

今天为大家介绍的是来自Sangseon Lee & Sun Kim团队在nature communications上发表的一篇论文,该论文将语义引导的随机游走用于知识图谱特征提取,并在药物重定位上取得了很好的效果。
一、 研究摘要
药物重定位(Drug Repurposing),即对已上市或临床试验中的药物进行新的适应症开发,是一种节约成本、缩短周期的创新方法。然而,由于现有的网络或知识图谱方法节点数量不平衡(图1),基因占主导,药物和疾病少,从关系层面看,PPI网络密集,药物疾病关联网络稀疏,两个稀疏的网络和一个稠密的网络进行嵌入很难得到有效的特征表示。
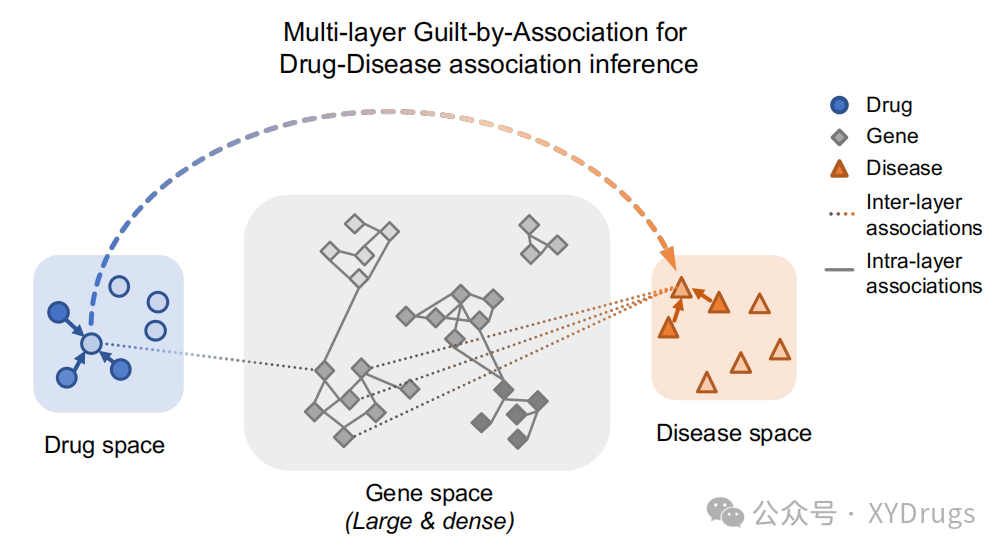
为了解决数据不平衡问题,本文提出了一种基于语义多层关联推断的知识图谱学习模型——DREAMwalk,通过语义引导的随机游走策略(图2)提升嵌入表示的准确性,尤其在药物与疾病关系的预测上表现出更高的准确度。
与目前最先进的模型相比准确率提升了16.8%,对嵌入空间的探索揭示了生物和语义上下文之间的良好协调。通过对乳腺癌和阿尔茨海默病的重新利用案例研究证明了方法的有效性,强调了多层关联罪责视角在生物医学知识图谱上药物重新利用的潜力。
二、研究背景
1. 药物研发的挑战
新药研发是一个漫长且高风险的过程,通常需要超过10年的时间,并且有高达90%的失败率。为此,药物重定位成为一种新兴的策略,它利用现有药物的安全性数据进行新适应症的开发,大大缩短了研发时间和成本。
2. 现有药物重定位方法及局限性
目前的药物重定位方法主要有两类:
基于药物-疾病相似性的网络模型,如MVGCN。这些模型没有充分考虑药物的生物学机制,导致预测效果不佳。 基于知识图谱的方法,利用了丰富的生物医学数据,解决了生物学机制不足的问题。但存在严重的数据不平衡问题,基因节点数量远多于药物和疾病节点,导致在随机游走过程中,嵌入表示过度依赖基因节点,无法充分捕捉药物与疾病之间的关系。
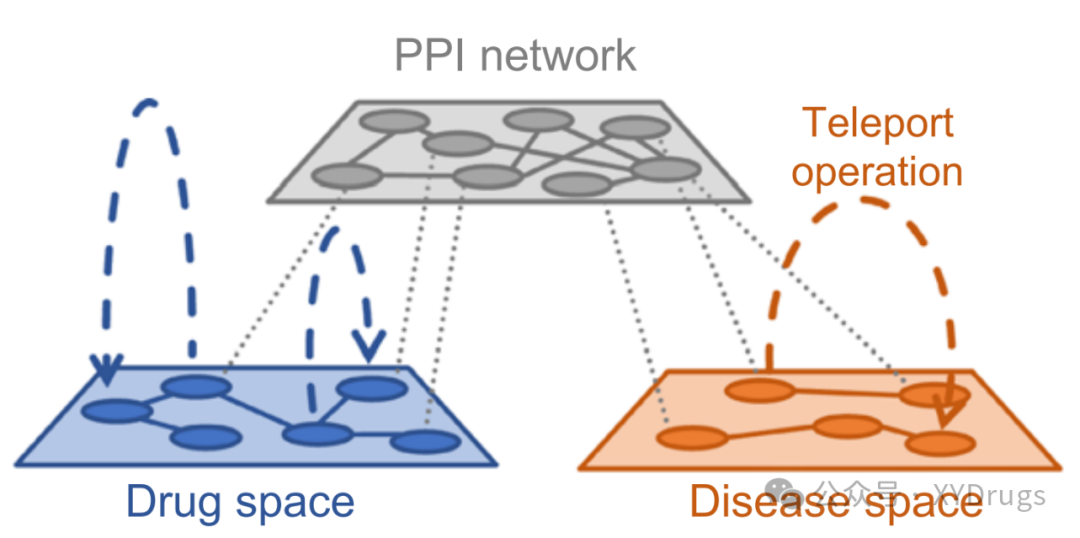
为解决知识图谱对基因节点的依赖,作者引入了基于语义的远程传输,解决了随机游走在不平衡网络中游走得到嵌入不佳的问题。
三、研究材料与方法
1. 知识图谱数据源
研究主要使用了三大知识图谱:MSI、HetioNet和KEGG,每个图谱中包含的药物、疾病、基因和通路等数量如下表所示:
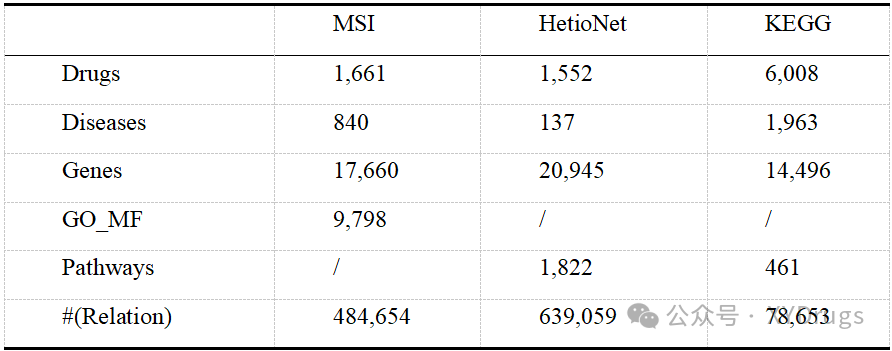
HetioNet疾病节点较少,因为使用了更广泛的概念,没有做细化,比如在MSI和KEGG中高血压,被分为肺动脉高血压,颅内高压等。HetioNet中统一称为高血压。HetioNet中关系进行了细化,比如化合物结合gene,化合物上调gene,化合物下调gene。
2. 语义信息引导的远程传输
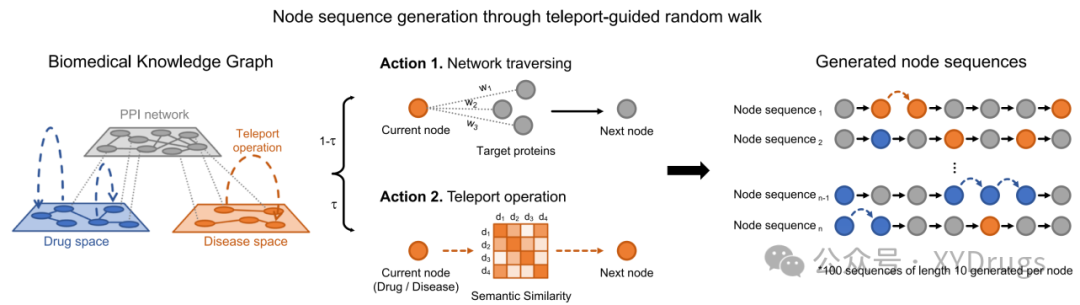
DREAMwalk 的创新之一是远程传输操作(Teleportation Operation)(图3),它通过语义引导的方式,在随机游走过程中实现药物和疾病节点的频繁出现。传统的随机游走方法容易偏向于基因节点,因为基因节点在知识图谱中占据主导地位,导致药物和疾病节点嵌入表示不足。为解决这一问题,DREAMwalk 引入了基于语义信息的远程传输机制。
远程传输机制:在随机游走过程中,模型会根据语义相似性决定是否进行远程传输。语义相似性根据药物和疾病的分类体系(如ATC分类和MeSH术语)来计算。当游走到药物或疾病节点时,模型将以一定概率(传输因子 τ)跳转到与当前节点语义相似的其他节点,从而增加药物和疾病的出现频率,解决了数据不平衡问题。具体传输概率公式为:
是传输因子,控制远程传输操作的频率。是药物节点之间的语义相似性矩阵。这种机制使得药物和疾病的关联更频繁地被探索,提高了它们的嵌入表示精度。
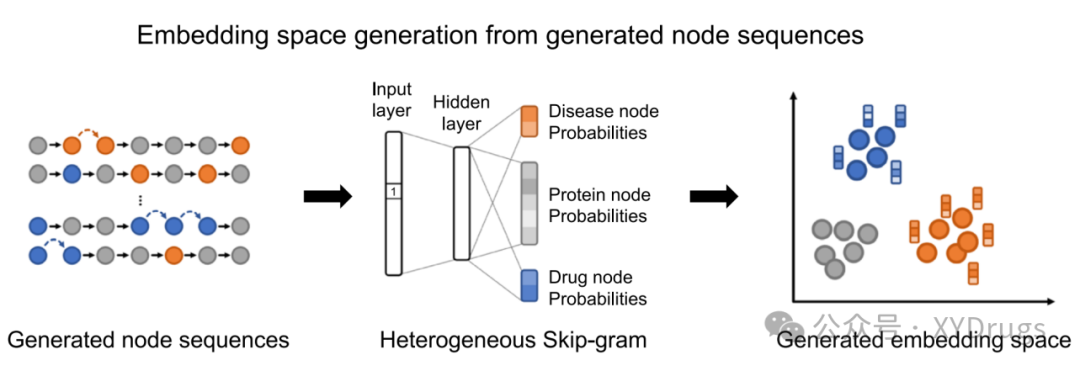
3.异质图的 Skip-Gram 嵌入表示
DREAMwalk 框架在生成随机游走路径后,使用了异质图的 Skip-Gram 模型来学习节点的嵌入表示。传统的 Skip-Gram 模型通过最大化一个节点与其上下文节点的共现概率来学习节点的连续特征表示。然而,经典的 Skip-Gram 模型并没有考虑不同类型节点在图中的分布差异。在处理异质图时,直接采用标准的 Skip-Gram 模型可能导致节点类型信息的丢失,从而生成不适合不同类型节点的嵌入表示。
DREAMwalk 通过引入节点类型感知的 Skip-Gram 方法,改进了这一嵌入表示过程。这一方法受异构节点表示学习模型 metapath2vec++ 的启发,专门针对异质图中不同类型节点的特点设计(图4),从而生成更具生物学和语义意义的嵌入向量。
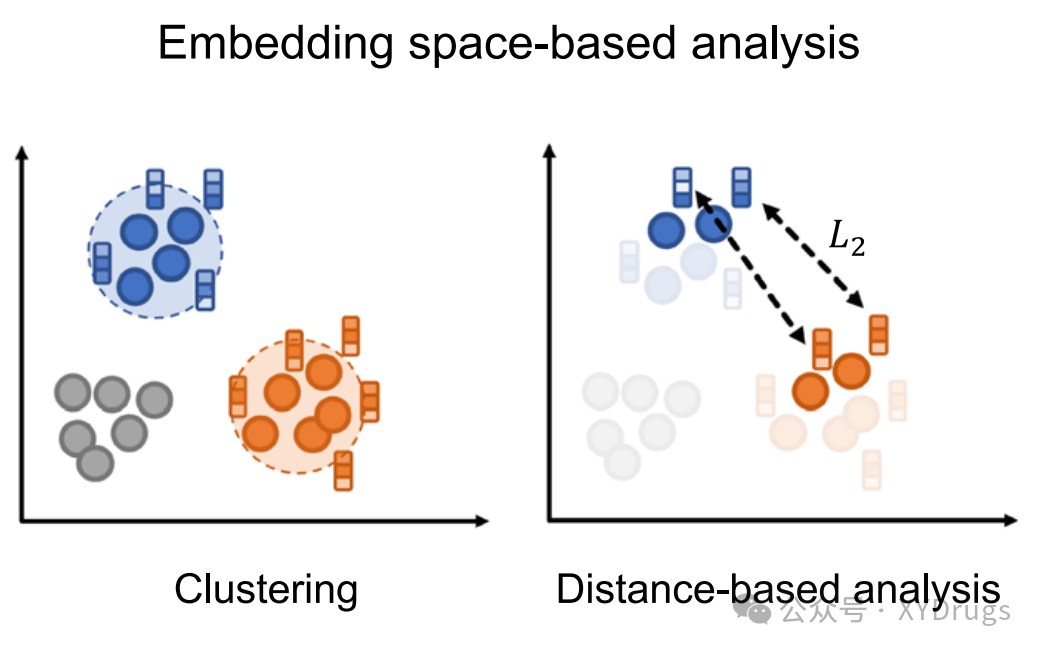
4. 基于距离的嵌入空间探索
DREAMwalk 的嵌入空间不仅能捕捉药物与疾病在生物学信息上的关联,还融合了语义信息。为了验证这一嵌入空间的表现,作者通过距离分析进行探讨,并比较了不同空间下的节点距离(图5)。
4.1 嵌入空间中的距离计算
首先,为了衡量不同实体(如药物和疾病)之间的差异性,作者使用了欧氏距离(Euclidean Distance)。这个方法可以量化两个实体之间的距离,公式为:
和分别代表实体 u 和 v 的嵌入向量。欧氏距离可以很好地捕捉同一个嵌入空间内的实体差异,但当我们试图比较不同嵌入空间(如带传送机制和不带传送机制的随机游走生成的嵌入空间)时,直接使用欧氏距离并不合适。
4.2 归一化处理
为了比较不同的嵌入空间,作者引入了一个归一化步骤。作者计算了网络中所有节点的成对距离,并对这些距离进行了z-score 标准化。这个过程通过以下步骤完成:对每个节点对之间的距离进行标准化:将欧氏距离减去均值,并除以标准差,从而生成一个标准化的欧氏距离。
标准化后的距离不再依赖于原始的尺度,变得无单位(unit-less),使得不同嵌入空间的距离可以被公平比较。通过这一方法,更好地评估带有传送机制的随机游走与传统随机游走之间的差异。
4.3 显著性检验
为了评估传送引导嵌入空间与非传送引导嵌入空间之间的差异,使用了双侧配对 t 检验。这种检验方法可以帮助我们判断两种空间之间的距离差异是否具有统计显著性。
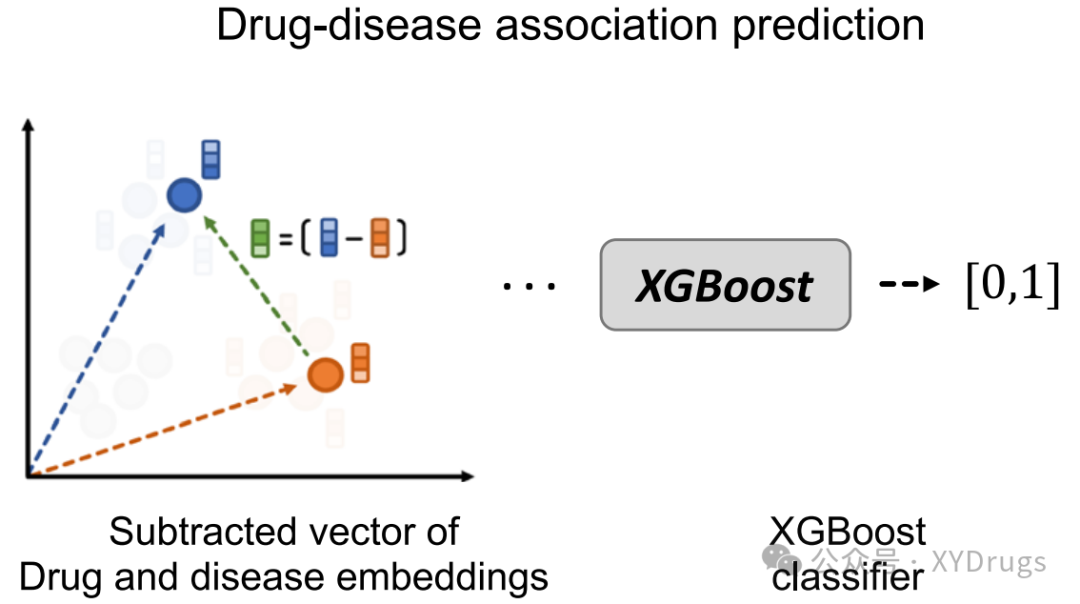
5. XGBoost 分类器
在生成嵌入表示后,DREAMwalk 使用XGBoost 分类器来预测药物和疾病之间的潜在关联(图6.)。模型将药物和疾病的嵌入向量进行向量差计算,并将该差值作为特征输入到 XGBoost 中,用于分类任务。向量差的计算公式为:
通过训练 XGBoost,模型输出每个药物-疾病对的关联概率,进而筛选出具有潜在治疗效果的药物。
四、研究结果与讨论
1. 模型性能评估
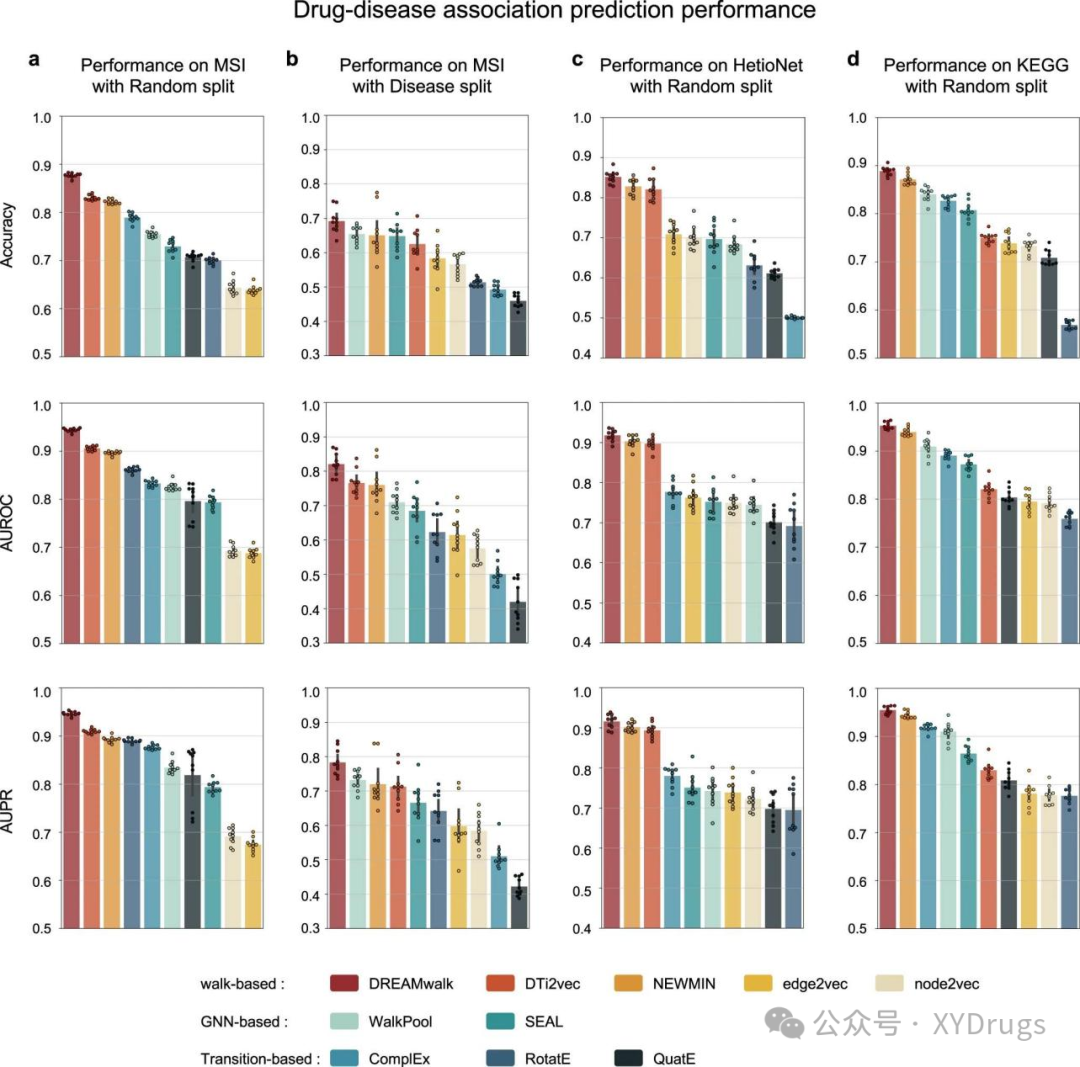
在MSI、HetioNet和KEGG三个数据集上,研究者与多种现有方法进行了对比,包括基于随机游走的DTI2Vec、node2vec,以及基于图神经网络(GNN)的Walkpool、SEAL等方法。结果表明,DReamwalk模型在多个任务上均优于其他方法(图7)。
2. 嵌入空间的改进
接下来是对嵌入空间的分析。主要是想说明加入远程传输,得到的表征更好。ABC是相似的药物(图8a)。在生成路径时,没使用远程传输,这三个相似药物的距离很远。但是使用了远程传输后,三个相似的药物在嵌入空间的距离就小了很多。说明得到的特征更能反应语义距离。然后作者就举了两个例子(图8b,c)。
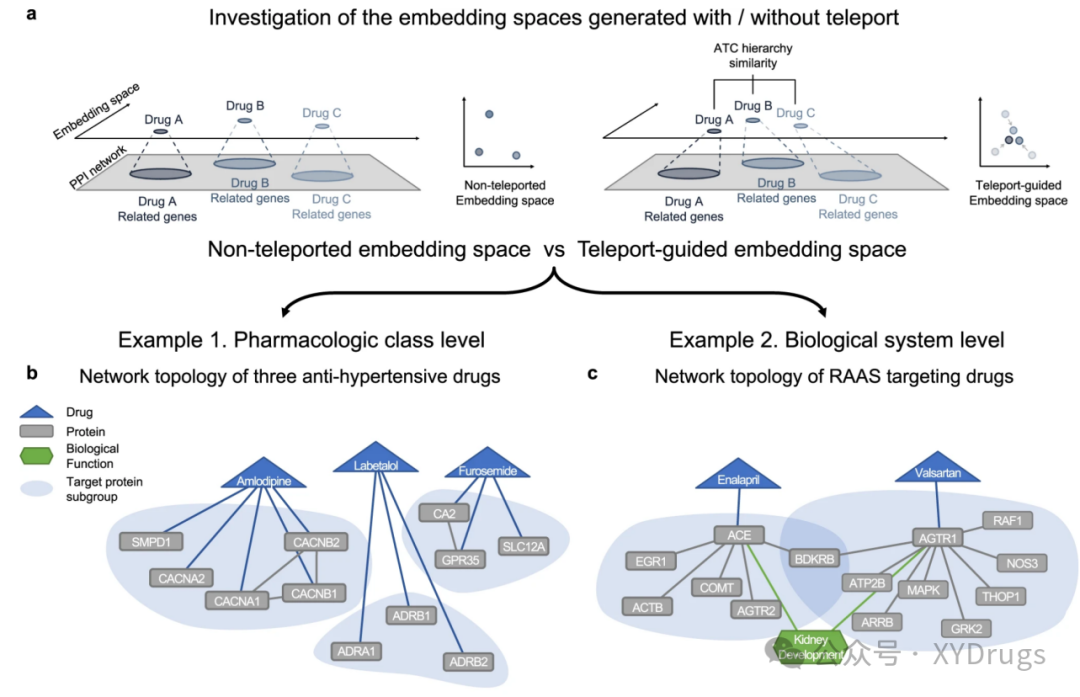
第一个例子是用于高血压治疗的三种药物。选择氨氯地平、拉贝洛尔和呋塞米这三个不同类别的高血压药物进行研究。这三种药物虽然都用于高血压的治疗。但是生物学机制完全不同。它们针对不同的蛋白质,扰乱不同的通路并导致不同的细胞事件。他们的靶蛋白之间没有表现出相互作用。然而,它们都是一线治疗方法,并且经常联合使用。具有相同目标疾病-不同 MoA 的药物的这些特征可能是基于 biomedKG 的药物再利用的障碍。第二个例子是依那普利和缬沙坦,也是治疗高血压的药物,依那普利作用于ACE靶标,缬沙坦作用于AGTR1,没有共享靶标,ACE 和 AGTR1邻居集只有BDKRB一个交集,jaccard相似性为0.018,这意味着两种药物存在着显著的生物学距离。
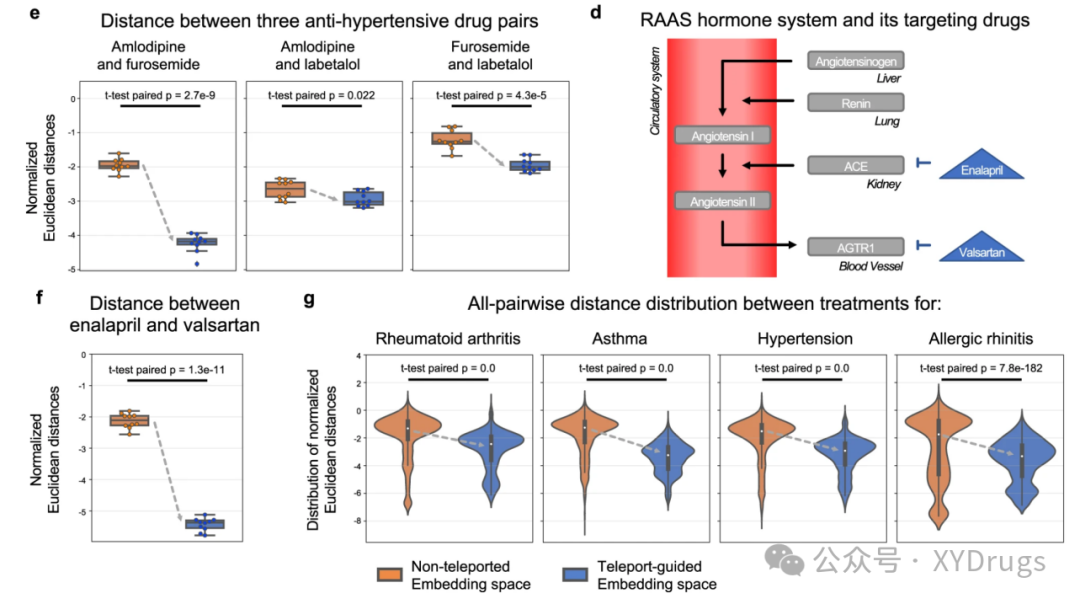
上述5种药物都是治疗高血压的药物,但在图谱中存在着较远的距离,随着语义的整合,也就是通过瞬移来得到的嵌入,几种药物间的距离有着明显的下降(图9e,f)。也就是在新的嵌入空间,作用相似的药物,距离更近,说明得到的嵌入更能反应语义信息。
类风湿性关节炎(92种药物)、哮喘(88种药物)、高血压病(82种药物)和过敏性鼻炎(74种药物)间成对的语义距离,也全都有所下降(图9g.)。
3. 语义信息引导的瞬移
接下来就是要探究为何这样做会有更好的效果,因为使用了瞬移,还是因为瞬移的同时使用了语义相似性呢?
作者他们做了下面的对比试验,一个是随机瞬移,一个是不使用瞬移,一个是加入计算相似性时使用的树状结构,还有就是使用语义信息的瞬移。可以看出,随机瞬移比没有瞬移效果更差,使用语义相似性的瞬移效果最好,其次是使用了语义网络的随机游走介于语义相似性的瞬移和不使用瞬移之间(图10b.)。
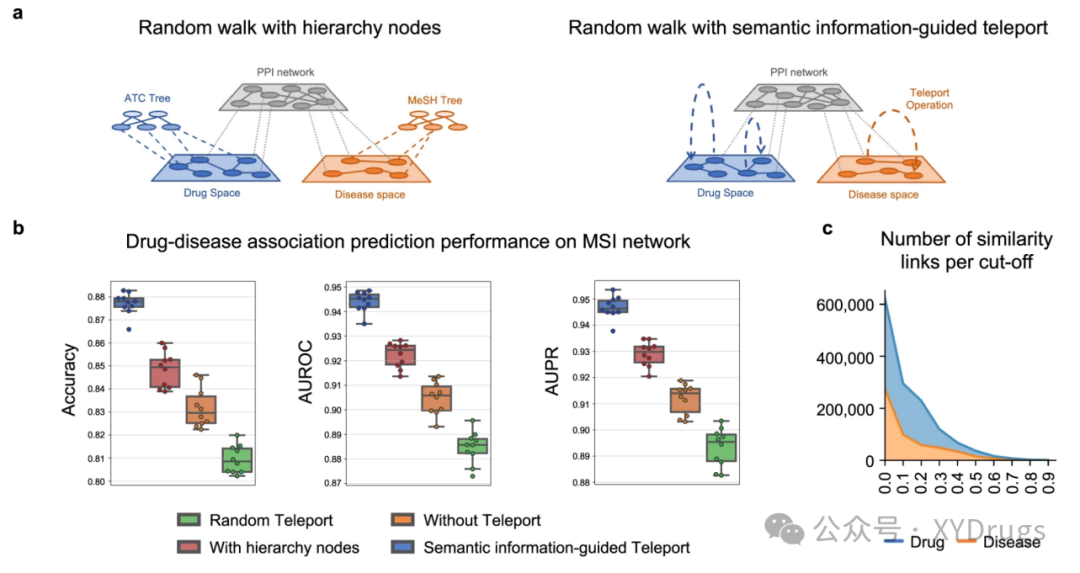
图10c是相似性的截断值和截断后相似性的数量。也就是说截断的值影响瞬移路径的,所以会对模型的结果有影响,那会有什么影响呢?
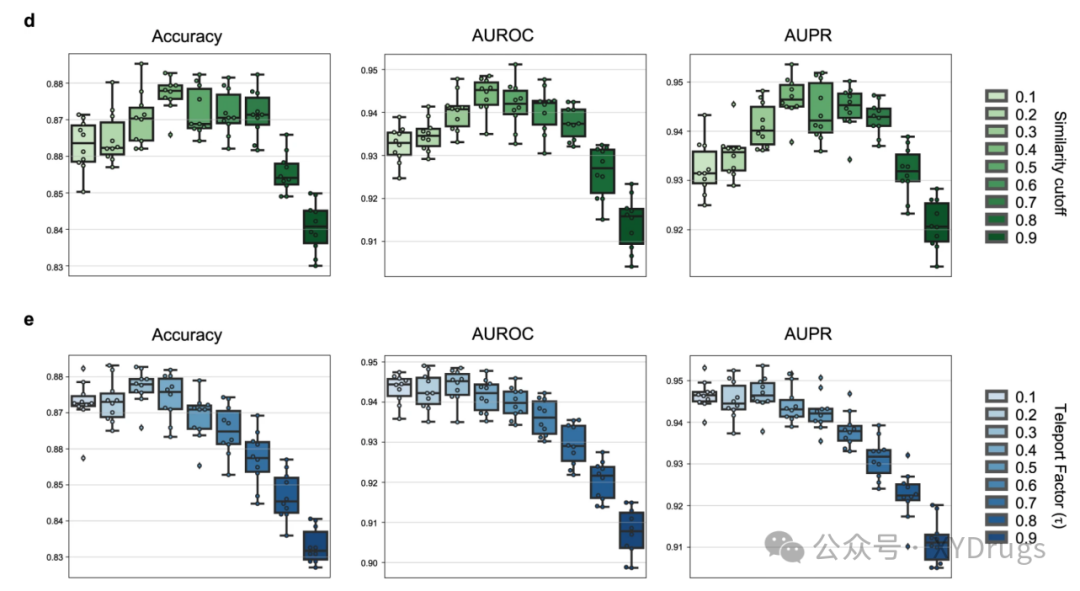
然后作者就比较了不同截断值模型的性能,可以看出截断值在0.4时,效果最好(图10d.),意味着信噪比降低,就是说不截断时,药物间有没有关系都能瞬移过去,会带来很多的噪声,截断后只会瞬移到语义相似的药物上,从而降低了信噪比。当截断值过大时,瞬移节点的多样性会下降,性能也逐渐下降。
然后还有就是瞬移的频率(传送因子)对模型也有很大影响,频率为0相当于没有瞬移,频率为1相当于全是瞬移,不在网络中游走,作者对比了不同瞬移频率的影响。可以看出瞬移为0.3时,效果最好(图10e)。
4. 基于瞬移的作用机理解释
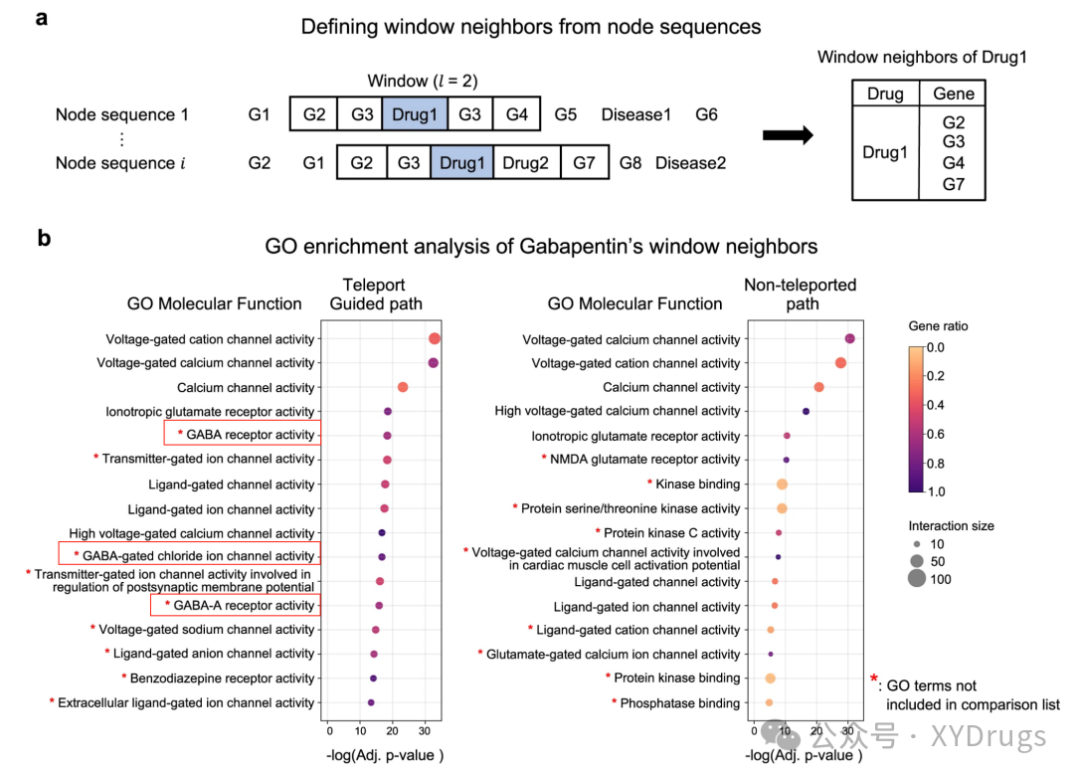
然后接下来就是从另外一个角度来说明瞬移是有好处的,就是可以解释一些,不使用瞬移解释不了的机制。首先作者定义了一个窗口邻居(图12a.)。所谓窗口邻居,就是中心节点左右在窗口中的邻居。
然后下面是两个实例,第一个是加巴喷丁的案例(图12b.)。窗口设置成2,然后用窗口邻居中的gene进行富集分析。加巴喷丁是用于治疗癫痫的相对较新的药物。研究报告称,加巴喷丁可显着增加大脑中的 GABA 水平。但该药物似乎并不直接影响 GABA 特异性酶或受体。药物靶标数据库表明加巴喷丁不直接与 GABA 受体结合。通过对窗口邻居中的gene富集,可以看出,经过瞬移的可以富集到 GABA 受体,GABA 门控氯离子通道,GABA-A受体。而不经过瞬移的富集结果和GABA无关。
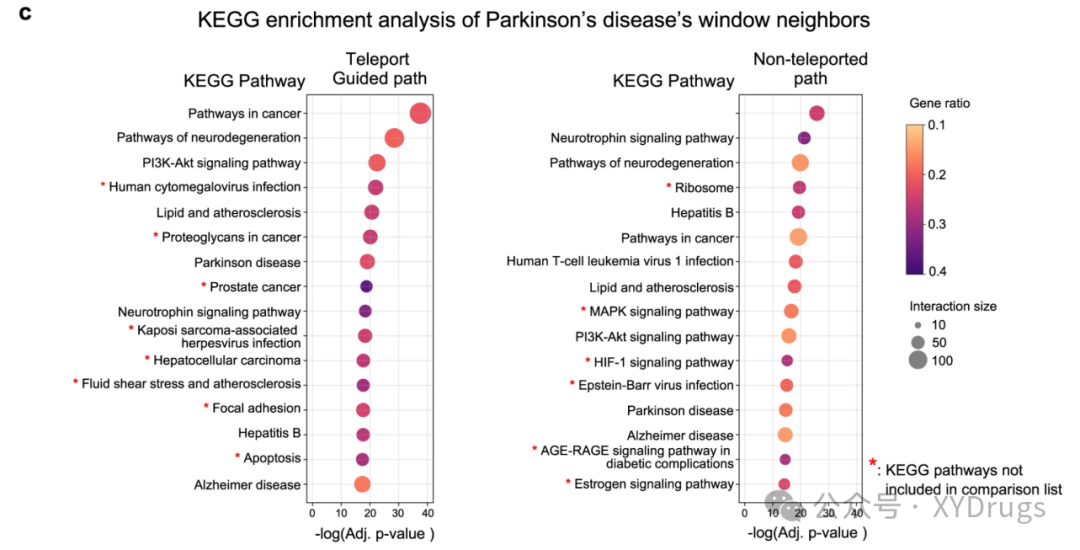
另一个例子是帕金森(图13)。帕金森要是由于神经递质多巴胺的耗竭而发生的。在 DREAMwalk 上出现的通路为流体剪切应力和动脉粥样硬化通路、粘着斑和凋亡通路。文献验证证实这些通路与PD密切相关。而不经过瞬移的没有上述通路。
5. 药物重定位案例分析
通过模型对乳腺癌和阿尔茨海默症进行了药物重定位分析。对于乳腺癌,筛选出的前10种药物中,有8种已有文献支持其对乳腺癌的潜在疗效;对于阿尔茨海默症,筛选出的10种药物中,有9种得到了文献支持。
五、总结展望
DREAMwalk 框架通过多层语义关联推断(GBA),提升了药物-疾病关联(DDA)预测能力。结合语义引导的随机游走算法,该框架整合分子与语义层次信息,生成统一的药物-疾病嵌入空间,在多个生物医学知识图谱上展现出良好泛化能力。消融实验显示,语义相似性度量显著提升了预测性能。DREAMwalk 嵌入空间在高血压药物分析中捕捉了药理和生物系统信息,增强了药物-疾病关联的可解释性。加巴喷丁与帕金森病的基因分析和其他预测结果也得到了文献支持。
尽管 DREAMwalk 在 DDA 预测中表现出色,仍存在局限性。传送操作中的概率 τ 为用户指定,未来研究可以根据局部网络拓扑动态调整。此外,负样本的随机采样存在不足,作者计划在未来开发正-未标注(Positive-Unlabeled, PU)学习框架,以建立更可靠的决策边界,提升预测的准确性。
参考文献:
Bang, D., Lim, S., Lee, S. et al. Biomedical knowledge graph learning for drug repurposing by extending guilt-by-association to multiple layers. Nat Commun 14, 3570 (2023). https://doi.org/10.1038/s41467-023-39301-y
文章代码:
https://github.com/eugenebang/DREAMwalk
投稿人:李 坤
责任编辑:许燕红
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢