

人工智能(AI)的发展极大地影响了我们的日常生活,甚至推动了新的科学发现。但是,基于深度学习的现代AI模型仍然是不透明的“黑匣子”,并提出了一个关键的“为什么问题” - 为什么这些AI模型能够实现如此出色的结果?回答这个问题会导致对可解释的AI(XAI)的研究,该研究提供了许多好处,例如增强模型性能,建立用户信任并从数据中提取更深入的见解。虽然已经针对图像和文本(例如图像和文本)探索了XAI,但图数据的相关研究(一种代表实体及其关系的更复杂的数据模式)欠发展。考虑到图数据及其在包括科学、业务和医疗保健在内的主要领域的普遍应用的无处不在,用于图数据的XAI成为关键的研究方向。
本文旨在从三个互补和同样重要的角度来解决XAI中的差距:模型、用户和数据。因此,我的研究通过开发来推进XAI的图数据:(1)面向模型的解释方法,阐明机制并提高最先进的 AI 模型在图数据上的性能。(2)面向用户的解释方法,提供直观的可视化和自然语言解释,以建立用户对实际应用的图AI 模型的信任。(3)面向数据的解释方法,可以识别关键模式并从图数据中提取见解,从而可能带来新的科学发现。通过整合这三个观点,本论文提高了AI对跨领域和应用程序的图数据的透明度、可信度和洞察力。

论文题目:Explainable Artificial Intelligence for Graph Data
作者:Shichang Zhang
类型:2024年博士论文
学校:University of California, Los Angeles(美国加州大学洛杉矶分校))
下载链接:
链接: https://pan.baidu.com/s/1Kax_luZ6O9Sha853oho5Mw?pwd=9vf8
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
人工智能 (AI) 取得了显著进步,在从图像识别和聊天机器人到游戏和新材料结构预测等各个领域都取得了人类水平甚至超越人类的表现。这些发展对我们的日常生活产生了重大影响,甚至推动了新的科学发现。然而,令人印象深刻的人工智能成就很大程度上是基于深度学习的发展,这使得人工智能模型仍然不透明且难以解释,通常被称为“黑匣子”。这些黑匣子人工智能模型缺乏可解释性,这引发了一个关键的“为什么”问题,令研究人员、从业者和政策制定者担忧——为什么这些人工智能模型能够取得如此显著的成果?随着人工智能模型变得越来越普遍,并越来越多地影响各个领域的关键决策过程,理解它们变得势在必行。
回答“为什么”这个问题引发了对可解释人工智能 (XAI) 的研究,它提供了许多好处,例如增强模型性能、建立用户信任以及从数据中提取更深入的见解。虽然近年来 XAI 领域获得了关注,研究人员正在探索各种解释人工智能模型的技术,但重点主要放在图像和文本等数据模式上。然而,图数据领域不仅代表实体,还代表它们的关系,在 XAI 的背景下却很少受到关注。鉴于图数据在许多领域无处不在,具有众多现实世界的应用,例如社交网络分析、电子商务图推荐、分子图的属性预测等等,图数据的 XAI 成为一个重要的研究方向。
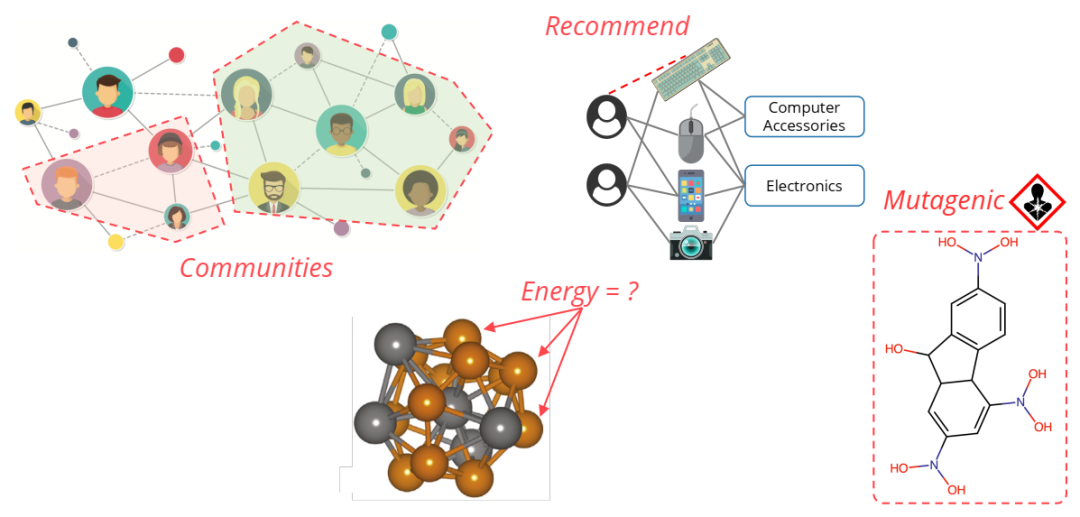 AI在图数据上的无处不在应用。在社交网络上检测社区。向客户推荐产品。预测材料的原子能量。对分子的特性进行分类。
AI在图数据上的无处不在应用。在社交网络上检测社区。向客户推荐产品。预测材料的原子能量。对分子的特性进行分类。
本论文旨在从三个互补且同等重要的角度解决图数据的 XAI 差距:模型、用户和数据(图 1.2)。这些观点是整个 AI 流程不可或缺的一部分,构成了 XAI 研究的基础支柱。首先,模型是预测、生成或任何其他设计任务的核心。揭示其机制是 XAI 需要解决的一个关键挑战,其结果可用于调试模型并进一步提高模型性能。接下来,作为解释的利益相关者,用户必须发现它们是可以理解的。XAI 研究人员的指导原则类似于“向 6 岁的孩子解释登月”,强调只有当解释足够清晰以在用户(包括没有任何技术背景的用户)之间建立信任时,解释才被认为是成功的。最后,数据支撑模型并提供模型学习的知识。在揭示模型的底层机制后,解释有望更深入地挖掘并从数据中提取见解,尤其是领域专家未曾预料到的见解。这一方面对于经常以图表形式出现的科学数据尤其重要,这种意外的发现可能会带来重大突破。
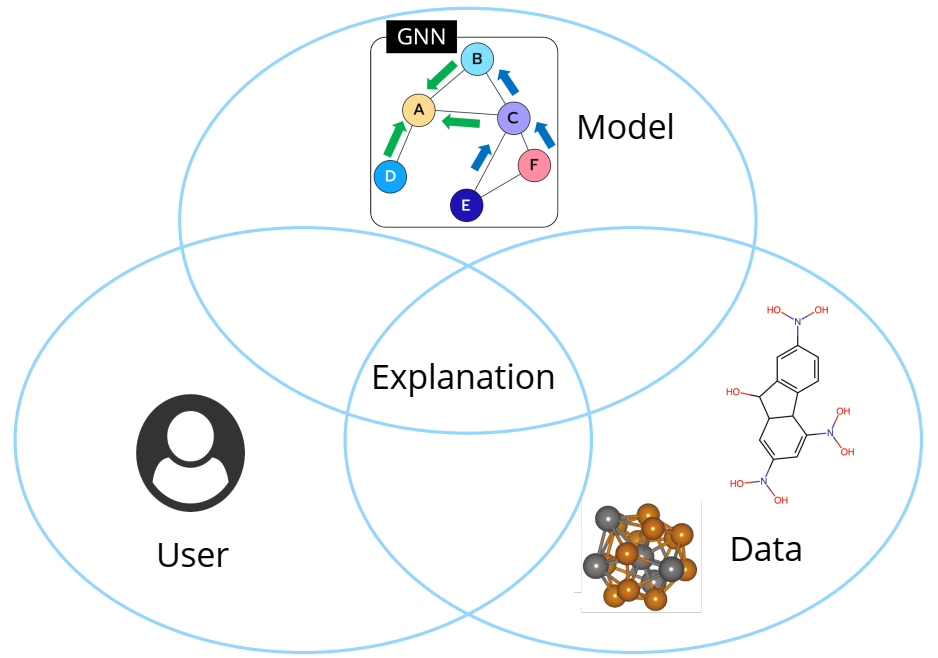
XAI的三种互补观点。
我的研究通过开发关于这三个视角的新方法和框架来推进图数据的 XAI:
1. 面向模型的解释方法,阐明机制并提高图数据上 AI 模型的性能。特别是,我专注于最先进的图神经网络 (GNN) 模型,并提出一种基于合作博弈论的新型结构感知方法来解释 GNN 预测过程,特别是 GNN 消息传递的工作原理。
2. 面向用户的解释方法,提供直观的可视化和自然语言解释以建立用户信任。一个特定的应用涉及向用户推荐电子商务图表上的链接预测项目。我的解释采用直观的路径形式,连接预测链接的源和目标,并且可以用自然语言清楚地表达给非技术用户。
3. 面向数据的解释方法,识别关键模式并从图数据中提取见解。从这个角度来看,我设计了事后解释方法以及为科学图数据量身定制的固有可解释模型。这些方法已应用于材料科学和分子科学问题,产生纯粹基于人工智能的解释,除了数据之外没有任何人类知识输入,但与领域专家的知识相匹配。
通过整合这三个互补的观点,本论文通过提高跨领域和应用的图数据人工智能模型的透明度、可信度和洞察力,为 XAI 做出了贡献。此外,它还可以促进有效的模型调试和错误分析,确保决策过程的公平性,促进人工智能系统的负责任的部署,并可能带来新的科学发现。
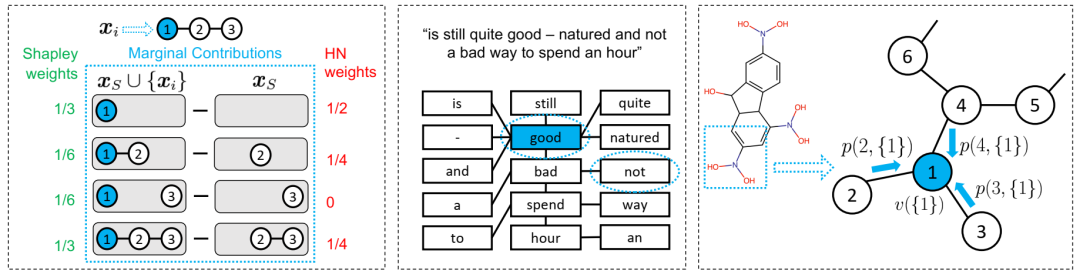 具有结构感知值的图表上的解释。具有结构感知值(如HN)的图表上的说明提供了优于非结构感知值(例如Shapley)。(a)合成图(左):Shapley值仅基于XS的大小将权重分配给M(i,s),而HN值则分配了考虑结构的权重,尤其是对断开的XS的重量为零。(b)文本图(中间):对于归类为正的句子,当他们不通过“坏”连接时,不应考虑{“非”,“好”}联盟。(c)化学图(右):对于具有诱变函数组-no2的化学图,如果在官能团内局部确定的本地决定,则可以更好地识别原子N(节点1)的重要性。
具有结构感知值的图表上的解释。具有结构感知值(如HN)的图表上的说明提供了优于非结构感知值(例如Shapley)。(a)合成图(左):Shapley值仅基于XS的大小将权重分配给M(i,s),而HN值则分配了考虑结构的权重,尤其是对断开的XS的重量为零。(b)文本图(中间):对于归类为正的句子,当他们不通过“坏”连接时,不应考虑{“非”,“好”}联盟。(c)化学图(右):对于具有诱变函数组-no2的化学图,如果在官能团内局部确定的本地决定,则可以更好地识别原子N(节点1)的重要性。
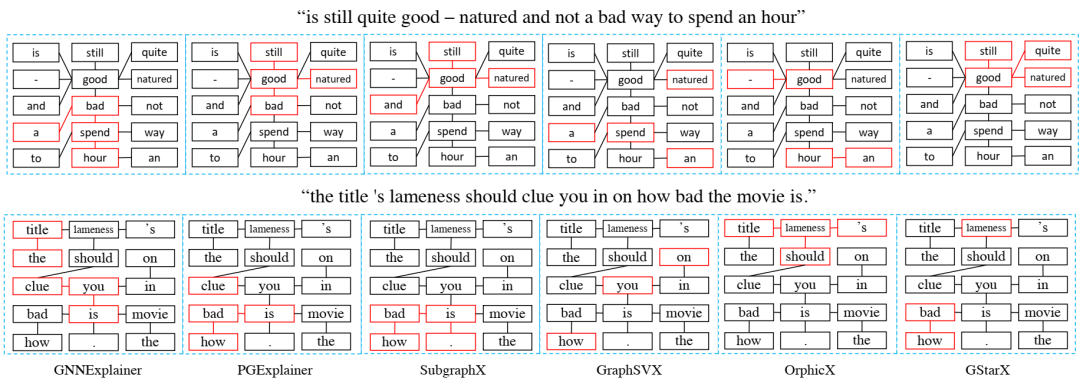 从GraphSST2中解释句子。我们展示了一个正句(上)和一个否定句(下)的解释。红色轮廓指示所选的节点/边缘作为解释。Gstarx与基线相比,更准确地识别了情感词。
从GraphSST2中解释句子。我们展示了一个正句(上)和一个否定句(下)的解释。红色轮廓指示所选的节点/边缘作为解释。Gstarx与基线相比,更准确地识别了情感词。
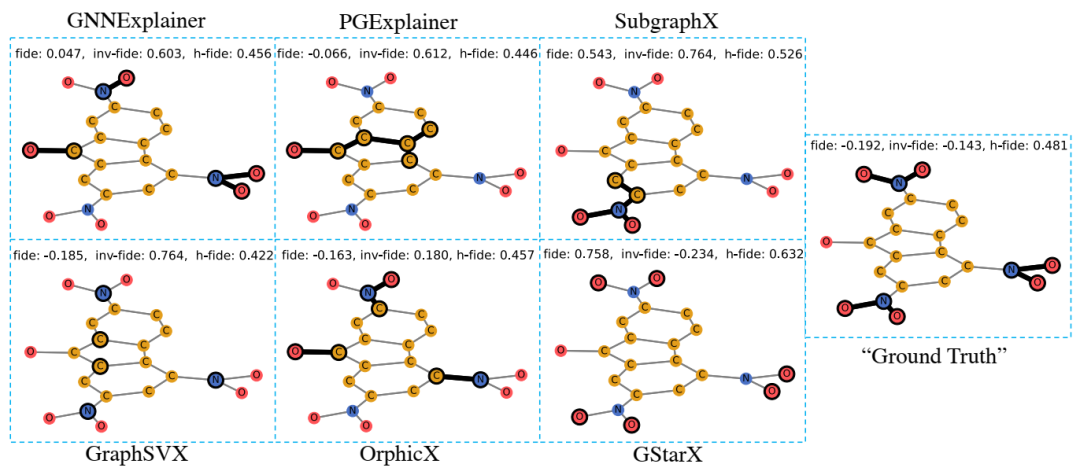 关于突变中诱变分子的解释。碳原子(C)为黄色,氮原子(N)为蓝色,氧原子为红色(O)。黑暗轮廓表明所选节点/边缘作为解释。我们报告了解释忠诚度(FIDE),Inv-Fidelity(Inv-Fide)和H-Fidelity(H fide)。就这些指标而言,GSTARX给出了比其他方法的明显更好的解释。
关于突变中诱变分子的解释。碳原子(C)为黄色,氮原子(N)为蓝色,氧原子为红色(O)。黑暗轮廓表明所选节点/边缘作为解释。我们报告了解释忠诚度(FIDE),Inv-Fidelity(Inv-Fide)和H-Fidelity(H fide)。就这些指标而言,GSTARX给出了比其他方法的明显更好的解释。
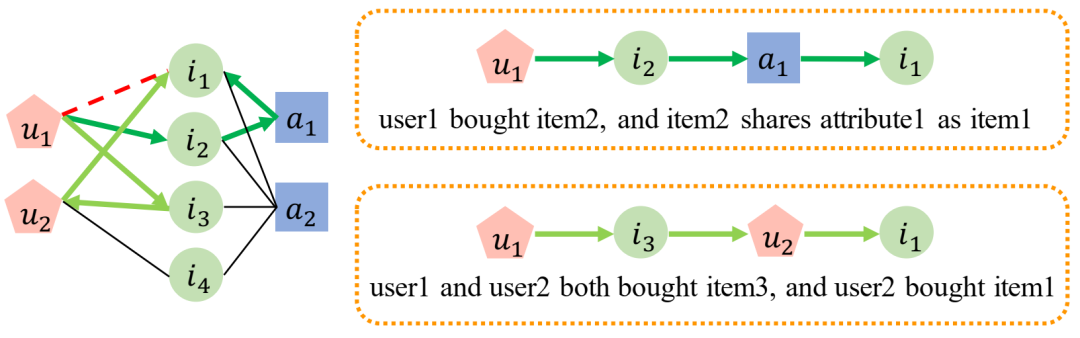 基于路径的解释是由页面链接生成的。给定一个GNN模型和一个预测的链接(U1,I1)(红色红色),在用户U,项目I和属性A(左)的异质图上(左)。页面链接生成两个路径解释(绿色箭头)。我们说明了右边的解释。
基于路径的解释是由页面链接生成的。给定一个GNN模型和一个预测的链接(U1,I1)(红色红色),在用户U,项目I和属性A(左)的异质图上(左)。页面链接生成两个路径解释(绿色箭头)。我们说明了右边的解释。
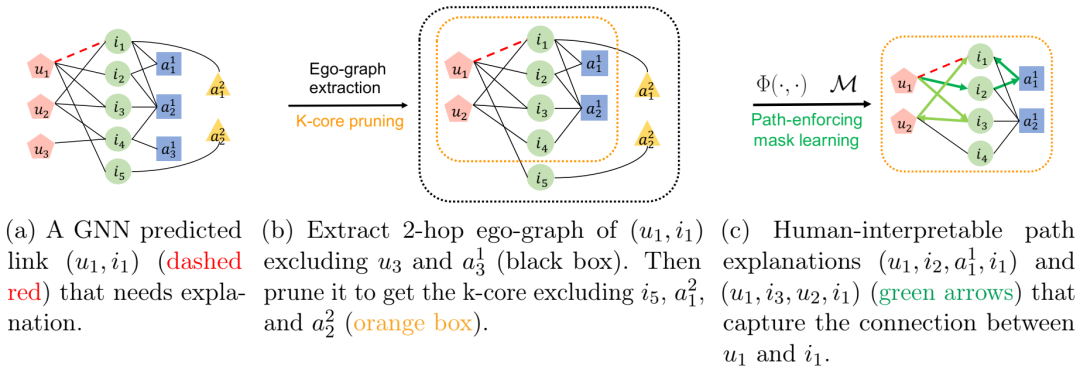 页面链接框架的插图。带有用户节点u,项目节点I和两个属性类型A1和A2的图上的页面链接。
页面链接框架的插图。带有用户节点u,项目节点I和两个属性类型A1和A2的图上的页面链接。
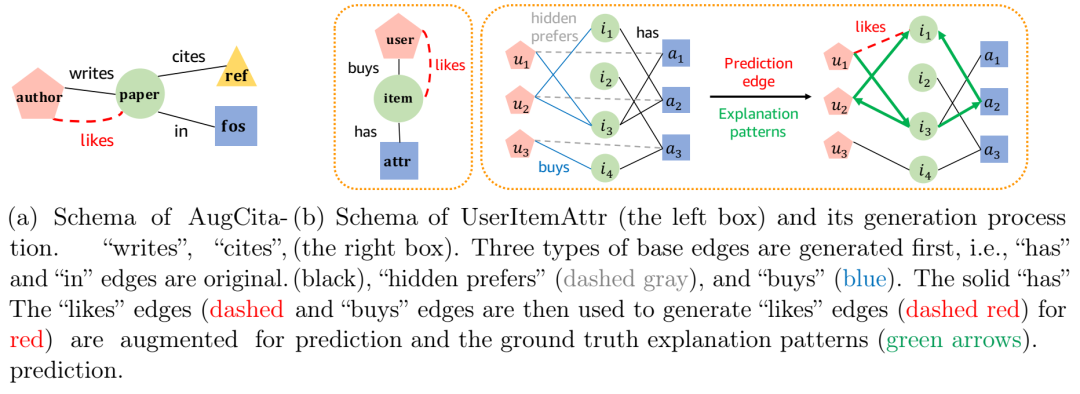 提出的增强图AUGCITITION和合成图UserItemattr。
提出的增强图AUGCITITION和合成图UserItemattr。
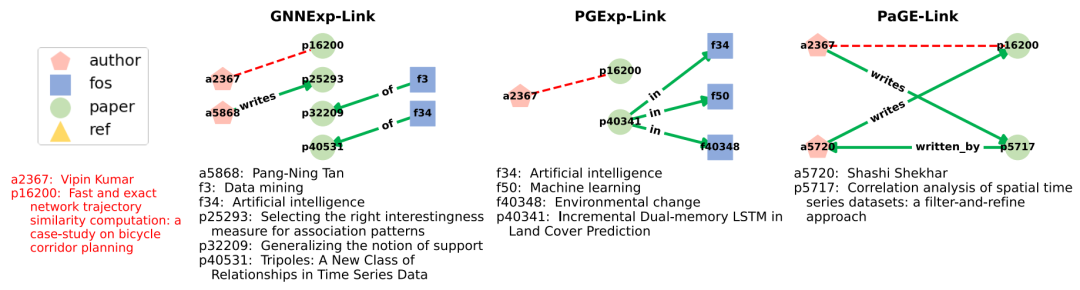 解释可视化和页面链路和基准之间的比较。不同解释器的解释(绿色箭头)针对预测的链接(A2367,P16200)(红色虚线)。通过页链接产生的解释解释了共同创作的建议,而基线解释则不太容易解释。
解释可视化和页面链路和基准之间的比较。不同解释器的解释(绿色箭头)针对预测的链接(A2367,P16200)(红色虚线)。通过页链接产生的解释解释了共同创作的建议,而基线解释则不太容易解释。
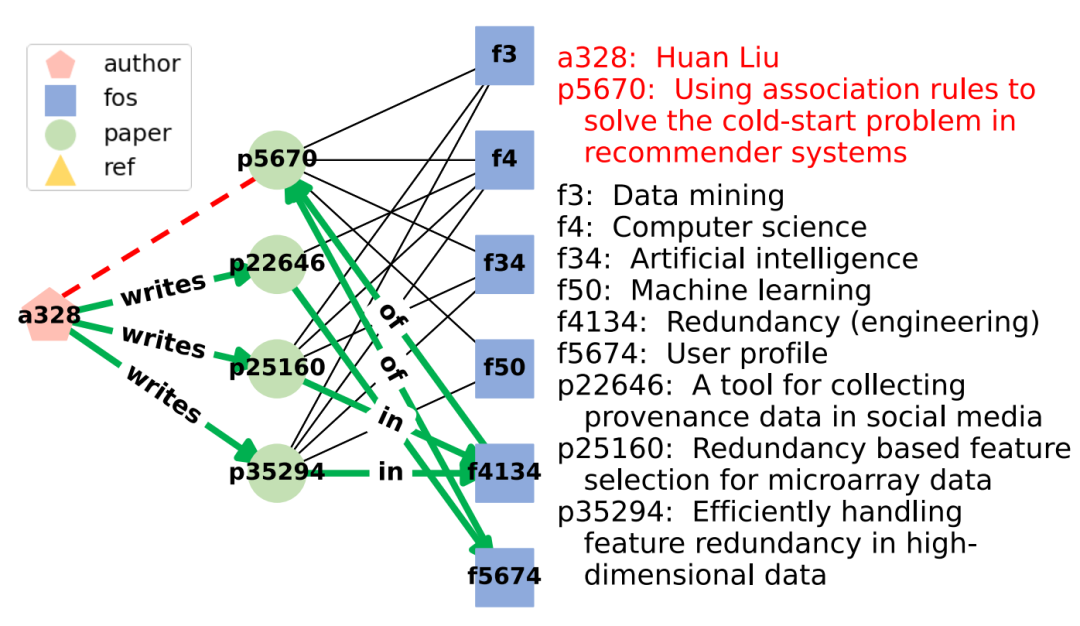 通过页链接选择的顶点。前三个路径(绿色箭头)用于解释预测链接(A328,p5670)(红色虚线)。选定的路径很短,并且不会浏览“计算机科学”等通用研究领域。
通过页链接选择的顶点。前三个路径(绿色箭头)用于解释预测链接(A328,p5670)(红色虚线)。选定的路径很短,并且不会浏览“计算机科学”等通用研究领域。
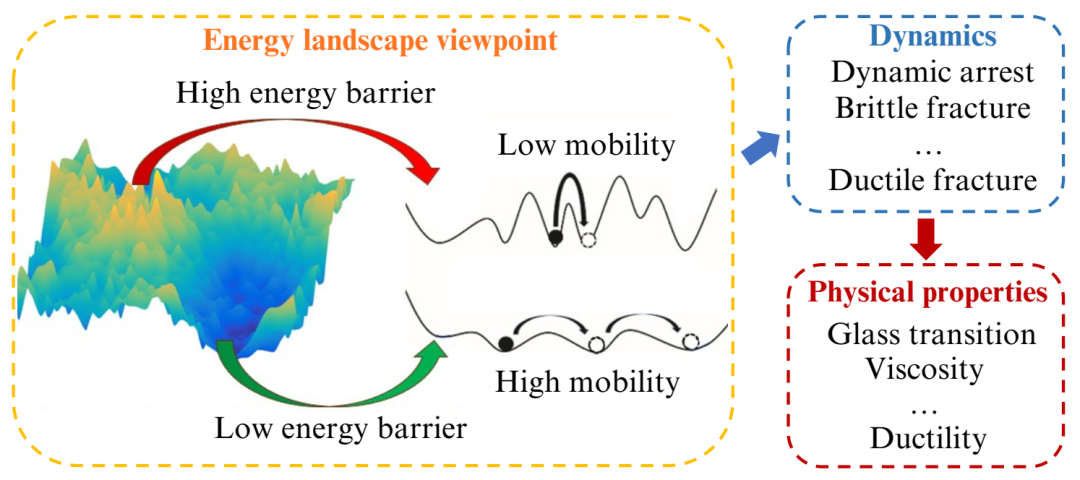 EBS,移动性和MG物理特性。EB表示移动性,可以进一步影响MG动力学及其物理特性。
EBS,移动性和MG物理特性。EB表示移动性,可以进一步影响MG动力学及其物理特性。
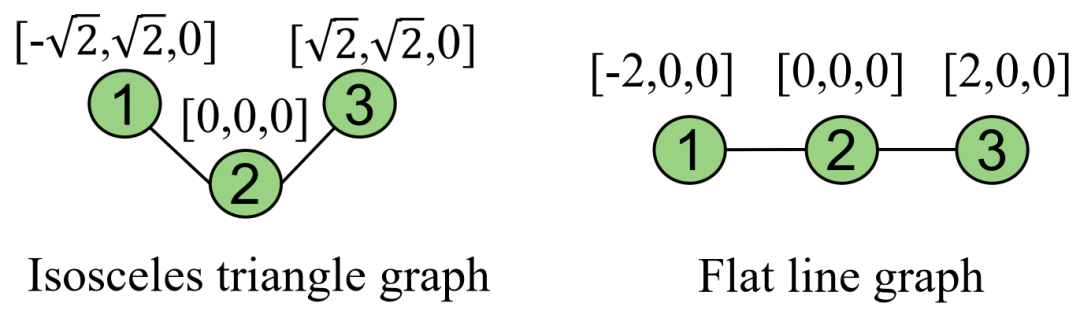
示例图证明了模型表现力。Schnet无法在这两个图中区分节点1的嵌入,但是Symgnn可以。
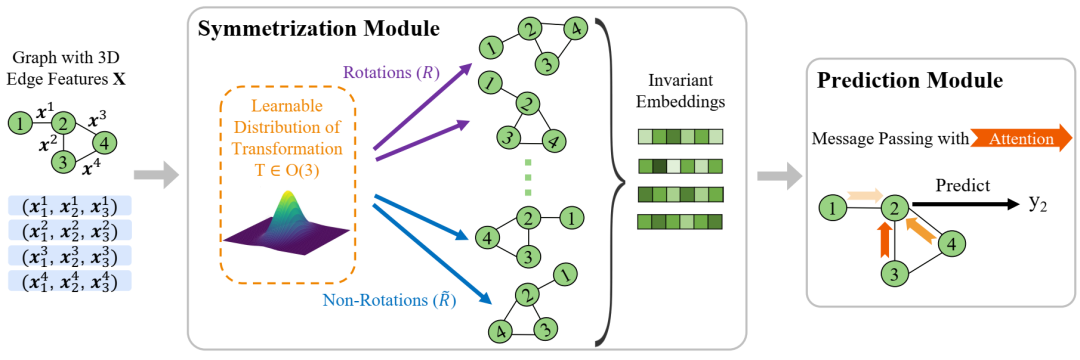 Symgnn框架的插图。给定带有节点特征的输入图是原子类型和边缘特征相对距离,在各种正交转换的图中编码结果的Symgnn聚集体的对称模块从可学习的分布采样以实现O(3)的预期。然后,不变的嵌入将传递给通信层,并注意汇总信息并预测标签。
Symgnn框架的插图。给定带有节点特征的输入图是原子类型和边缘特征相对距离,在各种正交转换的图中编码结果的Symgnn聚集体的对称模块从可学习的分布采样以实现O(3)的预期。然后,不变的嵌入将传递给通信层,并注意汇总信息并预测标签。
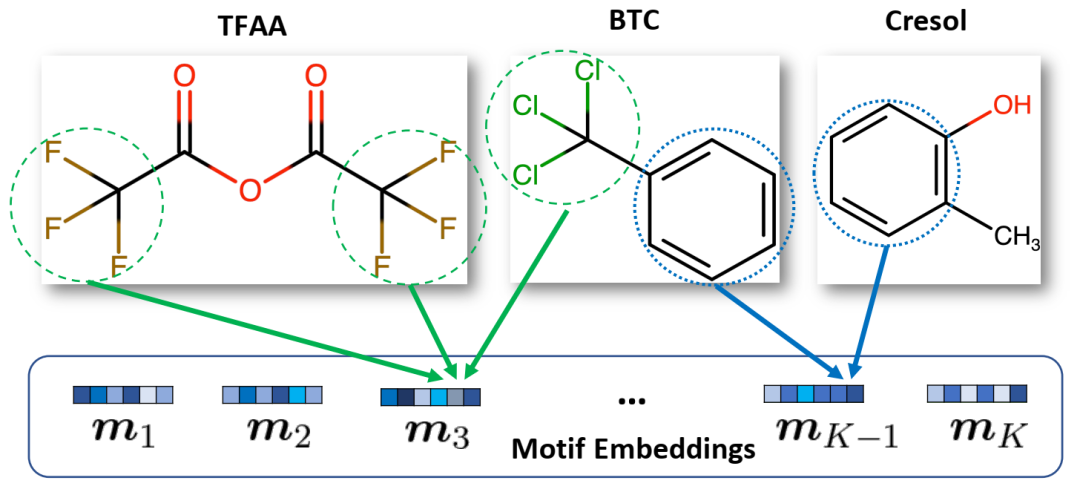
传统主题定义与我们的主题定义之间的区别。给定三种化合物,基于离散结构的传统定义只能以蓝色圆圈挖掘苯环。相反,我们使用连续嵌入向量的定义可以将苯环挖掘为一个基序,而语义上相似的-CF3和-CCL3作为另一个基序。
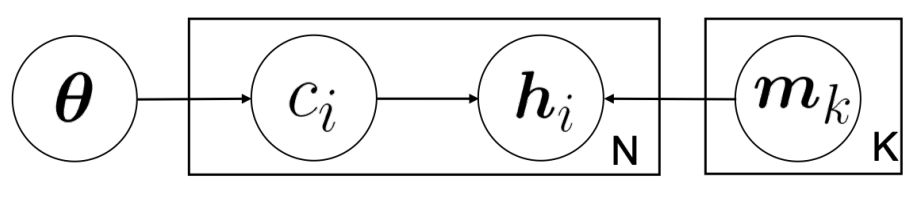
微图中图生成过程的概率图形模型。
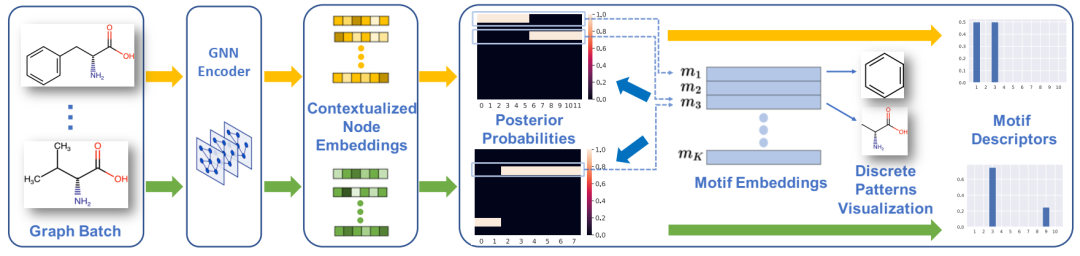 MICRO-Graph 框架。MICRO-Graph 推断主题描述符并通过两个示例化学图可视化挖掘的主题,分别遵循黄色和绿色流程。对于每个图,首先由 GNN 对其进行编码以获得节点嵌入 hi。然后计算后验概率(软分配)P(公式 5.4)。逐列平均 P 可得出主题描述符 z(公式 5.5)。同时,我们对节点进行分组,并通过将软分配转变为硬分配来可视化它们诱导的子图模式(公式 5.6 和 5.7)。
MICRO-Graph 框架。MICRO-Graph 推断主题描述符并通过两个示例化学图可视化挖掘的主题,分别遵循黄色和绿色流程。对于每个图,首先由 GNN 对其进行编码以获得节点嵌入 hi。然后计算后验概率(软分配)P(公式 5.4)。逐列平均 P 可得出主题描述符 z(公式 5.5)。同时,我们对节点进行分组,并通过将软分配转变为硬分配来可视化它们诱导的子图模式(公式 5.6 和 5.7)。
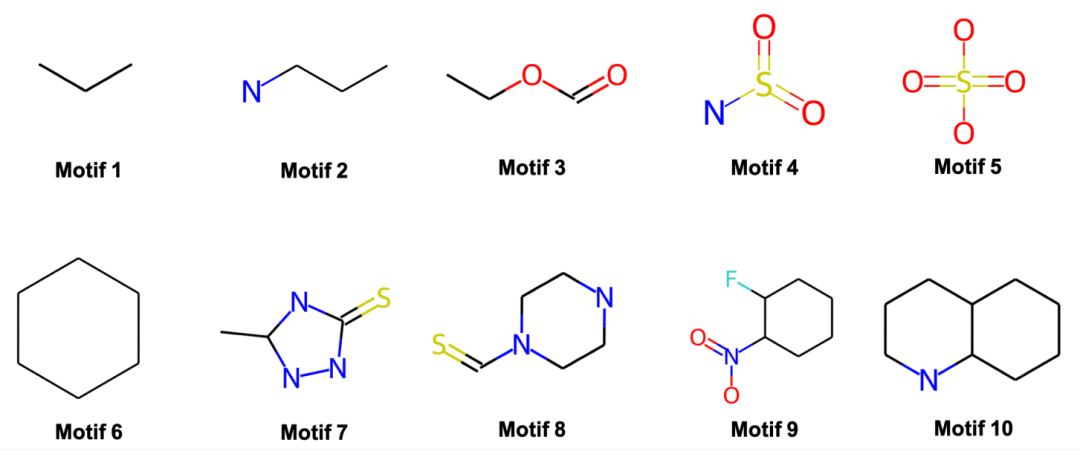 从 HIV 化合物数据集中挖掘出的常见基序。基序按大小递增顺序排列。挖掘出的基序与现实世界的功能组相匹配。
从 HIV 化合物数据集中挖掘出的常见基序。基序按大小递增顺序排列。挖掘出的基序与现实世界的功能组相匹配。
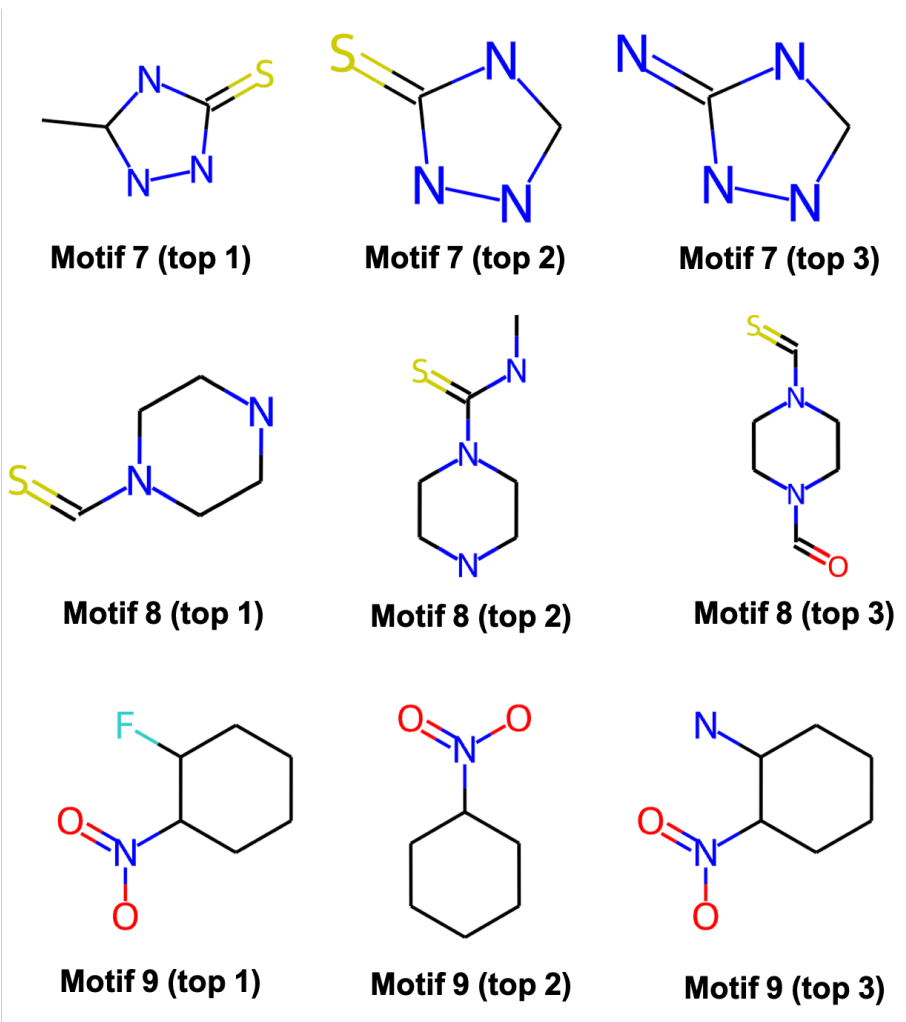
与基序对应的前 3 个最相似子图的可视化。图 5.4 中显示了基序 7、8 和 9 的示例。基序的嵌入定义允许小的结构变体,同时保持核心部分不变。
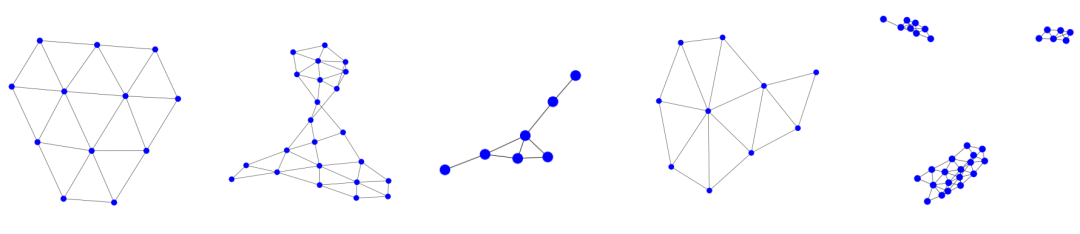 从 DD 蛋白质数据集中挖掘出的频繁基序。GStarX 学习到的五个频繁基序由它们最接近的子图表示。
从 DD 蛋白质数据集中挖掘出的频繁基序。GStarX 学习到的五个频繁基序由它们最接近的子图表示。
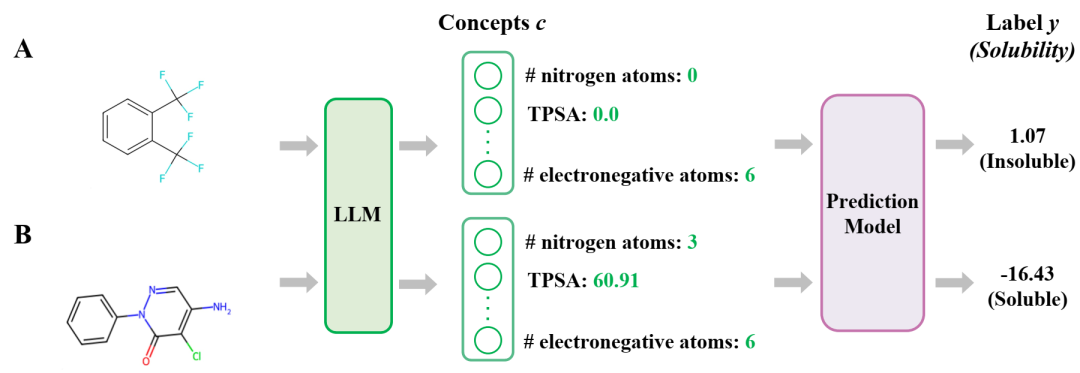 AutoMolCo 极大地阐明了分子特性的预测过程。首先,生成概念并用 LLM 标记。然后,可以拟合一个简单的预测模型(例如线性回归)来实现可解释的预测。LLM 相关部分以绿色突出显示,具体来说,绿色箭头表示提示。
AutoMolCo 极大地阐明了分子特性的预测过程。首先,生成概念并用 LLM 标记。然后,可以拟合一个简单的预测模型(例如线性回归)来实现可解释的预测。LLM 相关部分以绿色突出显示,具体来说,绿色箭头表示提示。
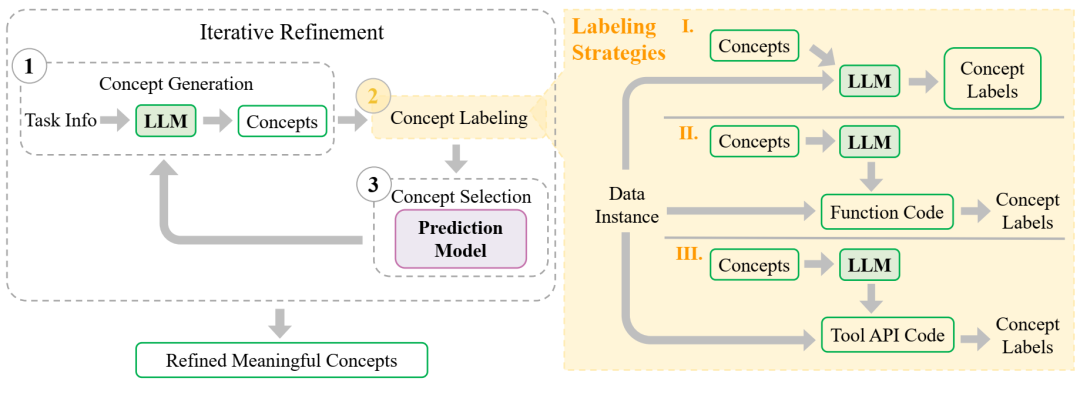 AutoMolCo 框架。步骤 1:概念生成。步骤 2:使用三种不同策略进行概念标记。步骤 3:拟合预测模型并执行概念选择。这三个步骤重复多次迭代以获得有意义的概念的细化列表,其中每次迭代中选择的概念都会通过提示反馈给 LLM。LLM 输出以绿色框突出显示。
AutoMolCo 框架。步骤 1:概念生成。步骤 2:使用三种不同策略进行概念标记。步骤 3:拟合预测模型并执行概念选择。这三个步骤重复多次迭代以获得有意义的概念的细化列表,其中每次迭代中选择的概念都会通过提示反馈给 LLM。LLM 输出以绿色框突出显示。
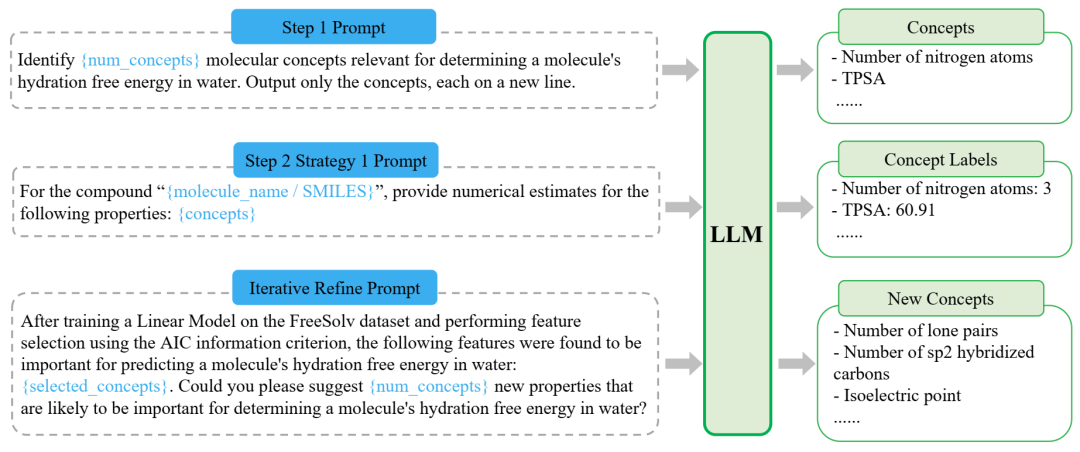 提示在 FreeSolv 上生成概念并进行标记。超参数、分子实例信息和上一步中重复使用的 LLM 响应以蓝色显示。
提示在 FreeSolv 上生成概念并进行标记。超参数、分子实例信息和上一步中重复使用的 LLM 响应以蓝色显示。
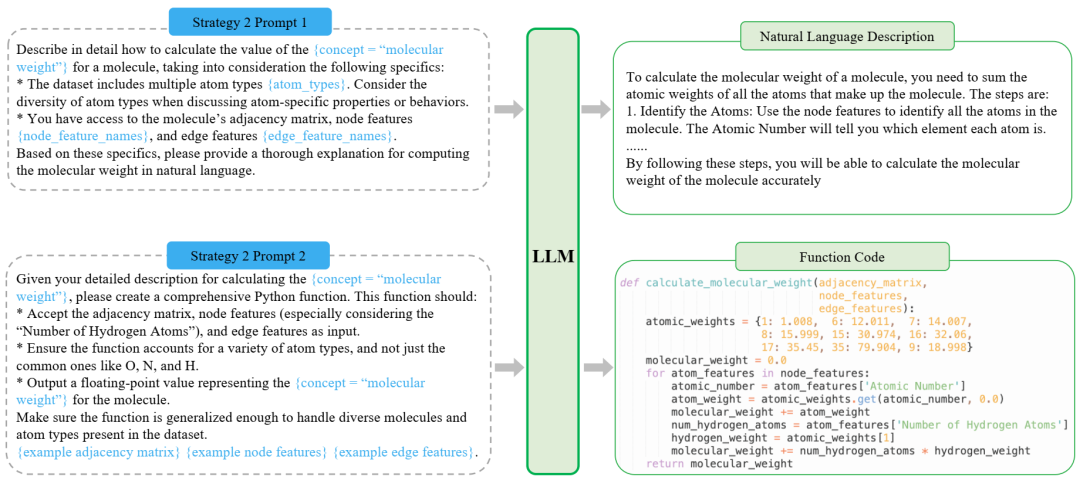 提示在 FreeSolv 上的 Python 代码中生成概念标记函数。
提示在 FreeSolv 上的 Python 代码中生成概念标记函数。
 提示调用外部工具 RDKit 来标记 FreeSolv 上的概念。
提示调用外部工具 RDKit 来标记 FreeSolv 上的概念。
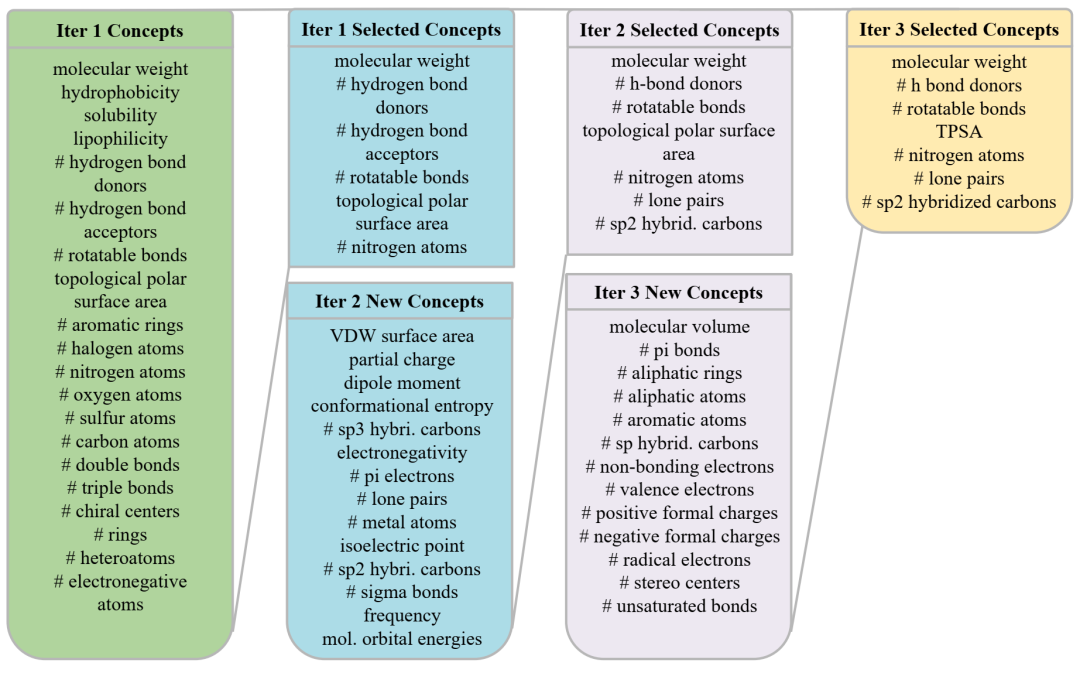 RQ1:AutoMolCo 在 FreeSolv 上的三次细化迭代中选择的概念。
RQ1:AutoMolCo 在 FreeSolv 上的三次细化迭代中选择的概念。
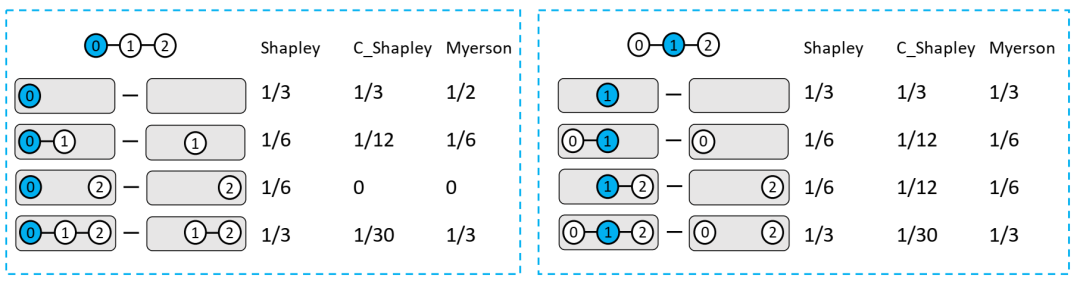 边际贡献系数比较。一个玩具 3 节点图示例,用于比较 Shapley、C-Shapley 和 Myerson 值之间的边际贡献系数。(a) 节点 0 的值计算(左)。(b) 节点 1 的值计算(右)。
边际贡献系数比较。一个玩具 3 节点图示例,用于比较 Shapley、C-Shapley 和 Myerson 值之间的边际贡献系数。(a) 节点 0 的值计算(左)。(b) 节点 1 的值计算(右)。
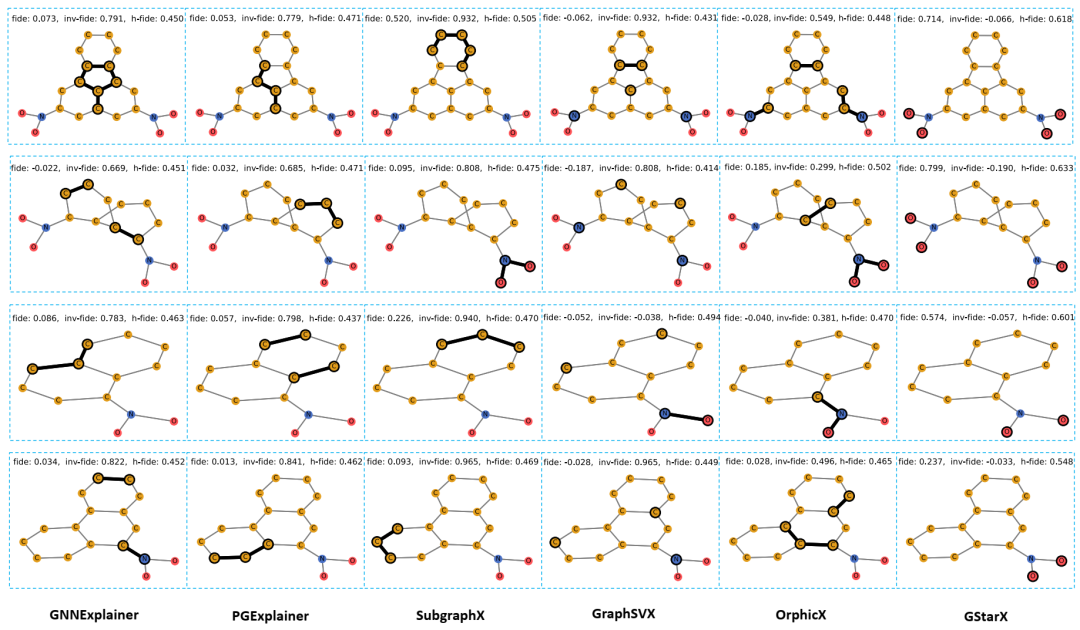 MUTAG 提供的更多有关诱变分子的解释。碳原子 (C) 为黄色,氮原子 (N) 为蓝色,氧原子 (O) 为红色。我们使用深色轮廓来表示所选子图解释,并报告每个解释的保真度 (fide)、反保真度 (inv-fide) 和 H-保真度 (h-fide)。GStarX 在这些指标方面比其他方法给出了更好的解释。
MUTAG 提供的更多有关诱变分子的解释。碳原子 (C) 为黄色,氮原子 (N) 为蓝色,氧原子 (O) 为红色。我们使用深色轮廓来表示所选子图解释,并报告每个解释的保真度 (fide)、反保真度 (inv-fide) 和 H-保真度 (h-fide)。GStarX 在这些指标方面比其他方法给出了更好的解释。
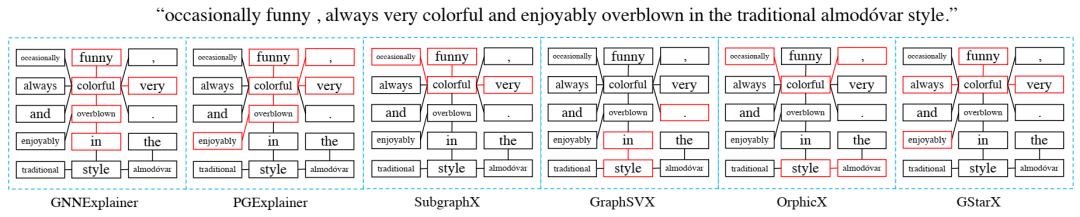 GraphSST2 中句子的更多解释。该句子被预测为积极情绪。红色轮廓表示所选节点/边作为解释。与基线相比,GStarX 可以更准确地识别情绪词。
GraphSST2 中句子的更多解释。该句子被预测为积极情绪。红色轮廓表示所选节点/边作为解释。与基线相比,GStarX 可以更准确地识别情绪词。
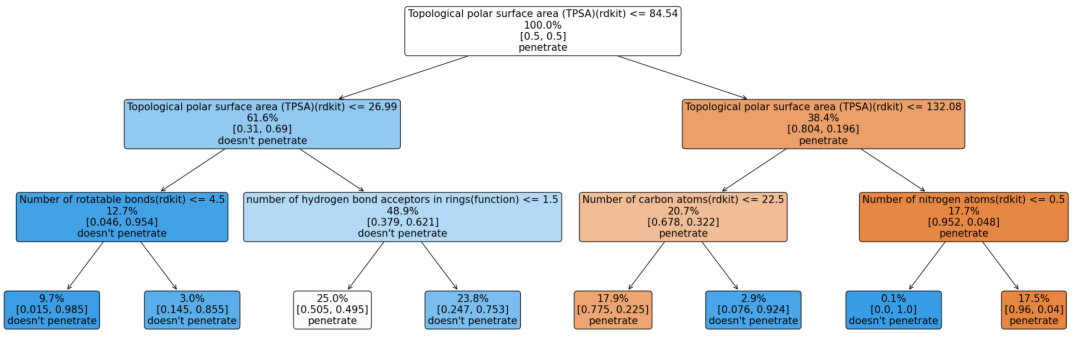 AutoMolCo 在 BBBP 上诱导的 CM 分类的决策树。
AutoMolCo 在 BBBP 上诱导的 CM 分类的决策树。









内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢