曾造出世界最大芯片公司 Cerebras,发布了全球最快的 AI 推理架构——Cerebras Inference。运行 Llama3.1 8B 时,它能以 1800 token/s 的速率吐出文字。自推出了使用一整个晶圆制造的芯片以来,Cerebras 在过去几年里的宣传,都是以攻进英伟达所把持的 AI 芯片市场为目标。以下文章转载自「新智元」和「半导体行业观察」,Founder Park 略有调整。
01
「全球最快」AI 推理服务
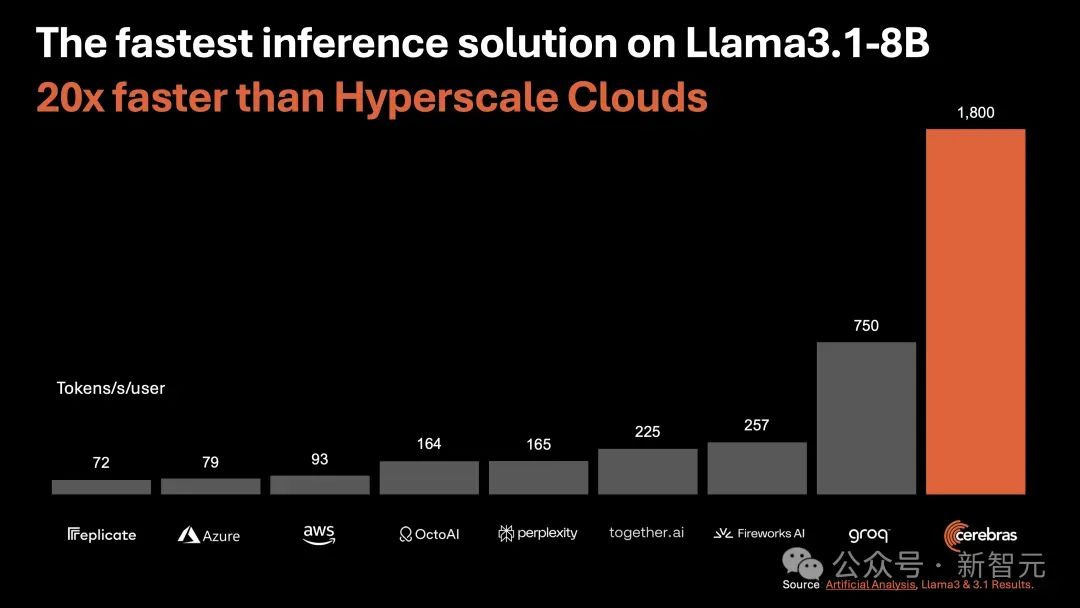
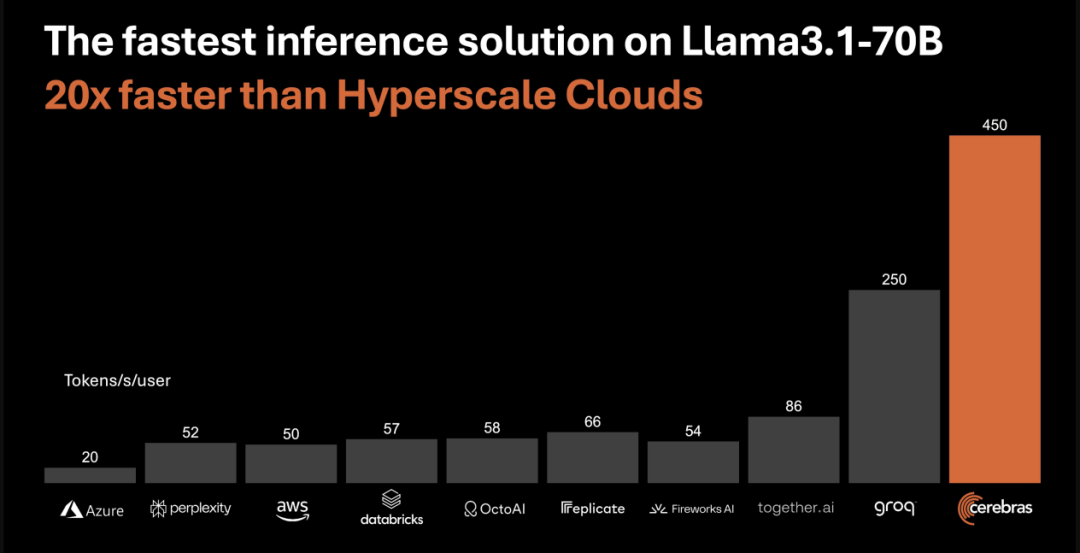
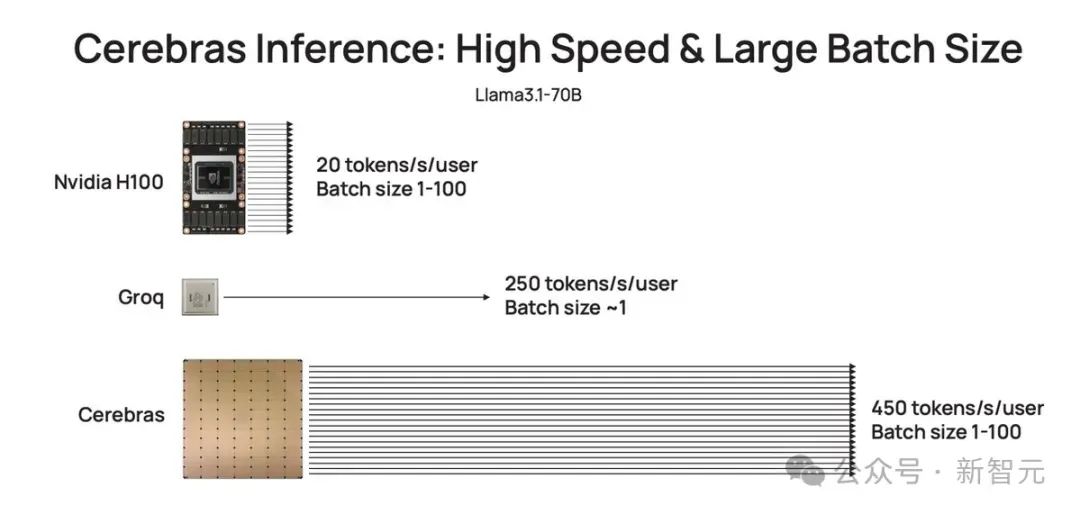
据首席执行官 Andrew Feldman 介绍,新的 AI 推理架构——Cerebras Inference。通过使用 SRAM,在以 16 位精度运行 Llama 3.1 8B 时每秒能够生成 1,800 个以上的 token,而性能最高的 H100 实例每秒最多可生成 242 个 token。不论是总结文档,还是代码生成等任务,响应几乎一闪而过,快到让你不敢相信自己的眼睛。如下图右所示,以往,微调版 Llama3.1 8B 推理速度为 90 token/s,清晰可见每行文字。而现在,直接从 90 token/s 跃升到 1800 token/s,相当于从拨号上网迈入了带宽时代。左边 Cerebras Inference 下模型的推理速度,只能用「瞬间」、「疯狂」两字形容。比起英伟达 GPU,Cerebras Inference 的推理速度快 20 倍,还要比专用 Groq 芯片还要快 2.4 倍。另外,对于 70B 参数的 Llama3.1,可达到 450 token/s 及时响应。值得一提的是,Cerebras 并没有因为提高 LLM 的速度,而损失其精度。测试中,使用的 Llama3.1 模型皆是采用了 Meta 原始 16 位权重,以便确保响应高精度。最关键的是,价格还实惠。根据官方 API 定价,Llama 3.1 8B 每百万 token 仅需 10 美分,Llama 3 70B 每百万 token 仅需 60 美分。如此之高的性价比,更是打破了业界纪录,不仅远超之前的保持者 Groq,而且和其他平台相比,甚至是隔「坐标轴」相望了。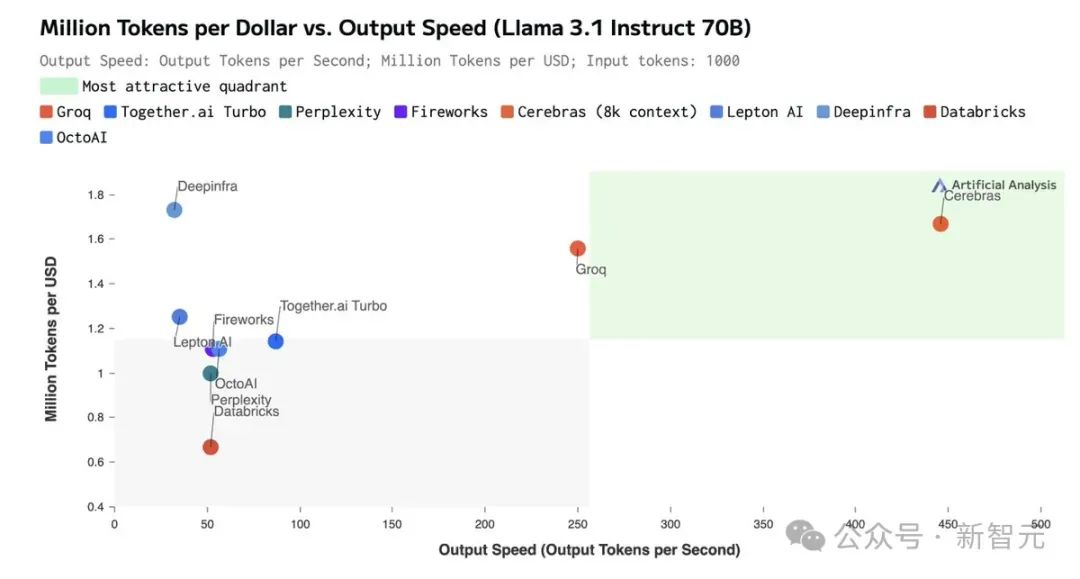
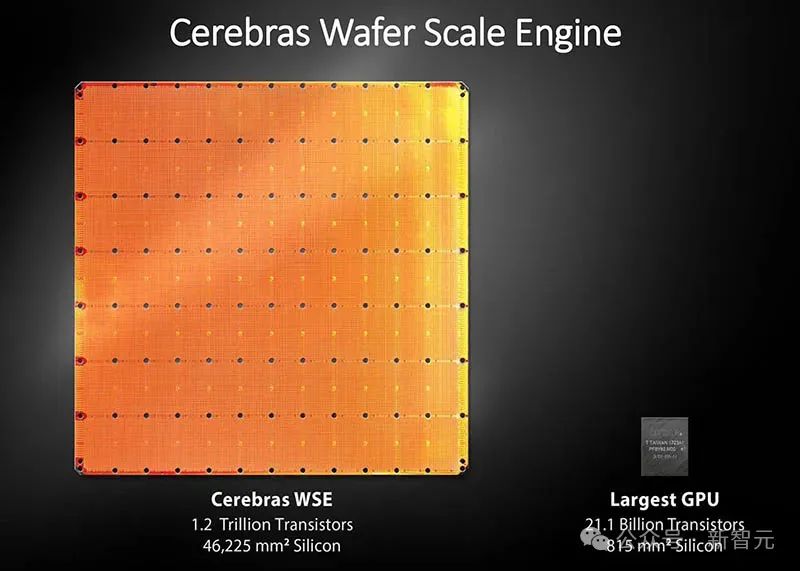
正是因为 Cerebras Inference 背后,是由自研的第三代芯片 Wafer Scale Engine 助力,才得以 1/5 价格快速推理 Llama3.1。看到自家模型推理如此神速,LeCun、Pytorch 之父纷纷动手转发起来。02
自研世界最大芯片,
解决英伟达GPU搞不定的难题
快速推理为什么重要?通常,LLM 会即刻输出自己的全部想法,而不考虑最佳答案。而诸如 scaffolding(脚手架)这类的新技术,则如同一个深思熟虑的智能体,会在作出决定前探索不同的可能解决方案。
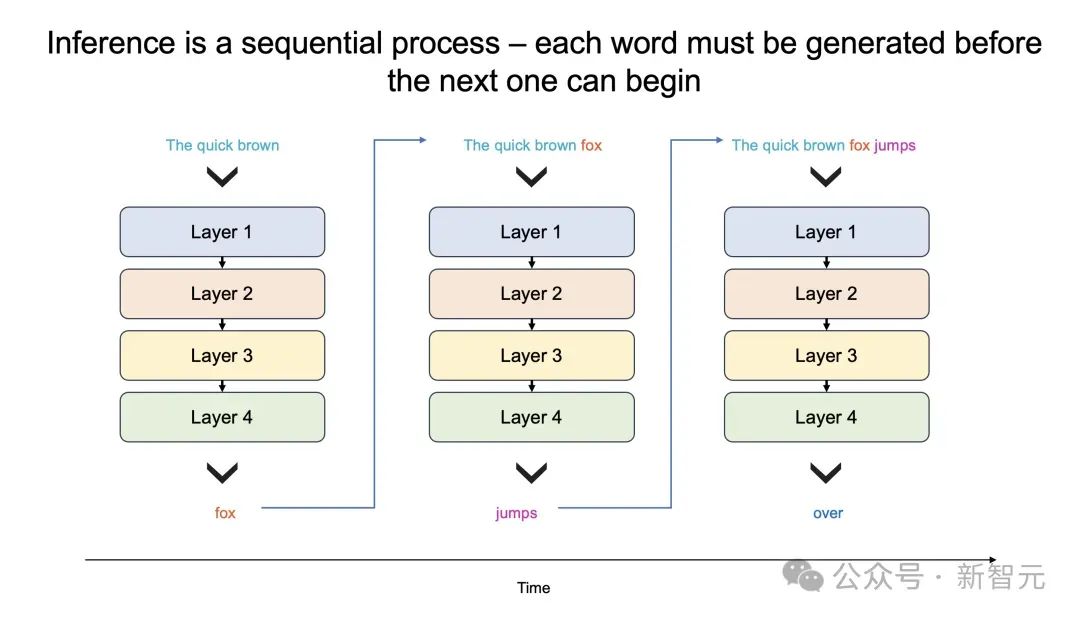
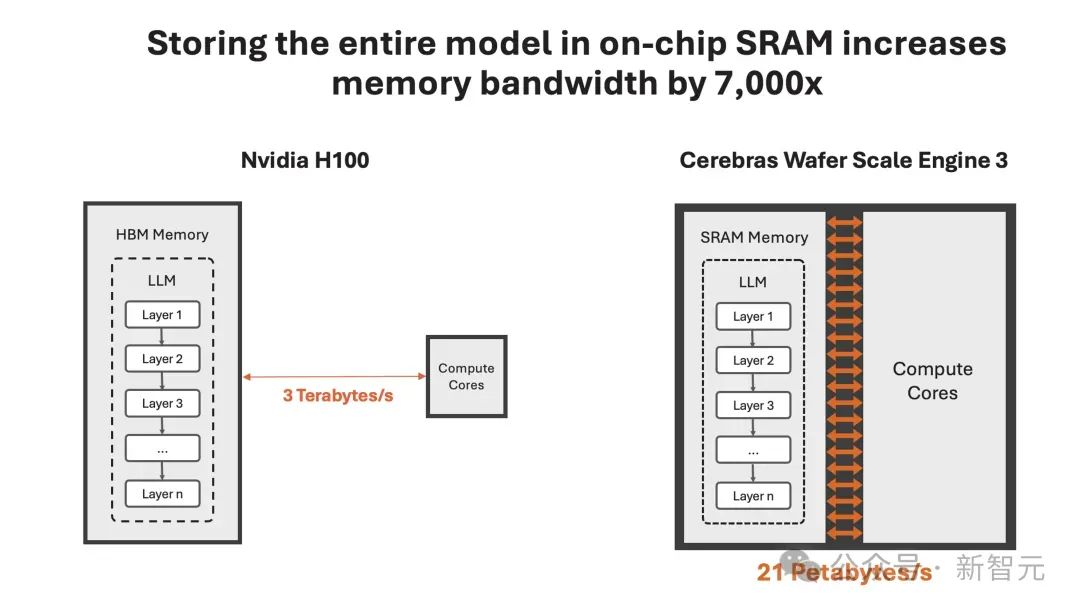
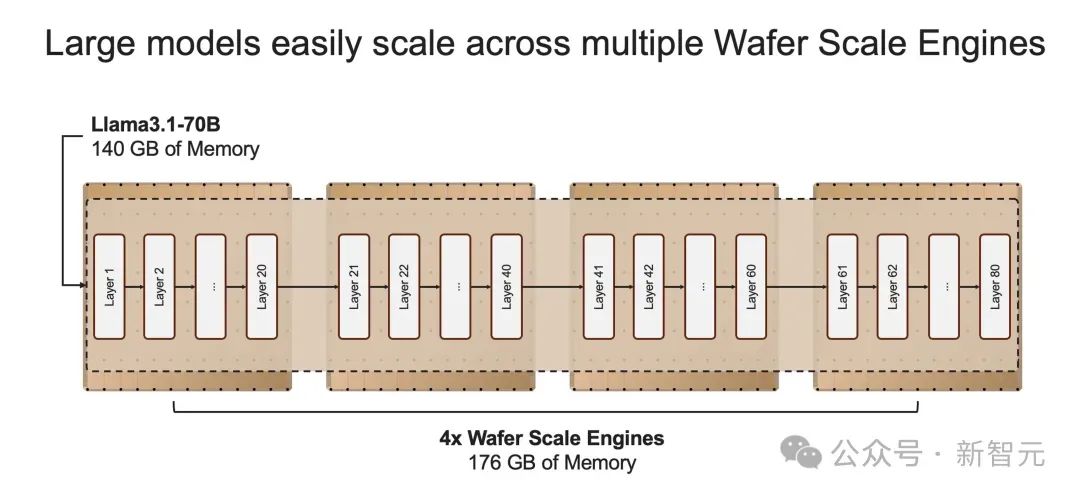
这种「先思考后发言」的方式在代码生成等严苛任务中,可以带来超过 10 倍的性能提升,从根本上提升了 AI 模型的智能,且无需额外训练。但这些技术在运行时,需要多达 100 倍的 token。因此可见,如果我们能大幅缩短处理时间,那么就可以实现更为复杂的 AI 工作流程,进而实时增强 LLM 的智能。但现实是,很多 LLM 的响应,就像拨号上网加载网页一样,一个字一个字慢慢地吐出,这是为什么?关键原因所在,大模型自身的顺序特性,以及需要大量的 GPU 内存和带宽。由于 GPU 的内存带宽限制,如今推理速度为每秒几十个 token,而不是数千个。更进一步说,大模型每个生成的单词,都必须通过整个模型进行处理,即所有参数必须从内存投入到计算中。而每生成一个单词,就需要一次处理,以此循环往复。也就是,生成 100 个单词需要 100 次处理,因为「下一词」的预测,皆需要依赖前一个单词,而且这个过程无法并行。那么,想要每秒生成 100 个单词,就需要所有模型参数,每秒投入计算 100 次。由此,这对 GPU 内存带宽提出了高要求。以社区流行的 Llama3.1-70B 模型为例。模型有 700 亿参数,每个参数是 16 位,需要 2 字节的存储,那整个模型便需要 140GB 的内存。想要模型输出一个 token,那 700 亿参数必须从内存,移动到计算核心,以执行前向推理计算。由于 GPU 只有约 200MB 的片上内存,模型无法存储在芯片。因此,每次生成的 token 输出时,需将整个占用 140GB 内存的模型,完整传输到计算中。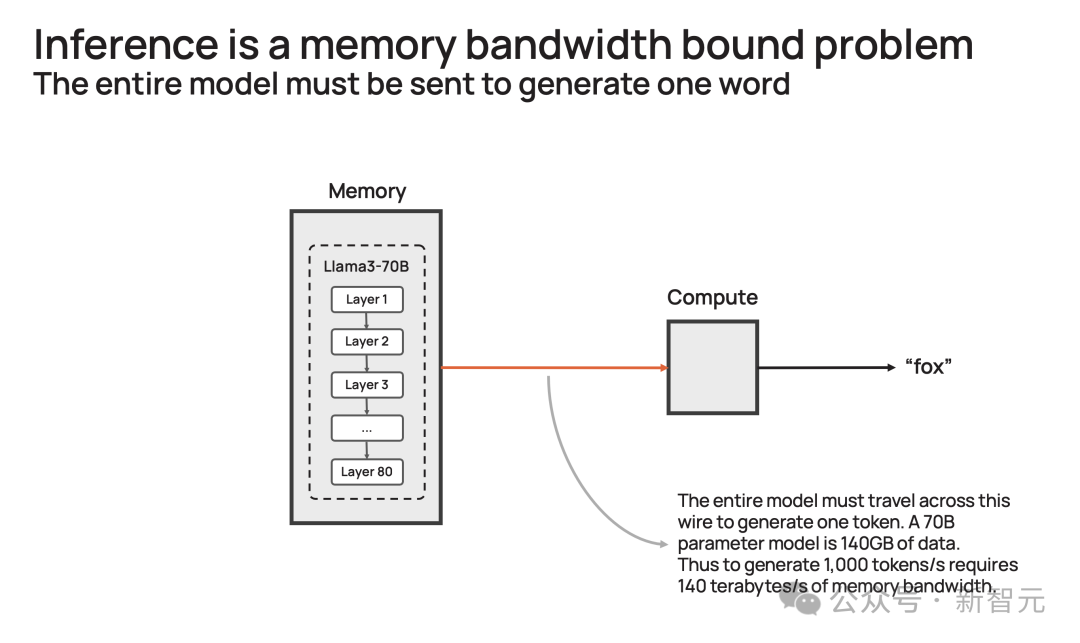
再细算下来,为了实现 10 token/s,则需要 10*140=1.4 TB/s 的内存带宽。那么,一个 H100 有 3.3 TB/s 的内存带宽,足以支持这种缓慢的推理。而若要实现即时推理,需要达到 1000 token/s 或 140 TB/s,这远远超过任何 GPU 服务器/系统内存带宽。一直以来,这家公司就致力于打造世界上最大芯片,希望将整个模型存储在一个晶片上,以此来解决内存带宽瓶颈。凭借独特的晶圆设计,WSE-3 单个芯片上便集成了 44GB SRAM,具备 21 PB/s 的内存带宽。单个芯片拥有如此大内存,便消除了对外部内存的需求,以及将外部内存连接到计算的慢速通道。总的来说,WSE-3 的总内存带宽为 21PB/s,是 H100 的 7000 倍。它是唯一一款同时具有 PB 级计算和 PB 级内存带宽的 AI 芯片,使其成为高速推理的近乎理想设计。Cerebras 推理不仅速度超快,而且吞吐量巨大。与小型 AI 芯片相比,芯片上内存多了约 200 倍,支持从 1-100 的批大小,使其在大规模部署时,具有极高的成本效益。正是有了如此强大的芯片,Cerebras Inference 的快速推理得以实现。它的出现,是为了实现数十亿到万亿参数模型的推理。如果模型参数超过单个晶圆的内存容量时,研究人员将在「层边界」将其拆分,并映射到多个 CS-3 系统上。20B 模型适合单个 CS-3,而 70B 模型则至少需要 4 个这样的系统。官方表示,未来几周,将会测试更大参数版本的模型,比如 Llama3-405B、Mistral Large。
03
首当其冲的受害者Groq
从上述介绍可以看到,Cerebras 能否撬动英伟达不知道,但第一个受害者,已经跃然纸上,那就是早阵子引起广泛讨论的 Groq。从设计上看,Groq 的语言处理单元 (LPU) 实际上采用了与 Cerebras 类似的方法,即依赖 SRAM。Groq 并不是 AI 芯片领域的新手,它由谷歌 TPU 的最初创造者 Jonathan Ross 在 2016 年创立。Ross 和他的团队开发了一种新的架构,最初称为张量流处理器 (TSP),后更名为语言处理单元(LPU)。这是一个巨大的芯片大小的内核,使用一种新颖的策略:确定性计算,可以非常高效地提供大量的 FLOPS。Groq 的主要架构优势在于所开发的是完全确定性的架构,完全由软件控制。这意味着更有效率。大多数应用程序都是非确定性的,例如文字处理器不知道人们要输入的下一个字母,因此它必须准备好响应它收到的任何输入。而现代芯片的很多复杂性都来自于能够处理非确定性计算。Groq 卡没有片外内存。每个芯片上有 220 MB 的 SRAM,仅此而已。这意味着,想运行大型模型需要很多芯片。这正是 Groq 与 Cerebras 的不同之处——Groq 的架构 SRAM 密度较低,因此需要通过光纤连接更多加速器来支持任何给定的模型。Cerebras 认为 Groq 使用 8 位量化来实现其性能目标,这减少了模型大小、计算开销和内存压力,但代价是准确性有所下降。与 Groq 类似,Cerebras 计划通过与 OpenAI 兼容的 API 提供推理服务。这种方法的优势在于,已经围绕 GPT-4、Claude、Mistral 或其他基于云的模型构建应用程序的开发人员无需重构其代码即可整合 Cerebra 的推理产品。然而,与 Groq 不同的是,Feldman 表示 Cerebras 将继续为某些客户提供内部部署系统,例如那些在严格监管的行业运营的客户提供内部部署系统。虽然 Cerebras 可能比竞争加速器具有性能优势,但其支持的模型仍然有些有限。在发布时,Cerebras 支持 Llama 3.1 的 80 亿 和 700 亿参数版本。不过,这家初创公司计划增加对 4050 亿、Mistral Large 2、Command R+、Whisper、Perplexity Sonar 以及自定义微调模型的支持。04
绕开英伟达设立的门槛
Nvidia 之所以能牢牢占据 AI 市场,原因之一是其在计算统一设备架构(CUDA:Compute Unified Device Architecture)方面的主导地位,这是其并行计算平台和编程系统。CUDA 提供了一个软件层,让开发人员可以直接访问 GPU 的虚拟指令集和并行计算元素。
多年来,Nvidia 的 CUDA 编程环境一直是 AI 开发的事实标准,并围绕它建立了庞大的工具和库生态系统。这造成了一种情况,即开发人员经常被锁定在 GPU 生态系统中,即使其他硬件解决方案可以提供更好的性能。Cerebras 的 WSE 是一种与传统 GPU 完全不同的架构,需要对软件进行调整或重写才能充分利用其功能。开发人员和研究人员需要学习新工具和潜在的新编程范例才能有效地使用 WSE。Cerebras 试图通过支持 PyTorch 等高级框架来解决这个问题,让开发人员更容易使用其 WSE,而无需学习新的低级编程模型。它还开发了自己的软件开发工具包,以允许进行低级编程,可能为某些应用程序提供 CUDA 的替代方案。但是,通过提供不仅速度更快而且更易于使用的推理服务(开发人员可以通过简单的 API 与其进行交互,就像使用任何其他基于云的服务一样),Cerebras 使刚刚加入竞争的组织能够绕过 CUDA 的复杂性并仍然实现顶级性能。这符合行业向开放标准的转变,开发人员可以自由选择最适合工作的工具,而不受现有基础设施限制的束缚。目前,Cerebras Inference 可通过聊天平台,以及 API 访问,任何一个人可随时体验。
体验传送门:https://cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed基于熟悉的 OpenAI Chat Completions 格式,开发者只需更换 API 密钥即可集成强大的推理功能。首次推出时,Cerebras 提供了 Llama3.1 8B 和 70B 模型,而且有能力每天为开发者和企业,提供数千亿 token。不过值得注意的是,在 Cerebras 上跑的 Llama 3.1,上下文只有 8k。相比之下,其他平台都是 128K。
更多阅读
在公司内部,AI应用正在这4个大场景里加速落地
转载原创文章请添加微信:founderparker
内容中包含的图片若涉及版权问题,请及时与我们联系删除










评论
沙发等你来抢