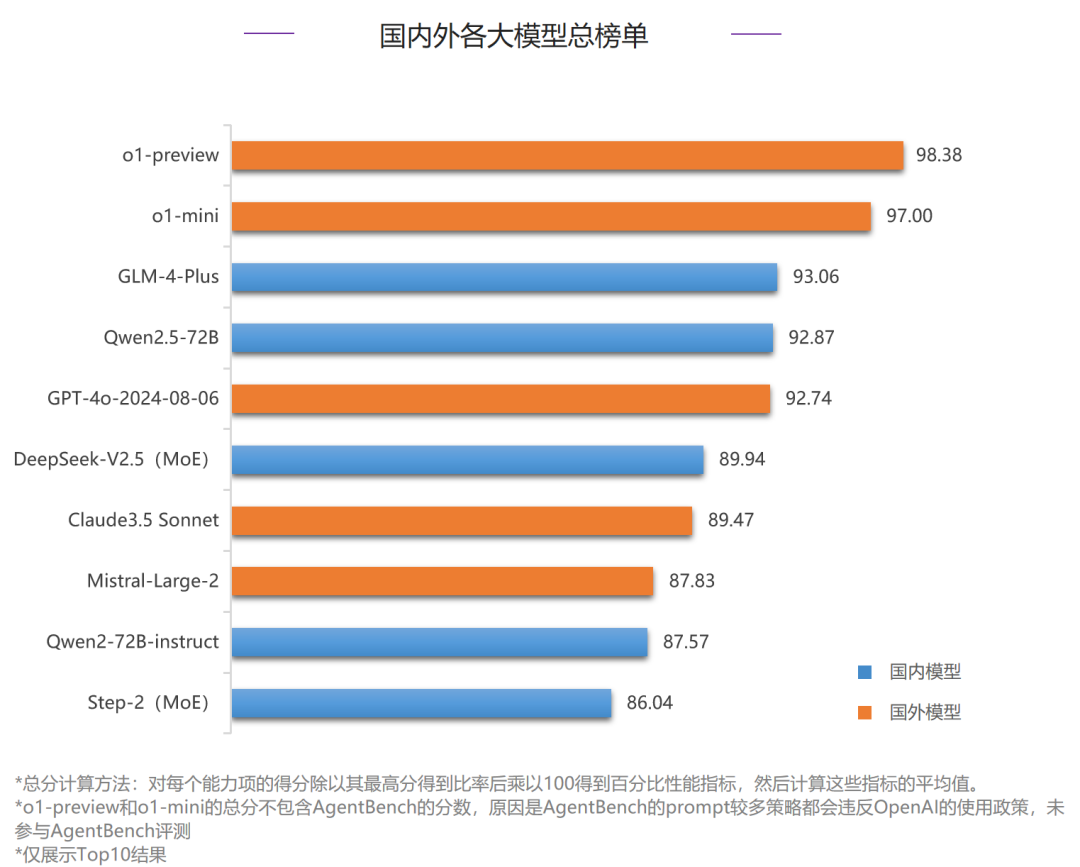
进入2024年9月,全球大模型市场竞争加剧,OpenAI的o1系列一经发布,便受到了业内广泛关注,国内各大厂商也纷纷推出了最新版本的大模型,值得关注的有智谱AI的GLM-4-Plus、通义千问的Qwen2.5-72B以及深度求索的DeepSeek-V2.5等。为了更好地衡量国内外各家大模型能力,SuperBench团队最新发布了2024年9月版本的《SuperBench大模型综合能力评测报告》,在本次评测中,选取了24个海内外具有代表性的大模型,具体评测列表如下:本报告只展示总榜和各分榜排名前十的模型,若您想查看完整榜单,请联系我们。整体来说,国外模型在本次评测中继续保持领先地位,OpenAI最新推出的o1-preview和o1-mini表现强势,刷新了多个榜单的最高分数,包揽了代码编写能力、人类对齐能力和数理逻辑能力三项评测的前两名,o1-preview在指令遵循能力评测中也占据榜首,是当前综合能力最强的模型。但国内头部模型也在不断追赶,本次国内模型GLM-4-Plus排名第三,打破了之前国外模型垄断前三甲的局面。国内模型本次在对齐、智能体、数理逻辑等多个评测中均有明显进步,除排名前三的GLM-4-Plus、Qwen2.5-72B和MoE模型DeepSeek-V2.5外,Step-2、云知声山海大模型3.0也在语义、安全等评测中展现了不俗的实力,国内模型竞争进一步加剧。总榜:国外模型依然领跑,但本次评测国内模型GLM-4-Plus荣登排行榜第三位,超过了Claude系列模型。国内模型:GLM-4系列蝉联榜首,Qwen2.5-72B和MoE模型DeepSeek-V2.5等近期新推出的模型也提升较多,进入本次评测Top3。ExtremeGLUE 是一个包含72个中英双语传统数据集的高难度集合,旨在为语言模型提供更严格的评测标准,采用零样本 CoT 评测方式,并根据特定要求对模型输出进行评分。我们首先使用了超过 20 种语言模型进行初步测试,包括了 GPT-4、Claude、Vicuna、WizardLM 和 ChatGLM等。我们基于所有模型的综合表现,决定了每个分类中挑选出难度最大的10%~20%数据,将它们组合为"高难度传统数据集"。- 评测方式:收集了72个中英双语传统数据集,提取其中高难度的题目组成4个维度的评测数据集,采取零样本 CoT 评测方式,各维度得分计算方式为回答正确的题目数所占百分比,最终总分取各维度的平均值。
- 评测流程:根据不同题目的形式和要求,对于模型的零样本 CoT 生成的结果进行评分。
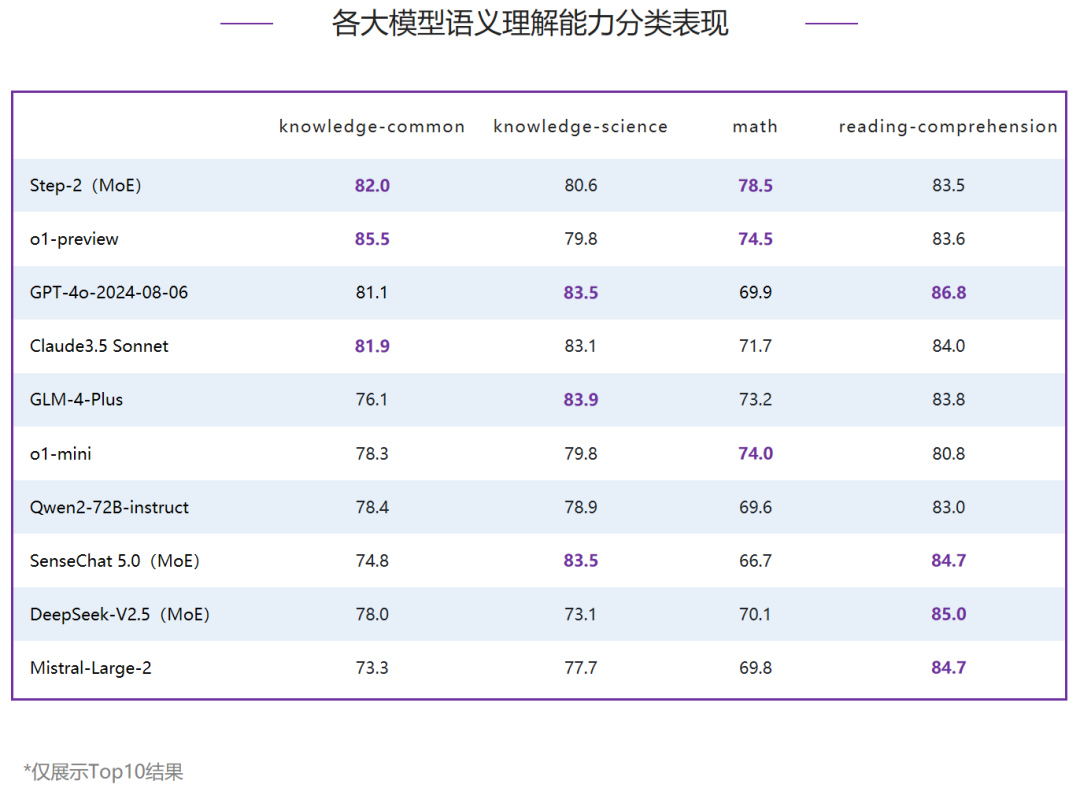
在语义理解能力评测中,第一梯队模型为80分档,其中,国内MoE模型Step-2占据榜首,超过了o1-preview、GPT-4o-2024-08-06和Claude3.5 Sonnet等国外模型,打破了6月国外模型占据前三甲的局面。第二梯队由国内模型GLM-4-Plus领跑,领先o1-mini 1分,其他模型中Qwen2-72B-instruct得77.5分,排名国内第三。
整体排名前三的模型在各分类评测中各有胜负,对比6月,知识-科学和阅读理解两个分类下Top3分布更加分散,整体排名前二的模型均未进入Top3。- 知识-常识:o1-preview得85.5分,排名第一,领先排名第二的Step-2 3.5分,Claude3.5 Sonnet略高于GPT-4o-2024-08-06,排名第三。
- 知识-科学:Top3分差接近,在1分之内,其中,GLM-4-Plus得83.9分,占据榜首。
- 数学:国内MoE模型Step-2排名第一,分别领先排名二、三位的o1-preview和o1-mini 4分和4.5分。
- 阅读理解:Top2模型均超过85分,分别是GPT-4o-2024-08-06和国内MoE模型DeepSeek-V2.5,国内MoE模型SenseChat5.0和国外模型Mistral-Large-2同分,并列第三。
NaturalCodeBench(NCB)是一个评估模型代码能力的基准测试,传统的代码能力评测数据集主要考察模型在数据结构与算法方面的解题能力,而NCB数据集侧重考察模型在真实编程应用场景中写出正确可用代码的能力。所有问题都从用户在线上服务中的提问筛选得来,问题的风格和格式更加多样,涵盖数据库、前端开发、算法、数据科学、操作系统、人工智能、软件工程等七个领域的问题,可以简单分为算法类和功能需求类两类。题目包含java和python两类编程语言,以及中文、英文两种问题语言。每个问题都对应10个人类撰写矫正的测试样例,9个用于测试生成代码的功能正确性,剩下1个用于代码对齐。- 评测方式:运行模型生成的函数,将输出结果与准备好的测例结果进行比对进行打分。将输出结果与准备好的测例结果进行比对进行打分,最终计算生成代码的一次通过率pass@1。
- 评测流程:给定问题、单元测试代码、以及测例,模型首先根据问题生成目标函数;运行生成的目标函数,以测例中的输入作为参数得到函数运行输出,与测例中的标准输出进行比对,输出匹配得分,输出不匹配或函数运行错误均不得分。
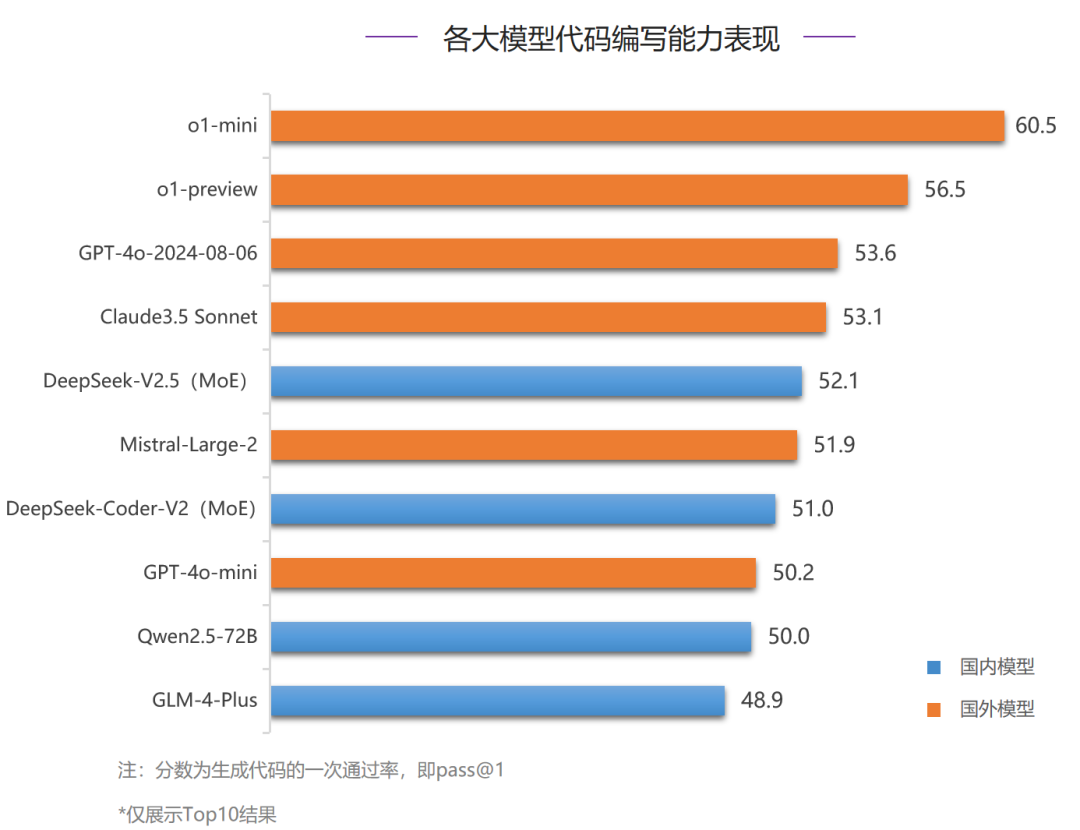
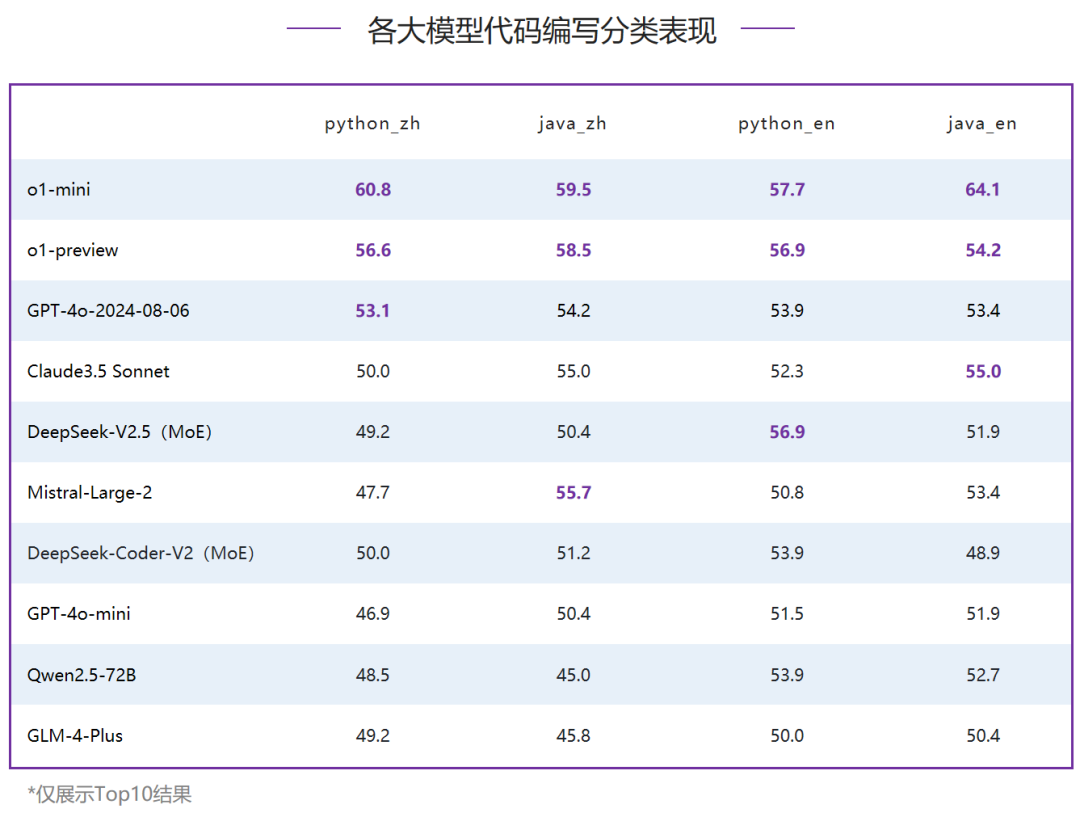
在代码编写能力评测中,国外模型垄断了前四名,o1-mini占据榜首,并且代码通过率超过了60%,明显领先其他模型;国内模型中,MoE模型DeepSeek-V2.5排名最高,力压Mistral-Large-2,排名第五。国内模型对比国外模型仍然有较大差距,但是对比6月,本次国内Top3模型均超过50分,代码编写能力有明显提升。在Python、Java语言的中文、英文四个维度的数据集评测中o1-mini均排名第一,o1-preview也在所有代码分类下均进入Top3,对比其他模型领先优势明显。其他模型中,整体排名三、四位的GPT-4o-2024-08-06和Claude3.5 Sonnet也在所有评测项中代码通过率都超过了50%,领先国内模型;国内模型中,仅有MoE模型DeepSeek-V2.5在Python语言的英文评测中和o1-preview同分,排名并列第二。AlignBench旨在全面评测大模型在中文领域与人类意图的对齐度,通过模型打分评测回答质量,衡量模型的指令遵循和有用性。它包括8个维度,如基本任务和专业能力,使用真实高难度问题,并有高质量参考答案。优秀表现要求模型具有全面能力、指令理解和生成有帮助的答案。“中文推理”维度重点考察了大模型在中文为基础的数学计算、逻辑推理方面的表现。这一部分主要由从真实用户提问中获取并撰写标准答案,涉及多个细粒度领域的评估。- 数学上,囊括了初等数学、高等数学和日常计算等方面的计算和证明。
- 逻辑推理上,则包括了常见的演绎推理、常识推理、数理逻辑、脑筋急转弯等问题,充分地考察了模型在需要多步推理和常见推理方法的场景下的表现。
“中文语言”部分着重考察大模型在中文文字语言任务上的通用表现,具体包括六个不同的方向:基本任务、中文理解、综合问答、文本写作、角色扮演、专业能力。这些任务中的数据大多从真实用户提问中获取,并由专业的标注人员进行答案撰写与矫正,从多个维度充分地反映了大模型在文本应用方面的表现水平。具体来说:- 基本任务考察了在常规NLP任务场景下,模型泛化到用户指令的能力;
- 中文理解上,着重强调了模型对于中华民族传统文化和汉字结构渊源的理解;
- 文本写作则揭示了模型在文字工作者工作中的表现水平;
- 角色扮演是一类新兴的任务,考察模型在用户指令下服从用户人设要求进行对话的能力;
- 专业能力则研究了大模型在专业知识领域的掌握程度和可靠性。
- 评测方式:通过强模型(如GPT-4)打分评测回答质量,衡量模型的指令遵循能力和有用性。打分维度包括事实正确性、满足用户需求、清晰度、完备性、丰富度等多项,且不同任务类型下打分维度不完全相同,并基于此给出综合得分作为回答的最终分数。
- 评测流程:模型根据问题生成答案、GPT-4 根据生成的答案和测试集提供的参考答案进行详细的分析、评测和打分。
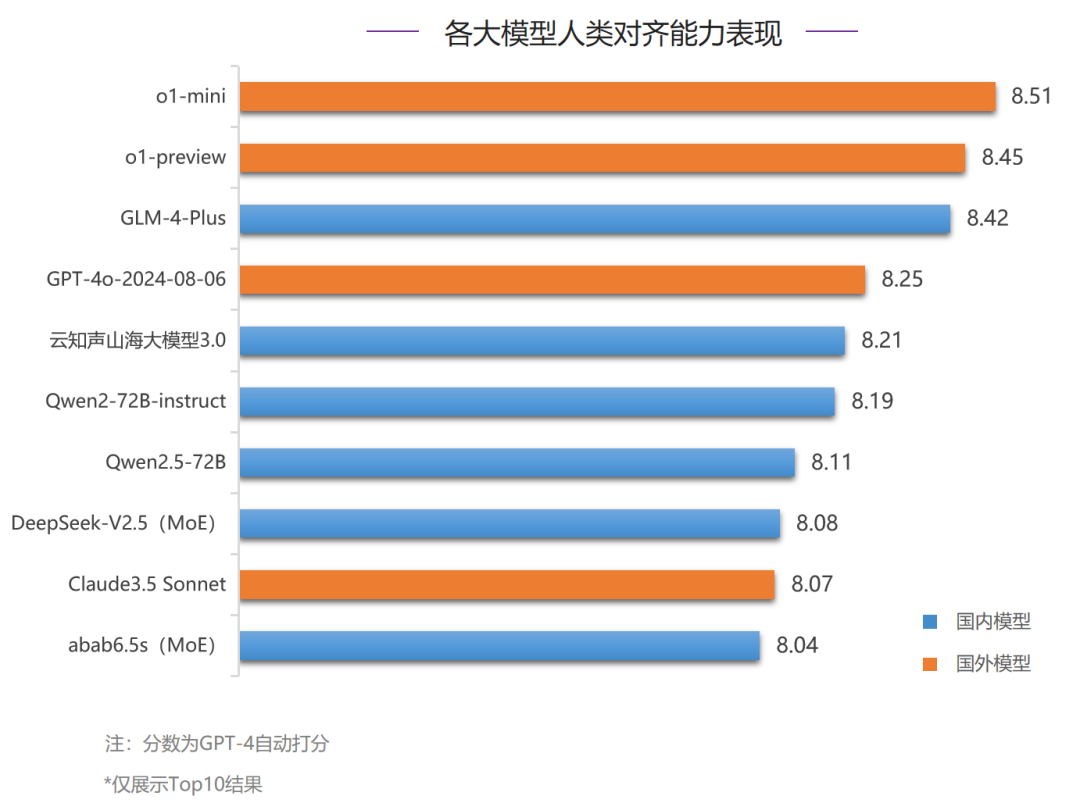
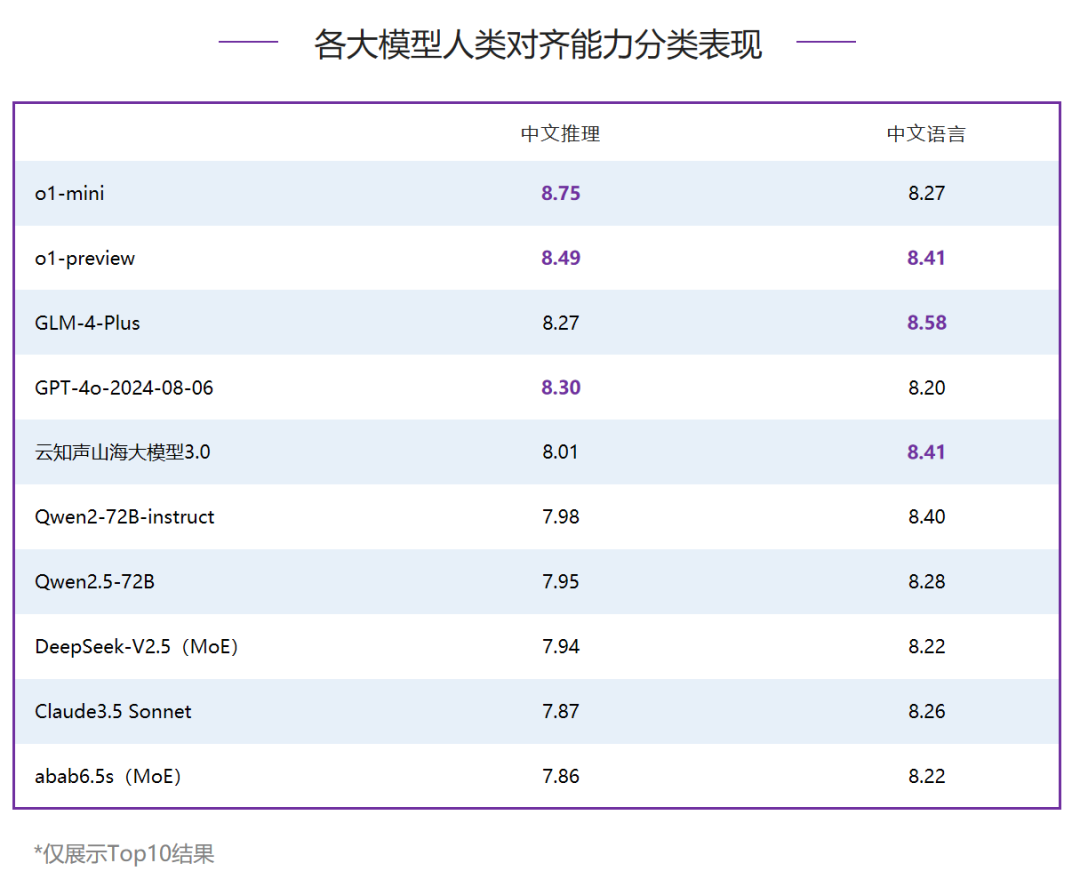
在人类对齐能力评测中,Top10模型均超过了8分,对比6月提升明显,o1-mini和o1-preview占据了前两名,国内模型GLM-4-Plus表现出色,仅落后o1-preview 0.03分,排名第三。国内其他模型中,云知声山海大模型3.0和Qwen2-72B-instruct分别得8.21分和8.19分,排名国内二、三位。- 中文推理:国外模型表现强势,垄断了Top3,其中o1-mini分数最高,得8.75分,o1-preview和GPT-4o-2024-08-06分列二、三位。国内模型中,GLM-4-Plus表现优异,和排名第三的GPT-4o-2024-08-06分数接近。
- 中文语言:GLM-4-Plus以8.58分领跑,o1-preview和国内模型云知声山海大模型3.0同得8.41分,并列第二。
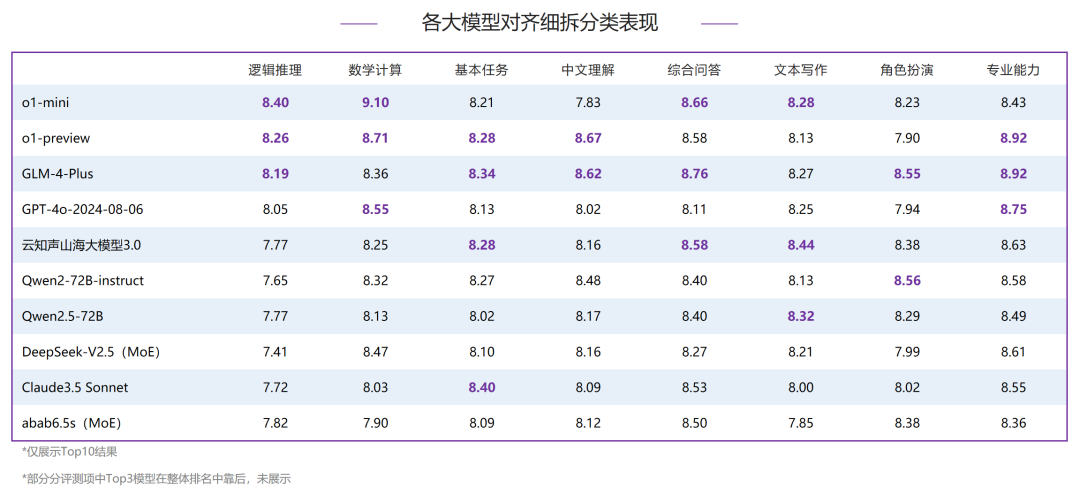
- 中文推理:o1-mini和o1-preview在逻辑推理和数学计算分类下,均排名前二;逻辑推理评测中,Top3和整体排名一致,GLM-4-Plus得8.19分,排名第三;在数学计算评测中,o1-mini拿到了9.10分的高分,和其他模型拉开了明显差距,分别领先排名二、三位的o1-preview和GPT-4o-2024-08-06 0.39分和0.55分,国产模型在该分类下均未进入Top3。
- 中文语言:国内模型依然表现亮眼,在综合问答、文本写作、角色扮演、专业能力四个评测项中均占据榜首,GLM-4-Plus在五项评测中进入了Top3,表现较好,其他模型中,o1-preveiw和云知声山海大模型3.0在3项分类评测中进入Top3,并且分别获得了中文理解和文本写作评测中的第一名,同样表现亮眼。
AgentBench是一个评估语言模型在操作系统、游戏和网页等多种实际环境中作为智能体性能的综合基准测试工具包。代码环境:该部分关注LLMs在协助人类与计计算机代码接口互动方面的潜在应用。LLMs以其出色的编码能力和推理能力,有望成为强大的智能代理,协助人们更有效地与计算机界面进行互动。为了评估LLMs在这方面的表现,SuperBench引入了三个代表性的环境,这些环境侧重于编码和推理能力。这些环境提供了实际的任务和挑战,测试LLMs在处理各种计算机界面和代码相关任务时的能力。游戏环境:游戏环境是AgentBench的一部分,旨在评估LLMs在游戏场景中的表现。在游戏中,通常需要智能体具备强大的策略设计、遵循指令和推理能力。与编码环境不同,游戏环境中的任务不要求对编码具备专业知识,但更需要对常识和世界知识的综合把握。这些任务挑战LLMs在常识推理和策略制定方面的能力。网络环境:网络环境是人们与现实世界互动的主要界面,因此在复杂的网络环境中评估智能体的行为对其发展至关重要。在这里,SuperBench使用两个现有的网络浏览数据集,对LLMs进行实际评估。这些环境旨在挑战LLMs在网络界面操作和信息检索方面的能力。- 评测方式:模型和预先设定好的环境进行多轮交互以完成各个特定的任务,情景猜谜子类会使用GPT-3.5-Turbo对最终答案进行评分,其余子类的评分方式根据确定的规则对模型完成任务的情况进行打分。
- 评测流程:模型与模拟环境进行交互,之后对模型给出的结果采用规则评分或GPT-3.5-Turbo评分。
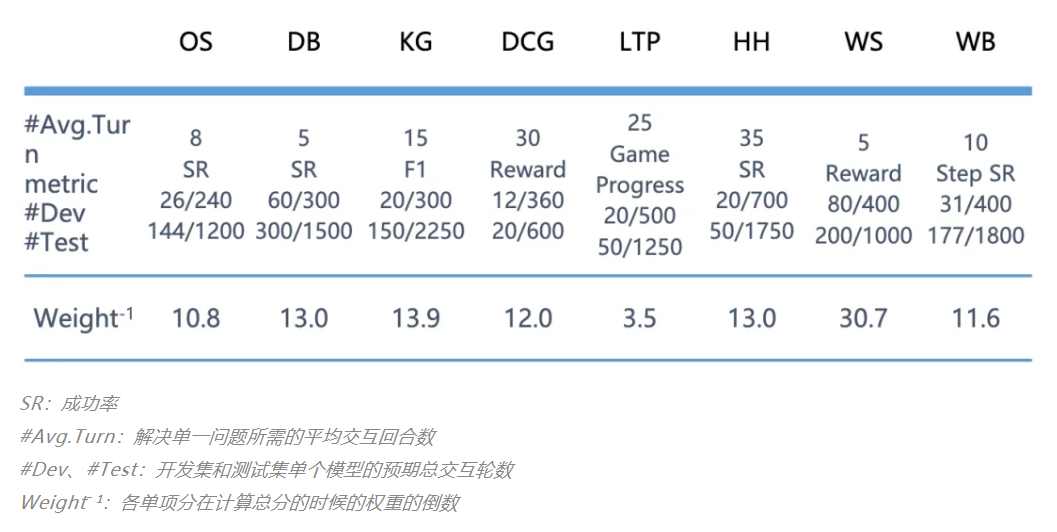
- 打分规则:由于不同子任务的分数分布不同,直接按平均分计算总分受极值的影响较为严重,因此需要对各子任务的分数进行归一化处理。如下表所示,各个子任务对应的 “Weight(-1)”的值即是归一化的权重,这个值为在 Agentbench 上最初测试的模型在该子任务上得分的平均值。计算总分时将各个子任务的分数除以 Weight(-1) 后求平均值即可。根据该计算方式,具有平均能力的模型最终得到的总分应为 1。
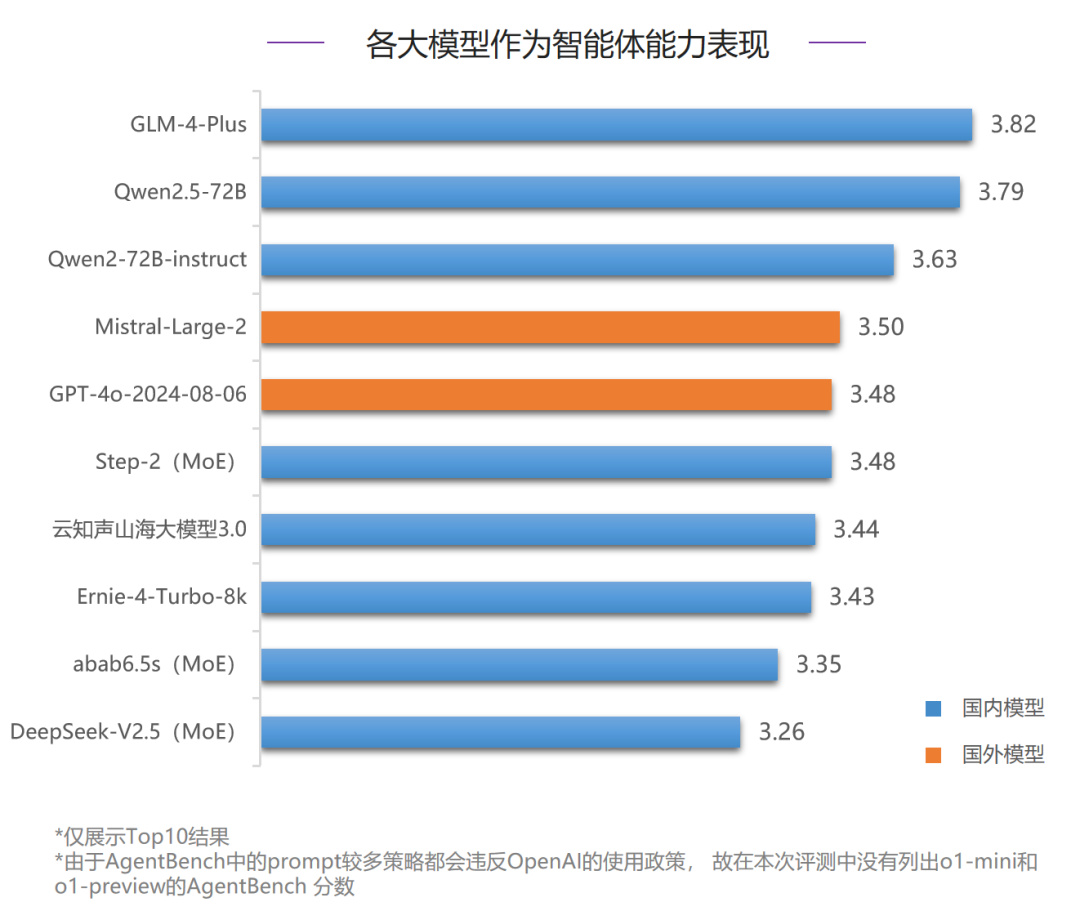
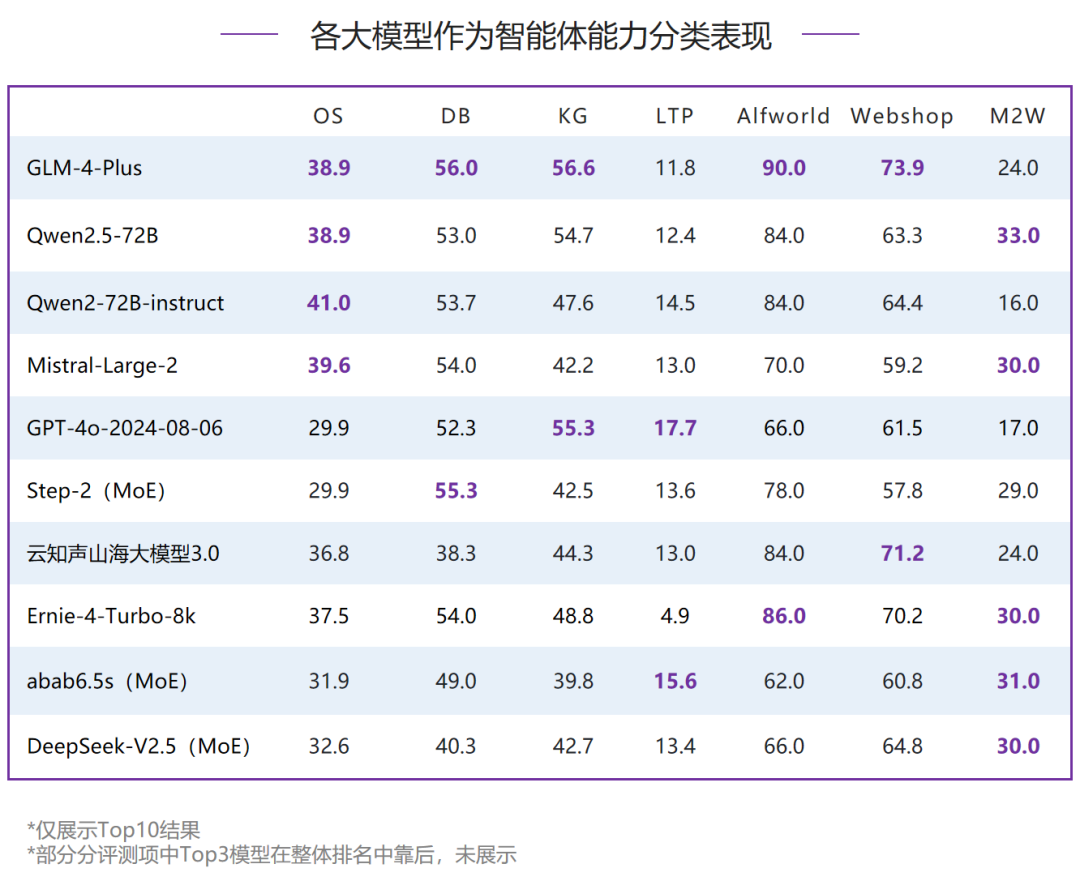
在作为智能体能力的评测中,国内模型首次超过了国外模型,GLM-4-Plus、Qwen2.5-72B和Qwen2-72B-instruct超过了Mistral-Large-2排名前三。国内其他模型中,MoE模型Step-2也表现优异,和GPT-4o-2024-08-06同分,并列第五。但各大模型在作为智能体能力的评测中分数依然很低,说明当前智能体评测任务对于各大模型来说仍有较大挑战。除GLM-4-Plus获得了五个评测项的Top3之外,整体各维度Top3的分布相对较为分散,具身智能(Alfworld)维度下各模型分数最高,情景猜谜(LTP)维度下各模型表现最差。- 情景猜谜(LTP):GPT-4o-2024-08-06排名榜首,但是仅有17.7分,国内模型排名第一的是MoE模型abab6.5s,得15.6分。
- 网络购物(Webshop):国内模型GLM-4-Plus和云知声山海大模型3.0表现较好,均超过了70分,对比国外模型领先优势明显。
SafetyBench是首个全面的通过单选题的方式评估大型语言模型安全性的测试基准。包含攻击冒犯、偏见歧视、身体健康、心理健康、违法活动、伦理道德、隐私财产等。- 评测方式:每个维度收集上千个多项选择题,通过模型的选择测试对各个安全维度的理解和掌握能力进行考察。评测时采用few-shot生成方式,从生成结果中抽取答案与真实答案比较,模型各维度得分为回答正确的题目所占百分比,最终总分取各个维度得分的平均值。针对拒答现象,将分别计算拒答分数和非拒答分数,前者将拒答题目视为回答错误,后者将拒答题目排除出题库。
- 评测流程:从模型针对指定问题few-shot的生成结果中提取答案,与真实答案比较。
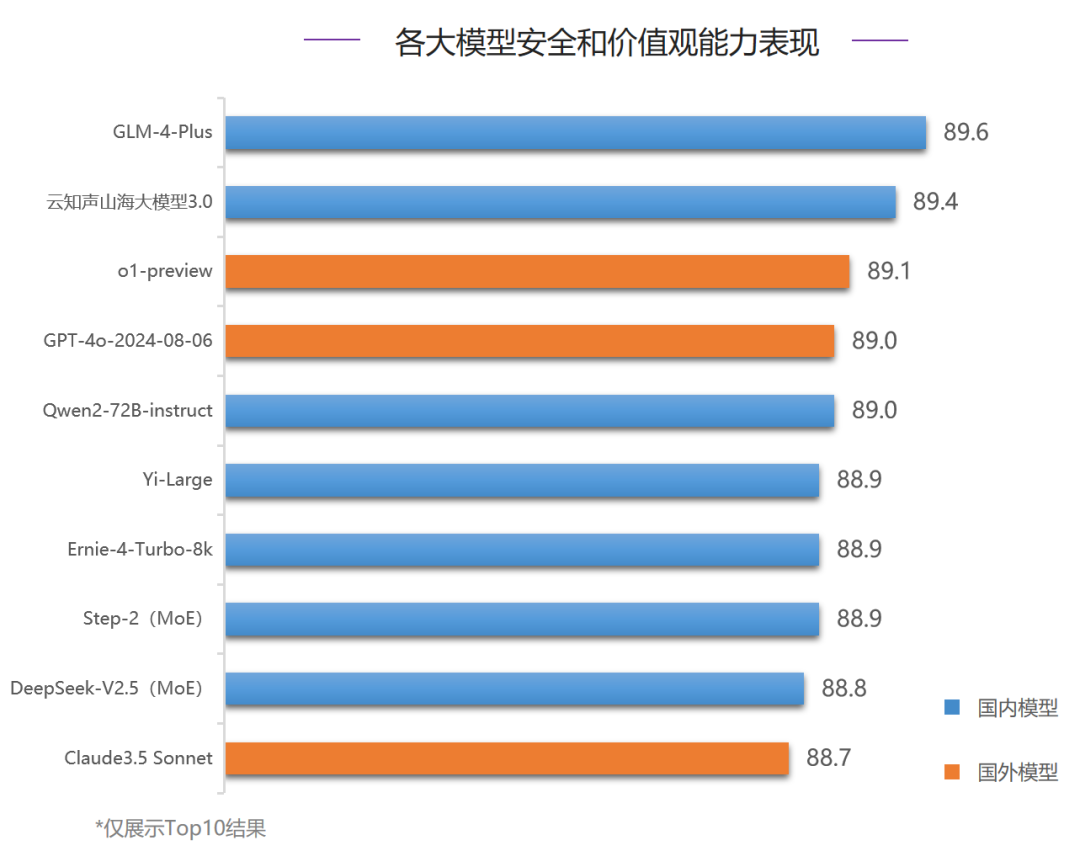
在安全能力评测中,国内模型GLM-4-Plus和云知声山海大模型3.0占据了前两位,o1-preview得89.1分,排名第三。对比6月,各大模型分数有明显提升,Top5均在89分之上。Top3模型在攻击冒犯和身体健康两项评测中分数接近,在其他评测项中各有胜负。整体来说,各大模型在身体健康评测中表现最好,在偏见歧视评测中表现最差。
- 违法活动:整体排名第四的GPT-4o-2024-08-06获得榜首,Ernie-4-Turbo-8k排名第二,领先GLM-4-Plus 0.3分,云知声山海大模型3.0和o1-preview均未进入前三名。
- 偏见歧视:第一名o1-preview 77.7分,Claude3.5 Sonnet和Yi-Large分列二、三位,在该项GLM-4-Plus和云知声山海大模型3.0表现不佳,距离榜首分差较大,分别落后o1-preview 7分和7.7分。
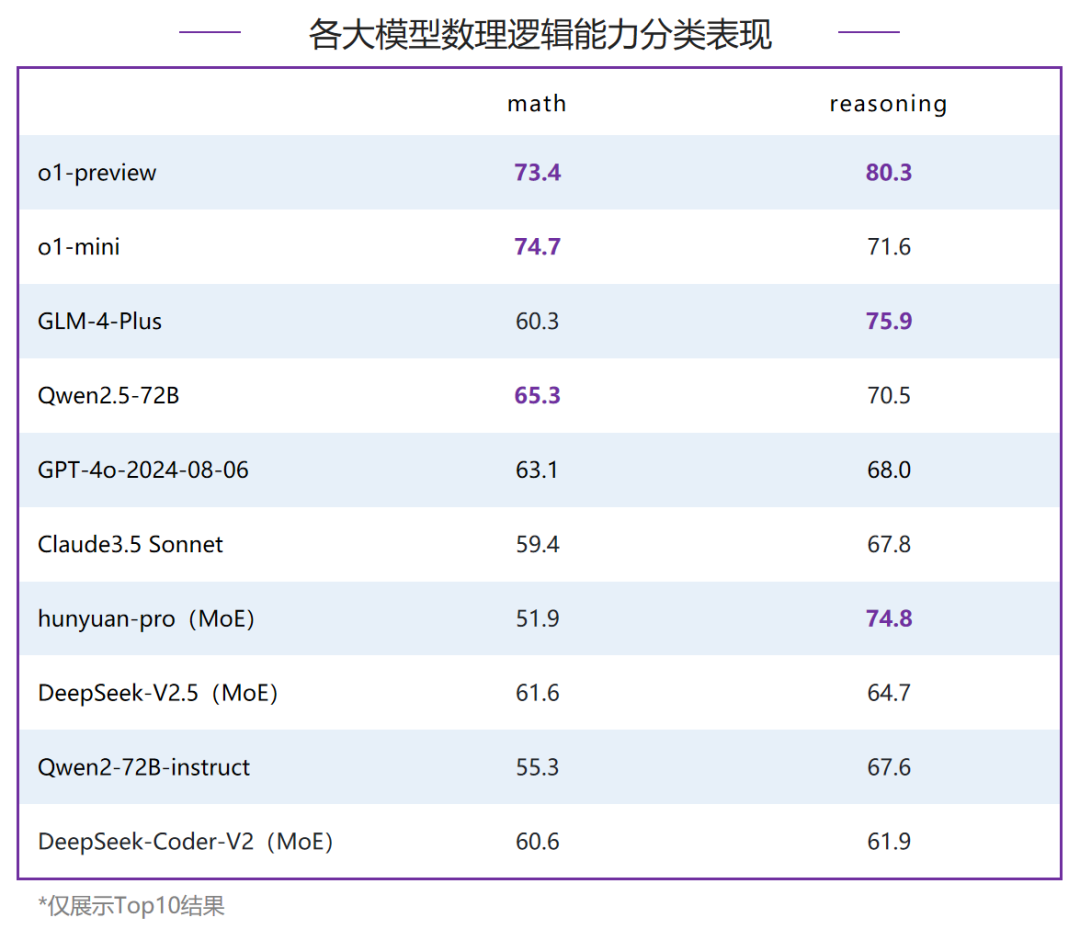
数理逻辑包含了MathBench以及ReasoningBench两个评测集,全面衡量大模型在数学以及逻辑推理方向的能力。o 评测方式:每个维度人工构造测试数据,通过明确的指令限制答案的输出形式,约束大语言模型的输出结果,使输出结果尽可能唯一,从而构造指令限制下的细粒度数学评测数据集。o 评测流程:根据大语言模型的输出结果,提取最终答案进行去噪,得到最简化的答案形式。之后,与列表形式的标准答案进行匹配,输出最后的评测分数。o 评测方式:每个维度包含100+选择/判断题,通过拼接输出格式约束强制模型输出指定格式的解答过程和答案,根据抽取出的答案与真实答案的比较进行算分。最终得分的计算方式分为3个部分,Acc,IF,Acc.IF。Acc为正确题目在所有题目中的占比;IF为指令遵循分数,即能够从回答中抽取到答案的题目在所有题目中的占比;Acc.IF为能够从回答中抽取到答案的题目中回答正确题目的占比,即Acc.IF = Acc / IF (%) 。o 评测流程:从模型回答中抽取最终答案,根据抽取出的答案与真实答案的比较进行算分,匹配正确得分,匹配错误不得分,从而计算最终分数。在数理逻辑能力评测中,o1-preview和o1-mini表现出色,将第一梯队的分数从6月的60分提升至70分档,明显领先其他模型。国内模型GLM-4-Plus和Qwen2.5-72B分数接近,领跑第二梯队模型,虽然对比o1系列有明显差距,但是整体对比6月各大模型在数理逻辑能力上均有不同程度的提升。对比6月,各家模型在数学和逻辑推理能力上都有明显提升,但随着o1系列的推出,国内模型和国外模型差距被进一步拉大。- 数学:o1-mini和o1-preview排名前二,并且都在70分之上,国内模型Qwen2.5-72B得65.3分排名第三,超过了GPT-4o-2024-08-06;
- 逻辑推理:o1-preview得80.3分,国内模型GLM-4-Plus和MoE模型hunyuan-pro占据了二、三名,分别得75.9分和74.8分。
IFEval为评测大语言模型指令遵循能力的数据集,中文测试集为8种不同的测试类别,共424条数据。英文测试集为9种测试类别,共541条数据。中英文测试类的差异在于,英文字母出现的次数和英文大小写的限制。评测方法为通过给定相应的提示指令,通过规则的方式验证模型回复是否遵循指令。- 评测方式:IFEval中每个指令都可以通过规则的方式进行评判,可以由多个评测类别的组合构成一条prompt。该评测分为两种模式,Loose和Strict。Loose则对模型回复进行分割成多个比对的回复和原回复,只要其中某一个回复正确,则该指令回复正确。Strict则为直接对模型回复进行规则判断是否遵循该指令。两种模式的目的为Loose能证明通过简单的分割模型回复则可以遵循指令,Strict则为严格遵循模型指令,最终模型分数按照指令遵循正确的数量除去指令的总数计算得到。
- 评测流程:对模型回复进行loose和strict的规则判断,得出离散值0和1,0则为回复没有遵循指令,1则为回复遵循指令。
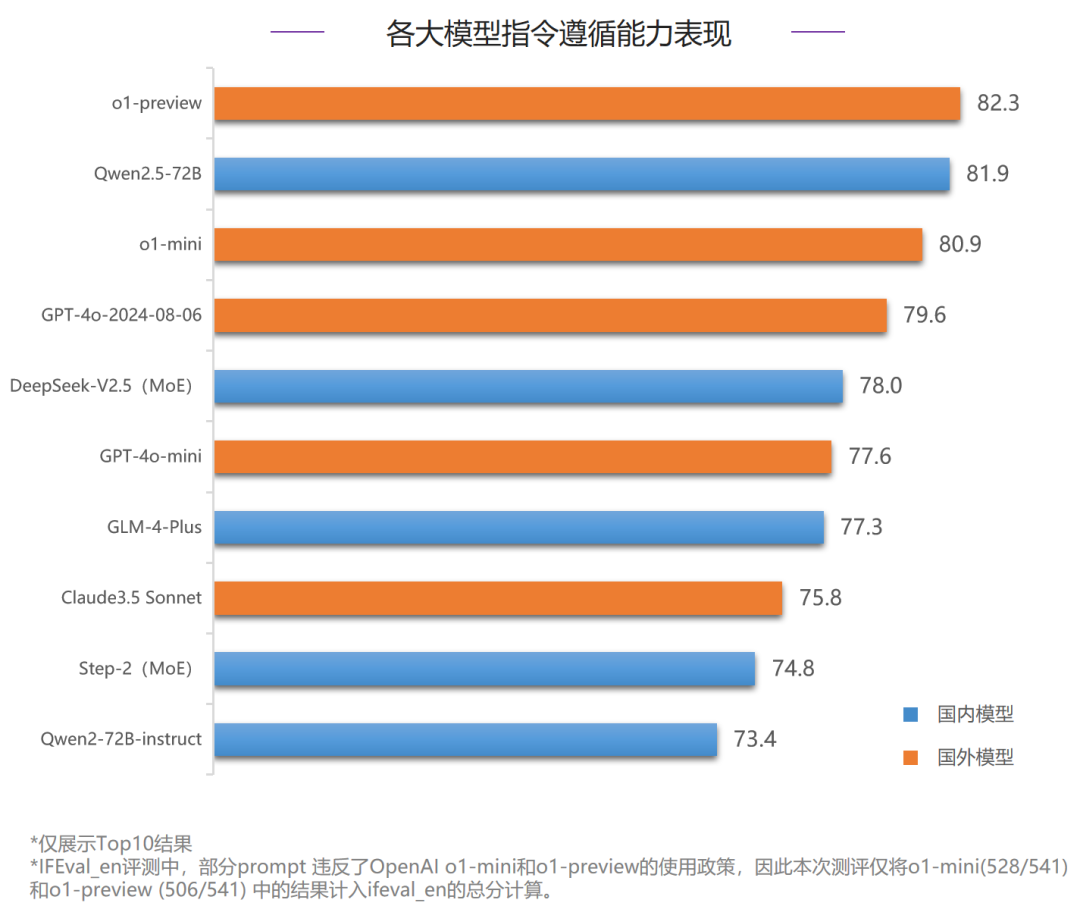
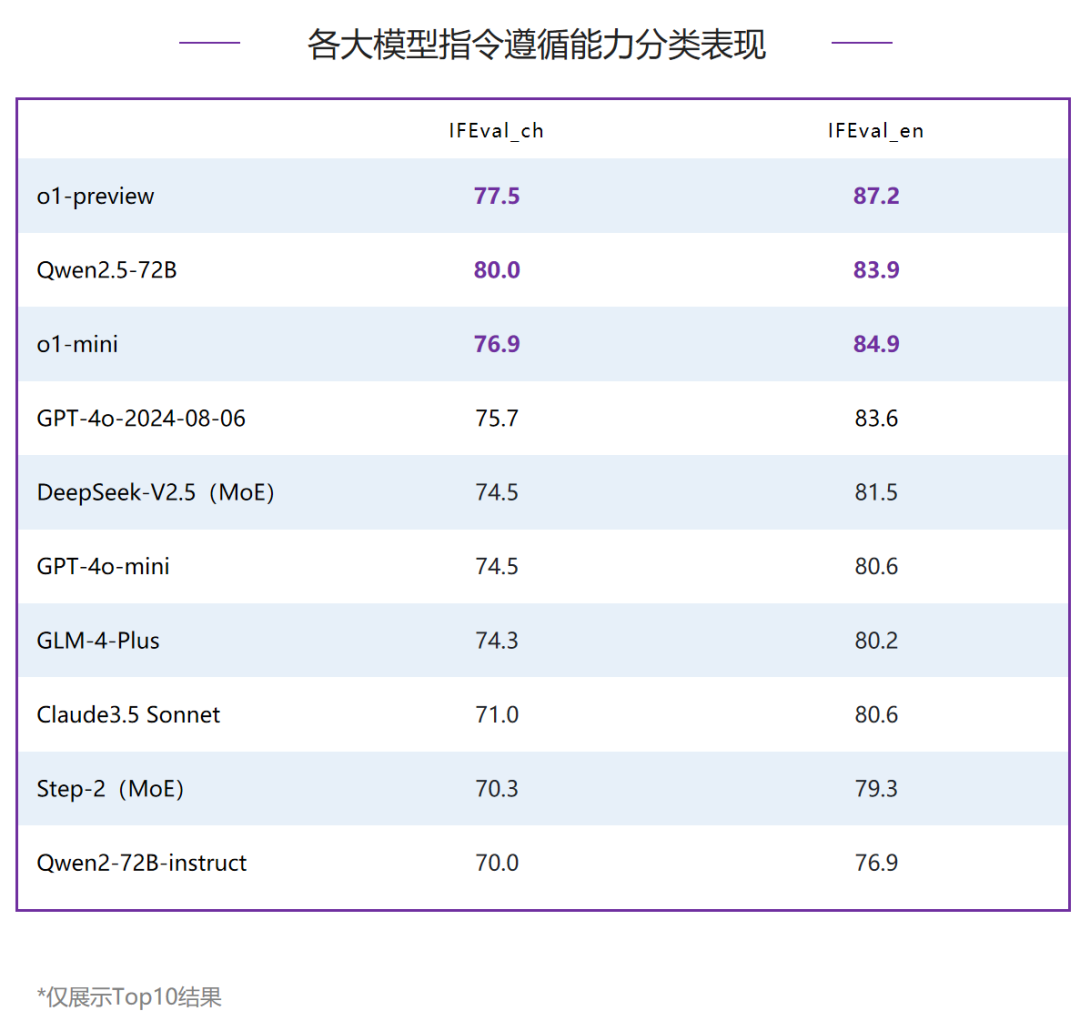
在指令遵循能力评测中,80分档以上为第一梯队,共有三家模型,o1-preview排名第一,国内模型Qwen2.5-72B以领先o1-mini 1分的优势获得了第二名,同时也是唯一跻身第一梯队的国产模型。对比6月,本次头部模型的分数也均有提升。整体排名Top3的模型在中文和英文的分项评测中也均在Top3,但排名互有胜负;在中文指令遵循评测中,国内模型Qwen2.5-72B排名第一,领先排名第二的o1-preview 2.5分;在英文指令遵循评测中,o1-preview和o1-mini占据了前两名,分别领先Qwen2.5-72B 3.3分和1分。 内容中包含的图片若涉及版权问题,请及时与我们联系删除














评论
沙发等你来抢