
今年MoE模型扎堆发布,至今已有近20个!苹果、昆仑万维、字节都在做MoE研究,连小米汽车也做了多模态MoE大模型做汽车智能中控。MoE实火! MoE在应对各种大模型复杂挑战方面的适应性、效率和准确性,及使用多维数据的场景中非常有用!
综上,冲顶会发论文【大模型方向】,【MoE模型高效调优】,【多模态大模型】方面的选题和创新点都是好选择!
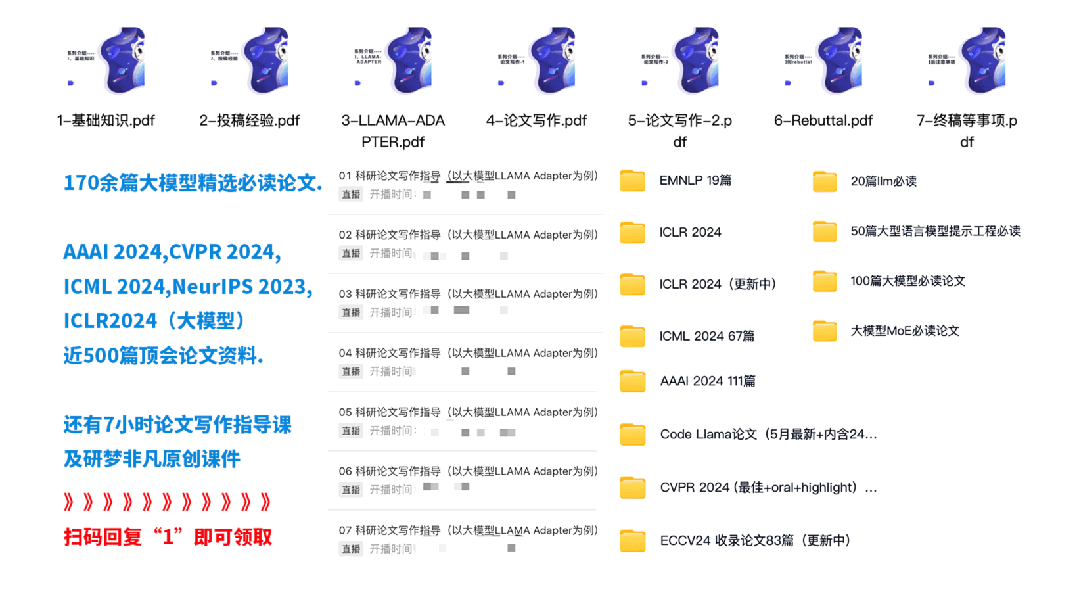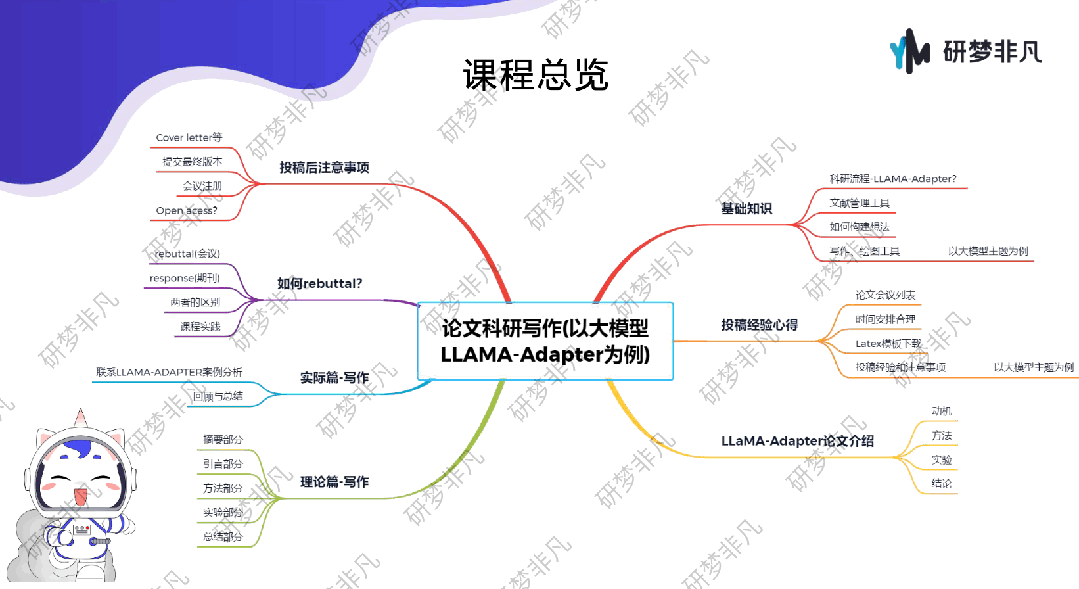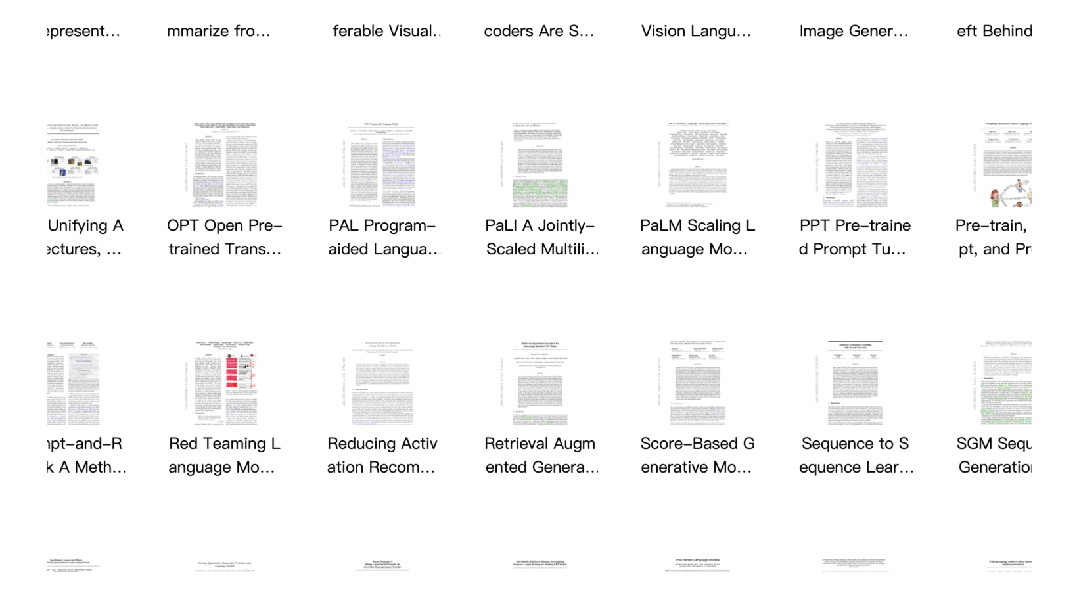
为此给大家准备了170余篇大模型精选必读论文,AAAI 2024,CVPR 2024,ICML 2024,NeurIPS 2023,ICLR2024(大模型)近500篇顶会论文资料, 还有7小时论文写作指导课,配套学习效果更佳,全都免费!
扫码回复“1”领论文和课程资料
(文末还有6重冲顶会免费领福利)

全面理解掌握MoE模型工作!掌握找顶会论文创新点技能! 8月9日研梦非凡精心制作了《AI前沿直播课NO.59:大模型SOTA-MoE模型讲解》从MoE的研究背景、MoE模型前世今生、模型结构、实验对比,代码实战等重难点讲解。
免费扫码预约直播👇

精选论文: 《Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning》
将专家组合推向极限:用于指令调优的极其参数高效的 MoE
一、论文研究背景
大模型中的挑战-MoEs在扩展时面临参数数量激增的问题。
提高参数效率; 指令调优; 泛化能力提高; 计算需求和内存效率; 优化挑战。
更新不到1%的参数来微调密集模型; 在不同尺度上保持高参数效率; 显着降低了计算成本。
二、知识储备“前世今生”
IA3 LoRA Mixture of Experts (MOE)
三、MoV/MoLora
对先前工作已经指出的MoE固有的优化挑战 矢量混合(MoV)和LORA混合(MoLORA) 对专家混合方法的参数高效改编
四、实验详解
数据集;实验设置;Baseline;计量指标;基础设施。
三组消融 路由策略
五、相关工作
六、代码讲解实现

扫码找助教免费预约直播➕论文领福利

ps:研梦非凡开设的前沿论文系列直播,旨在帮助大家提升读论文技能,快速抓住重点,掌握有效方法,进而找到创新点,轻松完成目标区位论文。
🌟90分钟人工智能零基础入门课免费领
🌟7小时科研论文写作系列课免费领
🌟原价2999年度会员福利价129元
🌟50小时3080GPU算力免费领
🌟百篇8月论文资料大合集免费领(不包括开头论文资料)
🌟报名本次直播课,即可福利价享受原价2999元的1小时导师meeting(助教+导师)!
👇🏻扫码领取以上6重粉丝专属科研福利!
如何快速找到idea,如何正确的选择模型,怎么避免与其他工作重复, 什么样的实验计划省时效果显著,一边实验一边出论文初稿技能,针对不同的期刊会议绘图方法,终稿完善,投稿策略,期刊/会议选择,response,直到accpet!研梦非凡全程陪伴你产出科研成果!


<<< 左右滑动见更多 >>>

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢