
DRUGAI
本文介绍一篇由浙江大学侯廷军教授、谢昌谕教授、澳门理工大学姚小军团队以及碳硅智慧联合发表的酶催化活性位点注释的论文。在该论文中,作者提出了一个基于多模态深度学习技术的酶催化位点注释模型EasIFA。该模型融合了来自蛋白质语言模型和3D结构编码器的潜在酶表示,然后使用多模态交叉注意力框架将蛋白质水平信息与酶反应知识相结合,从而更高效和准确地预测酶的催化活性位点。与目前最优的其他同类方法相比,EasIFA的识别速度较传统算法至少提高了10倍,活性位点识别质量至少提高了9.68%(以F1分数计量),且相对于基于位置特定得分矩阵(PSSM)和GNN的高精度深度学习算法的速度提升了约1300倍,并且支持更多种酶活性位点的识别和检测。该研究还展示了该算法在酶设计和功能预测中的潜力,为酶工程和药物开发等领域提供了新的工具和视角。最后,研究团队还开发了基于EasIFA的网络服务器(http://easifa.iddd.group)。

研究背景
在现代生物科学研究中,酶作为生物催化剂在多种生物化学反应中扮演着至关重要的角色。酶不仅在维持生命的基本过程中起着关键作用,还在疾病的发生与发展中扮演着重要角色。因此,准确注释酶的活性位点对于推动药物开发、疾病研究、酶工程和合成生物学等多个领域的发展具有重大意义。近年来,DNA测序技术取得了显著进展,使得科学家们能够不断从不同物种和来源获取大量酶序列,但准确注释这些酶的活性位点仍然是一个巨大的挑战。据统计,在已经识别的数千万种酶序列中,只有不到0.7%的酶具有高质量的活性位点注释。随着每年新增的酶序列数量呈指数级增长,传统的实验技术显然无法满足大规模注释的需求。
虽然已经有许多自动化的酶功能注释算法被开发出来,如预测酶的酶学分类号(EC number)等,但这些方法在注释酶的活性位点时仍面临着重大挑战。现有的酶活性位点预测算法大致可以分为三类:基于同源性和模板的方法、基于经验规则的方法以及基于机器学习的方法。然而,这些方法都存在一定的局限性。例如,基于同源性的方法依赖于庞大的数据库,当目标酶与数据库中的已知酶差异较大时,预测准确性会显著下降。基于经验规则的方法则因其依赖于特定的物理化学特性,难以适应不同酶的特性。基于机器学习的方法虽然展现出了一定的潜力,但仍面临着如何处理高维度数据、提高预测精度和速度的挑战。
为了应对这些挑战,研究团队提出了一种名为EasIFA的多模态深度学习算法。EasIFA通过融合蛋白质语言模型(Protein Language Model, PLM)和酶的三维结构编码器,并且使用注意力机制在酶的表示中整合来自预训练酶促反应编码器的特异性酶促反应信息。不仅提高了酶活性位点注释的速度,还显著提升了注释的准确性。该算法能够高效地从粗糙的酶注释数据中学习知识,并将其成功应用于高精度的小规模数据集,展现出其在酶功能预测和酶设计中的巨大潜力。
模型架构
提出的 EasIFA 框架如图 1 所示。给定一个酶-反应对作为输入,EasIFA使用两个分支分别表示酶和反应的特征。酶的特征表示分为三个阶段。在初始阶段,使用 ESM-2 将氨基酸残基序列转换为蛋白质语言表示。在第二阶段,每个氨基酸残基的蛋白质语言表示作为酶图 中的节点特征,然后输入到 GearNet 中。此处,一个消息传递机制更新酶的节点特征。随后,通过将氨基酸残基的蛋白质语言表示与酶图的更新特征连接起来,创建酶图的节点特征。在第三阶段,使用 BridgeNet 将这些特征映射到与反应信息相同的特征大小。
反应的特征表示分为两个分支,如图 1 所示,分别独立表示底物分子和产物分子的特征。在使用 MPNN更新底物和产物分子的特征后,采用基于注意力机制的底物-产物相互作用网络将产物分子的特征与底物分子的特征合并,形成一个携带产物信息的底物分子图。在将酶和反应的特征嵌入后,通过基于注意力机制的酶-反应相互作用网络将底物分子图上的信息合并到酶图上。值得注意的是,基于注意力机制的酶-反应相互作用网络与基于原子间距离感知的全局注意力的自注意力机制不同的底物-产物相互作用网络。
一旦信息整合完成,如图 1 所示,使用称为多层感知器残基活性预测器的氨基酸残基活性注释网络来预测每个氨基酸残基的活性类型。研究人员评估了多层感知器残基活性预测器的两种变体来完成两项任务:(1) 活性位点的识别和 (2) 活性位点类型的分配。
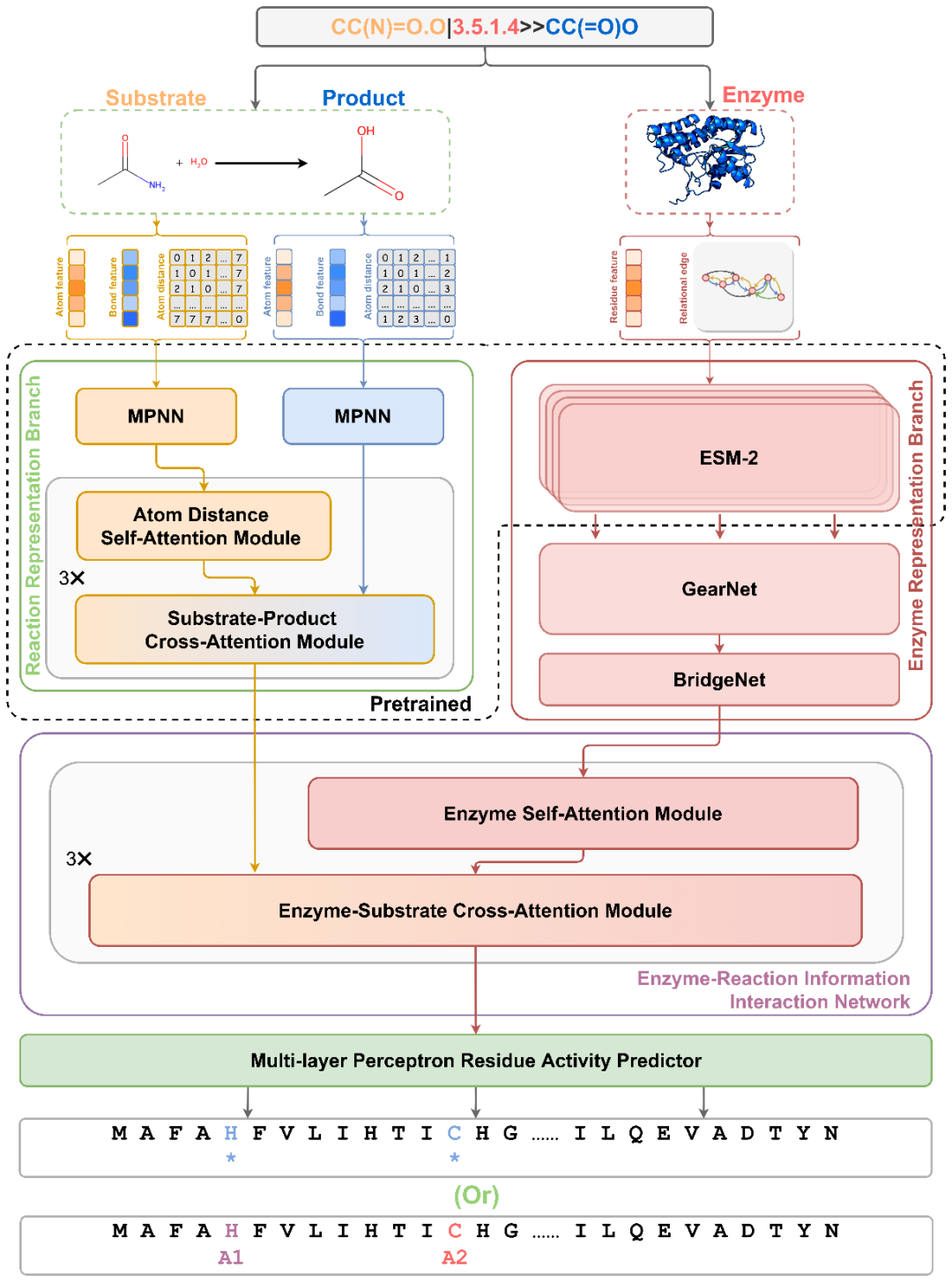
图1:EasIFA算法框架示意图。
结果与讨论
性能评价策略和标准
研究团队构建了SwissProt-ECReact酶-反应活性位点注释数据集(SwissProt E-RXN ASA数据集)和MCSA酶催化位点注释数据集(MCSA E-RXN CSA数据集)用于模型评估。为了确保训练集、验证集和测试集的独立性,研究团队排除了与训练集序列相似度超过80%的酶结构,并按8:1:1的比例划分数据集。
模型在两个任务上进行了独立评估:活性位点定位注释任务(二分类,用于判断氨基酸残基是否为活性位点)和活性位点类型注释任务(多分类,用于预测氨基酸残基的活性类型)。使用的主要评估指标包括:精准率、召回率、假阳性率(FPR)、F1得分和Matthews相关系数(MCC)。这些指标分别计算每个验证/测试样本的得分,最终报告所有测试样本的平均值。此外,值得注意的是,模型在不同序列相似度和TM-Score区间内的表现被与基准方法进行了对比,并在测试集中得到了详细报告。
提高注释速度和准确性
研究团队对比了EasIFA-ESM和EasIFA-SaProt算法与其他三种代表性算法在SwissProt E-RXN ASA数据集上的表现,包括BLASTp、AEGAN和Schrodinger-SiteMap。EasIFA-ESM和EasIFA-SaProt的主要区别在于酶序列表示模块。具体来说,EasIFA-ESM使用ESM-2-650M模型表示酶序列,而EasIFA-SaProt采用SaProt-650M-AF模型。SaProt模型作为ESM-2的增强版,整合了由Foldseek计算的三维结构编码。评估包括了算法在标记酶活性位点位置(对氨基酸残基的二分类任务)的能力,以及它们预测酶活性位点类别(对氨基酸残基的多分类任务)的能力。对比结果展示在表1中。
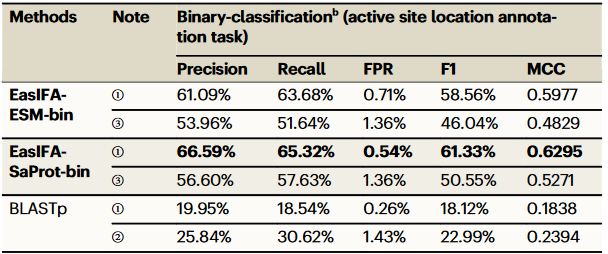
表1. 在SwissProt E-RXN ASA测试集中EasIFA与基线模型的性能比较
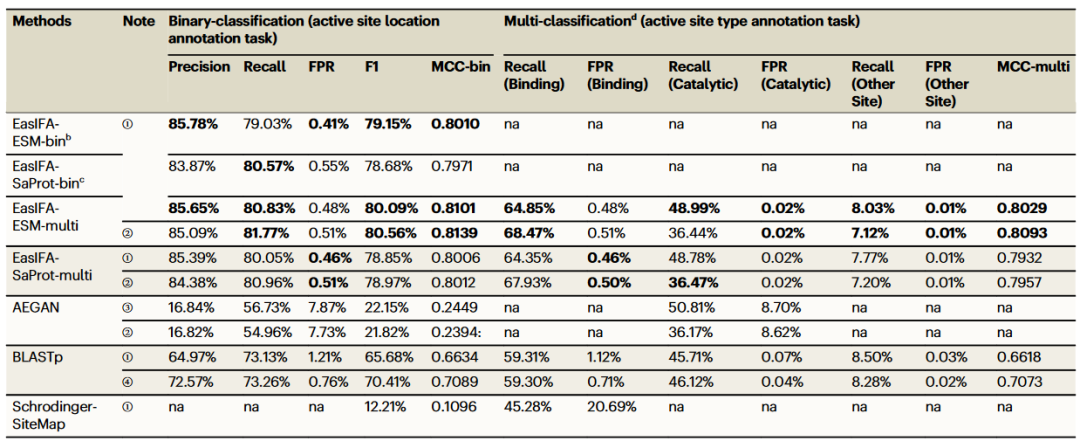
值得注意的是,EasIFA-ESM和EasIFA-SaProt算法提供了两种版本:EasIFA-ESM-bin和EasIFA-SaProt-bin专注于标注氨基酸残基中催化位点的位置;EasIFA-ESM-multi和EasIFA-SaProt-multi不仅标注活性位点位置,还鉴别活性位点的类别,包括结合位点、催化位点和其他位点。测试结果表明,EasIFA-ESM/EasIFA-SaProt在注释质量上优于其他基准方法,特别是在精准率、召回率、F1得分和MCC等指标上表现出色。为了更清晰地展示EasIFA模型和基准方法在不同序列相似度区间的预测能力,研究团队使用CD-HIT将测试集划分为五个子集,并分别计算了F1得分、MCC、召回率和FPR。结果显示,EasIFA-ESM-bin、EasIFA-SaProt-bin和BLASTp在所有序列相似度区间内的预测性能明显优于AEGAN和Schrodinger-SiteMap。而且EasIFA算法相对于其他算法的性能优势随着相似度的降低而提升。
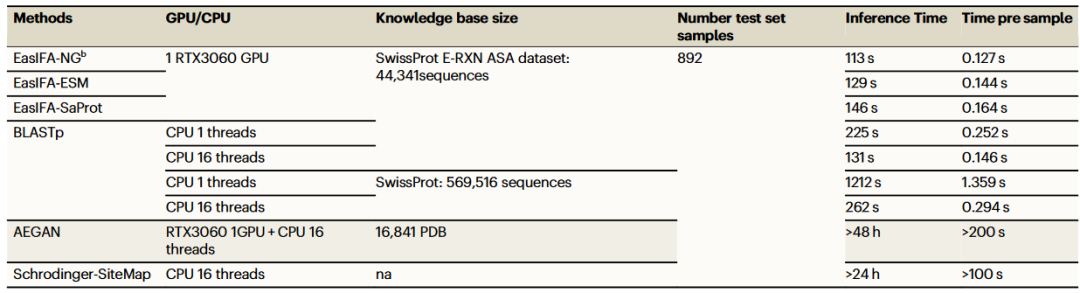
为了比较算法在大规模注释任务上的计算能力,研究团队还比较了在相同条件下,每个算法的推理时间消耗,结果展示在表2中。表2展示了EasIFA算法的推理速度,其平均每个酶的注释时间仅为0.144秒,显著优于其他算法。尽管BLASTp算法的速度也相对较快,但其推理效率仍然不如EasIFA算法。此外,EasIFA算法在注释质量和推理效率上表现出色,即使在缺乏3D结构的情况下,EasIFA-NG-bin仍能提供快速且准确的注释方案。
表2. 在SwissProt E-RXN ASA测试集上EasIFA与基线算法的推理速度比较
消融研究
研究团队进行了进一步的消融实验,以评估各种因素对酶活性位点注释的影响:包括或排除化学反应信息、化学反应分支的预训练、不同的预训练反应表示方案、是否利用3D图结构表示酶以及酶的不同序列表示方案。研究发现,纳入反应分支信息后,EasIFA模型的预测性能显著提升:F1分数增加3.79%,MCC提高0.0388,AUPRC增加0.0375。这证明了反应信息对酶活性位点注释的重要性及酶-反应交互网络的有效整合。然而,未经充分训练的反应分支(EasIFA-RS-bin)表现最差,其F1分数、MCC和AUPRC分别比EasIFA-ESM-bin低4.27%、0.0602和0.0666,表明准确表示基于有限酶反应集的反应具有挑战性。此外,预训练在更广泛的有机反应数据集上对反应分支的表征能力至关重要。RXNFP表示的EasIFA-RXNFP-bin变体性能与不包括反应表示分支的EasIFA-E-bin接近,说明RXNFP表示对模型能力既无增强也无拖累。不包含GearNet的EasIFA-NG-bin模型性能下降,但推理速度更快,平均每个测试样本推理时间减少0.017秒。序列表示改为SaProt的EasIFA-SaProt-bin变体召回率提高1.54%,尽管其他分数略低,差异不大,表明从Foldseek获得的三维结构表示信息对已经包含GearNet的EasIFA影响较小。除了检验上述EasIFA变体外,研究团队还研究了使用不同PDB结构源表示相同结构的影响。研究团队在测试集中用由ESMFold2推断的结构替换了由AlphaFold2推断的酶结构。测试结果表明,模型性能略有下降,但下降幅度很小,显示了EasIFA对结构数据分布变化的强大鲁棒性。
研究还比较了EasIFA-ESM-bin和EasIFA-E-bin在不同酶序列相似度下的ROC和PRC曲线差异。结果表明,随着酶序列相似度的增加,EasIFA-ESM-bin与EasIFA-E-bin之间的AUPRC差距逐渐扩大,表明酶-反应交互网络能够更有效地提高模型性能,尤其是在处理高相似度序列时。
案例研究
如图2所示,研究团队在Swiss-Prot E-RXN ASA测试集上展示了EasIFA算法生成的活性位点注释,准确预测了多种酶的关键催化残基,如蛋白酪氨酸磷酸酶和肉碱N-甲基转移酶。特别是,模型识别出酪氨酸磷酸酶中的活性半胱氨酸残基和肉碱N-甲基转移酶中的所有底物结合位点。此外,EasIFA在TIM桶结构的酶中也表现出高精度,例如苹果酸合成酶A和酮糖3-环化酶,准确注释了催化反应所需的关键残基。
此外,研究团队还建立了一个酶与假激酶配对数据集,评估了EasIFA在区分未知假酶上的能力。通过使用BLASTp精确匹配假激酶与真实酶,研究团队对27对有效配对进行了活性位点预测,成功鉴别了大部分假激酶。混淆矩阵结果显示,EasIFA正确识别了所有酶样本和大多数假激酶样本,表明其在鉴别真实酶和假激酶上具有一定的效能。这些结果验证了EasIFA在活性位点注释及其鉴别能力上的准确性和实用性。
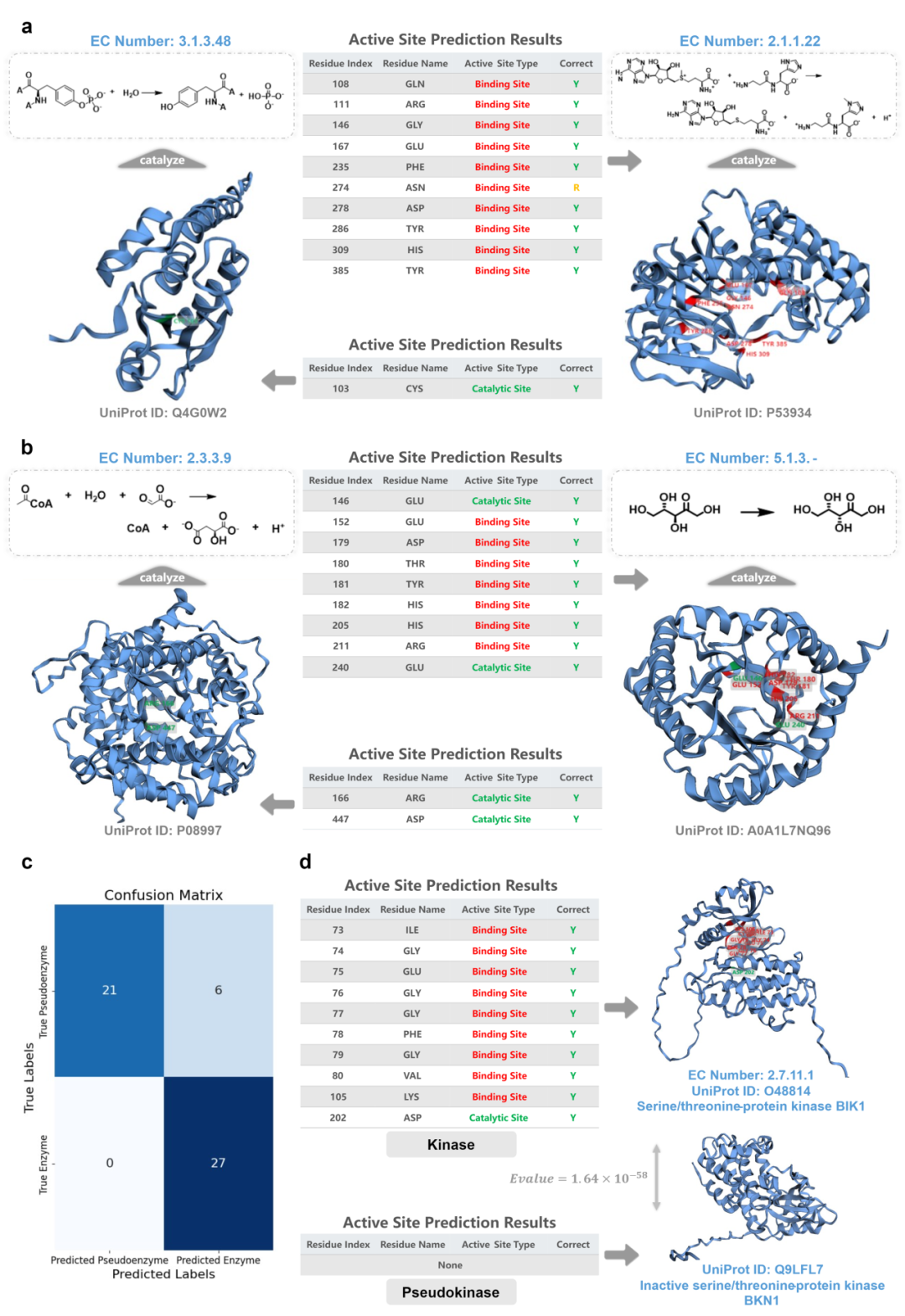
图2. 案例研究展示
知识库迁移实验
UniProt数据库虽提供全面的手工注释蛋白数据,但在酶领域的细节常缺乏,与专业数据库相差甚远。相比之下,如MCSA这样的数据集虽注释质量高、细节丰富,但成本高、难以大规模扩展,且条目有限,导致相似度低,给小规模高质量数据集的建模带来挑战。
研究团队在本研究中利用EasIFA算法,经SwissProt E-RXN ASA数据集预训练后,应用迁移学习于MCSA E-RXN CSA数据集,同时也研究了直接使用未经过迁移学习的EasIFA算法进行测试并与BLASTp方法对比。结果如表3显示,EasIFA-SaProt-bin在MCSA数据集上的表现最佳,显著优于BLASTp,F1得分达到61.33%,MCC为0.6295,而BLASTp仅有18.12%的F1得分。这表明EasIFA算法能够成功将其在大规模数据集上学到的知识迁移到高质量的小规模数据集上,显著提升了预测性能。EasIFA通过引入Foldseek的3D结构数据和迁移学习策略,在不同数据集之间展示了强大的知识迁移能力,相比于传统的序列比对方法,具有显著的优势。
表3. EasIFA-ESM-bin、EasIFA-SaProt-bin与序列相似性算法BLASTp在MCSA E-RXN CSA数据集上的性能比较
人工设计酶催化位点监测潜力的探索
随着蛋白质设计和酶工程的进步,越来越多的人工酶被创造出来,这些酶的结构模式通常与天然酶不同,给预测带来挑战。为此,研究团队探索了EasIFA算法在酶设计中的应用,尤其是作为活性位点的监测器。由于人工设计的酶与天然酶的氨基酸序列分布不同,传统的BLASTp和AEGAN算法无法准确预测Watson等人使用RFdiffusion设计的四类人工酶的活性位点。如图3所示,研究人员通过分析人工酶结构,发现这些人工酶与天然酶在结构和序列上的巨大差异。此外,通过使用CD-HIT进行聚类分析,所有人工酶的序列同一性均低于40%,表明它们与现有数据库中的序列差异显著。
为增强EasIFA的预测能力,研究团队对数据集进行了序列和结构基的数据增强,最终EasIFA具备了识别人工设计的支架酶的活性位点的能力,预测结果如图4a所示,证明了其在预测人工酶活性方面的有效性。
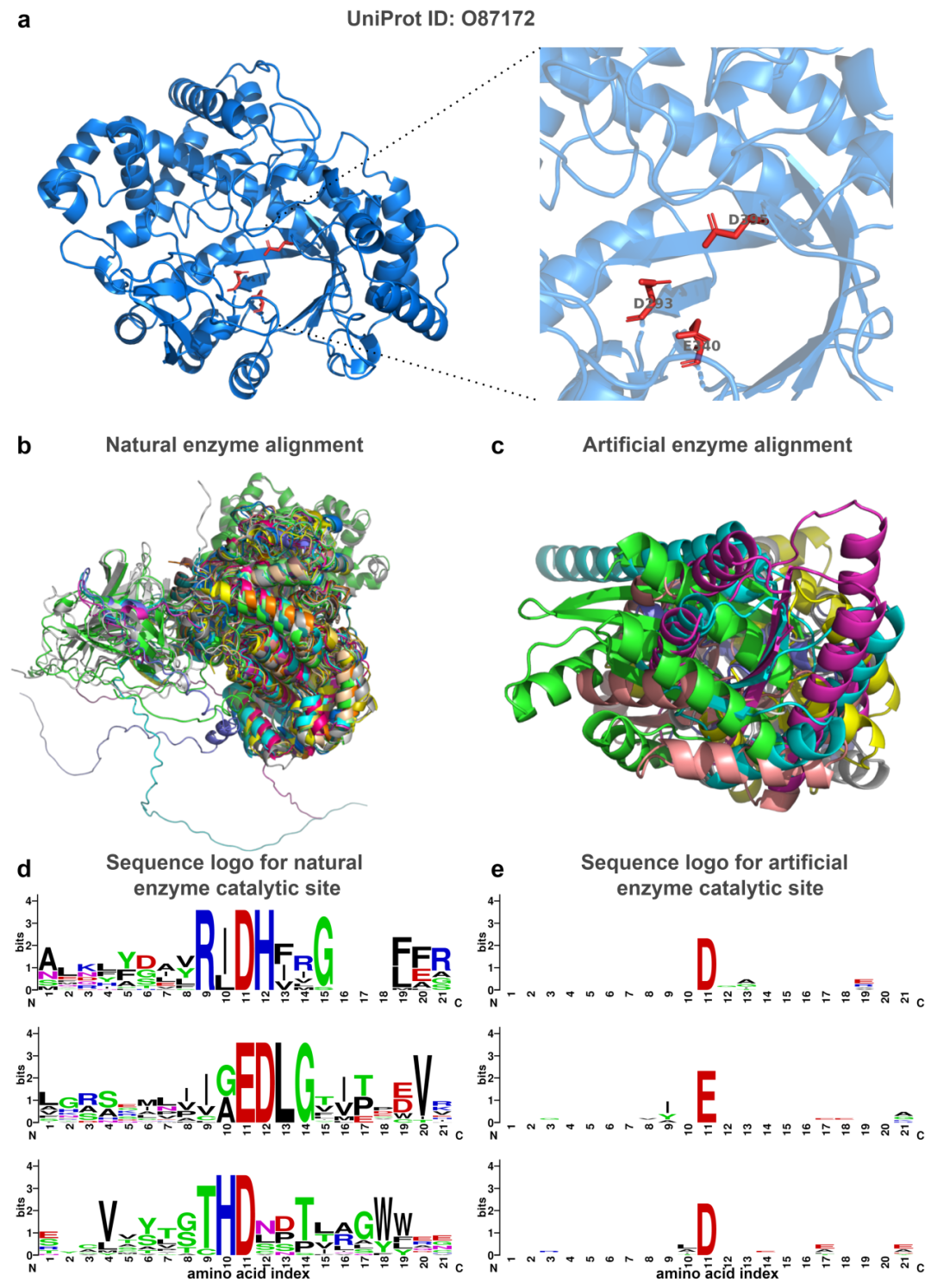
图3. 用RFdiffusion人工设计的酶与天然酶的差异分析
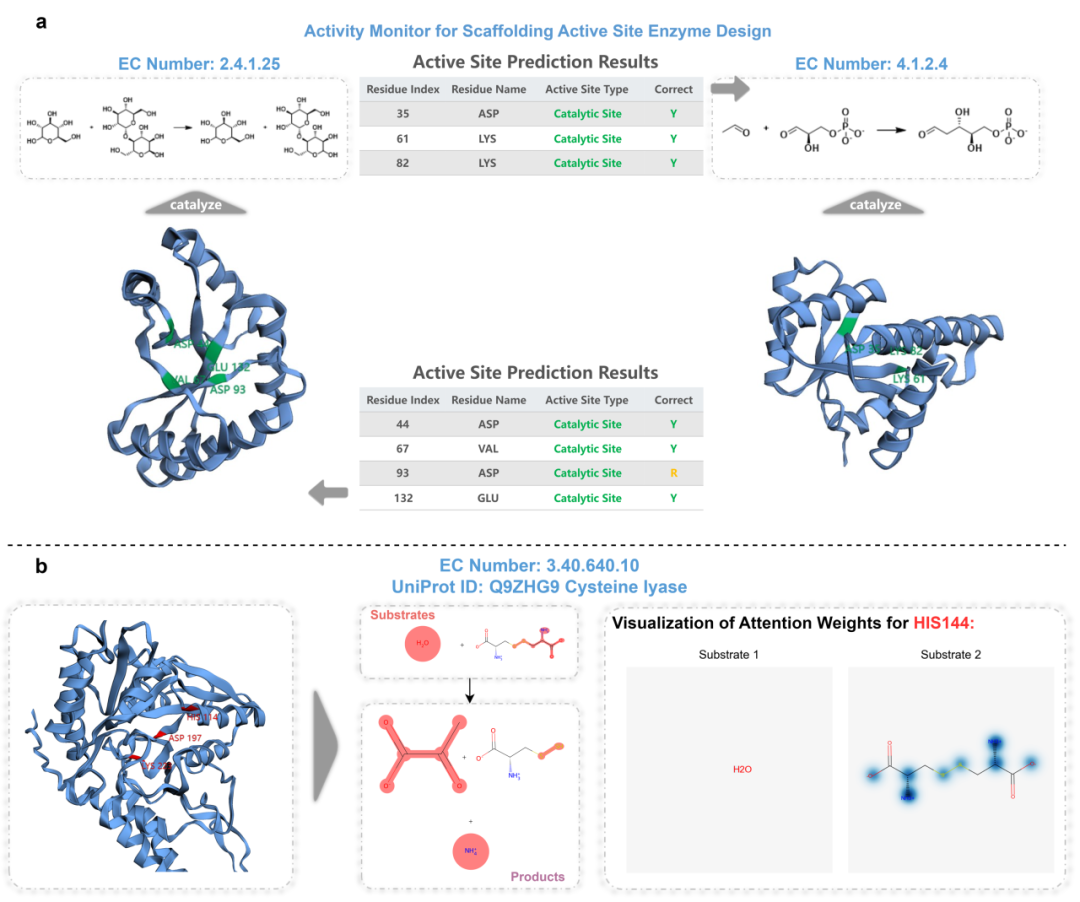
图4. 活性位点支架酶设计活性监测与可解释案例研究
可解释信息交互网络的注意力权重可视化
在酶-反应信息交互网络中引入注意力机制大大提高了EasIFA模型的高可解释性。通过分析MCSA E-RXN CSA验证集中的一些案例,研究团队识别出了专门关注关键酶-反应交互的注意力层和头部。研究团队对底物原子上的酶活性残基位点的注意力权重进行了可视化(用蓝色标记),这些权重超过了基于验证集确定的阈值。这种可视化为许多测试集样本提供了很强的可解释性。图4b显示了半胱氨酸裂解酶的注释结果(左)以及底物分子上活性位点权重的可视化(右)。研究团队还使用RDChiral的反应模板对整个胱氨酸裂解反应进行了可视化,突出显示了反应中心(中间)。值得注意的是,His144对L-胱氨酸两性离子的反应中心,特别是氨基,表现出了很高的注意力权重。这与酶的催化机制相一致,突出了His144在L-胱氨酸两性离子氨基去质子化中的关键作用。由于L-胱氨酸两性离子的对称结构,EasIFA模型关注了反应中心的两侧。然而,值得注意的是,模型的交互网络对水分子的关注较少,这一趋势也在其他样本中观察到。
结论
研究团队开发了EasIFA算法,这是一个用于酶活性位点注释的端到端模型。该模型结合了几项关键技术:使用PLMs-Structure融合方法表示酶,通过图注意力网络引入酶反应特征,并利用基于注意力机制的交互网络整合酶反应信息。EasIFA在SwissProt E-RXN ASA数据集上的表现显著优于现有主流算法如BLASTp、AEGAN和SiteMap,且注释速度远快于这些算法。此外,EasIFA通过知识库转移方案,能够将在大型粗略数据集上训练的模型应用于精细的小型数据集,如MCSA。该算法还展示了在人工酶领域的应用潜力,能够扩展从天然酶获得的活性位点知识到不同分布的人工酶。EasIFA的酶-反应信息交互网络通过注意力机制提取具体的机制信息,具有良好的可解释性。总体上,EasIFA被认为能替代常规的注释工具,有效减轻研究人员的负担,推动药物设计、疾病机制解析和酶工程发展。
参考资料
Wang, X., Yin, X., Jiang, D. et al. Multi-modal deep learning enables efficient and accurate annotation of enzymatic active sites. Nat Commun 15, 7348 (2024).
https://www.nature.com/articles/s41467-024-51511-6
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢