
DRUGAI
今天为大家介绍的是浙江大学吴飞教授团队和南洋理工大学助理教授魏颖在2024 ICLR上合作发表的论文:Active Retrosynthetic Planning Aware of Route Quality。该论文定义了一个新的“人在回路”研究问题,即在逆合成路径预测的迭代式推理过程中,如何利用最少次数的化学反应质量标注,高效、高质量地设计目标分子的合成路径。为此,我们开发了一个基于强化学习的框架——Active Retrosynthetic Planning (ARP),该框架能够主动向化学家“提问”化学反应的质量,并利用专家的反馈优化预测。ARP兼容所有现有的逆合成搜索算法,对逆合成课题实现从研究向应用的转化具有重要意义。

图 1
背景简介及问题定义
新药合成是药物开发流程中的重要组成部分。逆合成路径预测旨在设计一条从目标分子到可购买原料库的合成路径,并按照这一路径在实验室中进行从原料库至目标分子的正向合成。这一规划任务类似于“机器人走迷宫”的寻路过程,经过“当前分子-选择一个化学反应-得到下一个分子”的迭代探索,直至“下一分子”为可商业购买的原料。
已有的逆合成算法通常专注于最小化上述迭代次数,并以路径长度作为评价标准。然而,在实际实验中,较短的路径并不总是意味着更高的可行性。例如,如图2中的合成路径A,虽然路径短,但会面临选择性问题(如烷基化位点和卤代烃水解),影响实验可行性。为了获得更具可行性的合成路线,研究通常将化学反应在公开数据集上的频率视为质量评分,并将其与分子结构一同作为模型的输入。然而,已有研究表明,公开化学反应数据集中的高频反应与高产率之间并无显著相关性,如图2B所示。
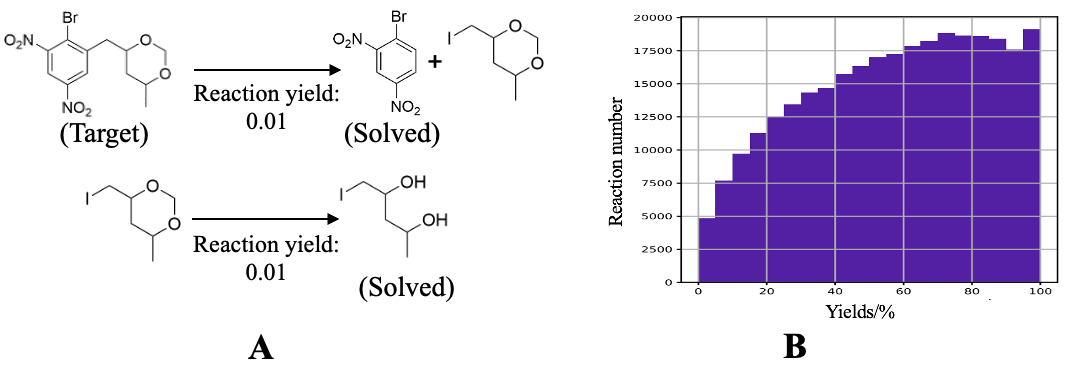
图 2
为此,我们提出用真实的化学反应标注来替代频率,这些标注可以是反应产率或化学家的实时评分。这一思路源自SYNTHIA [1]等逆合成软件的推理场景:算法在探索逆合成路径时,实时将遇到的反应发送给线上化学家进行评分,从而进行选择。然而,对每一步反应都进行无差别标注会在迭代搜索过程中导致时间和成本的增加。假如模型能够学会隐性地判断化学反应对搜索过程的价值,仅对重要反应进行标注,则可以最大程度地减少开销。因此,我们提出了一个更贴合实际应用的逆合成研究场景:在逆合成搜索过程中,存在一个“在线专家”可以对化学反应质量进行实时评分,但每次模型进行“提问”都会产生质询成本(query cost)。算法性能最终通过两个指标进行评价:1. 合成路径上化学反应质量评分的加权;2. 搜索过程中的总质询成本。
算法流程及模型结构
针对上述定义的“人在回路”问题,本研究设计了基于主动学习和强化学习的逆合成搜索框架Active Retrosynthetic Planning (ARP),并在开源数据集USPTO和专家数据集上与已有逆合成算法进行了对比实验,同时进行了消融实验,探究了稀疏与充足标注下的算法性能。
ARP作为一种框架,可以兼容现有的逆合成搜索算法,如GRASP [2] 等在线(online)搜索算法,以及Retro [3] 等离线(offline)搜索算法。ARP采用了Actor-Critic模型结构,并在文章中以GRASP和Retro*+为两类算法代表进行了部署和实验。这些算法在ARP中作为评价器,被绑定在Critic结构中。ARP的参数训练可以与在线算法模型协同训练,若为离线算法,则需在ARP的训练过程中将其参数梯度冻结。
ARP延续了基于强化学习的逆合成路径规划马尔可夫链:分子代表当前状态(state),可发生的候选化学反应(reaction candidates)由单步模型(single-step model)给出,定义为动作(action)。此外,我们定义了质询动作:对于某一化学反应动作,是否向“专家”提问其质量(quality)。ARP采用了Actor-Critic模型结构结构。Actor作为决策模型,以化学反应作为输入,输出质询动作;若质询动作为True,则quality等于真实的化学反应质量,反之则以掩码(mask)填充quality;Critic作为价值评估模型,以化学反应导向的下一分子(next state)和quality作为输入,输出强化学习的预估价值(value)。
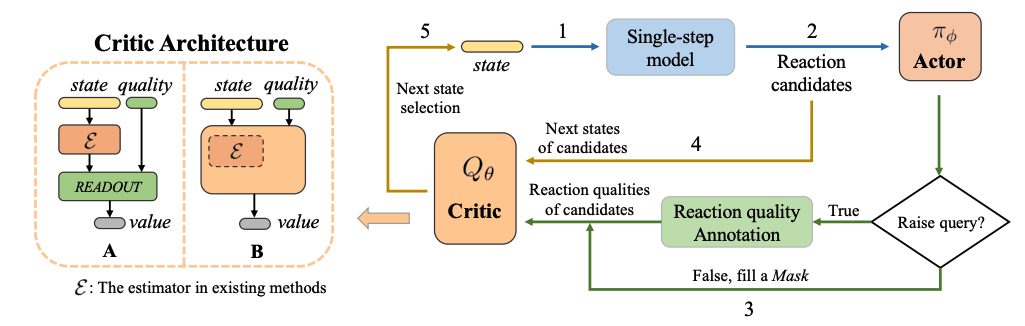
图 3
如图3所示,每一次“当前分子-选择一个化学反应-得到下一分子”的迭代过程包括以下步骤:1. 从当前分子得到若干候选反应;2. 将候选反应输入Actor,输出各自的质询动作;3. 若质询动作为True,则以标注的化学反应质量数值填充quality,若为False,则以掩码填充对应的quality;4. 对每个候选反应,得到其对应的下一个分子;5. Critic对所有的(候选反应,quality,下一分子)进行评价,并排序后选择得分最高的状态进入下一次迭代。算法流程图如图4所示,ARP框架通过TD3强化学习算法进行训练。

图 4
与其他模型的比较
在实验中,我们选择了Retro*+ [3] 和GRASP [2] 作为在线与离线搜索算法的代表,部署在ARP框架中,并与HgSearch [4]、Retro* [3]、EG-MCTS [5] 等算法进行了比较。实验在开源数据集USPTO和专家数据集(Expert test set)上进行,除成功率外,我们还使用了质询比例(query rate)和路径质量(Normalized route quality)作为评价指标。结果显示,GRASP和Retro*+在ARP框架中均表现出性能提升。尤其是GRASP with ARP在两个数据集上均取得最佳效果,较当前最优算法EG-MCTS在路径质量上提升6.2%,质询比例下降12.8%。
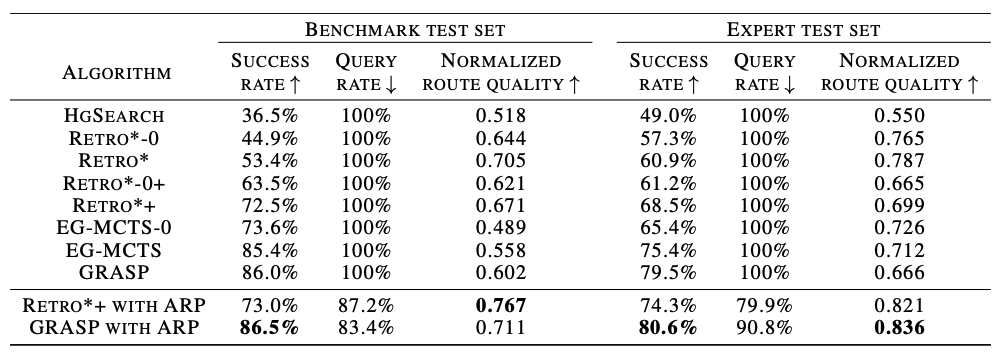
图 5
主动学习能力的消融实验
ARP框架的质询比例可以通过调整超参数query cost进行控制,query cost越大,单次反应质量质询的成本越高,结果中的质询比例越低。实验结果如图6所示,随着query cost提高,质询反应数量逐步减少。在质询比例低于20%时,路径质量未出现显著下降,证明了ARP的主动学习能力,可以有效挑选对搜索过程有较大影响的化学反应进行标注。
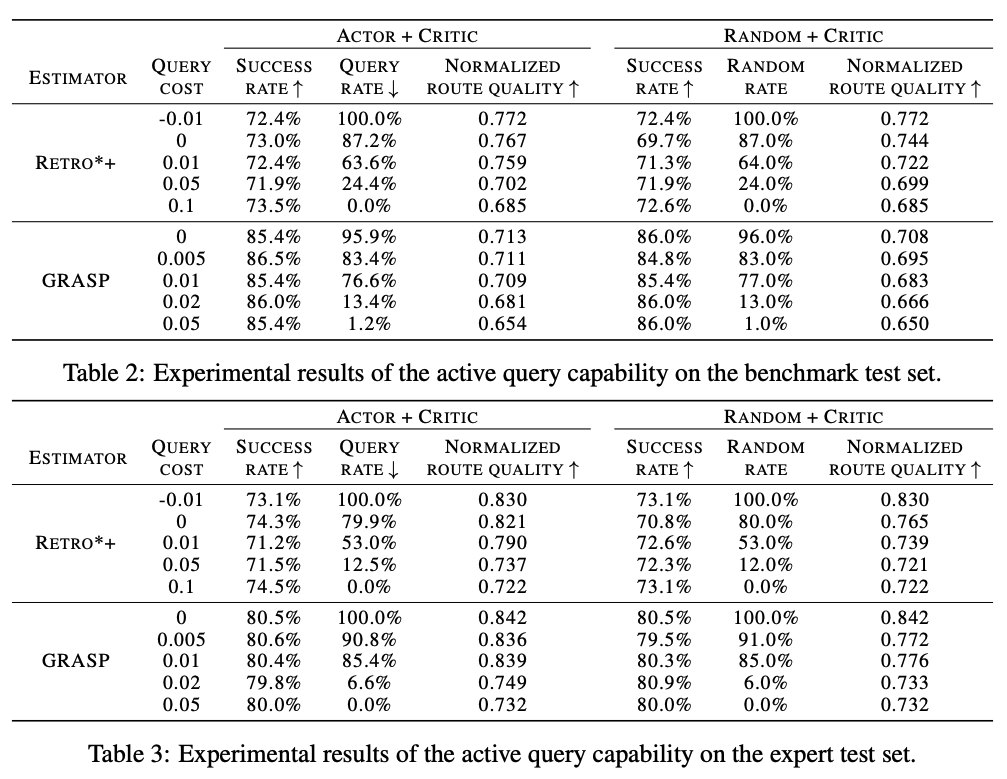
图 6
影响、局限与展望
合成科学是化学学科中的根本任务之一。尽管近年来数据科学与神经网络在实验科学中展现出惊人的预测能力,但在许多AI for Science的问题上,神经网络的预测模型尚未达到应用水平。将重复性简单的任务交给人工智能、将算法确定度较低的复杂问题交给专家,“人在回路”节省时间、人力和资源成本的同时,也为AI模型的发展提出了新的方向。本研究抓手于增强逆合成路线在实验室中的可行性较差问题,将“模型提问-专家回答”嵌入到迭代式搜索过程当中,对逆合成问题从研究向应用落地具有重要意义。
然而,本研究定义的可行性仍局限于化学反应产率和反应质量等转化率指标。而实验室中的实际合成过程更为复杂,还涉及毒性、成本、后处理难度和表征难度等因素。这些不同因素具有不同的质询成本,可以抽象为不同query costs的多agent强化学习过程。理想的逆合成算法应能够整合实验过程中的大部分变量,从而具备更高的可靠性和应用价值。
参考资料
[1] Lin, Yingfu, et al. "Computer-aided key step generation in alkaloid total synthesis." Science 379.6631 (2023): 453-457.
[2] Yu, Yemin, et al. "Grasp: Navigating retrosynthetic planning with goal-driven policy." Advances in Neural Information Processing Systems 35 (2022): 10257-10268.
[3] Chen, Binghong, et al. "Retro*: learning retrosynthetic planning with neural guided A* search." International conference on machine learning. PMLR, 2020.
[4] Schwaller, Philippe, et al. "Predicting retrosynthetic pathways using transformer-based models and a hyper-graph exploration strategy." Chemical science 11.12 (2020): 3316-3325.
[5] Hong, Siqi, et al. "Retrosynthetic planning with experience-guided Monte Carlo tree search." Communications Chemistry 6.1 (2023): 120.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢