

新智元报道
新智元报道
【新智元导读】最近,Meta的多个工程团队联合发表了一篇论文,描述了在引入基于GPU的分布式训练时,他们如何为其「量身定制」专用的数据中心网络。

论文地址:https://ai.meta.com/blog/meta-llama-3-1/
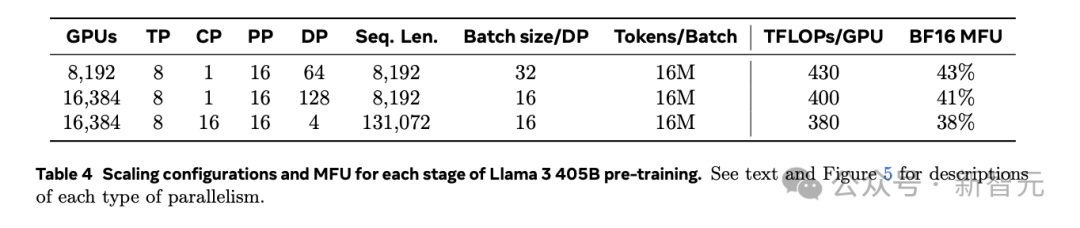

选择RoCE的原因
分布式网络中的GPU间通信主要包括两个阶段。首先是在单个训练节点上的4~8个GPU之间进行「节点内通信」,使用NVLink高速互联方式。 如果训练工作需要额外GPU参与,就需要引入「节点间通信」,对此,业界通常有两种设计方式。 - 标准的TCP/IP网络或对其中的插件进行修饰,比如fastsocket - 专有的互连技术,比如InfiniBand、NVSwitch、Elastic Fabric Adaptor、Inter-rack等 由于CPU开销和延迟的增加,前者容易造成集群性能的下降;后者尽管能提供较好的性能,但由于是专有技术,很难灵活部署。 因此,当Meta引入基于GPU的分布式训练时,工程师们决定为其量身定制数据中心网络,最后选择RoCEv2(RDMA over Converged EtherNet v2)作为主要的节点间通信机制。 RDMA全称Remote Direct Memory Access,可以在无需CPU参与的情况下实现互连GPU的内存共享。 基于TCP/IP的通信机制中,数据包必须先发送到内核才能拷贝至内存,而RDMA则绕过内核,信息可以直接到达或发送至应用内存。 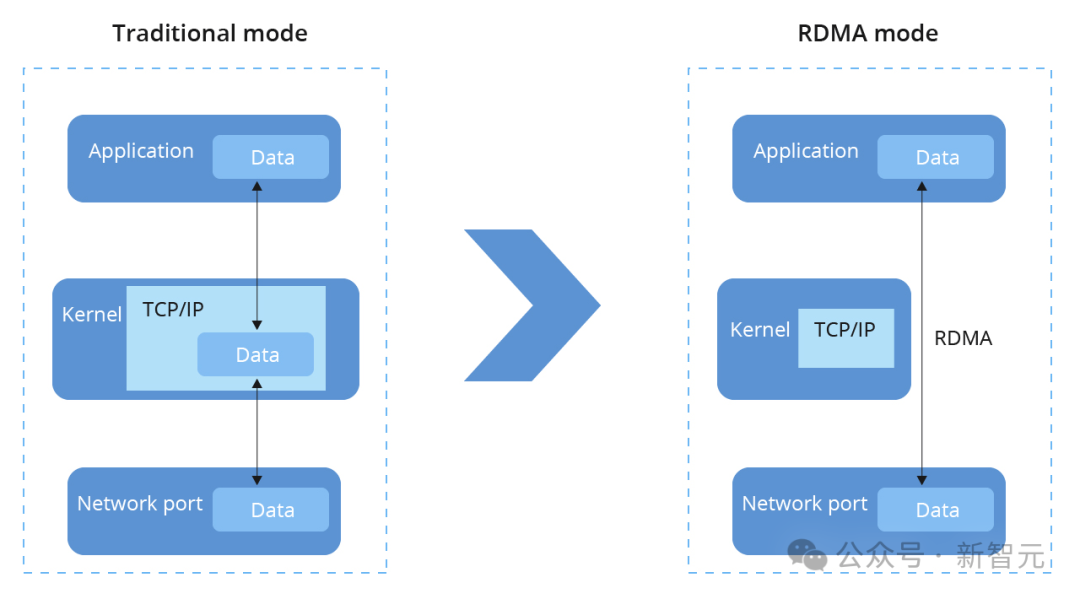
RoCEv2则是实施RDMA的一种具体协议,规定使用以太网传输,数据包采用UDP格式,读写信息的封装和解封都由RDMA NIC硬件处理。 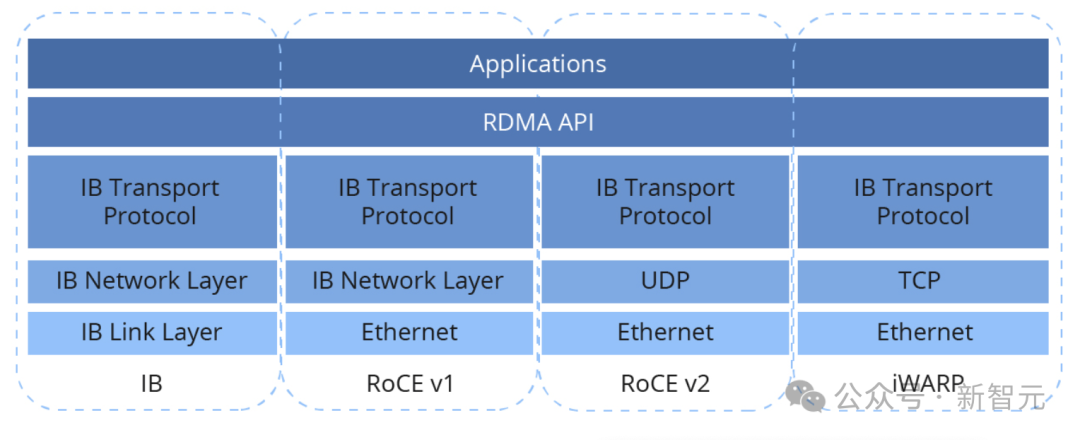
之所以选择RoCE,出于以下三方面的动机: - RoCE与训练工作负载常用的RDMA一脉相承,确保已有设施的无缝衔接 - 使用以太网可以保留原数据中心相当比例的组件和工具,并能继续使用基于Clos的设计 - 整个技术栈都以开放标准为基础,确保网络基础设施的兼容和灵活 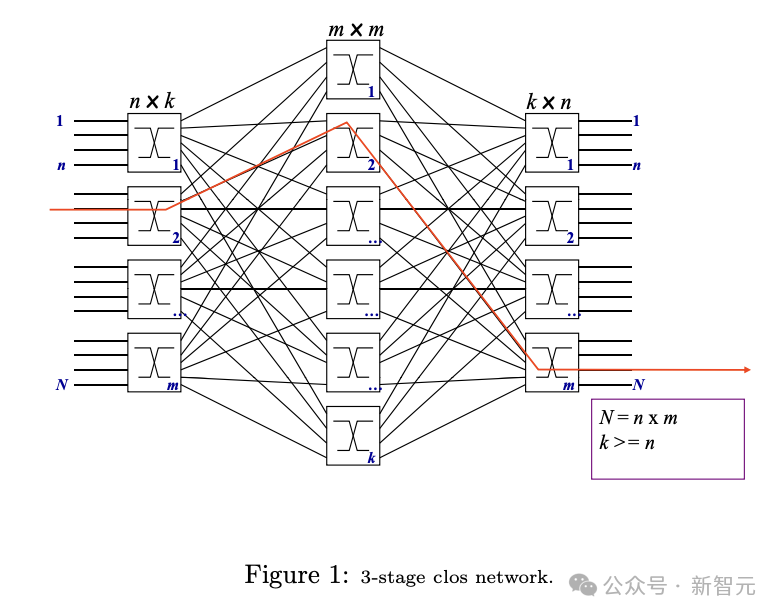
扩展后的RoCE网络中,每个集群可容纳数千甚至数万个GPU,而且可用于支持生产场景下的各种GPU工作任务,比如排名、内容推荐、内容理解、NLP和GenAI模型训练等。 拓扑结构
拓扑结构
前后端分离
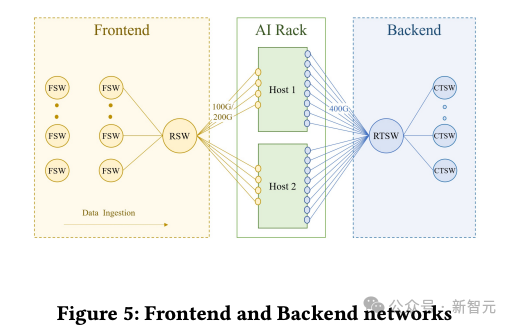
AI Zone
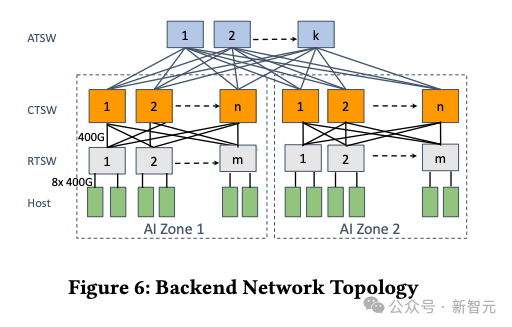
RTSW:Rack Training Switch,机架训练交换机
CTSW:Cluster Training Switch,集群训练交换机
ATSW:Aggregator Training Switch,聚合训练交换机
路由
上面讨论的计算能力和网络拓扑的扩展引发了大量训练流量的路由和负载均衡问题。具体来说,AI训练的工作负载体现出以下3个具有挑战性的特征: - 低熵:与传统数据中心相比,AI工作负载的流的数量和多样性要小得多,流的模式通常是重复的和可预测的 - 突发性:在时间维度上,流量通常在毫秒级的时间粒度上出现或结束 - 「大象流」:每次流量爆发时,强度可以与NIC的线路速率相当
ECMP和路径固定
队列对扩展
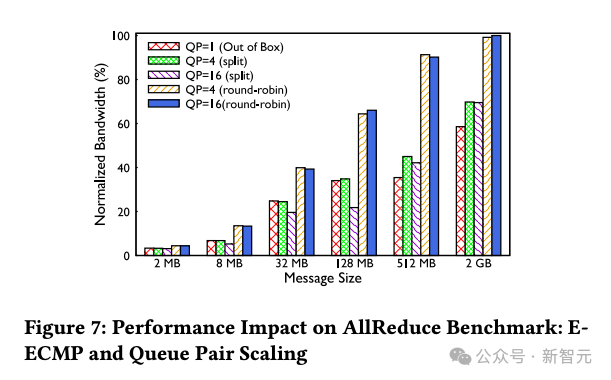
拥塞控制
将集群过渡到400G网络部署时,团队尝试调整原有的DCQCN算法以适应新的网络速度和拓扑结构,然而却遇到了无法解决的问题,相比200G网络出现了性能下降。 因此,团队选择在没有DCQCN的情况下继续进行400G部署,在一年多的时间中仅使用PFC,没有任何其他传输级的拥塞控制机制。结果发现,训练集群表现稳定,并没有出现持续拥堵的情况。
接收方驱动的流量准入
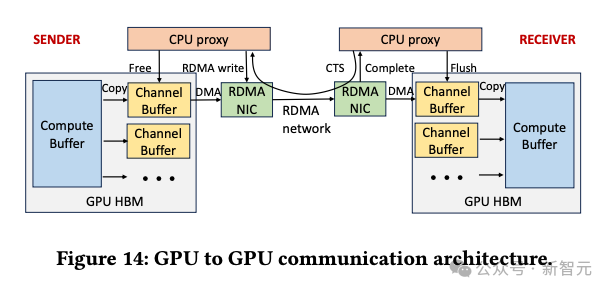
总结
除了介绍工程设计方面的考量,论文也描述了使用的集群观测工具,以及一些故障排除案例。 通过分离FE和BE网络、采用不同的路由方案并优化集群流量模式,Meta团队构建了高性能且可靠的网络基础设施,强调了深入理解训练工作负载的重要性,并对相关的网络组件进行了「量身定制」。 参考资料: https://engineering.fb.com/2024/08/05/data-center-engineering/roce-network-distributed-ai-training-at-scale/ https://web.stanford.edu/class/ee384y/Handouts/clos_networks.pdf https://community.fs.com/article/roce-vs-infiniband-vs-tcp-ip.html



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢