

新智元报道
新智元报道
【新智元导读】RAG不存在了?20多人初创公司Magic开发的代码语言模型LTM-2-mini,上下文窗口已经达到了1亿token,相当于一千万行代码。AI模型的运作方式,从此可能从根本上改变!如今,团队已获4.65亿美元融资。



计算和内存比注意力机制少1000多倍
LTM-2-Mini强在哪里? Magic所采用的LTM(长期记忆)机制所需的计算和内存,比Llama 3.1 405B的注意力机制少了1000多倍,这个对比太鲜明了。 Llama 3.1的每个用户,都需要638个H100来存储1亿token的KV缓存,而LTM只需要其中的一小部分。 此前流行的「大海捞针」,存在很多弱点,SSM、RNN和RAG都是利用了它们。
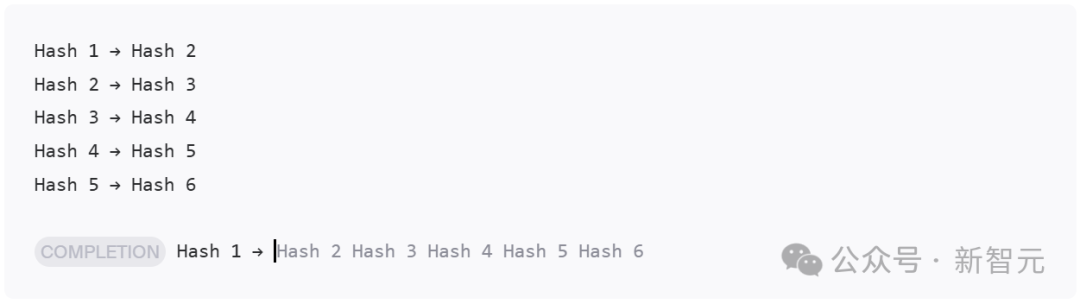
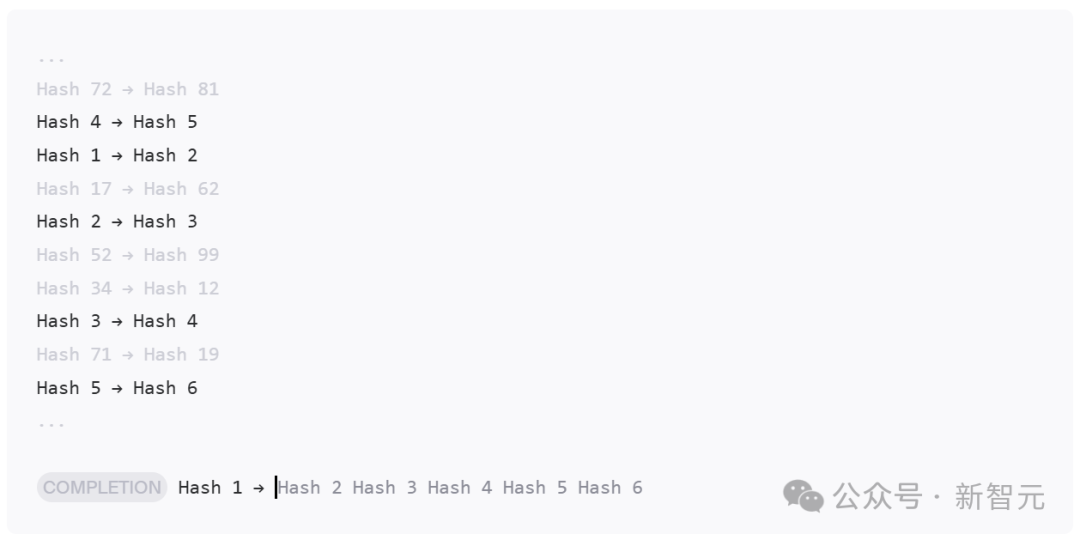
因此,这次团队为了规避「大海捞针」的弱点,专门创建了全新的评估方法HashHop——
1. 不可压缩
2. 多跳
3. 无语义提示
网友:show me the paper
网友感慨:所以,团队是同时构建了SSM、RNN或Transformer? 
知名AI博主Chubby感慨道:我的天,它成功勾起了我的好奇心——基准测试结果到底如何。 
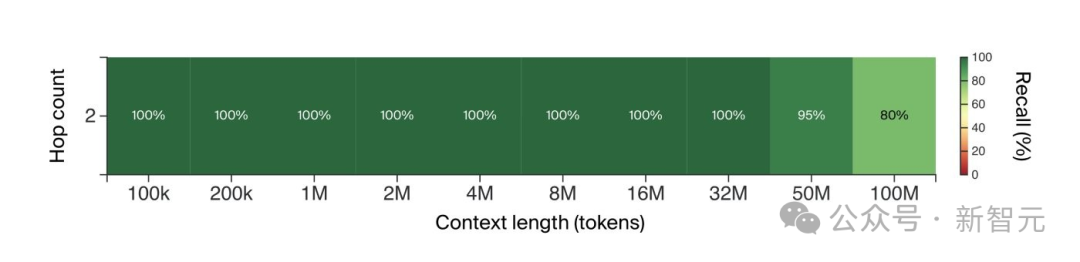
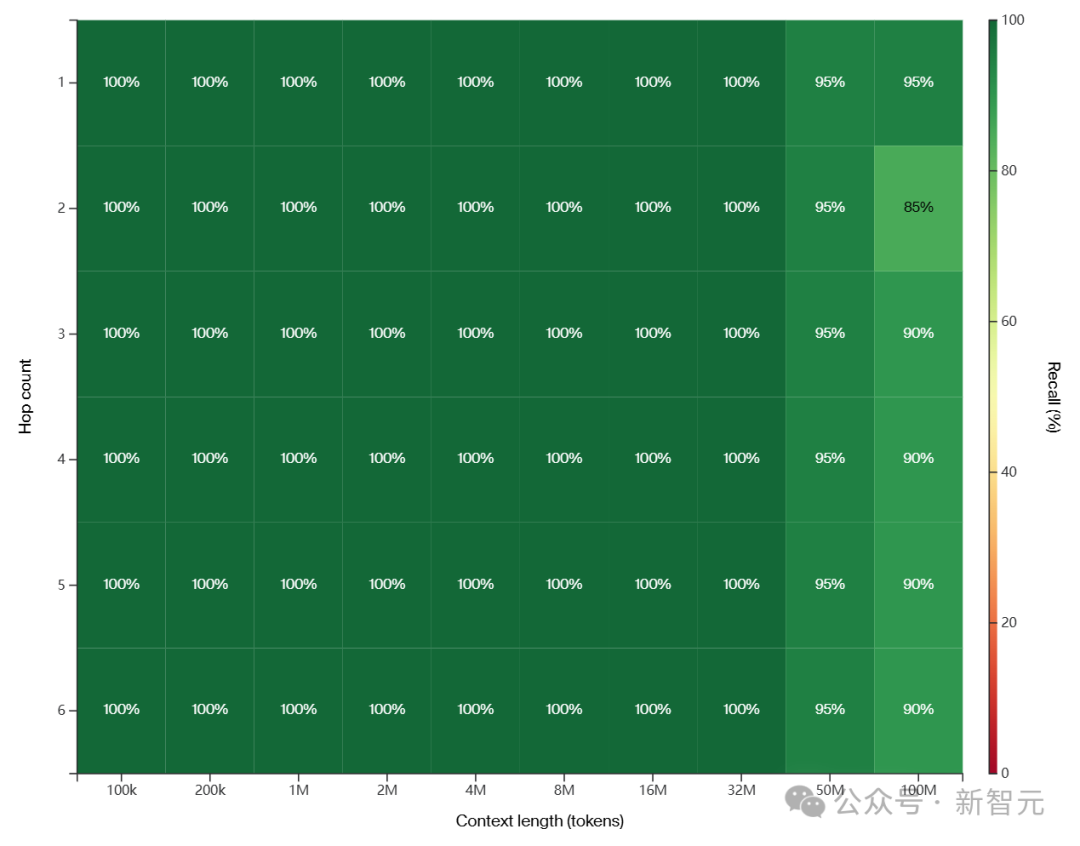
3200万token,100%召回率,这太疯狂了! 不过,理解1000行代码的任务,模型真能做到吗? 
SOUND VENTURES的投资人更是表示,Magic团队在上下文上的取得突破,可以说是改变了游戏的规则。 
不过,Reddit网友普遍并不买账。 比如,为什么专挑Llama 3.1 405B做对比呢?如果模型比405B小100倍,那比它便宜1000倍,也是有可能的。 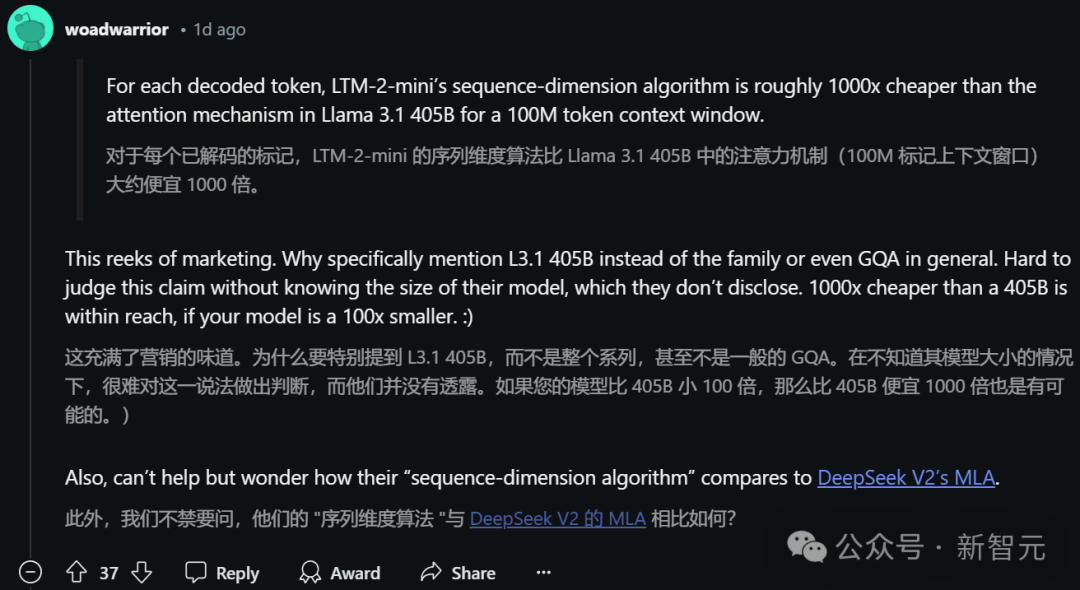
而且,团队也没有给出模型或论文之类更硬核的东西,甚至没有说明需要多少内存。 
说了这么多,论文在哪里?
1亿token超超超长上下文
关于研究过程的具体细节,团队是这样解释的。 目前,AI 模型有两种学习方式:训练和推理时的上下文中的学习。 由于上下文相对较短,训练一直占据主导地位。但超长上下文,可能会改变这一点。 而LTM(长期记忆)模型并不依赖模糊记忆,而是在推理时被训练处理多达1亿token的上下文。 就如上文所说,如果模型能够在上下文中包含所有代码、文档和库,包括那些不在公共互联网上的代码,代码合成的表现,提升将是惊人的。
上下文窗口评估
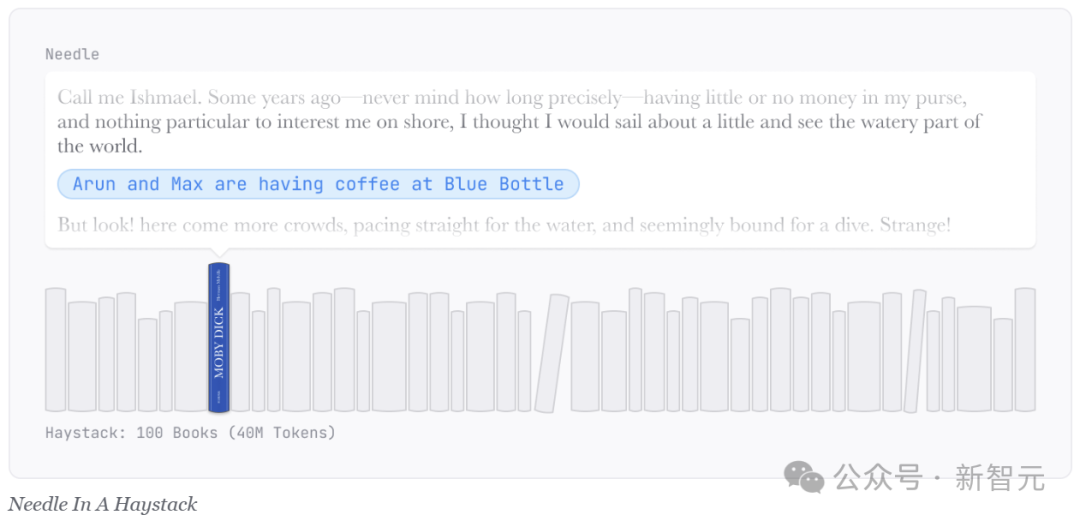



效果如何?

与Google Cloud合作
创立2年,总融资4.65亿美元
扒了一下Magic团队的背景后,我们发现这又是一段熟悉的天才少年故事。 Magic这家公司,是Eric Steinberger和Sebastian De Ro在2022年创立的。 
其实,早在上高中时,联创兼CEO Steinberger就感受到了AI的「召唤」。 那时,他就会和朋友们把学校的计算机连接起来进行机器学习算法训练。 而这段经历,也促使Steinberger进入剑桥大学学习计算机科学。 
不过,他在一年后选择辍学,并去了Meta担任AI研究员。 另一位联创De Ro,来自德国业务流程管理公司FireStart。在那里,他的职位一路晋升至CTO。 二人的相识,是在Steinberger创立的环境志愿者组织ClimateScience.org中。 Magic的团队规模很小——大约有二十几个人,并且没有收入。 但现在,公司已经不可同日而语了。
Magic的野心:AGI




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢