

新智元报道
新智元报道
【新智元导读】是时候用CPU通用服务器跑千亿参数大模型了!
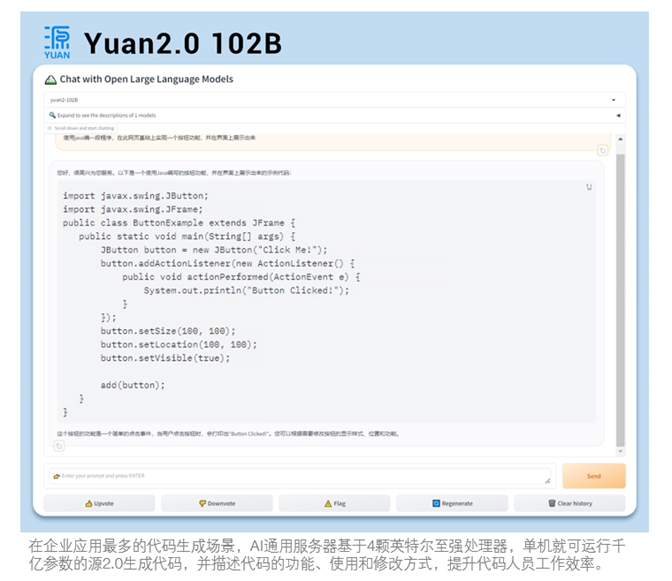
面对用Java编写程序的代码任务,「源2.0」非常迅速地给出了结果。
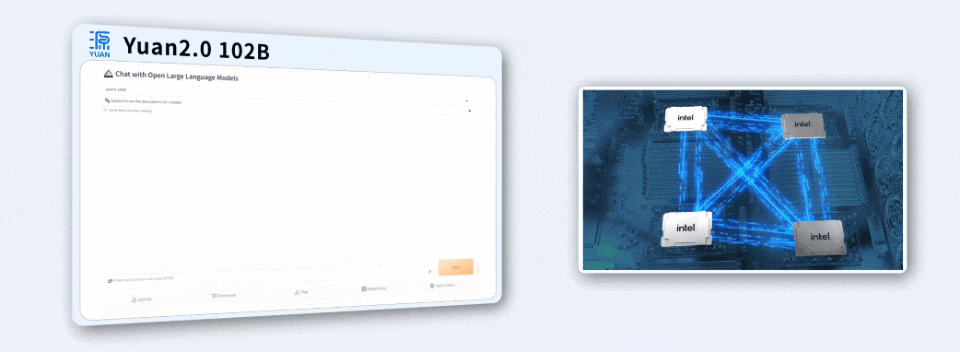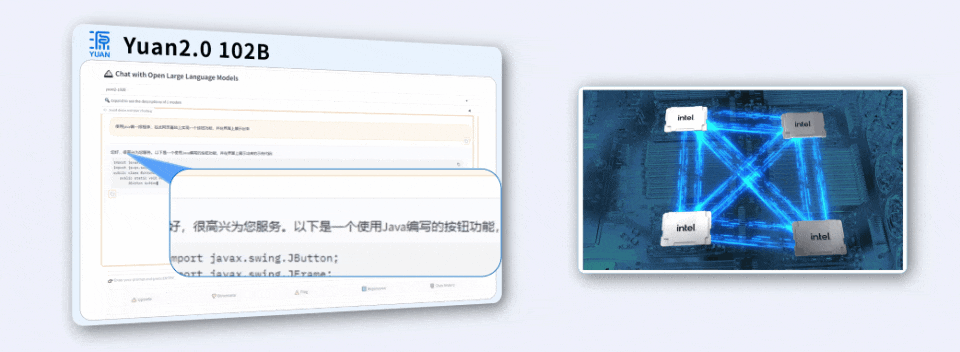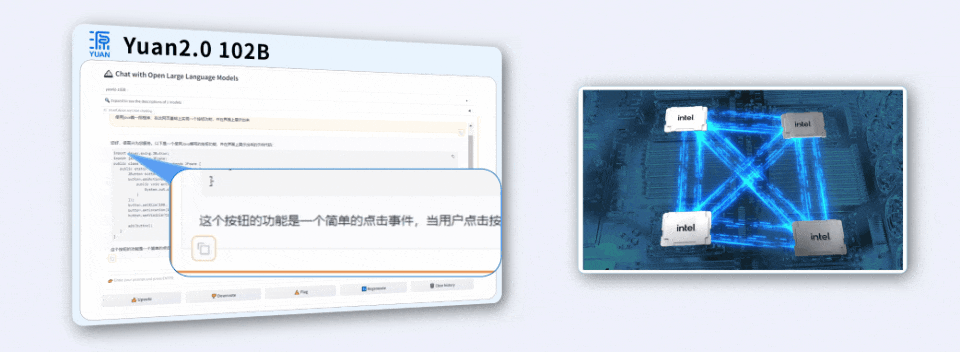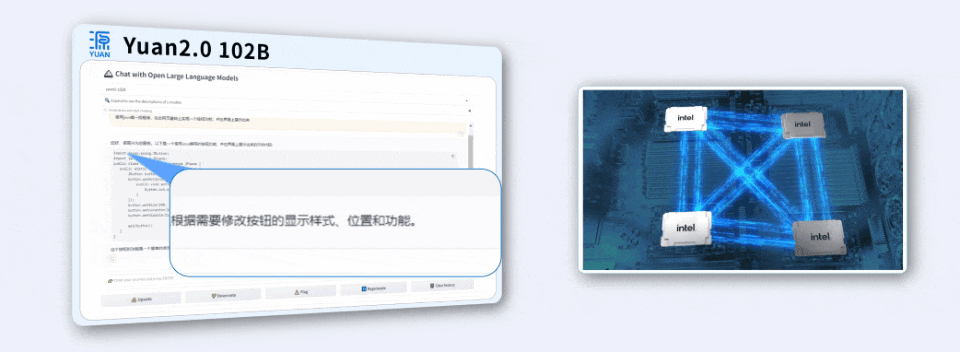
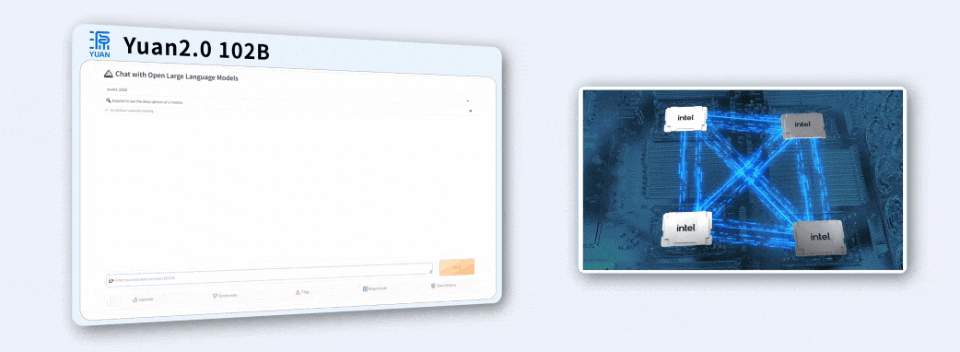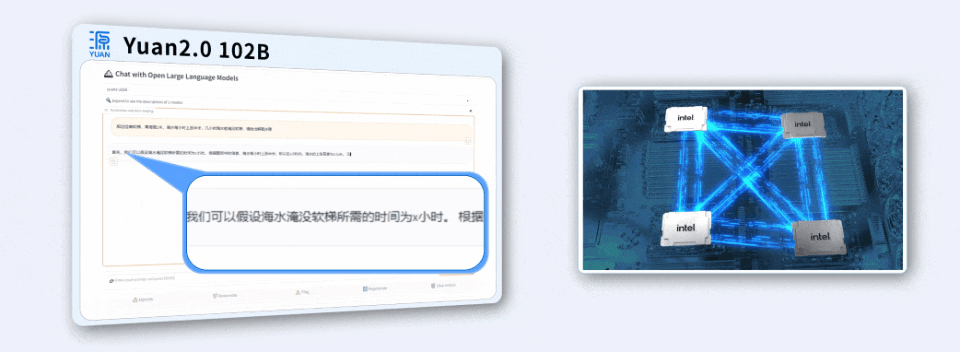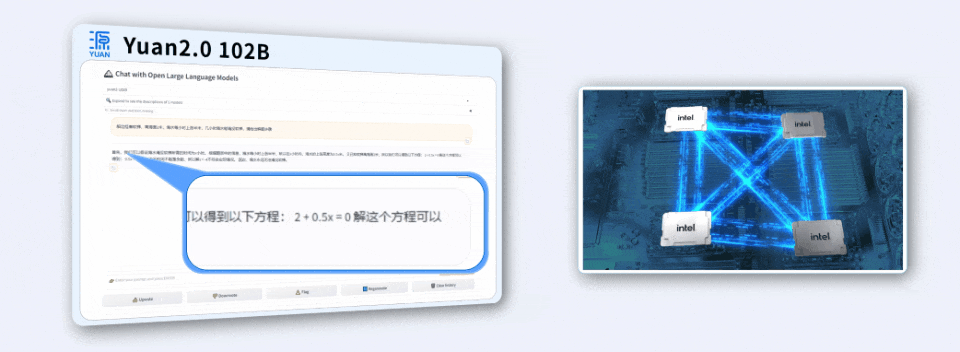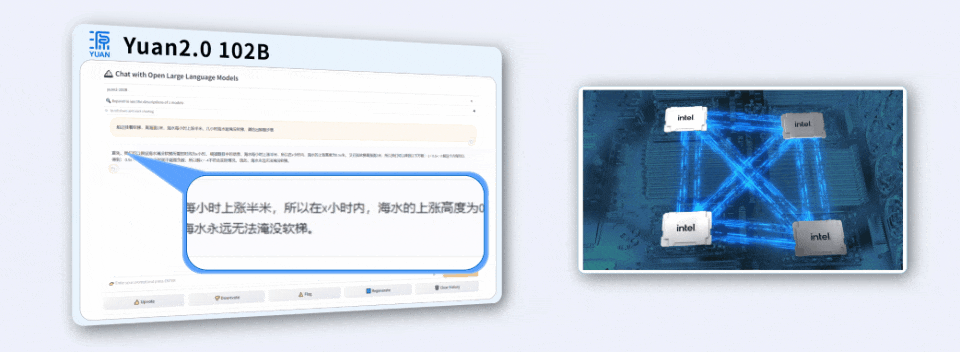
用4颗CPU,撬动千亿参数大模型
若要在单台服务器中,实现千亿参数大模型的推理,包含了2个主要阶段,均对计算能力提出了硬性需求。 首先,是预填充阶段,也叫做前向传播阶段。 这一阶段涉及到输入数据的处理、模型参数第一次读取。 比如,当你输入「给我写一篇有关AI的文章」提示,预填充阶段便会将问题中所有token、模型参数,一次性输入计算。 有时,这一输入可能是几个字,也可能是几千个字,或者是一本著作。 第一阶段的计算需求有多大,主要取决于我们输入的长度。 而在计算第一个token过程中,由于模型首次加载,会在内存中存放全部的权重参数,以及KV Cache等数据。 这是模型参数本身所占内存空间的2-3倍。 对于千亿参数模型来说,大量的参数和数据输入,需要在强大计算单元中处理。对此,它需要支持向量化指令集、矩阵计算指令集,来实现大量的矩阵乘法和张量运算。 其次,是解码阶段,即在问题全部输入之后,模型开始输出结果的阶段。 在这个阶段,对大模型唯一要求便是,输出尽可能快。同时,挑战不再是算力挑战,转而为「数据搬运」的挑战。 它包含了两部分「数据搬运」: 预填充阶段生成的大量KV Cache,需要从显存/内存,搬运到计算单元中(工作量非常大) 模型参数本身的搬运
这些搬运对大模型的计算和推理速度,起到了一个决定性的作用。数据搬运很快,LLM吐字的速度也会快。 LLM输出主要通过KV Catch,逐一生成token,并在每步生成后存储新词块的键值向量。 因此,千亿大模型的实时推理,服务器需要具备较高的计算能力,以及较高的存储单元到计算单元的数据搬运效率。 总而言之,在大模型推理的两阶段中,有着截然不同的计算特征,需要在软硬件方面去做协同优化。
模型参数本身的搬运
GPU不是万能的

被低估的通用服务器
超大内存+高速带宽
算力方面,目前领先的服务器CPU都已经具备了AI加速功能。
类似于GPU的Tensor core,AMX高级矩阵扩展可以将低精度的计算做加速,编成指令集给CPU的核,利用专用的核做加速。
算法方面,浪潮信息的通用服务器可同时支持PyTorch、TensorFlow等主流AI框架,以及DeepSpeed等流行开发工具,满足了用户更成熟、易部署、更便捷的开放生态需求。
通信方面,全链路UPI(Ultra Path Interconnect)总线互连的设计,则实现了CPU之间高效的数据传输:
允许任意两个CPU之间直接进行数据传输,减少了通信延迟 提供了高传输速率,高达16GT/s(Giga Transfers per second)
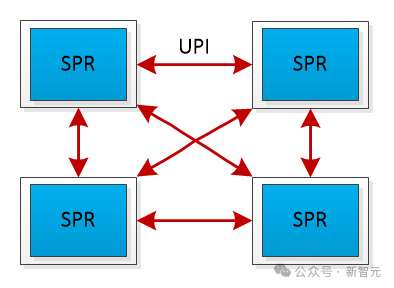
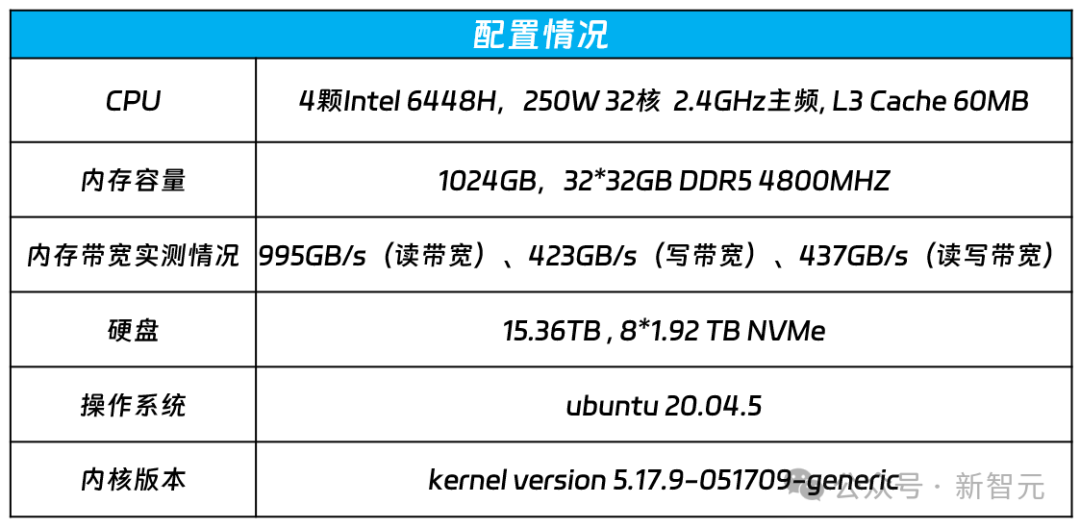
内存方面,可以说是通用服务器的最大优势了。
容量
带宽
但仅靠硬件远远不够
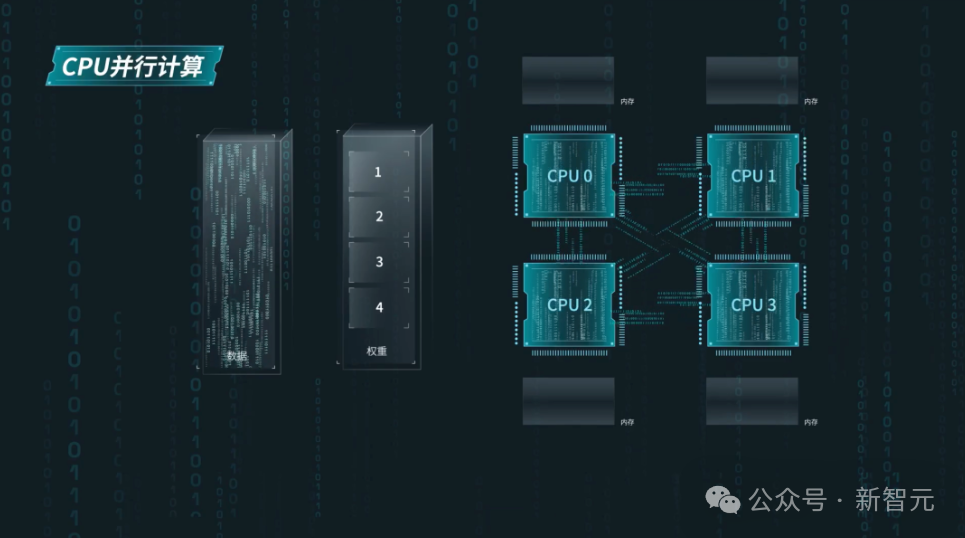
仅仅依靠硬件创新,是远远不够的,CPU很难进行大模型算法的大规模并行计算。 正如开篇所述,大模型对通信带宽的要求是非常高的,无论是数据计算、计算单元之间,还是计算单元与内存之间。 如果按照BF16精度计算,想要让千亿大模型的运行时延小于100ms,内存和计算单元之间的通信带宽,就至少要达到2TB/s以上。 不仅如此,对于基于擅长大规模并行计算的加速卡设计的AI大模型,通用服务器的处理器与之并不适配。 原因很明显:后者虽然拥有高通用性和高性能的计算核心,但并没有并行工作的环境。 通常来说,通用服务器会将先将模型的权重传给一个CPU,然后再由它去串联其他CPU,实现权重数据的传输。 然而,由于大模型在运行时需要频繁地在内存和CPU之间搬运算法权重,这样造成的后果就是,CPU与内存之间的带宽利用率不高,通信开销极大。 
如何解题?用算法创新
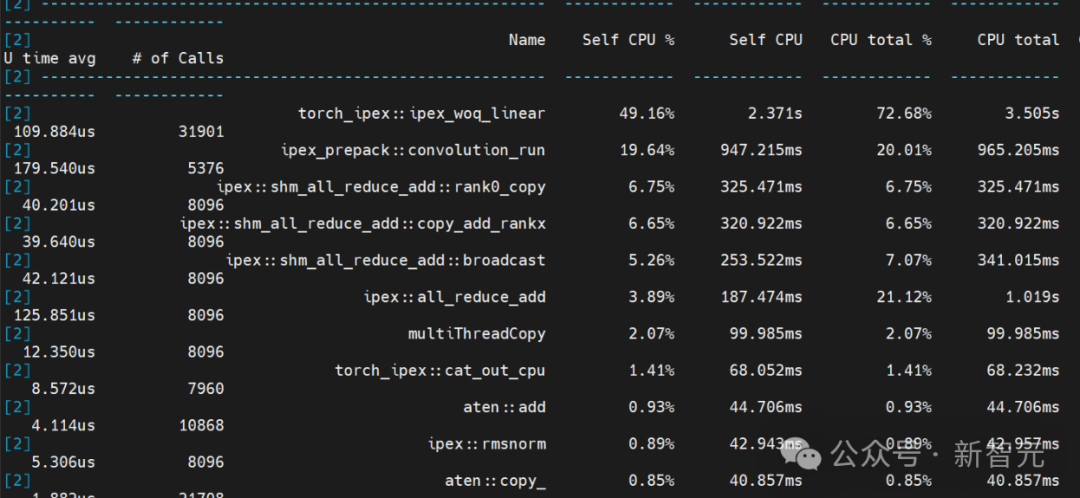
线性层运行时间占比50%,卷积运行时间占比20%,聚合通信时间占比20%,其它计算占比10%。
张量并行
NF4量化

所谓通用,就是让大家都用上



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢