项,筛选出更少但更精准的文档。
精排阶段:利用排序大模型进行深度优化。此模型擅长处理复杂的交互特征和上下文信息,确保从剩余文档中挑选出最优解,为用户呈现最满意的搜索结果。
通过上述分阶段优化策略,我们不仅提升了整个召回排序环节的效率,还显著增强了结果的准确性和用户满意度。
“
召回阶段
召回阶段被划分为文本召回与语义召回两大环节,旨在从大量的数据中尽可能多地筛选出包含答案的文本。
文本召回:依托经典排序算法如BM25,高效筛选文本,侧重于关键词匹配,确保基础召回率。
语义召回:则深入探索查询的深层意图与文本的语义内容,利用先进的向量表示模型(双塔模型),实现更智能、更精准的召回。此策略虽在召回效果上限上或有所保留,但凭借其飞速的响应能力,成为召回阶段的优选方案。
具体实现流程如下:
文档预处理:用户上传文档后,系统自动运用双塔模型将文档转化为向量,并计算其他关键文本特征,随后将这些信息高效存储于数据库中,供后续用户查询匹配。
查询向量化:一旦用户发起查询请求,系统即刻将查询内容同样转化为向量形式,为接下来的精准匹配做好准备。
高效匹配:系统迅速在数据库中遍历,基于向量相似度及文本特征的双重考量,筛选出与用户查询高度契合的文档集合。此过程既保证了召回的速度,又兼顾了召回的质量。
“
重排序阶段
进入重排序阶段,系统的核心目标在于对召回阶段筛选出的候选文本进行深度提炼与精准排序。随着搜索技术的演进,从传统的关键词匹配网页,如“北京旅游攻略”,到现代大模型驱动的语义化查询,如“三天两晚北京游,推荐必去景点?”,用户的搜索需求日益复杂多样。
为了让搜索系统能力尽可能通用,我们需要兼容传统的关键词查询和语义化的查询。双塔模型可以捕捉复杂语义关系,而单塔模型则在初筛基础上强化了结果的相关性排序。然而,单一模型难以全面覆盖所有场景,因此,我们引入了LTR(Learning To Rank)模型作为桥梁,巧妙融合语义特征与经过时间验证的文本统计特征。
我们的重排序模型集成了三大关键要素:
单塔语义特征:使用预训练的单塔模型来计算查询和候选文本之间的语义相似度。
传统排序特征:保留TF-IDF、BM25等传统排序技术,确保在关键词主导的传统查询场景中依然保持卓越表现。
内容质量特征:多维度考量文本长度、结构合理性、更新时效性等,全方位评估内容质量。

最终,LTR模型以其强大的学习能力,智能地平衡并优化上述特征之间的非线性关系,自动调整各特征权重,使重排序模型能够灵活应对关键词查询与语义化查询的双重挑战。无论是简明的关键词搜索,还是复杂的语义化需求,我们的系统都能提供精准、高效的排序结果。
“
大模型精排阶段
在重排序阶段之后,进入大模型精排阶段。精排阶段的主要目标是通过参数量更大的模型进一步提高相关性,以提供更优质的搜索结果。
在此阶段,我们聚焦于搜索系统在大模型窗口长度内检索的召回率。针对此,我们设计了以下两种策略进行对比分析:
单一策略:直接应用大模型对百万级的文档段落进行精排,省去了重排序环节。
协同策略:先通过重排序阶段筛选出十条文档段落,再交由大模型进行深度精排。
实验数据显示:协同策略不仅将召回率显著提升了5%,而且执行速度只有单一策略的34.77%。这表明,将重排序与大模型精排有机结合,能够有效筛选出高质量候选文档,并在此基础上通过大模型的精细处理,实现系统效率与效果的双赢。
RAG模型通过整合检索信息与生成能力,显著提升了回答的准确性和丰富性。然而,在复杂的多轮对话环境中,RAG面临诸多挑战,尤其是query的省略与指代问题,这些都源于用户查询与对话历史的紧密关联性。当前轮查询若孤立处理,常因缺乏上下文而难以有效检索,进而影响回答质量。
省略现象:用户可能省略关键上下文,如直接询问“如何解决”,而具体待解问题需回溯对话历史。此外,也存在完全脱离历史的独立性问题,需结合上下文判断其意图。
指代模糊:代词或指代词(如“那个地方”、“他们”)的频繁使用,要求系统具备强大的上下文理解能力以明确指代对象。
针对上述问题,我们聚焦于通过改写查询以融入必要上下文信息,并提出以下解决思路:
数据构建与优化
生成多轮问答数据:利用LLM(大型语言模型)生成覆盖各种不同场景与主题的对话数据,特别设计包含省略、指代及独立问题的对话轮次,以增强数据多样性。
基于COT的改写:采用思维链(Chain-of-Thought)技术,先解析查询的实际意图,再精准改写,确保改写后的查询包含完整的上下文信息。
模型训练与集成
LoRA训练法:采用LoRA(Low-Rank Adaptation)方法独立训练各任务模型,生成专属的LoRA参数组。
Multi-LoRA在线推理:将多组LoRA参数挂载于同一LLM底座上,实现多任务共享底座而互不干扰的高效推理机制。
我们构建了包含省略、指代及独立问题等多类场景的测试数据集,并通过人工评估验证了改写模型的效果。结果显示,改写准确率高达94%,同时LoRA与全参数微调(Fully SFT)在性能上展现出相近的优异表现。
综上所述,通过精心设计的数据构建策略与高效的模型训练方法,我们成功克服了RAG模型在多轮对话中的关键挑战,显著提升了系统的上下文理解与回答能力。
在自然语言处理(NLP)的广阔领域中,高效解析与理解文档是实现信息检索和问答系统的关键步骤。然而,面对多样化的文档格式,尤其是表格数据,其结构的复杂性与多样性给文本统一表示带来了巨大挑战。表格数据在预处理过程中易出现错位、粘连等问题,导致与预训练阶段的表格表示产生显著差异,进而影响模型的表格理解及问答系统的整体效能。
表格文本表示的复杂性:
无标记文档的挑战:PDF等无标记文档中的表格结构化信息易受损,需依赖预处理工具如PDF解析器进行提取,但不同解析器的性能差异导致表格表示的不一致性,影响模型表现。
表格类型的多样性:垂直、水平、嵌套及复杂表格各具特色,尤其是复杂表格的灵活表头位置及层次化文本表示,对模型的理解能力构成严峻考验。
垂直表格:
嵌套表格:

复杂表格:

表格理解的深度挑战:
即使表格解析与表示正确,复杂的文本内容及细粒度的语义差异亦对模型提出了更高要求。例如,在包含多个相似表格的文档中,准确识别并回答问题所需的具体表格内容成为难题。
那如何在不牺牲底座模型其他能力的前提下,针对性地增强其对表格数据的理解和问答能力。通过深入分析表格文本表示的复杂性及模型理解表格的难点,我们提出了一系列创新策略,旨在实现表格问答能力的显著提升,同时保持模型的全面性能稳定。
优化表格文本表示:
引入先进的预处理技术,提升无标记文档中表格的解析精度与一致性。
针对不同类型表格设计定制化解析策略,确保表格表示的准确性与完整性。
增强表格理解能力:
构建高质量训练数据:通过收集多样化的文档数据(包括个股研报、行业研报等),结合高效的解析工具与筛选规则,生成丰富的表格文本表示。
利用大规模语言模型与智能Prompt框架:采用如self-instruction、evolve instruction等先进方法,生成多样化的高质量问题,构建全面的监督训练数据集。
实施精细化监督微调(SFT):在保持模型整体架构不变的基础上,针对表格问答任务进行精细化SFT,确保模型在提升表格问答能力的同时,不损害其他能力。
参数集成策略:
在SFT后,按比例丢弃部分参数更新值,并调整剩余更新值以保持其分布特性,最后与原始模型参数加权融合,从而在不牺牲广泛能力的前提下,赋予模型更多专项微调能力。
通过实施上述策略,我们预期能够在显著提升底座模型表格问答能力的同时,保持其整体性能的稳定性。
利用大语言模型进行zero-shot提问时,我们常采用Baseline方法结合prompt。这类模型,得益于广泛的语料预训练与对齐训练,具有较好的文本理解力与指令跟随能力。在此基础上,我们可直接构建prompt来发起查询。
以Baseline-middle模型为例,虽其性能强劲,但在处理特定任务(如解析表格数据以读取EPS)时,仍可能受限于表格信息的不完全准确性,导致如“无法回答,输出为'nothing'”的响应。这凸显了模型在理解表格格式上的局限性。
prompt例子和对应原文如下:

为增强模型在特定领域的表现,supervised fine-tuning(SFT)成为关键策略。在baseline模型基础上实施SFT,关键在于构建高质量的input-output对,这要求输入数据的多样性与输出结果的准确性并重。
为增强模型在特定领域的表现,supervised fine-tuning(SFT)成为关键策略。在baseline模型基础上实施SFT,关键在于构建高质量的input-output对,这要求输入数据的多样性与输出结果的准确性并重。
为了验证不同模型在处理表格及非表格数据上的性能,我们设计了以下实验。
首先,我们从广泛的文档来源(包括个股研报、行业研报、宏观研究报告、策略报告、财报及年报)中筛选出了包含表格的文本段落,构建了表格测试集。同时,从办公文档数据中提取非表格文本,构建了非表格问题测试集。
接着,我们采用了以下几种模型配置进行测试:
Baseline-small:小参数量模型作为语言模型,使用上述prompt。
Baseline-middle: 中参数量模型作为语言模型,使用上述prompt。
Table-Model-small:小参数量模型经过表格全参数微调之后的模型,使用上述prompt。
Table-Model-Merge-Small: Table-Model使用了模型融合方法之后的模型。使用上述prompt。
Table-Model-Merge-Middle: 经过表格全参数微调之后,并且使用了模型融合方法之后的模型。使用上述prompt。
实验结果如下表所示:
数据集 | 表格测试集正确率 | 非表格问题测试集正确率 |
Baseline-small | 87.05% | 86.48% |
Table-Model-small | 96.47% | 83.78% |
Table-Model-Merge-Small | 95.29% | 85.28% |
Baseline-middle | 91.76% | 87.3% |
Table-Model-Merge-Middle | 96.47% | 90.09% |
从实验结果中,我们可以得出以下关键发现:
表格微调的有效性:无论是无论是Small还是Middle模型,经过表格全参数微调后,在表格测试集上的表现均有显著提升,证明了SFT对于特定领域任务优化的有效性。
模型规模与提升幅度:较小规模的模型在微调后获得的性能提升更为显著,反映出其基础能力较弱,更易于通过SFT实现性能提升。
非表格问题上的表现:微调后的模型在专注于表格理解的同时,不可避免地牺牲了部分非表格问题的处理能力。然而,通过模型融合技术,我们观察到Small模型在非表格问题上的表现有所恢复,而Middle模型更是在融合后实现了非表格问题处理能力的进一步提升,这表明融合策略有助于平衡模型的广泛性与专业性。
综上所述,本次实验不仅验证了表格微调对模型性能的积极影响,还探索了通过模型融合技术缓解特定领域优化带来的泛化能力下降问题的有效途径。
深度问答是自然语言处理(NLP)技术,对复杂问题进行深入分析和理解,并提供准确、全面以及深度答案的过程。这种问答系统不仅能够回答简单的事实性问题,还能够整合多个信息源,进行推理、分析和综合,以应对需要深度理解的查询。
尽管标准问答系统的答案准确度已显著提升,但在面对需要深度解析的复杂问题时,现有大模型往往难以直接给出完整、有深度的答案。这主要源于以下几个难点:
深度问答框架构建:如何确保答案内容完整且符合用户阅读习惯。
效果优化:如何协调多个处理环节,以达到最优问答效果。
速度考量:在资源有限的情况下,如何保持高效的推理速度。
为了应对上述挑战,我们采用了一种纯自动化的Multi-Agent流程,包括Planner、素材检索(API 1)、大纲生成(API 2)、答案生成(API 3)及结果拆解(API 4)等模块。此外,通过LoRA SFT + Multi-LoRA inference方案,我们实现了能力的有效整合与部署,显著提升了模型的灵活性和效率。
效果对比与评估
深度问答 vs 标准问答:深度问答在答案的广泛性和深入性上表现出色,远超标准问答系统。
LoRA SFT vs 全参数SFT:LoRA SFT之后采取Multi-LoRA的推理方式,在多个评价维度上(如语义相关性、流程有序性、主题深入程度等),单个能力的LoRA SFT效果与全参数SFT相当或更优,且无需考虑合并能力的全参数SFT引入的数据平衡问题。
我们以“大纲生成”、“子标题内容生成”为例,通过GPT4打分对比一下效果:
定义6个维度,以衡量生成大纲的好坏:

语义相关性 | 流程有序性 | 主题深入程度 | 主题重复程度 | 层次结构 | 匹配程度 | |
单个能力全参数sft | 98.7 | 88.7 | 87 | 97.3 | 92 | 95.5 |
合并能力全参数sft | 97.7 | 90.7 | 81.3 | 92.7 | 89 | 97.7 |
单个能力lora | 99.0 | 91.7 | 86.3 | 94.3 | 90 | 97 |
六个维度合并总分占比情况:
分数区间 | 单个能力全参数sft | 合并能力全参数sft | 单个能力lora |
[95,100] | 30% | 34% | 27% |
[90,95) | 50% | 53% | 60% |
[85,90) | 20% | 10% | 13% |
[0,85) | 0 | 3% | 0 |
大纲生成:在GPT4的打分下,LoRA SFT在多数维度上得分高于全参数SFT,特别是在语义相关性、流程有序性等方面。
从单个子标题内容的质量以及所有子标题内容之间的逻辑两个方面进行打分。


子标题内容生成:LoRA SFT在内容质量、逻辑性、重复性等维度的平均得分也高于全参数SFT,证明了其在生成高质量答案内容方面的优势。
我们再通过澜舟智库看一下效果对比
标准问答:
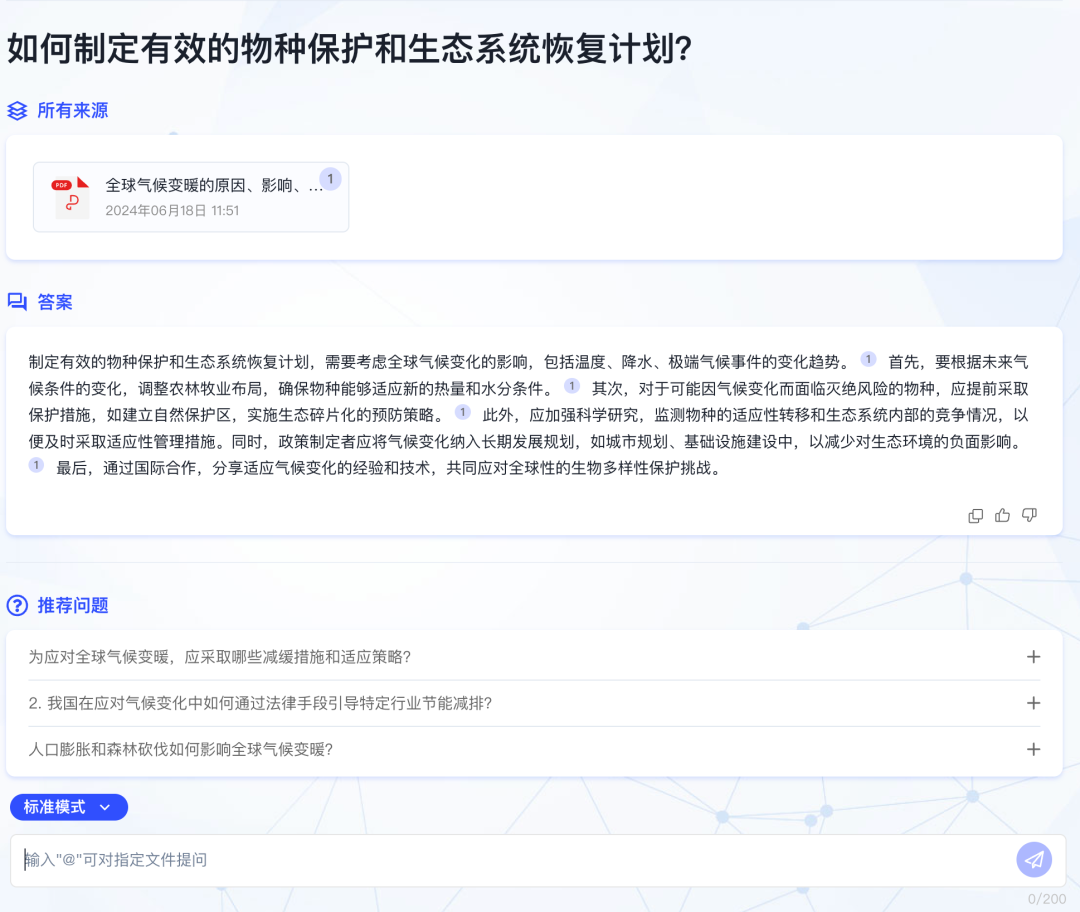
深度问答:

通过引入深度问答技术和优化方案,我们不仅能够应对复杂问题的挑战,还能在保持高效推理速度的同时,提供更为准确、全面且富含深度的答案。
答案溯源技术,旨在精准定位答案中每一句话的原文出处,不仅强化了答案的可信度,还极大地方便了用户的核查与对比。
当前,答案溯源的主流架构分为两大流派:一是集成式,即大模型在回答时同步标注来源;二是分离式,即先生成答案,后独立溯源。鉴于分离式架构能有效解耦问答与溯源功能,便于独立优化且整体响应更快,我们决定采用后者,独立开发答案溯源模块。
答案溯源本质上可视为一种文本相似度评估或语义匹配任务,其核心在于从海量文本中精准筛选出与答案高度匹配的原文句子。
主流的文本匹配算法有三类:
基于ngram与关键词的字面匹配,虽简单直接但深度有限;
向量驱动的分类式语义匹配,以高效著称;
而大模型驱动的生成式语义匹配,则以其强大的理解与生成能力见长。
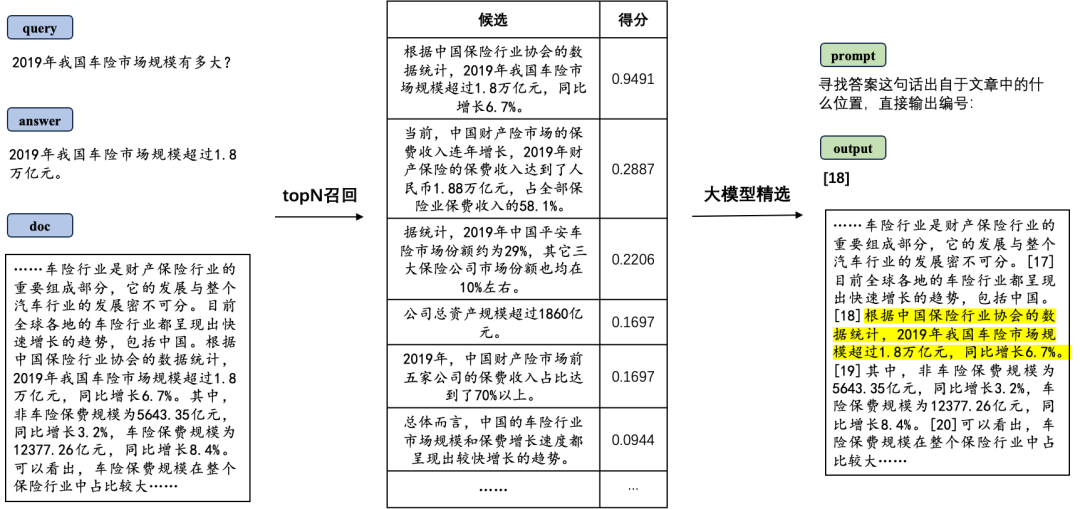
答案溯源整体流程
我们致力于探索一种策略,既能确保溯源的速度,又不失其精准度。为实现这一目标,我们设计了召回与精选相结合的两阶段策略。
在召回阶段,我们利用高效的ngram算法快速筛选出最有可能成为答案来源的句子集合,确保高召回率的同时,保持流程的快速响应。实验验证,当选取Top 80的句子时,召回率可轻松突破98%。
进入精选阶段,我们则对模型的语义理解与上下文把握能力提出了更高要求。为此,我们选定大模型作为核心工具,但直接应用通用模型效果不佳,且受few-shot learning与COT等技术影响,推理速度受限。因此,我们对大模型进行了针对性的SFT微调,专注于答案溯源任务,并在推理时采用zero-shot模式,仅输出句子标号,极大缩短了处理时间。最终,微调后的模型在保持f1值高达95%的同时,实现了单句答案溯源的时延控制在1秒以内的卓越性能。
澜舟智库,定位大模型时代企业智能知识库平台,集成多场景问答、智能搜索与AI辅助文档生成等功能,确保知识资产的安全性与高效利用。该平台的核心优势在于其知识搜索问答功能,深度融合大模型技术,实现了技术层面的全面革新与飞跃。通过引入RAG(Retrieval-Augmented Generation)技术、增强的多轮对话改写能力、针对表格数据的智能问答、深度语义理解问答以及答案的可信溯源等先进功能,澜舟智库有效解决了传统知识库面临的搜索精度不足、应用效率低下及内容生产缓慢等问题。

澜舟智库
澜舟智库不仅重塑了知识管理的格局,还极大地增强了企业挖掘、整合与利用知识资源的能力,为企业持续创新、科学决策注入了强大的智能动力。在AI2.0时代,澜舟智库正引领着企业智能知识库管理的新潮流,成为推动行业进步的重要力量。
扫码体验澜舟智库👇


”
澜舟科技官方网站
获奖与新闻
澜舟科技完成信通院“可信AI”评估
澜舟科技完成Pre-A+轮融资
HICOOL 2021创业大赛一等奖 | 周明博士专访
技术专栏一览

期待您的关注与加入:)
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢