

从低层次的感知输入开始,人类可以自动推断出视觉世界中更高层次的语义上有意义的结构。在本论文中,我介绍了我在提取和利用这种层次结构进行视觉内容创建和编辑的系统上的工作。首先,我将介绍运动程序,这是一种用于人体动作的分层运动表示,它捕获了低级运动及其作为运动概念的高级描述。这种表示可以在单一框架内实现人体运动描述、交互式编辑和新视频序列的可控合成。接下来,我将介绍 ProGRIP,这是一种新颖的形状程序表示,它使用隐式函数来表示零件。ProGRIP 在形状重建保真度和语义分割方面优于现有的结构化表示,并支持交互式编辑。最后,我将提出了一个将人物真实地插入场景的模型。我们的模型可以根据场景上下文推断出一组真实的姿势,重新调整参考人物的姿势,并协调构图。我们训练了一个大规模扩散模型来执行此任务。在推理时,我们的模型还可以被不同地提示来执行几种不同的辅助任务,例如人物幻觉、场景幻觉和衣服交换。定量和定性评估表明,与以前的工作相比,我们的方法更能合成真实的人的外观和更自然的人-场景交互。

论文题目:Visual Content Creation and Editing via Structural and Functional Hierarchies
作者:Sumith Kulal
类型:2023年博士论文
学校:University of California, Los Angeles(美国加州大学洛杉矶分校))
下载链接:
链接: https://pan.baidu.com/s/1Eq8lN23-0ZRC_zt8lQZTFQ?pwd=nyc8
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5

需要对各种操作操作符(例如运动编辑、对象和场景编辑以及在已编辑场景或新场景中重新渲染)进行分层理解的示例视频序列。原始视频来源:https://youtu.be/NwOhMsPY_5U、https://youtu.be/H45SADZKshw 和https://youtu.be/wAYurJYRtNE。
 运动程序支持在多个粒度级别上编辑运动和视频:低级编辑(例如减速下降)和高级编辑(例如添加和删除动作)。
运动程序支持在多个粒度级别上编辑运动和视频:低级编辑(例如减速下降)和高级编辑(例如添加和删除动作)。
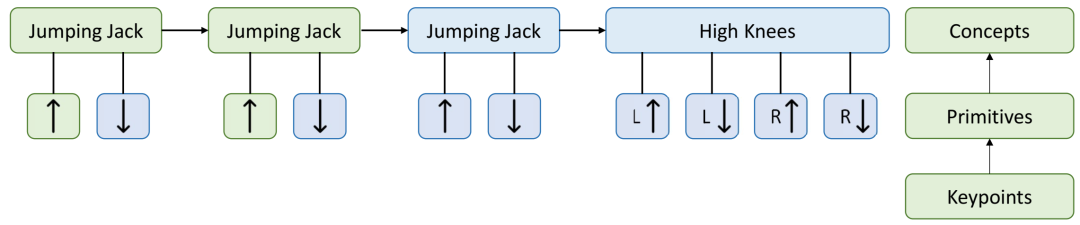 从低级关键点开始,运动程序首先将视频表示为一系列运动原语。然后,它学习将原语分组为具有语义意义的概念。
从低级关键点开始,运动程序首先将视频表示为一系列运动原语。然后,它学习将原语分组为具有语义意义的概念。
 ProGRIP 支持的示例编辑操作。给定两个以网格或点云表示的输入 3D 飞机,ProGRIP 只需单击两次鼠标即可交换“机翼”。
ProGRIP 支持的示例编辑操作。给定两个以网格或点云表示的输入 3D 飞机,ProGRIP 只需单击两次鼠标即可交换“机翼”。
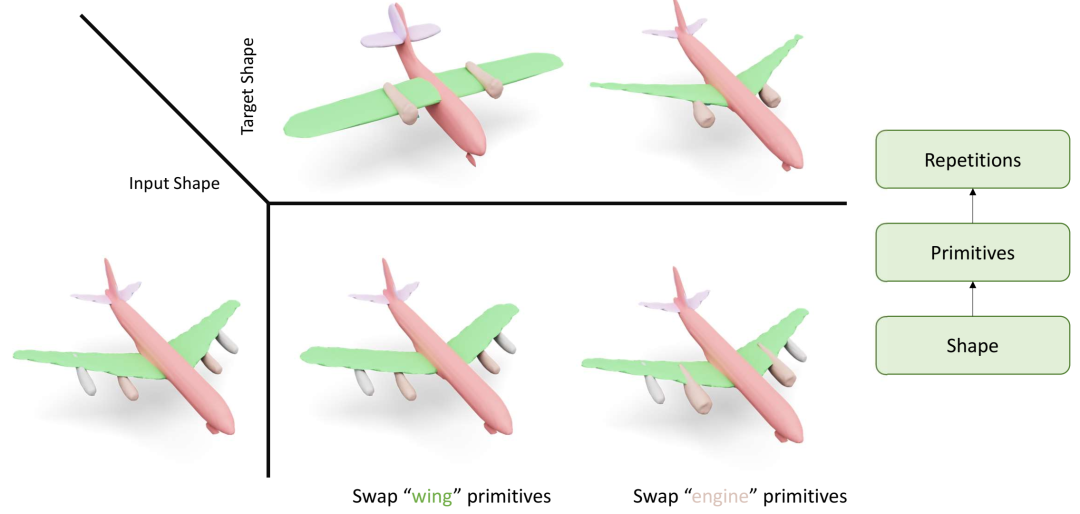 从以点云或网格表示的原始 3D 形状开始,ProGRIP 可以推断出诸如“机翼”和“发动机”等原始部件。此外,它还可以识别这些原始部件的重复。
从以点云或网格表示的原始 3D 形状开始,ProGRIP 可以推断出诸如“机翼”和“发动机”等原始部件。此外,它还可以识别这些原始部件的重复。

给定一个人的图像和带有标记区域的场景图像,我们的模型可以真实地将人类插入场景中。这包括能够识别合理的姿势、重新摆出人类的姿势并协调插入。
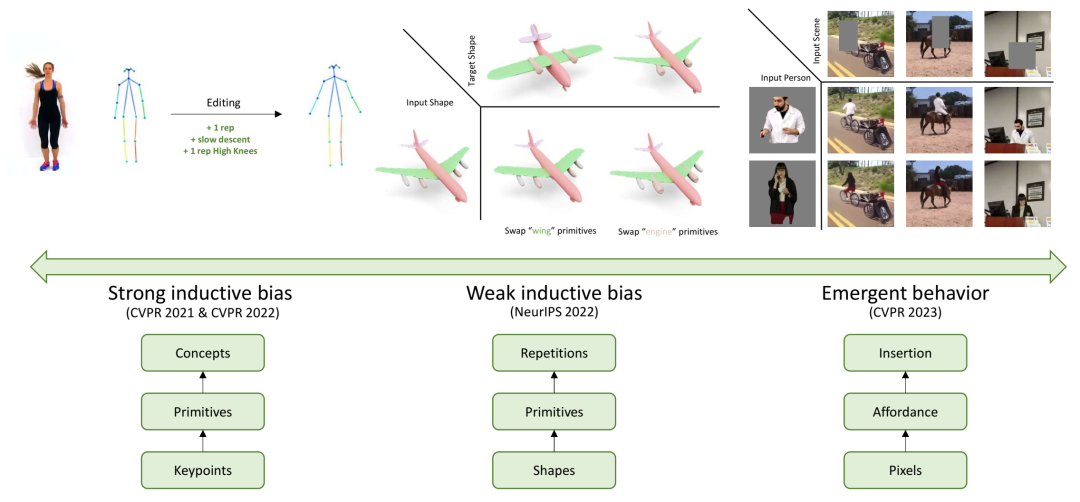
这些合成和编辑应用中的每一个都需要我们有一个层次化的理解。对于运动和形状,它是结构层次。对于人类插入,它是场景中可供性的功能层次。
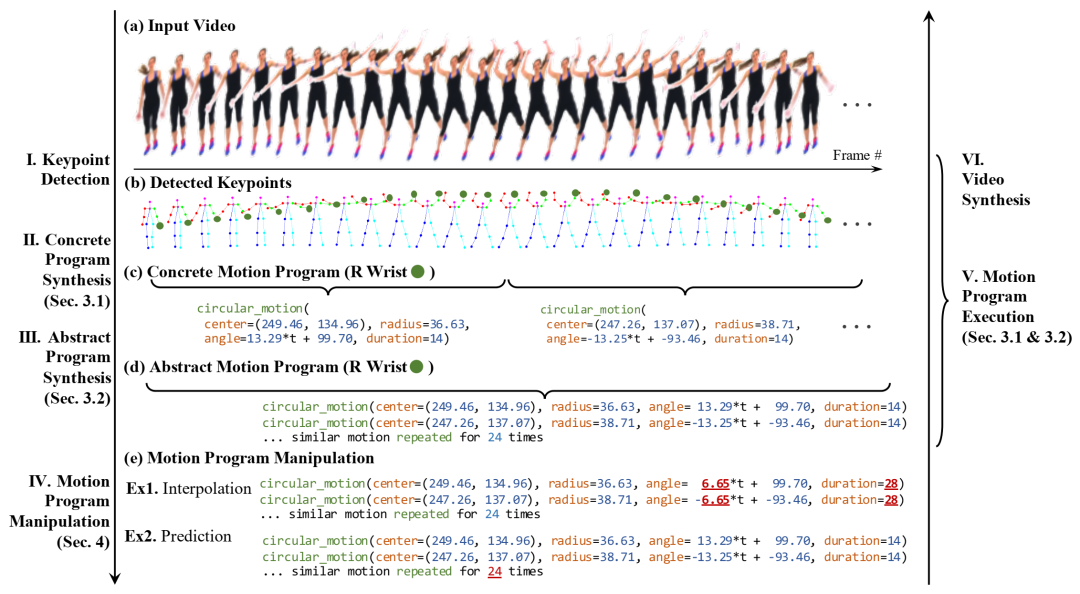 我们的分层运动理解框架概述。我们从原始视频中提取的低级关键点开始,并构建更高级别的运动理解。更高级别的抽象由一系列运动基元及其重复模式组成。使用概率 for 循环体捕获重复模式中的类似运动。
我们的分层运动理解框架概述。我们从原始视频中提取的低级关键点开始,并构建更高级别的运动理解。更高级别的抽象由一系列运动基元及其重复模式组成。使用概率 for 循环体捕获重复模式中的类似运动。
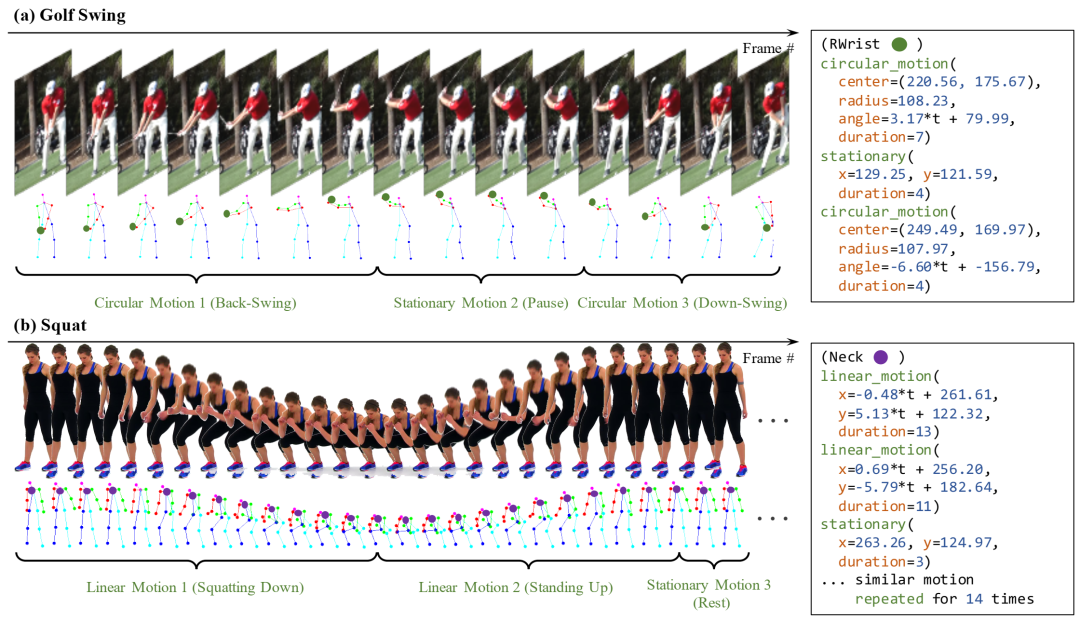
合成动作基元的示例。a) 此高尔夫挥杆动作有三个基元:后挥杆、暂停和下挥杆。b) 深蹲序列有三个类似基元的重复子序列:下蹲、站起和站立姿势的短暂休息。
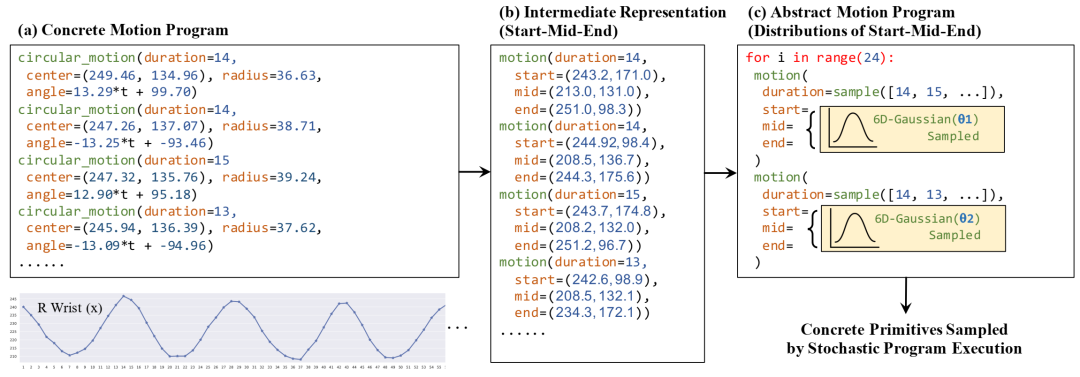 将 6 个重复(交替)语句汇总到主体大小为 2 的 for 循环中的图示。我们首先将具体基元转换为确定性抽象基元,然后在主体中合成具有概率基元的 for 循环。在执行过程中,从概率抽象基元中抽取具体基元。
将 6 个重复(交替)语句汇总到主体大小为 2 的 for 循环中的图示。我们首先将具体基元转换为确定性抽象基元,然后在主体中合成具有概率基元的 for 循环。在执行过程中,从概率抽象基元中抽取具体基元。
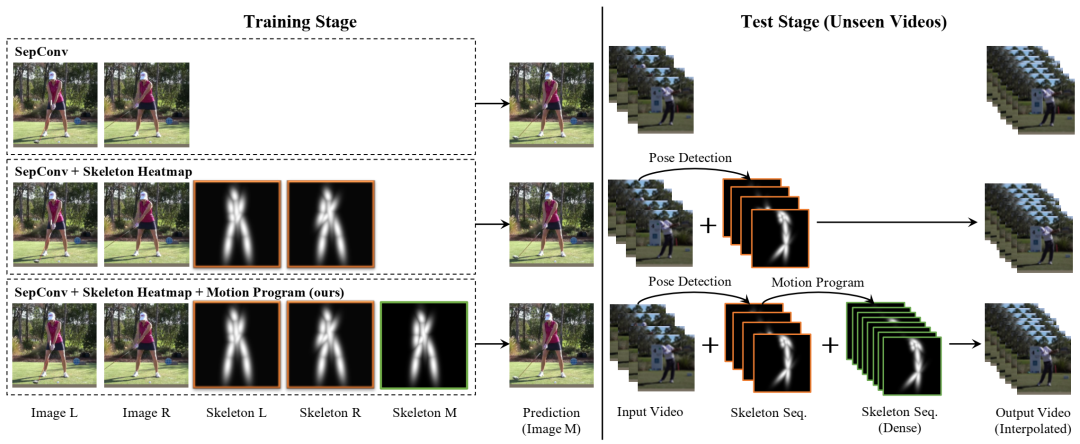 评估三种视频插值变体:顶行(SepConv)、中间行(带热图的 SepConv)和底行(带程序的 SepConv),这是我们的模型,其中中间帧的姿势由运动程序提供。中间行(带热图的 SepConv)作为消融研究进行评估。
评估三种视频插值变体:顶行(SepConv)、中间行(带热图的 SepConv)和底行(带程序的 SepConv),这是我们的模型,其中中间帧的姿势由运动程序提供。中间行(带热图的 SepConv)作为消融研究进行评估。
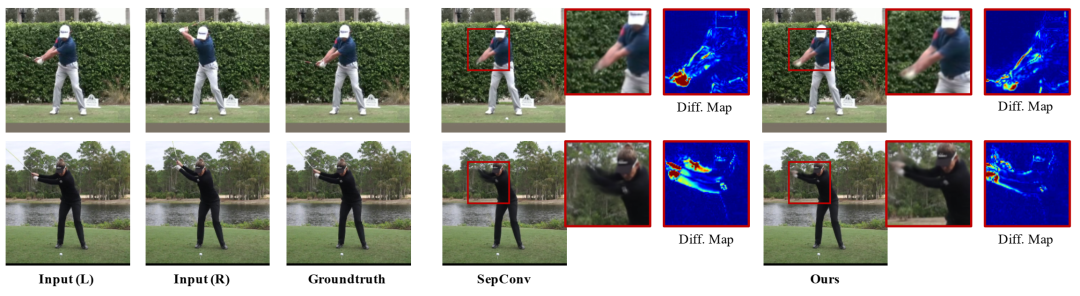 8 倍视频插值的定性结果。我们观察到,使用程序信息可获得更高的图像质量。
8 倍视频插值的定性结果。我们观察到,使用程序信息可获得更高的图像质量。
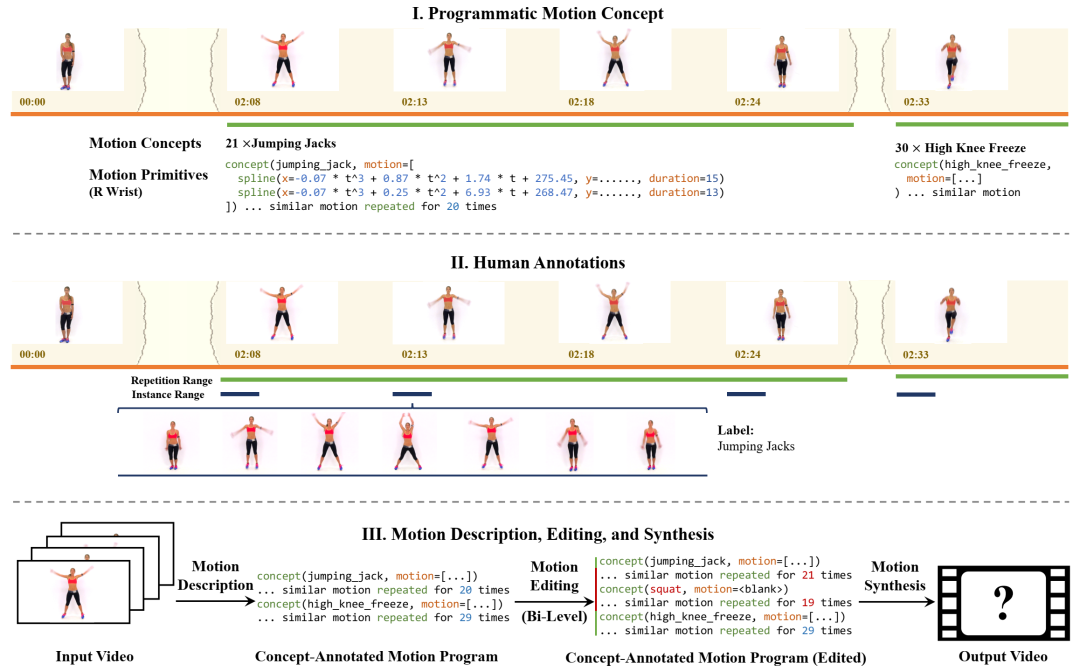
(I)我们提出了一个分层的人体运动描述框架。每个视频都表示为一系列运动概念,每个运动概念进一步被定义为一系列运动基元。(II)运动概念可以从非常少量的人工注释中学习:人工注释者标记运动概念的重复范围和该重复组中的三个实例范围。(III)运动概念支持交互式编辑和视频合成。人工编辑可以在概念级别或基元级别灵活地编辑人体运动视频。我们使用神经生成模型来渲染输出视频。
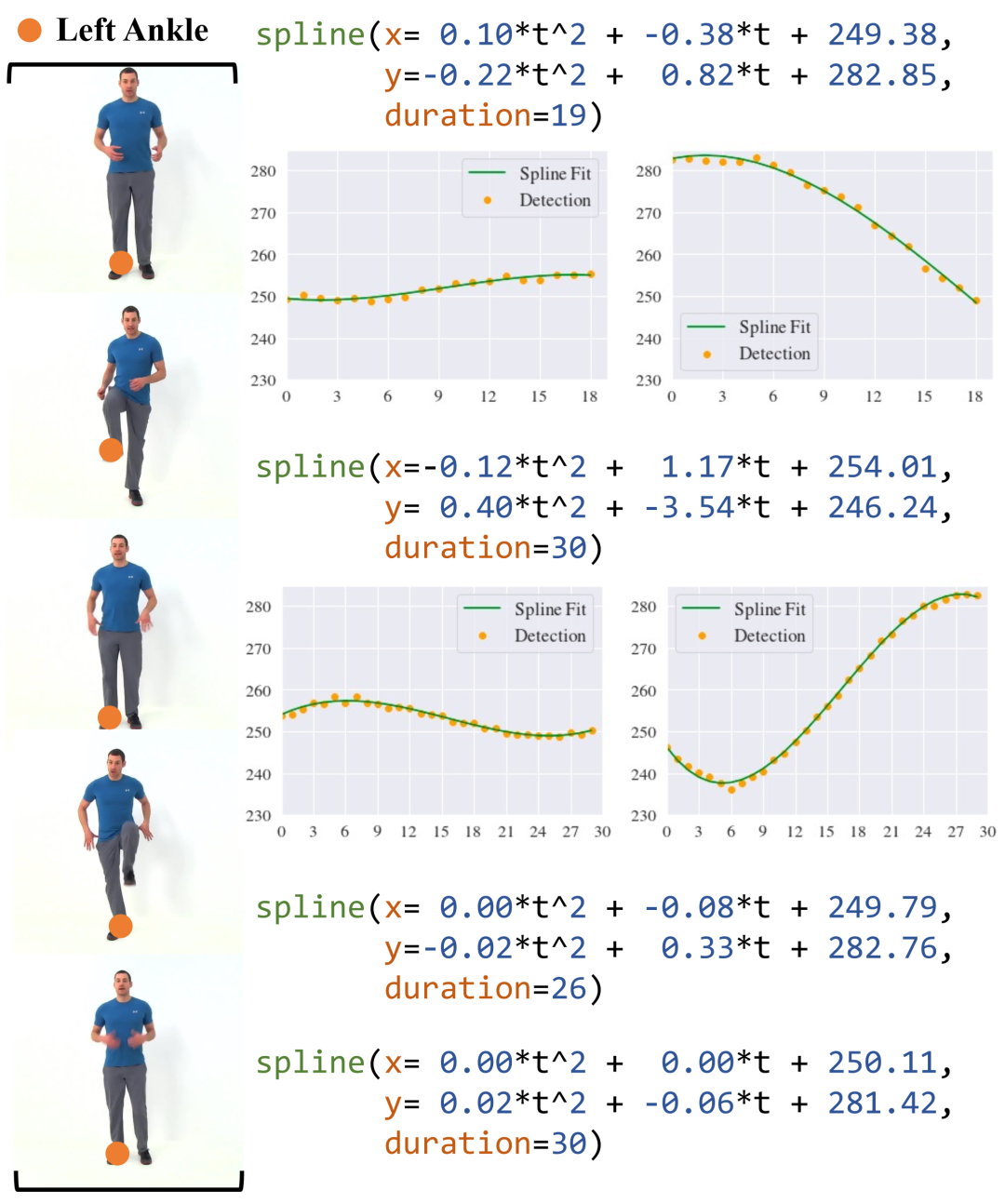 High Knees 片段中检测到的四个运动基元。四个基元中的三阶系数都很小(绝对值小于 0.01),因此我们在可视化中省略了它们。
High Knees 片段中检测到的四个运动基元。四个基元中的三阶系数都很小(绝对值小于 0.01),因此我们在可视化中省略了它们。
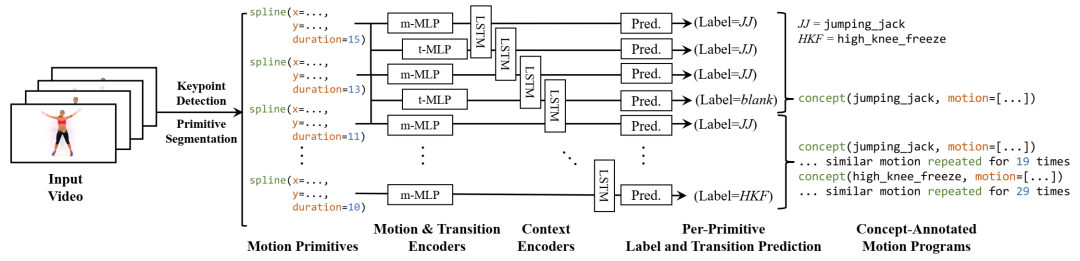 生成运动描述的模型。给定输入视频,我们首先生成运动原语,并将原语输入到包含前馈层和循环层的简单神经架构中,以计算每个原语的概念标签预测。我们使用联结主义时间分类风格 (CTC) 目标来提取最可能的运动描述。
生成运动描述的模型。给定输入视频,我们首先生成运动原语,并将原语输入到包含前馈层和循环层的简单神经架构中,以计算每个原语的概念标签预测。我们使用联结主义时间分类风格 (CTC) 目标来提取最可能的运动描述。
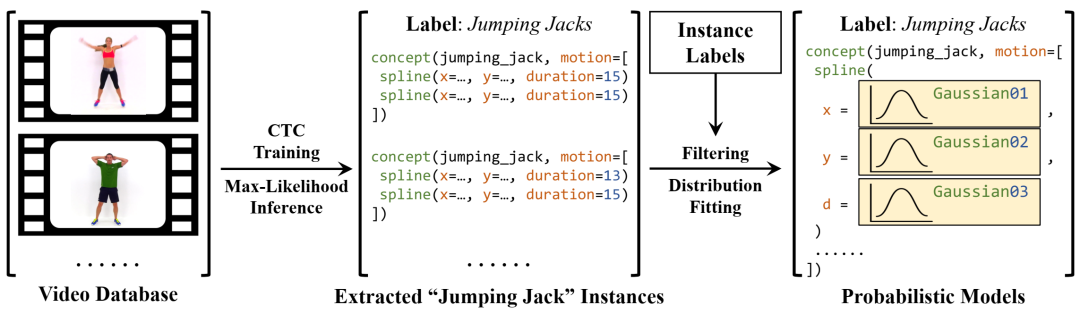 学习运动概念的生成模型。我们利用学习到的对齐来提取每个动作类的所有单次重复示例。通过以一些真实重复作为参考,我们对它们进行过滤以解决歧义,然后学习原始分布作为我们的概念表示。
学习运动概念的生成模型。我们利用学习到的对齐来提取每个动作类的所有单次重复示例。通过以一些真实重复作为参考,我们对它们进行过滤以解决歧义,然后学习原始分布作为我们的概念表示。
 在视频中可视化局部“躯干扭转”概念。不同的颜色代表模型定位的不同部分。即使它们都预测了“躯干扭转”的正确重复次数,使用我们基于原始表示和 LP + LT 的模型也会找到与地面真相最大程度一致的部分。
在视频中可视化局部“躯干扭转”概念。不同的颜色代表模型定位的不同部分。即使它们都预测了“躯干扭转”的正确重复次数,使用我们基于原始表示和 LP + LT 的模型也会找到与地面真相最大程度一致的部分。
 我们的方法将对象表示为具有可重复隐式部分的形状程序 (ProGRIP)。该程序有两个级别:顶层定义一组可重复部分(作为潜在向量 zi),底层定义每个部分的所有出现情况,这些部分具有不同的姿势。联合预测,即姿势部分,作为姿势隐式函数执行。ProGRIP 的生成和执行与两个级别的预测顺序无关。使用我们提出的基于匹配的无监督训练目标,无需任何注释即可学习 ProGRIP。
我们的方法将对象表示为具有可重复隐式部分的形状程序 (ProGRIP)。该程序有两个级别:顶层定义一组可重复部分(作为潜在向量 zi),底层定义每个部分的所有出现情况,这些部分具有不同的姿势。联合预测,即姿势部分,作为姿势隐式函数执行。ProGRIP 的生成和执行与两个级别的预测顺序无关。使用我们提出的基于匹配的无监督训练目标,无需任何注释即可学习 ProGRIP。
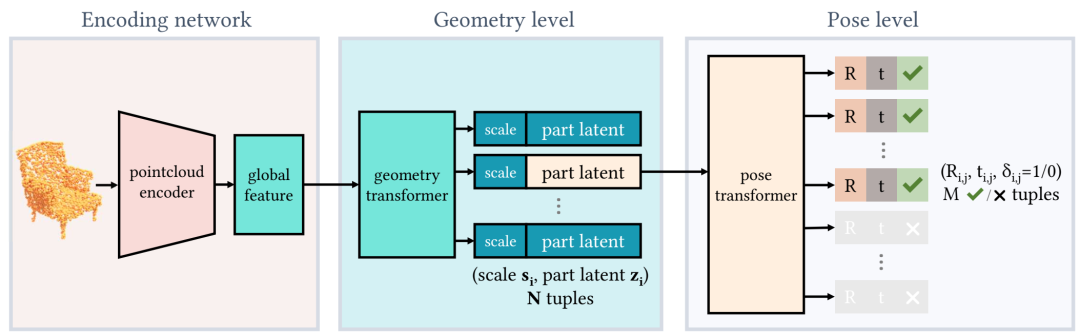 ProGRIP 生成。给定一个点云,自动编码架构会生成一个由 2 个预测级别组成的 ProGRIP。在几何级别,我们的模型将一组 (si, zi) 对预测为可重复部分的尺度和深度潜伏(中间);在姿势级别,我们的模型将一组 (ti,j, Ri,j, δi,j) 三元组预测为平移、旋转和存在概率(右)。Transformer 在两个级别上都用于置换不变预测。
ProGRIP 生成。给定一个点云,自动编码架构会生成一个由 2 个预测级别组成的 ProGRIP。在几何级别,我们的模型将一组 (si, zi) 对预测为可重复部分的尺度和深度潜伏(中间);在姿势级别,我们的模型将一组 (ti,j, Ri,j, δi,j) 三元组预测为平移、旋转和存在概率(右)。Transformer 在两个级别上都用于置换不变预测。
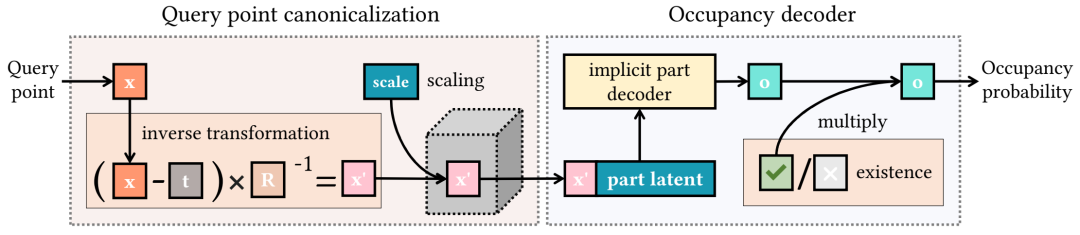 提出的隐式函数。我们将每个提出的部分(即 (si, zi, ti,j, Ri,j, δi,j) 元组)作为提出的隐式函数执行。提出的隐式函数构造一个占用函数 oi,j 来回答点查询 x。对于每个查询点 x,我们首先使用 (si, ti,j, Ri,j) 对其进行规范化,然后根据部分潜在 zi 预测其占用率,最后通过二值化存在性 δˆi,j 对其进行掩盖。
提出的隐式函数。我们将每个提出的部分(即 (si, zi, ti,j, Ri,j, δi,j) 元组)作为提出的隐式函数执行。提出的隐式函数构造一个占用函数 oi,j 来回答点查询 x。对于每个查询点 x,我们首先使用 (si, ti,j, Ri,j) 对其进行规范化,然后根据部分潜在 zi 预测其占用率,最后通过二值化存在性 δˆi,j 对其进行掩盖。
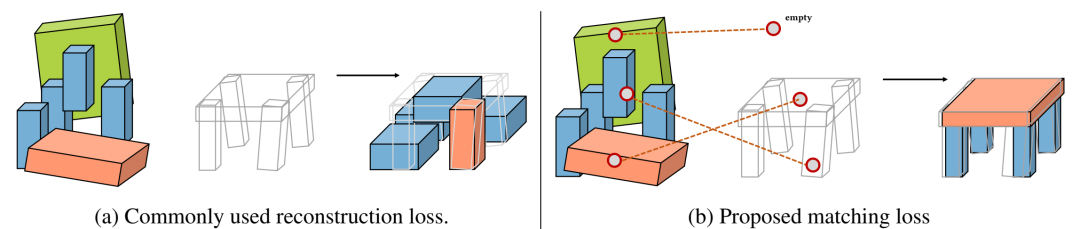
无监督匹配损失的演示。在将可重复部件拟合到目标形状的任务中,从相同的初始化开始,重构损失(左)将每个摆姿势的部件限制在其初始局部邻域中,从而阻止更好的部件排列。相反,我们的匹配损失(右)将摆姿势的部件按形状与目标的局部几何形状相匹配,从而将部件排列从重构损失中的次优局部最小值中拯救出来。
 我们通过渲染重建结果,对 ProGRIP 与最先进的形状分解方法(包括 Shape2Prog、CubeSeg和 BSP-Net)进行了定性比较。对于 ProGRIP,我们展示了普通重建(倒数第二行)以及每个部分的彩色渲染(最后一行)。第一行显示了地面真实网格。ProGRIP 可以更准确、更流畅地重建形状。请注意,椅背上的圆柱形部分(列 1 和列 2)被重建为与 4 条椅子腿相同形状的不同副本,因为它们具有几何相似性。同时,由于 ShapeNet 中的桌腿不对称(列 4),我们的方法可以独立发现左右腿的对称性(列 5)。
我们通过渲染重建结果,对 ProGRIP 与最先进的形状分解方法(包括 Shape2Prog、CubeSeg和 BSP-Net)进行了定性比较。对于 ProGRIP,我们展示了普通重建(倒数第二行)以及每个部分的彩色渲染(最后一行)。第一行显示了地面真实网格。ProGRIP 可以更准确、更流畅地重建形状。请注意,椅背上的圆柱形部分(列 1 和列 2)被重建为与 4 条椅子腿相同形状的不同副本,因为它们具有几何相似性。同时,由于 ShapeNet 中的桌腿不对称(列 4),我们的方法可以独立发现左右腿的对称性(列 5)。
 我们可视化了 ProGRIP 产生的无监督部件分割结果,该结果可以很好地适用于不同的对象类别。此外,ProGRIP 还能够分割细粒度的部件,例如飞机的发动机和尾部。
我们可视化了 ProGRIP 产生的无监督部件分割结果,该结果可以很好地适用于不同的对象类别。此外,ProGRIP 还能够分割细粒度的部件,例如飞机的发动机和尾部。
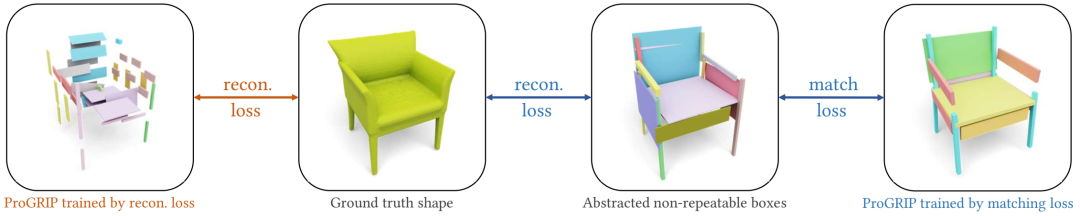 我们的匹配损失 Lm 与CubeSeg中的重建损失。我们使用我们的匹配损失 Lm(底部)或CubeSeg中的重建损失(顶部)来训练 ProGRIP,并在一个测试示例上可视化它们的结果。请注意,匹配损失使用抽象的不可重复框,这些框是通过重建地面真实形状(垂直箭头)无监督学习的。因此,两种损失都是完全无监督的。然而,我们明显观察到,右下角由 Lm 训练的 ProGRIP 的重建质量和更合理的部件排列比右上角由重建损失训练的更好。
我们的匹配损失 Lm 与CubeSeg中的重建损失。我们使用我们的匹配损失 Lm(底部)或CubeSeg中的重建损失(顶部)来训练 ProGRIP,并在一个测试示例上可视化它们的结果。请注意,匹配损失使用抽象的不可重复框,这些框是通过重建地面真实形状(垂直箭头)无监督学习的。因此,两种损失都是完全无监督的。然而,我们明显观察到,右下角由 Lm 训练的 ProGRIP 的重建质量和更合理的部件排列比右上角由重建损失训练的更好。
 给定一个蒙版场景图像(第一行)和一个参考人物(第一列),我们的模型可以成功地将人物插入到场景图像中。该模型根据场景背景推断可能的姿势(可供性),适当地重新调整人物姿势,并协调插入。当没有给出参考时,我们还可以部分完成一个人(最后一列)并幻觉一个人(最后一行)。
给定一个蒙版场景图像(第一行)和一个参考人物(第一列),我们的模型可以成功地将人物插入到场景图像中。该模型根据场景背景推断可能的姿势(可供性),适当地重新调整人物姿势,并协调插入。当没有给出参考时,我们还可以部分完成一个人(最后一列)并幻觉一个人(最后一行)。
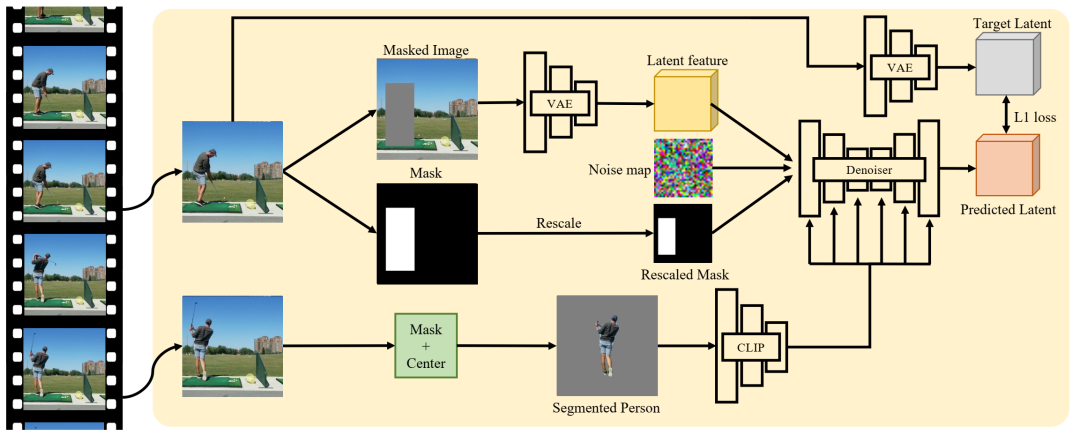 架构概述。我们从视频剪辑中获取两个随机帧。我们屏蔽第一帧中的人,并使用第二帧中的人作为条件来修复图像。我们将背景图像和重新缩放的掩码的潜在特征与噪声图像一起连接到去噪 UNet。参考人嵌入(CLIP ViT-L/14)通过交叉注意传递。
架构概述。我们从视频剪辑中获取两个随机帧。我们屏蔽第一帧中的人,并使用第二帧中的人作为条件来修复图像。我们将背景图像和重新缩放的掩码的潜在特征与噪声图像一起连接到去噪 UNet。参考人嵌入(CLIP ViT-L/14)通过交叉注意传递。
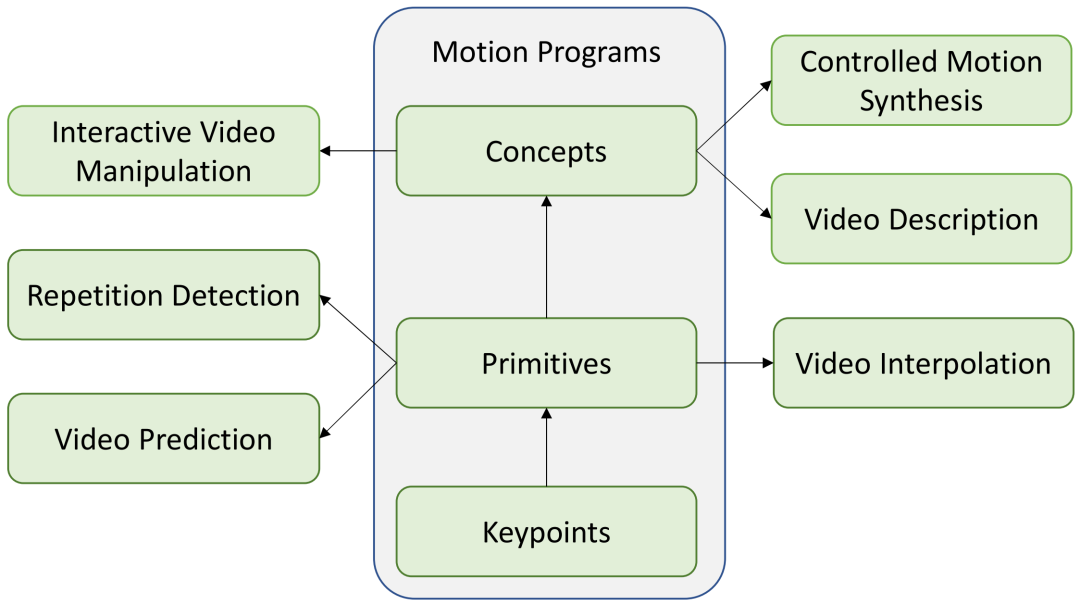
运动程序概述:从输入的运动或视频开始,我们自动推断出更高级别的抽象,例如基元和概念。我们可以利用这些来改进多个下游任务,例如视频插值、预测、描述、编辑等。
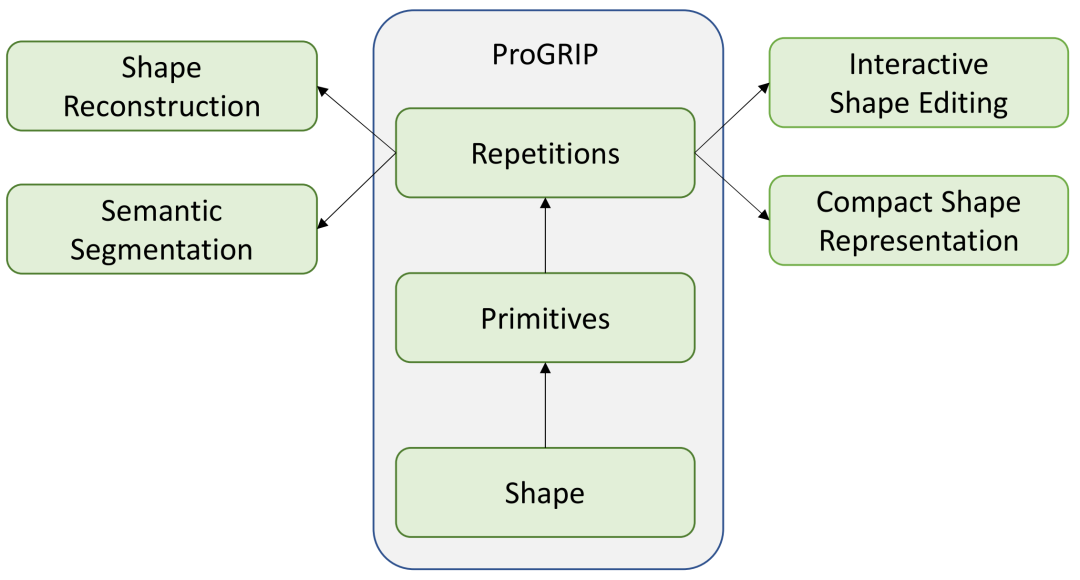
ProGRIP 概述:从输入的 3D 点云开始,我们自动推断出更高级别的抽象,例如形状基元及其重复。我们可以利用这些来改进多个下游任务,例如语义形状分割和交互式形状编辑。
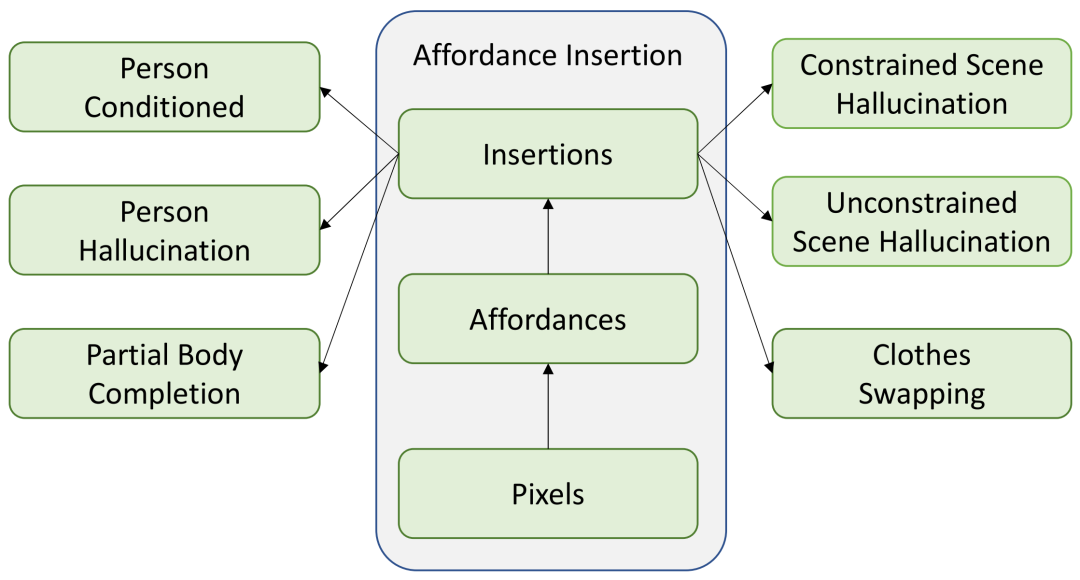
可供性插入概述:给定一个输入场景图像和一个人的图像,我们的模型可以真实地将人插入到场景中。它还能够执行其他辅助任务。






内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢