

- ECCV 2024论文发布合辑-
科研成果速览

近期,清华大学交叉信息院研究组在国际知名的欧洲计算机视觉国际会议(European Conference on Computer Vision)上发表了一系列创新性科研成果。赵行助理教授、许华哲助理教授共发表4项创新科研工作,包括纯视觉自动驾驶系统视角转换模型CVT-Occ,以及新型自动驾驶感知系统框架PreSight、通过语义对应实现机器人操控的新框架Robo-ABC,以及通过条件视频扩散模型学习专家视频的Diffusion Reward新框架。
CVT-Occ: 利用时序信息在三维空间中构建匹配代价的占据栅格预测方法
纯视觉自动驾驶系统面临从2D图像输入到3D场景建模的视角转换问题,而缺乏深度信息使得这一任务面临严峻挑战。而不同时刻的信息提供了辅助的观测视角,有助于修正模型对深度的预测,提升占据栅格(Occupancy)预测效果。为此,赵行团队设计了一个全新的匹配代价体时序模块,基于匹配代价(Cost Volume)的构建,利用长时序信息,修正模型对深度的预测,显著提升模型的空间理解能力。
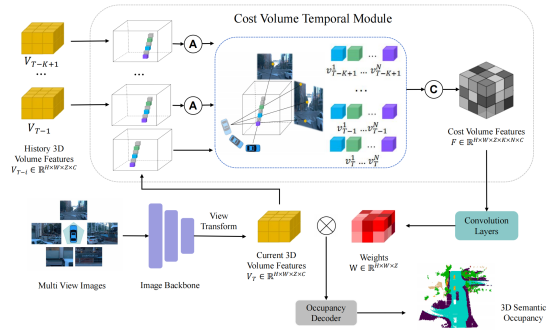
图|CVT-Occ整体架构图
该模块首次探索了在三维空间中构建匹配代价,通过同一视线在不同时刻的视差信息,降低二维到三维转换中的深度不确定性。具体做法是利用数据集中的投影矩阵,对所有历史时刻的三维体特征与当前时刻进行坐标对齐。在当前时刻的三维体特征上,以固定间距采样多个点,并将其投影到历史时刻的坐标系中。所有采样点在特征维度上拼接形成匹配代价体特征。随后,卷积神经网络以匹配代价体特征作为输入,输出辅助修正深度信息的权重,作用到当前时刻的三维体特征上,从而提升空间理解的准确性。
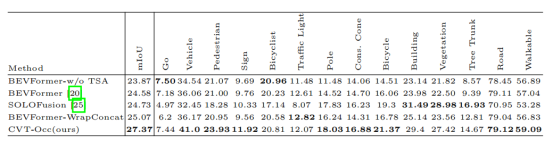
图|在Occ3D-Waymo数据集上CVT-Occ优于其他时序融合方法
团队在数据集Occ3D-Waymo上与时序融合方法进行了比较,在mIoU指标上有了显著的提升,在大部分类别上都超过了所有其他方法。从可视化结果中也可以看到,CVT-Occ对体素点的深度预测更为精准,表现出了更强的空间理解能力。

图|可视化结果
CVT-Occ方法首次尝试了在三维空间构建匹配代价的技术路线,为利用时序信息提升纯视觉自动驾驶Occupancy预测效果提供了新的思路,具有重要的理论和实践价值。本论文第一作者为清华大学交叉信息院本科生叶章琛,导师为赵行助理教授。
项目论文:
CVT-Occ : CVT-Occ: Cost Volume Temporal Fusion for 3D Occupancy Prediction, Zhangchen Ye*, Tao Jiang*, Chenfeng Xu, Yiming Li, Hang Zhao, ECCV 2024.
PreSight:利用神经辐射场先验帮助自动驾驶场景的在线感知
今天的自动驾驶系统通常仅依靠在线传感器数据实现实时环境感知,而缺乏高效地利用过去观测数据的手段。与之相比,人类驾驶员在开车时会记住自己所开过的路段,在熟悉的道路上越开越好。为此,赵行团队设计了新的感知框架PreSight,通过构建城市级神经辐射场(NeRF),对过去的观测数据加以利用,重建城市级先验知识,增强下次经过同一路段时在线感知模型的表现。

图|PreSight方法展示图
团队首先提出分块重建的思路,从而实现使用百万数量级图片构建数公里级的城市级NeRF。引入基础视觉模型DINO的知识,构建包含可泛化语义信息的场景先验。设计了一种即插即用的融合模块,可以有效地将构建好的场景先验和在线观测进行融合,能够与任意一种基于BEV的在线感知进行组合,提升其感知能力。最后,在nuScenes数据集上设计实验,证明了该方法能在局部高清地图感知、占据栅格(Occupancy)预测任务上有效提升模型表现。
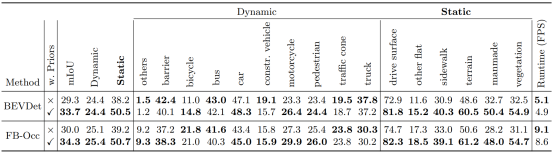
图|PreSight对Occupancy预测任务的提升
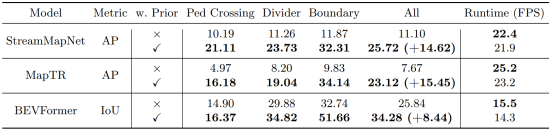
图|PreSight对局部高清地图感知任务的提升
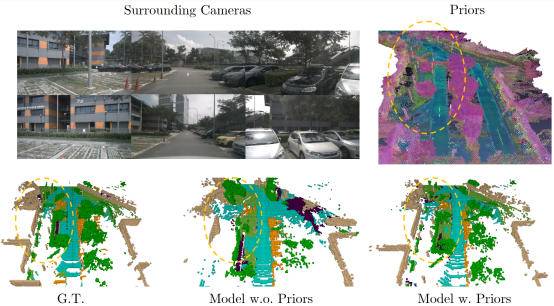
图|PreSight对环境几何信息的精确重建
帮助在线感知
PreSight框架首次提出了使用过去观测信息重建可泛化的城市级先验,为解自动驾驶在线感知难的问题提供了新的思路,具有重要的理论和实践价值。该论文第一作者为清华大学交叉信息院2022级博士生袁天远,导师为赵行助理教授。
项目论文:
PreSight: Enhancing Autonomous Vehicle Perception with City-Scale NeRF Priors, Tianyuan Yuan, Yucheng Mao, Jiawei Yang, Yicheng Liu, Yue Wang, Hang Zhao, ECCV 2024.
Robo-ABC: 通过语义对应实现跨类别的可供性泛化,用于机器人操控
Robo-ABC 是一种新的机器人操控框架,旨在使机器人能够泛化地理解和操作在训练时未见过的类别的物体。该框架的核心思想是利用人类视频中的交互经验,通过语义对应(semantic correspondence)来帮助机器人在面对新物体时,能够通过检索与已知物体在视觉或语义上相似的物体,来推断新物体的可供性(即物体可被如何操作的特性)。
许华哲研究组首先从人类与物体互动的视频中提取可供性信息,并将这些信息存储在可供性记忆中。当机器人面对一个新物体时,它会从记忆中检索与新物体在视觉和语义上相似的物体。然后,利用扩散模型的语义对应能力,将检索到的物体的接触点映射到新物体上。这个过程使得机器人能够在没有手动标注、额外训练、部件分割、预编码知识或视角限制的情况下,零样本地泛化到跨类别物体的操控。
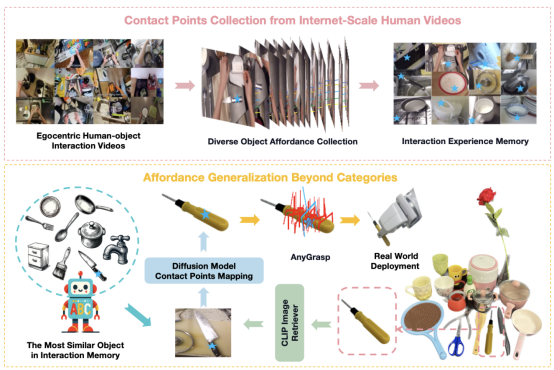
图|Robo-ABC流程图
研究组发现了Robo-ABC在泛化性上有优异的性能。相较于前人的方法,有了显著的提升。
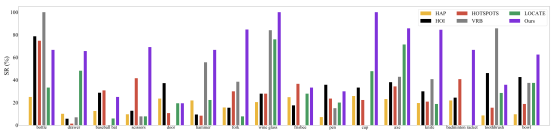
图2. Robo-ABC的优异性能

图|Robo-ABC可泛化至多种不同类型的物体
Robo-ABC在泛化抓取方面取得重要进展。该论文共同第一作者为清华大学交叉信息院2022级博士生胡开哲、上海期智研究院助理研究员鞠沅辰。
项目论文:
Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation, Yuanchen Ju*, Kaizhe Hu*, Guowei Zhang, Gu Zhang, Mingrun Jiang, Huazhe Xu, ECCV 2024.
Diffusion Reward:通过条件视频扩散模型学习专家视频的奖励函数
这篇论文提出了一个名为“Diffusion Reward”的新框架,它通过条件视频扩散模型从专家视频中学习奖励函数,以解决复杂的视觉强化学习(RL)问题。Diffusion Reward通过估计条件熵的负值来鼓励RL智能体探索类似专家的行为。
具体来说,研究者们首先使用专家视频训练一个视频扩散模型,然后利用该模型预测的分布的熵来估计条件熵,将其作为奖励信号。这个奖励信号结合了新颖性寻求奖励和稀疏的环境奖励,以形成用于高效RL的密集奖励。为了加速奖励推断,研究者们还采用了向量量化编码来压缩高维观测。
通过在MetaWorld和Adroit的10个视觉机器人操控任务上的实验,我们验证了他们框架的有效性,展示了其在相同训练步骤下比最佳基线方法分别提高了38%和35%的性能。此外,预训练的奖励模型能够在未见任务上实现合理的零样本泛化性能。
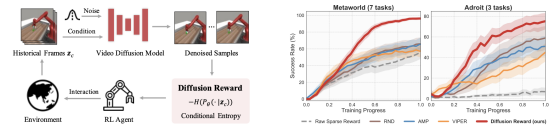
图|Diffusion Reward流程图(左)
和性能曲线(右)
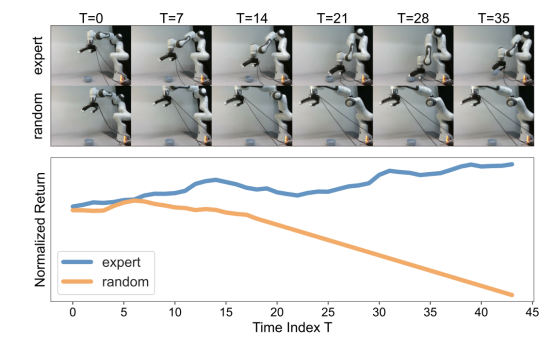
图|Diffusion Reward 在真实机器人上准确区分专家数据和随机数据
总的来说,这篇论文提出了一种从专家视频中提取密集奖励信号的新方法,通过利用视频扩散模型的生成能力,为视觉RL任务提供了一种有效的奖励学习框架,并展示了其在复杂任务中的潜力。该论文共同第一作者为上海期智研究院实习生黄涛、蒋光启。
项目论文:
Diffusion Reward: Learning Rewards via Conditional Video Diffusion, Tao Huang*, Guangqi Jiang*, Yanjie Ze, Huazhe Xu, ECCV 2024.
编辑 | 姜月亮
审核 | 吕厦敏
学术顾问 | 许华哲、赵行

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢