
DRUGAI
今天为大家介绍的是来自Fabian Kiessling团队的一篇论文。基础模型在大规模预训练后,在非医学领域展示了显著成功。然而,训练这些模型通常需要大规模、综合的数据集,这与生物医学影像领域中常见的小型且专门的数据集形成对比。作者提出了一种多任务学习策略,该策略将训练任务的数量与内存需求分离。作者在一个包含断层成像、显微镜图像和X光图像的多任务数据库上训练了一个通用的生物医学预训练模型(UMedPT),采用了分类、分割和目标检测等多种标注策略。UMedPT基础模型的表现优于ImageNet预训练和之前的最先进模型。在与预训练数据库相关的分类任务中,它在仅使用1%的原始训练数据且不进行微调的情况下保持了其性能。而在域外任务中,它仅需要50%的原始训练数据。在外部独立验证中,使用UMedPT提取的影像特征证明在跨中心转移能力方面设立了新的标准。

随着预训练数据集规模的日益增大,生物医学影像中对基础模型的需求变得清晰。然而,有效预训练深度神经网络需要大量标注的训练数据,而这些数据在生物医学影像中往往是稀缺的。尽管在生物医学领域存在许多公共的小型和中型数据集,但没有一个单一的预训练数据集可以与ImageNet或LAION相比。
针对数据稀缺问题,已经提出了几种解决方法。一种方法是使用自监督学习,通过解决预设任务从未标注数据中学习视觉表示。然而,自监督预训练方法与标签监督预训练方法之间存在明显的性能差距。另一种方法是使用领域特定的监督预训练。例如,Zhou等人使用一个大规模的文本标注胸部X光数据集,训练出适用于胸部X光的通用表示。他们在未见过的数据集上评估了该方法,发现他们的胸部X光编码器在应用于其他胸部X光分析任务时,准确率比ImageNet预训练高出10%。尽管如此,监督预训练只能应用于有大量训练数据的领域,如放射影像。
Mei等人提出将多个医学分类数据集合并为一个,用于放射学任务的深度网络预训练,往往表现优于ImageNet。然而,这种方法仅依赖分类标签,可能无法捕捉医学图像中的所有相关信息,并且要求网络预测合并数据集中无关或无意义的类别。
多任务学习(MTL)有望通过同时训练一个能在多个任务中泛化的单一模型,解决数据稀缺问题。它利用生物医学影像中的许多小型和中型数据集,结合不同的标签类型和数据源,预训练适用于所有任务的图像表示,从而在数据稀缺的领域中实现深度学习。MTL已在生物医学图像分析中得到各种应用,如在多个不同任务的小型和中型数据集上训练,具体限于分类或分割任务。此外,MTL还被用于单个图像的多种标签类型,证明共享不同标签类型的特征可以提升任务性能。
模型部分

图 1
在这篇文章中,为了将不同标签类型的多个数据集结合起来进行大规模预训练,作者引入了一种多任务训练策略和相应的模型架构,专门设计用来解决生物医学影像中的数据稀缺问题,通过学习跨多种模态、疾病和标签类型的多功能表示。为了解决大规模多任务学习中遇到的内存限制问题,作者的方法采用了一种基于梯度累积的训练循环,其扩展几乎不受训练任务数量的限制。在此基础上,作者训练了一个名为UMedPT的完全监督的生物医学影像基础模型,使用了17个任务及其原始标注。每个任务包含训练集和测试集,并具有其标签类型,例如分类、分割或目标检测。研究概述如图1所示。作为数据稀缺领域未来发展的基础,UMedPT为将深度学习应用扩展到特别难以收集大规模数据的医学领域(如罕见疾病和儿科影像)开辟了新的前景。
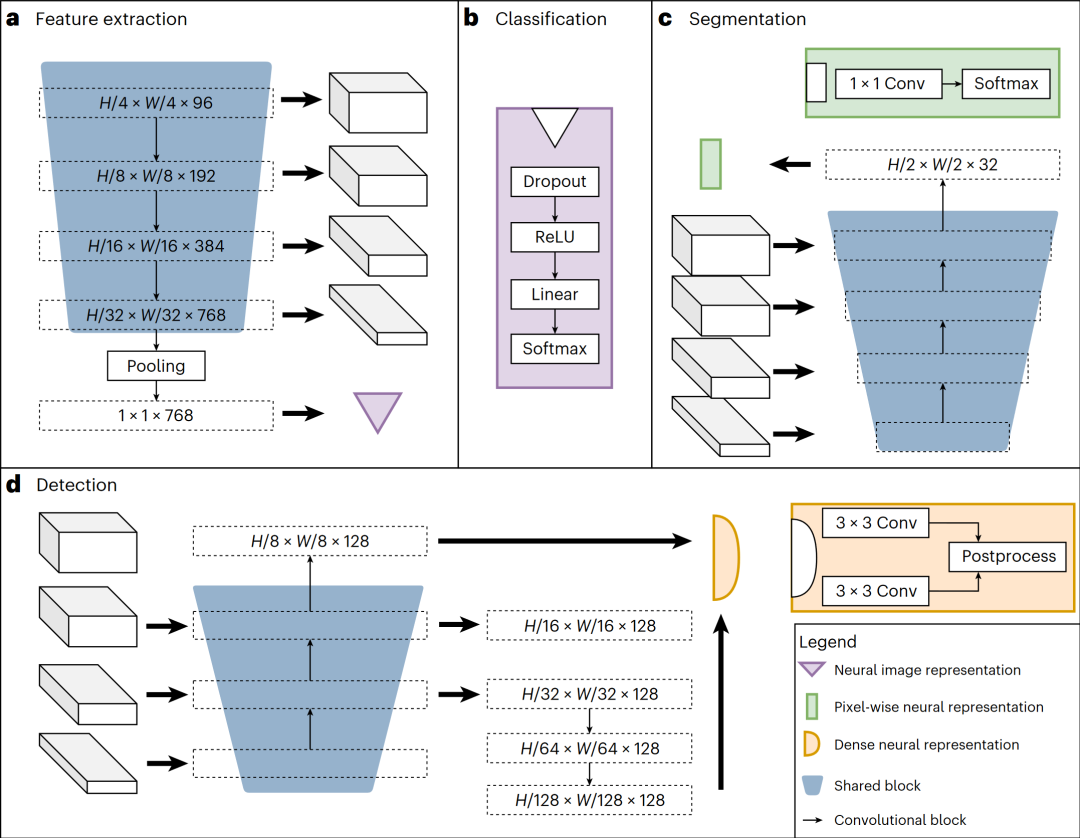
图 2
图2展示了作者神经网络的架构,包括共享模块(编码器、分割解码器和检测解码器)以及任务特定的头部。共享模块被训练为适用于所有预训练任务,以便提取通用特征,而任务特定的头部则处理标签特定的损失计算和预测。作者的任务包括三种监督标签类型:目标检测、分割和分类。例如,分类任务可以对二进制生物标志物建模,分割任务可以提取空间信息,目标检测任务可以用于基于细胞数量训练生物标志物。
实验评估设置
作者根据三个基准对模型进行了评估。第一个是“域内基准”,旨在确定UMedPT在与其预训练数据库密切相关的任务中的表现。第二个是“域外基准”,旨在评估UMedPT在其直接训练领域之外的新任务中的适应能力。第三个是MedMNIST基准,用于在一个独立的训练数据库上评估提出的多任务训练策略,并独立测试UMedPT。然后,作者将这些结果与之前发表的域内、域外和MedMNIST目标任务的最先进结果进行了比较。
在适用的情况下,作者在数据稀缺的场景中通过使用不同数量的原始训练数据(从1%到100%)训练UMedPT,并报告每个实验设置的五次重复运行的平均结果。所有网络都使用冻结编码器进行训练,随后在微调设置中使用相同的训练方案和超参数进行训练。
对于域内和域外的临床基准,作者进行了UMedPT的消融研究,调查了UMedPT可变输入图像大小与固定输入图像大小(224 × 224)的UMedPT-fixed,以及是否在其架构中包括可训练参数的层归一化(UMedPT-affine)的影响。研究发现,可变输入大小对UMedPT的性能有益,而UMedPT-affine对结果的影响较小。此外,作者还比较了UMedPT与仅用分类任务训练的变体UMedPT-clf的性能,结果显示,包含分割和目标检测任务尤其对其他类似任务有很大好处。
UMedPT与ImageNet基线在域内任务上的性能比较
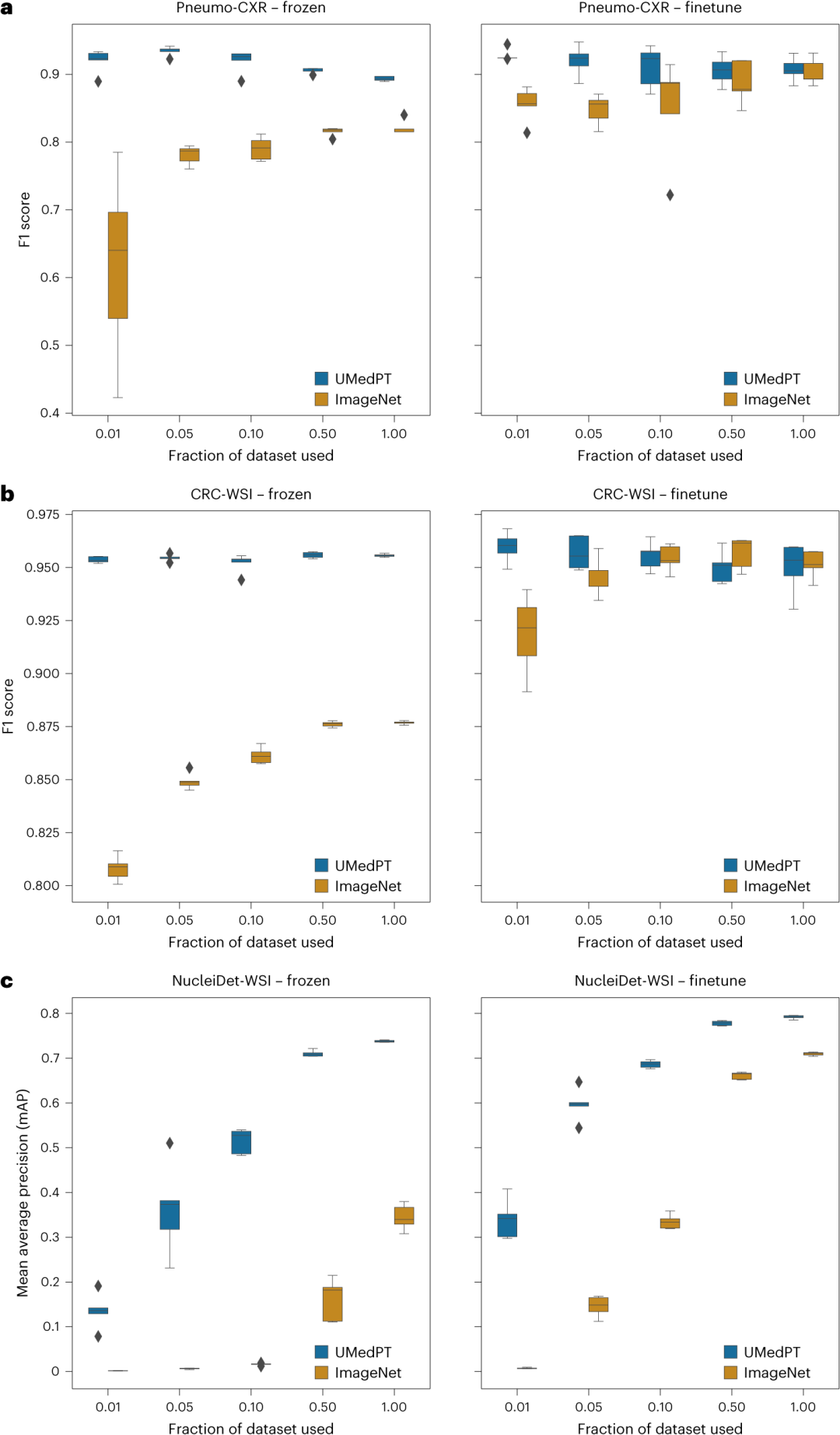
图 3
作者将UMedPT与在ImageNet-1K上预训练的权重所获得的结果进行了比较。在分类任务中,UMedPT仅使用1%的原始训练数据便能匹敌ImageNet基线在所有配置中的最佳表现。值得注意的是,如图3所示,UMedPT在编码器冻结的情况下表现优于微调后的模型。
在结直肠癌(CRC)组织分类(CRC-WSI)中,作者将显微镜全视野图像(WSIs)中的CRC组织分类为九种不同的类别,包括脂肪组织、正常结肠粘膜和结直肠腺癌上皮。在CRC-WSI中,ImageNet在使用所有训练数据并进行微调的情况下,在未见过的测试集上达到了95.2%的平均F1分数。而UMedPT在仅使用1%训练数据和冻结编码器的情况下,达到了95.4%的F1分数(见图3)。当训练数据集的大小增加到50%和100%并进行微调时,所有方法的结果趋于相同的F1分数。令人惊讶的是,对于UMedPT,增加训练数据量超过1%并未提高模型性能,有时反而会降低性能。值得注意的是,无论选择哪个1%,最终的性能都具有较低的方差。作者进一步调查了这是否是由于灾难性遗忘或过拟合导致的,发现这一现象是数据集特定的。
在Pneumo-CXR研究中,作者聚焦于诊断小儿肺炎。这里,UMedPT在所有数据集规模上均优于ImageNet。UMedPT的最佳表现是在使用5%的数据(约250张图像)和冻结特征的情况下,F1分数达到93.5%。ImageNet的最佳表现(F1分数90.3%,使用100%的数据)仅在使用最小分割(1%的数据,约50张图像)的情况下才被匹配。
作者使用NucleiDet-WSI数据集检测来自十种不同癌症类型的WSI中的细胞核。ImageNet的最佳表现是在使用100%的数据并进行微调的情况下,平均精度(mAP)达到0.71。UMedPT在使用50%的训练数据且不进行微调的情况下,能够复制这一性能。然而,微调往往能提高两个模型的结果。有趣的是,与ImageNet相比,UMedPT在所有数据比例上均表现优异,无论是微调还是冻结预训练模型。这在使用完整训练数据集并进行微调时,达到了0.792 mAP的最高性能。
UMedPT与ImageNet基线在域外任务上的性能比较
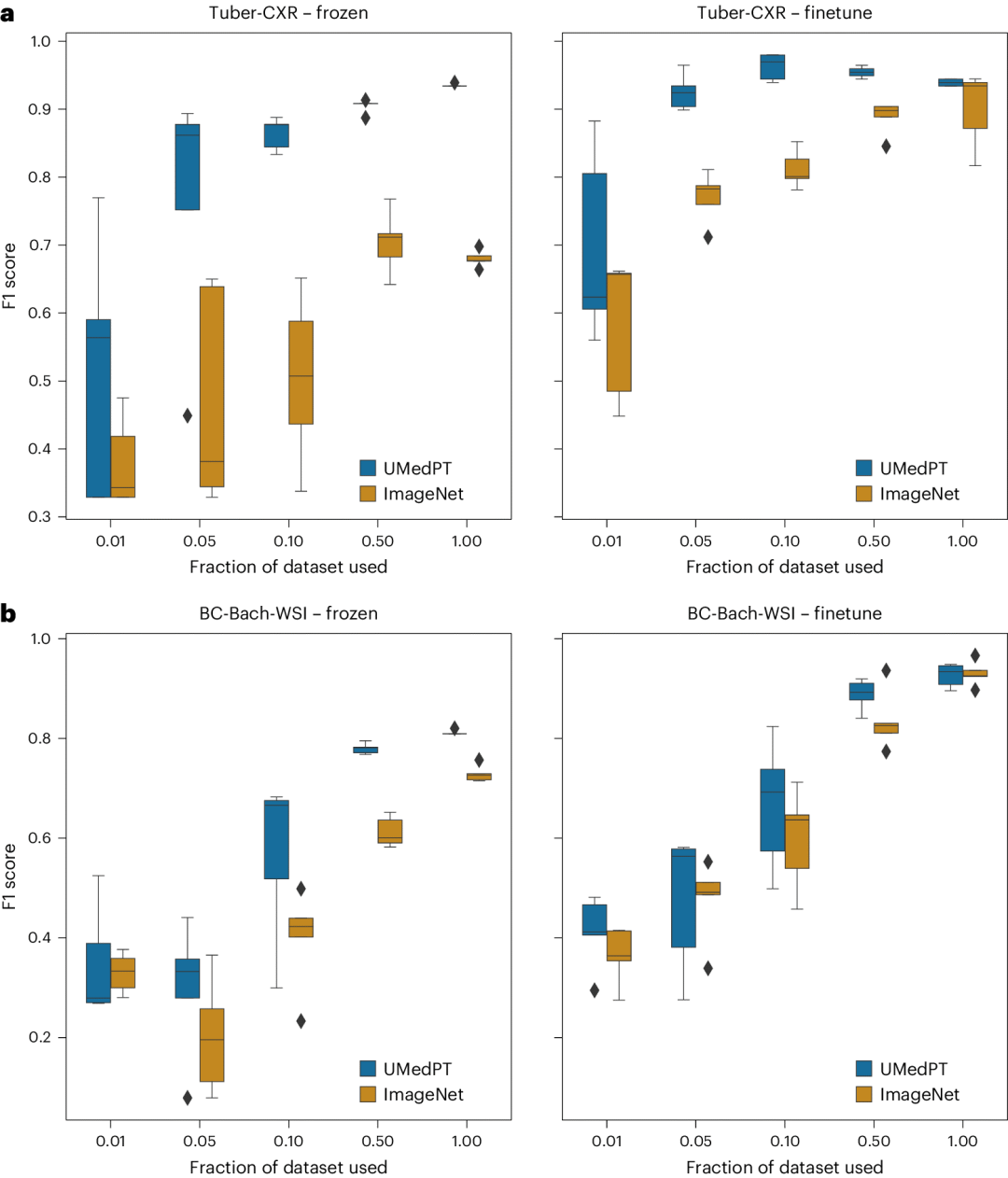
图 4
在域外基准测试中,UMedPT在编码器冻结的情况下,对所有分类数据集的数据量减少50%或更多时,仍能保持良好表现。通过微调,使用更多数据时,ImageNet的性能会持续提升。在五个数据集中的两个数据集中,UMedPT使用50%或更少的数据,甚至在微调的情况下,也能与ImageNet的性能相匹敌(图4)。以下是域外任务中的关键发现。
在从胸部X光片诊断肺结核的任务(Tuber-CXR)中,UMedPT通过微调模型并使用仅10%的数据,达到了最高平均F1分数96.3%。增加更多的训练数据并未进一步提高模型的得分(图4)。为了匹配ImageNet的整体最佳平均结果,UMedPT在微调时需要5%的数据,而在冻结编码器的情况下需要50%的数据。
作者使用CNS-MRI数据集训练系统,以从磁共振成像(MRI)扫描中诊断中枢神经系统(CNS)肿瘤。ImageNet在冻结特征的情况下,F1分数为89.0%。UMedPT使用5%的训练数据就能匹配这个得分。使用全部训练数据并进行微调后,UMedPT达到了最高F1分数99.3%。
BC-Bach-WSI数据集用于WSI中的乳腺癌分类。在冻结编码器的情况下,ImageNet的F1分数为72.9%。UMedPT使用50%的数据达到了这个分数,并最终获得了78.0%的F1分数。在这里,通过微调获得了最佳结果。
BC-BHis-MIC数据集用于显微镜(MIC)图像中乳腺肿瘤的良性和恶性分类。使用100%的数据和微调后,ImageNet和UMedPT均达到了98.4%的F1分数。在编码器冻结的情况下,ImageNet的F1分数为82.3%。UMedPT使用50%的数据也达到了这个分数。
PolypSeg-RGB数据集聚焦于结肠镜图像中的息肉分割。使用整个数据集进行微调时,ImageNet取得了最佳平均结果,平均交并比(mIoU)为0.905。UMedPT达到了0.911的mIoU。预训练使用ImageNet的模型在编码器冻结时表现更好,如扩展数据图1c所示。在所有数据比例中,UMedPT通过微调取得了最佳性能。此外,尽管UMedPT在所有数据比例中通过微调均优于ImageNet,但在使用1%的数据时优势最为明显(0.797 ± 0.09,相比之下ImageNet为0.683 ± 0.144)。
UMedPT与其他文献结果的性能比较
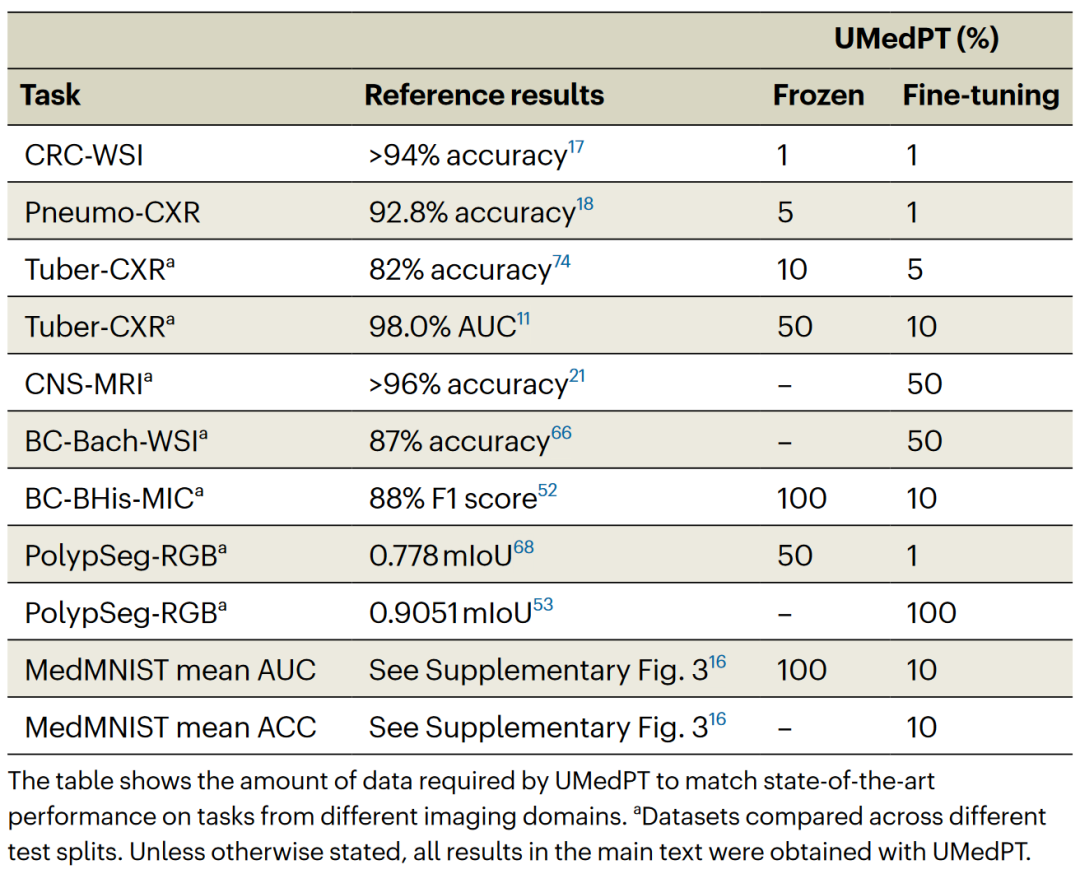
表 1
作者将UMedPT的性能与文献中报告的结果进行了比较。在使用冻结编码器配置时,UMedPT在大多数任务中都超过了外部参考结果。在这种情况下,它也优于MedMNIST数据库中的平均曲线下面积(AUC)。值得注意的是,在UMedPT冻结应用未能超过参考结果的任务中,涉及域外任务(乳腺癌分类BC-Bach-WSI和中枢神经系统肿瘤诊断CNS-MRI)。通过微调,UMedPT在所有任务中都超过了外部参考结果(表1)。
MedPT与2D多任务模型、3D单任务模型的性能比较
独立于上述训练数据库,作者在MedMNIST上评估了训练策略。MedMNIST包含多种标准化和缩小版的生物医学图像数据集,包括二维(2D)和三维(3D)图像。为了评估将本质上是3D的医学图像数据转换为2D切片进行预训练的影响,作者评估了使用2D数据的单任务学习、使用原始3D数据的单任务学习以及使用2D数据的多任务学习。对于多任务和单任务训练,作者通过最后一个维度将3D数据转换为2D切片。然后,作者应用了一种基于对切片表征进行加权平均操作的多实例学习分类任务。在只考虑3D任务时,平均准确率如下:使用ImageNet预训练的单任务学习:83.22 ± 1.61%;单任务MedMNIST 3D卷积神经网络(CNN):83.76%;多任务学习:86.46 ± 1.13%。
结果显示,单任务3D CNN比使用ImageNet预训练的单任务2D CNN表现更好。然而,多任务2D网络优于单任务3D CNN。详细信息见表2。
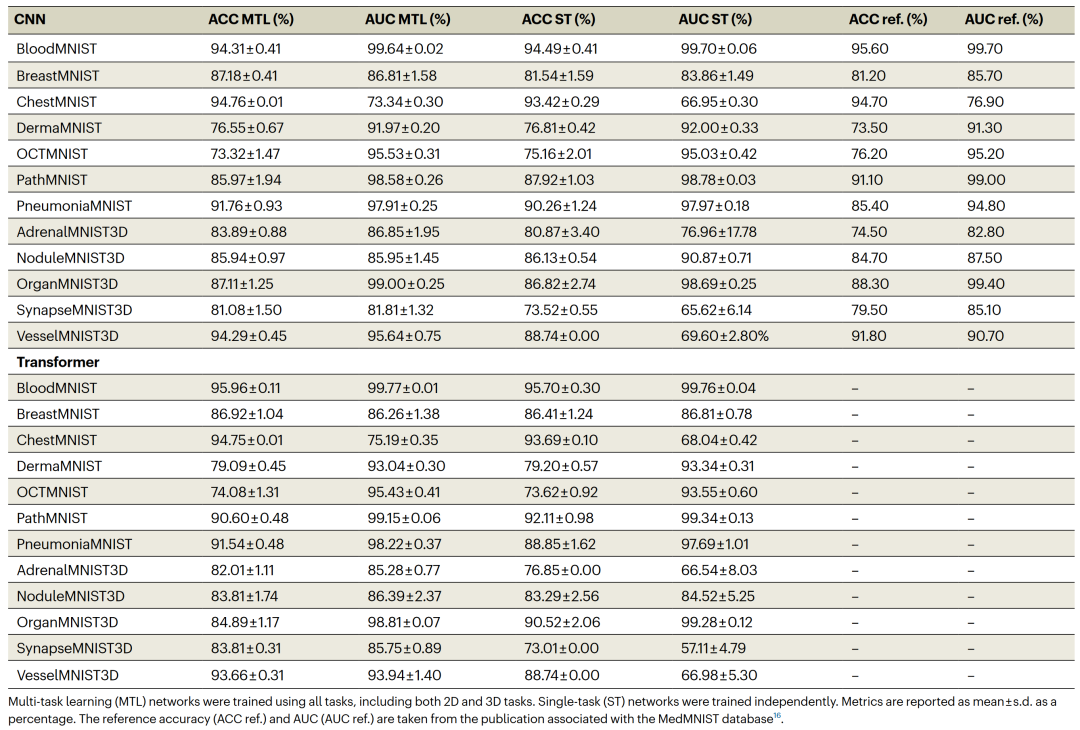
表 2
在这个背景下,作者还调查了多任务学习策略中CNN和transformer架构之间的性能差异。研究发现,Swin transformer架构对性能有微小的正面影响。关于训练方案,作者发现没有梯度累积时,训练策略的收敛性和性能都会变差。
除了3D分类,作者还研究了训练方法在计算机断层扫描(CT)扫描中的3D肺结节分割中的直接适用性。实验表明,大规模2D预训练及其所提供的更大2D空间上下文可以弥补3D上下文的缺失。
编译 | 黄海涛
审稿 | 曾全晨
参考资料
Schäfer, R., Nicke, T., Höfener, H., Lange, A., Merhof, D., Feuerhake, F., ... & Kiessling, F. (2024). Overcoming data scarcity in biomedical imaging with a foundational multi-task model. Nature Computational Science, 1-15.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢