

本文,我们将发布

Docmatix 数据集样本示例
缘起于
丹鼎 (The Cauldron) https://hf.co/datasets/HuggingFaceM4/the_cauldron Idefics2 https://hf.co/blog/idefics2
为了解决这一问题,我们很高兴推出 Docmatix,这是一个 DocVQA 数据集,包含 240 万张图像以及源自 130 万个 PDF 文档的 950 万对问答。与之前的数据集相比,规模扩大了 240 倍。
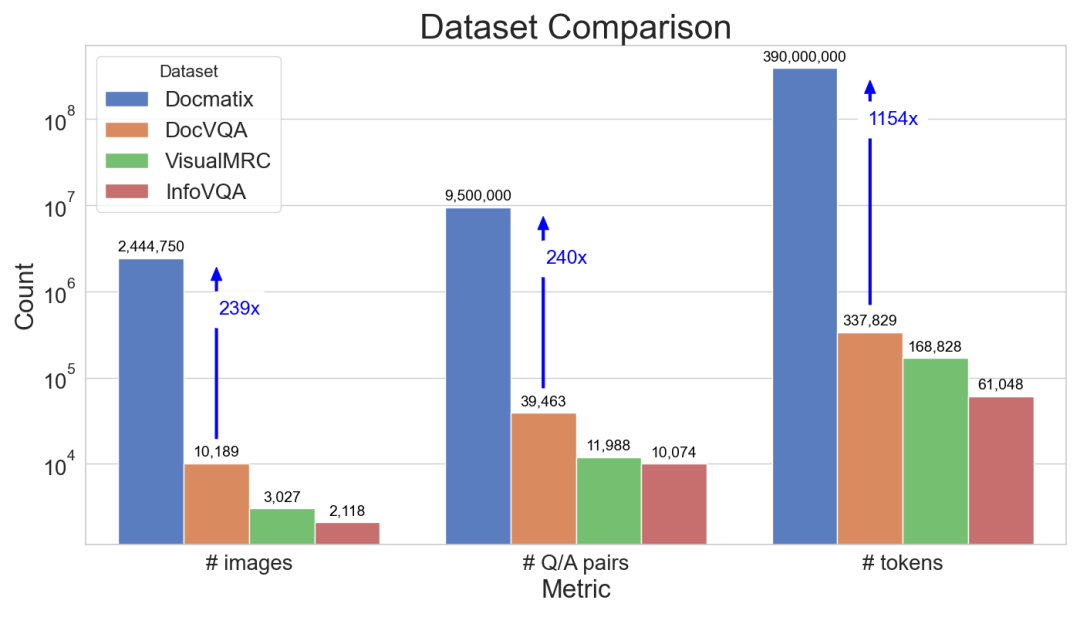
Docmatix 和其它 DocVQA 数据集的对比
你可以通过下面的页面自由探索数据集并查阅 Docmatix 中包含的文档类型以及问答对。
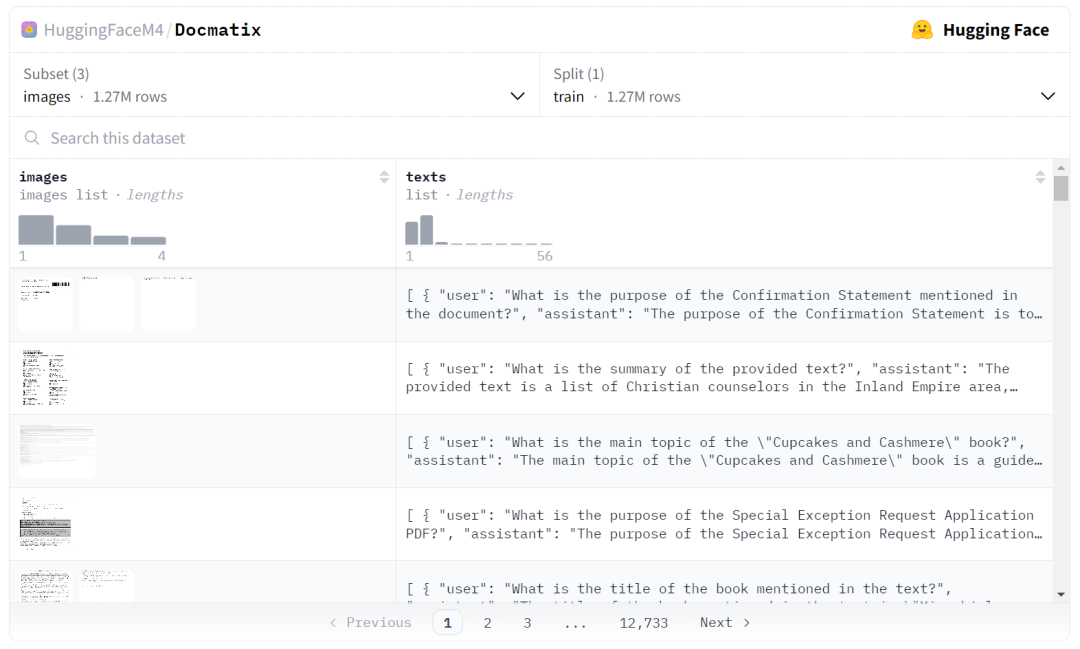
Docmatix 是基于
PDFA - 一个包含 210 万个 PDF 的 OCR 数据集 https://hf.co/datasets/pixparse/pdfa-eng-wds Phi-3-small https://hf.co/microsoft/Phi-3-small-8k-instruct
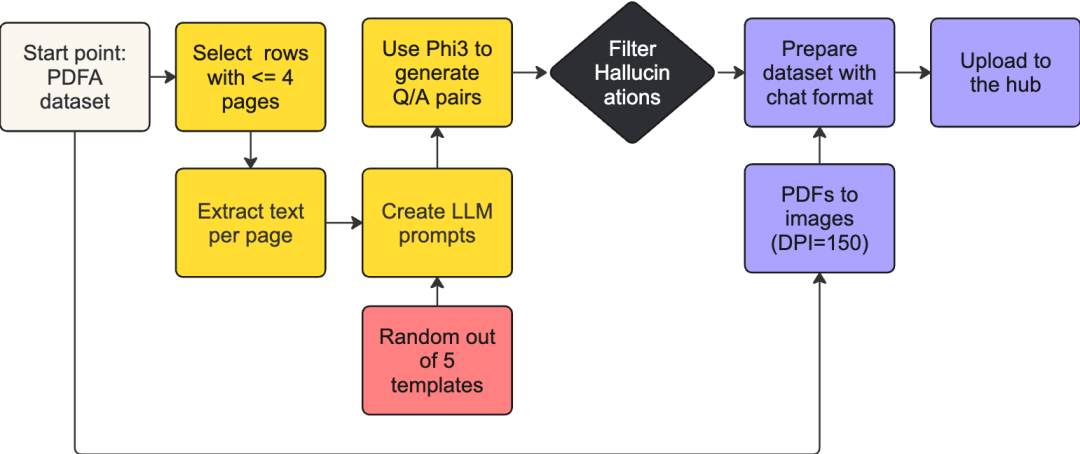
生成 Docmatix 的数据处理流水线
我们先处理了一小批数据集,并对其进行多次消融研究以对提示进行优化。我们的目标是每页生成大约 4 对问答。太多的话,它们之间会有很大的重叠,太少的话,则说明当前页的内容中细节较少。此外,我们的目标是让生成的答案与人类回答相似,避免过短或过长的答案。我们还比较重视问题的多样性,以确保尽量减少重复问题。有趣的是,当我们引导
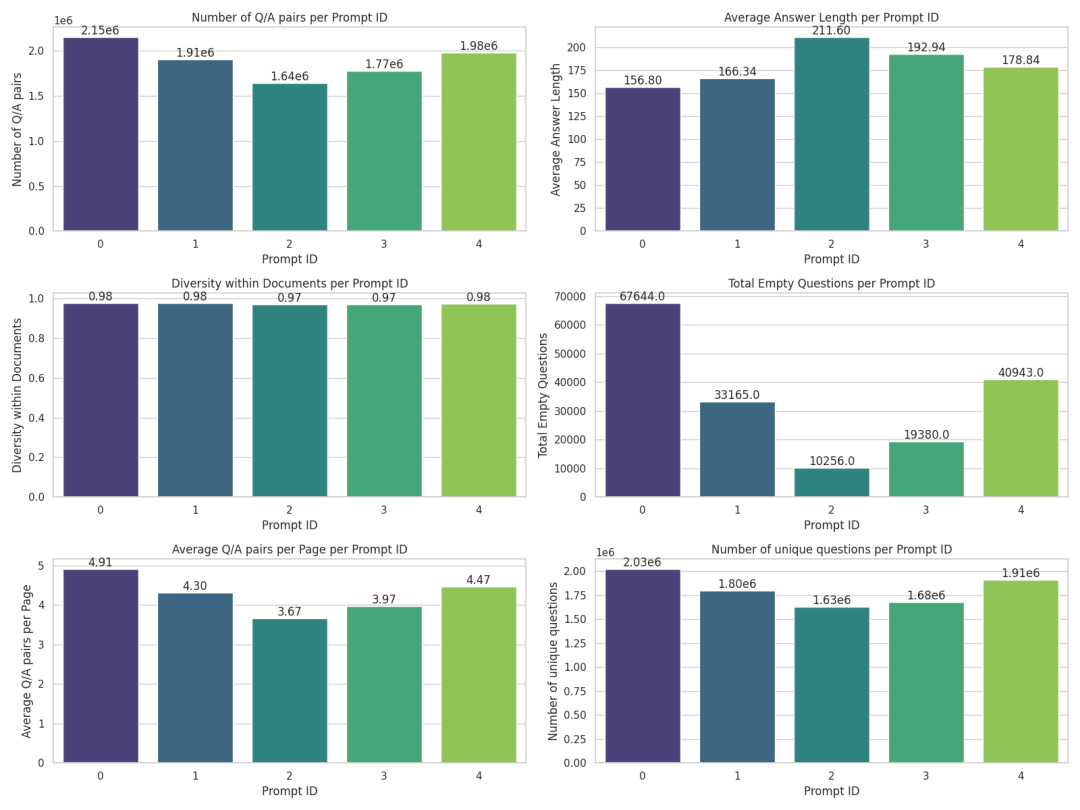
从提示的维度分析 Docmatix
为了评估 Docmatix 的质量,我们使用 Florence-2 模型进行了消融实验。我们训练了两个版本的模型以进行比较。第一个版本在 DocVQA 数据集上训练数个 epoch。第二个版本先在 Docmatix 上训练 1 个 epoch (仅使用 20% 的图像、4% 的 Q/A 对),然后再在 DocVQA 上训练 1 个 epoch,以确保模型的输出格式符合 DocVQA 评估的要求。结果很明显: 先对 Docmatix 进行微调可带来近 20% 的相对指标提升。此外,所得的 0.7B Florence-2 模型的性能仅比基于混合训练集训练的 8B Idefics2 模型差 5%,要知道从模型尺寸上来看 8B 可以比 0.7B 大得远不止 5%。
| 数据集 | DocVQA 上的 ANSL 值 | 模型尺寸 |
|---|---|---|
| 在 DocVQA 上微调的 Florence 2 | 60.1 | 700M |
| 在 Docmatix 上微调的 Florence 2 | 71.4 | 700M |
| Idefics2 | 74.0 | 8B |
本文介绍了 Docmatix,一个用于 DocVQA 的超大数据集。我们的结果表明,使用 Docmatix 在微调 Florence-2 时,我们可以将 DocVQA 性能提高 20%。该数据集有助用户弥合开源 VLM 相对于闭源 VLM 的性能差距。我们鼓励开源社区利用 Docmatix 去训练新的的 DocVQA 模型,创造新的 SOTA!我们迫不及待地想在 🤗 Hub 上看到你的模型!
Docmatix 微调 Florence-2 所得模型的演示 https://hf.co/spaces/HuggingFaceM4/Docmatix-Florence-2 微调 Florence-2 - 微软的尖端视觉语言模型 https://hf.co/blog/zh/finetune-florence2 Florence-2 微调的 Github 代码库 https://github.com/andimarafioti/florence2-finetuning 视觉语言模型详解 https://hf.co/blog/zh/vlms
我们要感谢 merve 和 leo 对本文的审阅并提供了缩略图。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢