

1966年,斯坦福大学SRI研究所开发了 Shakey[1],其被广泛认为是第一个结合感知、规划和执行能力的自主移动机器人。Shakey 能够在场景中自主探索并避开障碍物,但由于当时传感器设备的局限性以及计算能力的不足,Shakey 完成一个任务通常需要耗费数小时,而且只能在预先设置好的、相对简单且受控的实验室环境中工作。
如今,得益于硬件性能、计算能力以及算法的发展,移动机器人已经从实验室走向实际应用。人们已经开始习惯移动机器人在餐厅送餐、建筑清洁等场景的应用。更令人兴奋的是,近年来基础模型(foundation models)展现了令人惊讶的场景理解和文字生成方面的能力。研究者开始期待将基础模型应用于移动机器人,使其能够更精准地感知复杂场景并完成基于自然语言的任务指令。
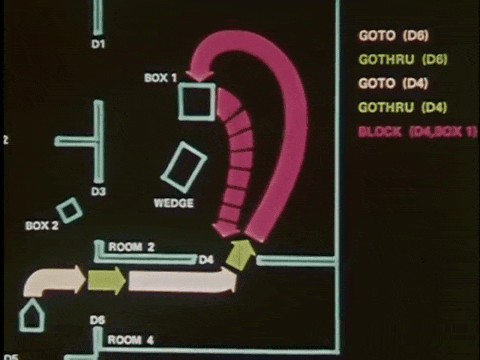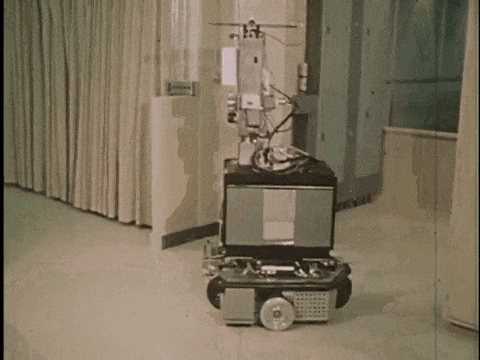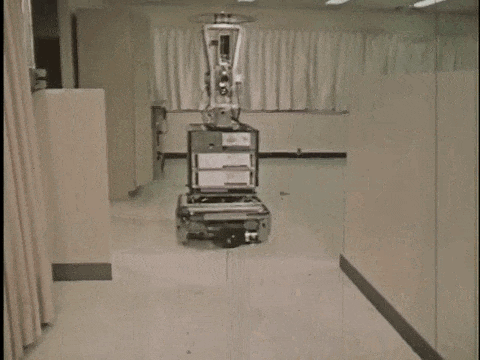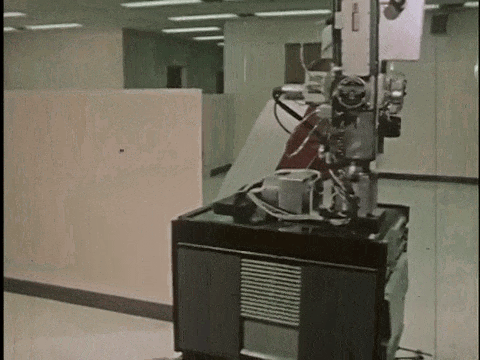
Shakey
一种较为稳健的研究思路是扩展现有的基于地图的技术路线。随着传感器(如IMU、Lidar、深度相机)技术的进步以及更先进的 SLAM 算法的应用,构建高质量地图的难度和成本都在迅速下降。在此基础上,研究者们通过预训练的基础模型,对场景进行语义分割和物体识别,进一步丰富了地图中的信息。这些信息涵盖了从建筑整体结构,到每一层楼的布局,再到房间内部的物体细节,既包括全局的宏观信息,也包含细粒度的物体特征。通过这些场景信息,可以支持一些基于启发式策略的方法,来执行特定任务,例如寻找某个物体或前往指定楼层。进一步的研究还在探索将这些信息与大语言模型(如ChatGPT)结合,以处理更复杂的指令任务,如找到一楼办公室里的公文包。
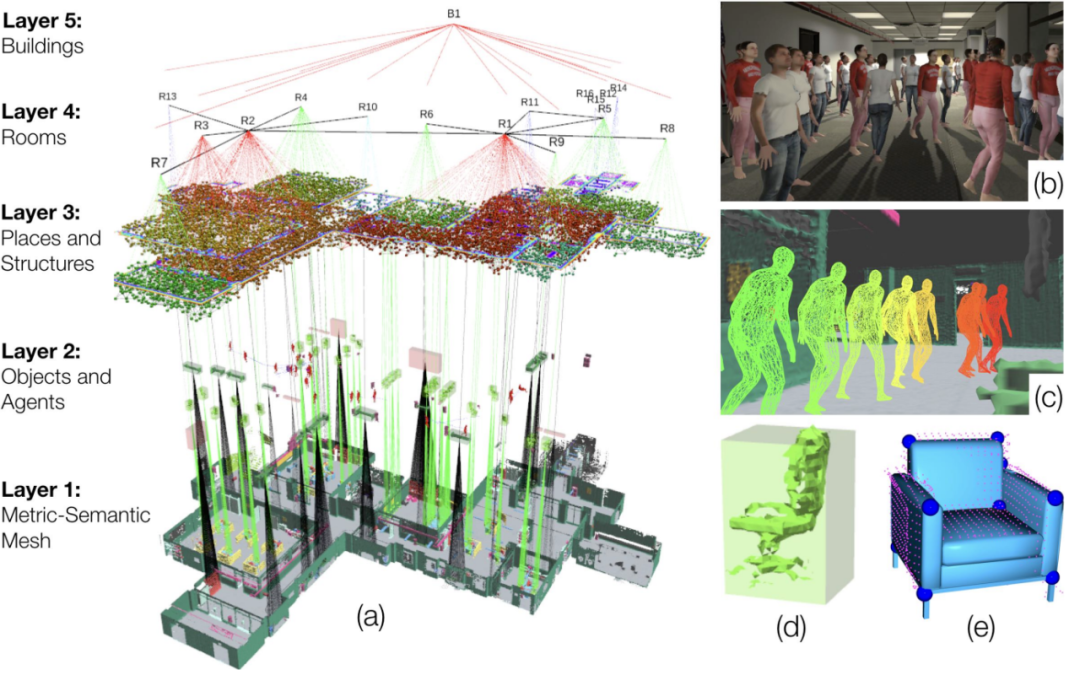
3D Dynamic Scene Graphs[2]
这种基于地图的做法既保留了传统地图的优势(继续使用现有的定位和规划算法),又能支持更加智能化的任务,因而受到许多研究团队的关注。然而,处理这些多样且丰富(甚至可能包含少量错误)的场景信息,往往需要使用复杂的数据结构来整理,例如层次化节点图(hierarchical node graph)[3]或复杂的长文本描述[4,5]。这些数据结构的构建过程常常伴随着频繁的修正。当场景信息更新或切换到新的场景时,各种适配性工作也往往使得研究者疲惫不堪。
一种更新颖且激进的做法是端到端的移动机器人算法。这类算法直接将传感器获取的观测数据输入到大模型中,然后根据模型的输出执行相应动作。这种想法受到端到端的自动驾驶的发展的激励。然而移动机器人需要面临一些特殊的挑战,包括: (1) 场景的多样性且缺少固定路线指引,(2) 更加细粒度的语义(找到放着米色毛衣的椅子)和 (3) 近距离的人员接触(学校/商场环境)。这类研究避免了繁琐的规则设计,通常以数据驱动为核心,通过构建合适的模型结构,并利用大量数据进行训练,使模型能够在现实环境中高效完成任务。
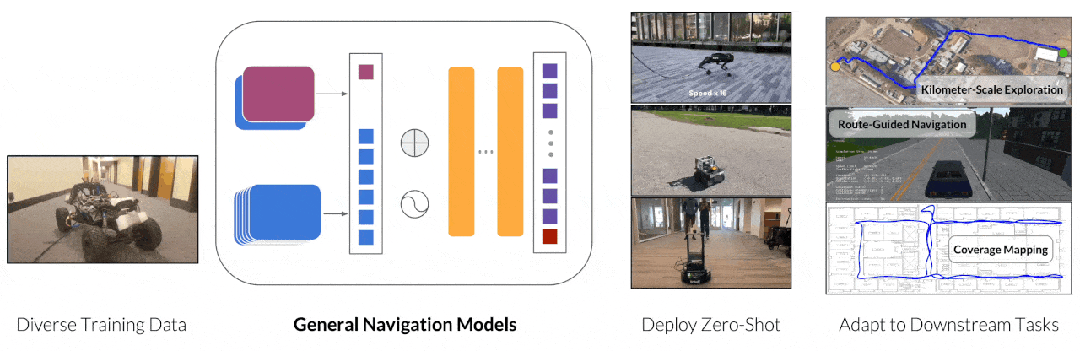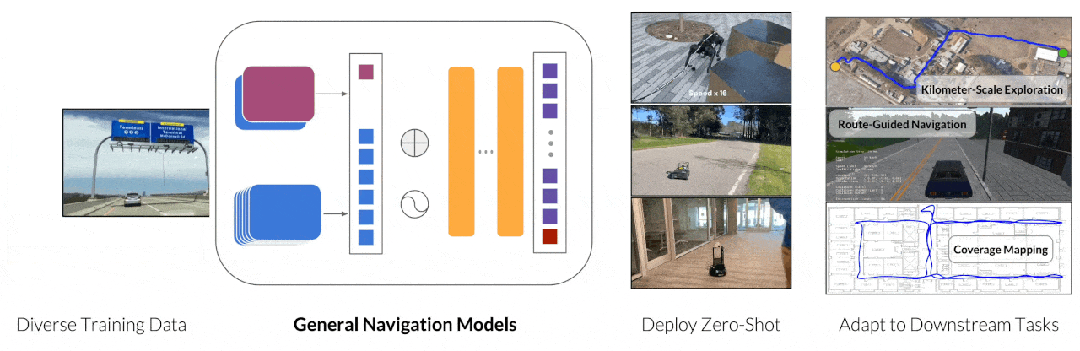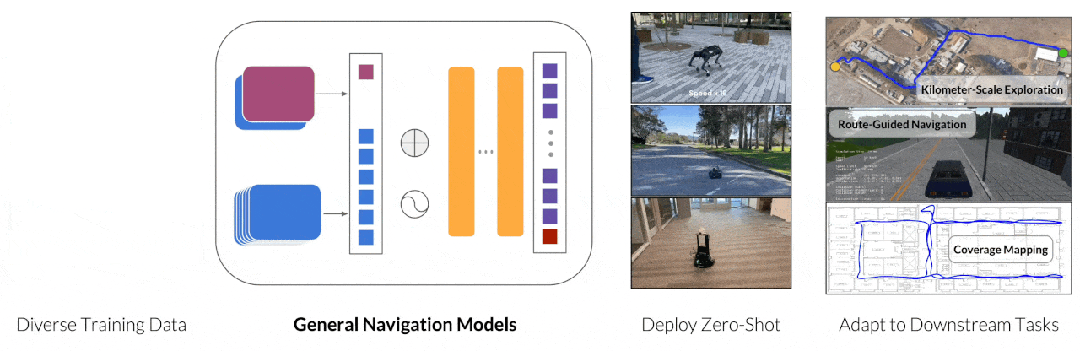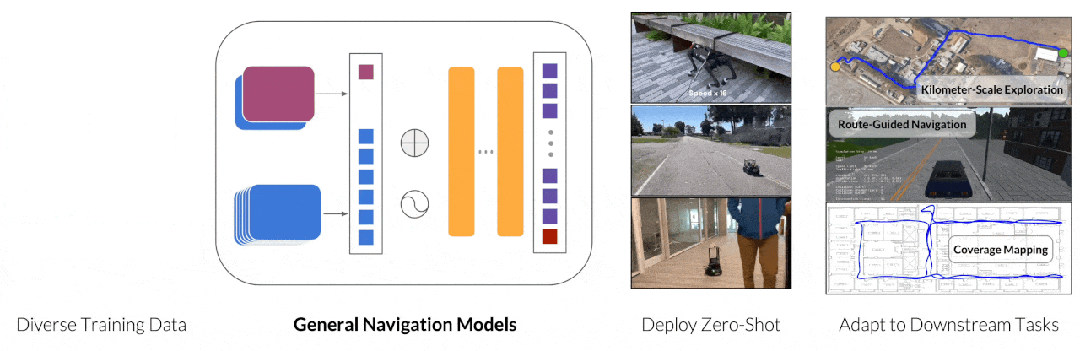
Pipeline of GNM
这其中比较出名的工作是 GNM(General Navigation Models)[6]和其系列工作, 该系列工作收集真实的任务数据,训练模型掌握包括路径规划,避障,目标寻找等能力。鉴于收集大量且多样真实数据的挑战,另一种端到端方法 NaVid[7]选择使用模拟器生成的数据,并结合真实图像的问答数据进行训练。这种做法既保留模拟器制作数据的灵活性,同时利用真实图像问答数据让模型理解真实世界图像,从而实现模拟器到真实世界的泛化。然而相比更成功的端到端的案例(自动驾驶),移动机器人在数据数量和质量上仍然存在巨大差距,这限制了端到端移动机器人进一步的发展。
尽管面临诸多亟待解决的问题,基础模型的结合正逐渐成为移动机器人领域的热点与重要发展方向。凭借其在语义理解与场景感知上的强大能力,基础模型为移动机器人带来了前所未有的智能化突破。未来,移动机器人有望在开放场景中实现智能的自主决策,展现出卓越的适应能力。随着数据规模的不断扩展与模型优化的深入推进,移动机器人将在多个领域展现出更强的自主性与灵活性。
参考文献
[1] https://www.sri.com/hoi/shakey-the-robot/
[2] Rosinol, Antoni, et al. "3D dynamic scene graphs: Actionable spatial perception with places, objects, and humans." arXiv preprint arXiv:2002.06289 (2020).
[3] Werby, Abdelrhman, et al. "Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation." RSS. 2024.
[4] Zhou, Gengze, Yicong Hong, and Qi Wu. "Navgpt: Explicit reasoning in vision-and-language navigation with large language models." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 7. 2024.
[5] Long, Yuxing, et al. "InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment." arXiv preprint arXiv:2406.04882 (2024).
[6] Shah, Dhruv, et al. "Gnm: A general navigation model to drive any robot." 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023.
[7] Zhang, Jiazhao, et al. "NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation. RSS. 2024.

文 | 张嘉曌
图 | 陈冠宏

— 版权声明 —
本微信公众号所有内容,由北京大学前沿计算研究中心微信自身创作、收集的文字、图片和音视频资料,版权属北京大学前沿计算研究中心微信所有;从公开渠道收集、整理及授权转载的文字、图片和音视频资料,版权属原作者。本公众号内容原作者如不愿意在本号刊登内容,请及时通知本号,予以删除。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢