

- IROS 2024论文发布合辑-
科研成果速览


在即将举行的机器人研究领域的顶级学术会议2024 International Conference on Intelligent Robots and Systems(IROS, 10.14-18,阿联酋-阿布扎比)中,清华大学交叉信息院助理教授高阳、陈建宇、吴翼、许华哲各研究组共计发布7项最新科研成果:通过空间约束实现机器人通用操控能力的CoPa框架,可迅速对齐上层计划和下层执行的DoReMi机器人规划决策框架,使机器人能够快速自我生成有效训练数据的RST框架,以及在基于强化学习的足式机器人运动控制中引入对称性,结合行为克隆与强化学习的分层学习框架等创新成果,为机器人操作和人机协作等领域研究提供了新思路。
CoPa:基于基础大模型生成物体部件间空间约束的机器人通用操作框架
在机器人技术领域,适应复杂环境的操作能力是关键挑战之一。然而,操作任务中的每个低层控制指令的实现往往依赖于特定任务上的学习方法或人为定义的规则,因此需要大量的数据收集工作或人力付出,并且难以泛化到不同场景和任务。与此同时,在互联网规模数据上训练得到的基础大模型被证实隐含着对世界的广泛常识知识。研究者发现其在机器人操作的高层任务规划中的应用是十分有效的。而其在低层控制中的应用尚待研究。
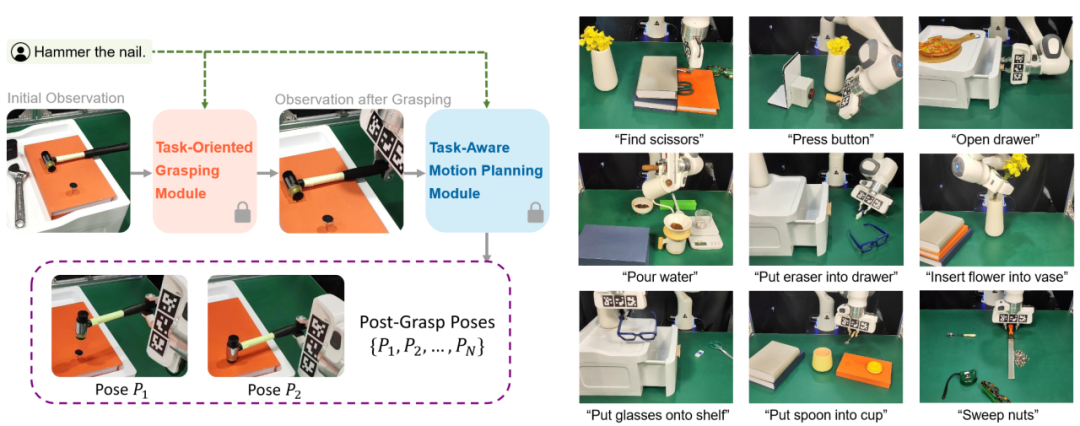
图|CoPa—利用基础大模型实现机器人通用操作
高阳研究组研究了这个问题,提出了“基于物体部位间约束的通用机器人工具操作框架”。此创新框架可以将大模型内嵌的常识运用到低层的机器人控制当中,通过物体部位间约束生成一系列末端执行器六自由度位姿,从而解决开放世界中的任务与物体操作任务,并且无需复杂的提示词设计和额外的训练。此外,该框架还可以与高层任务规划算法无缝衔接,完成如制作手冲咖啡和布置浪漫餐桌等长周期复杂任务。
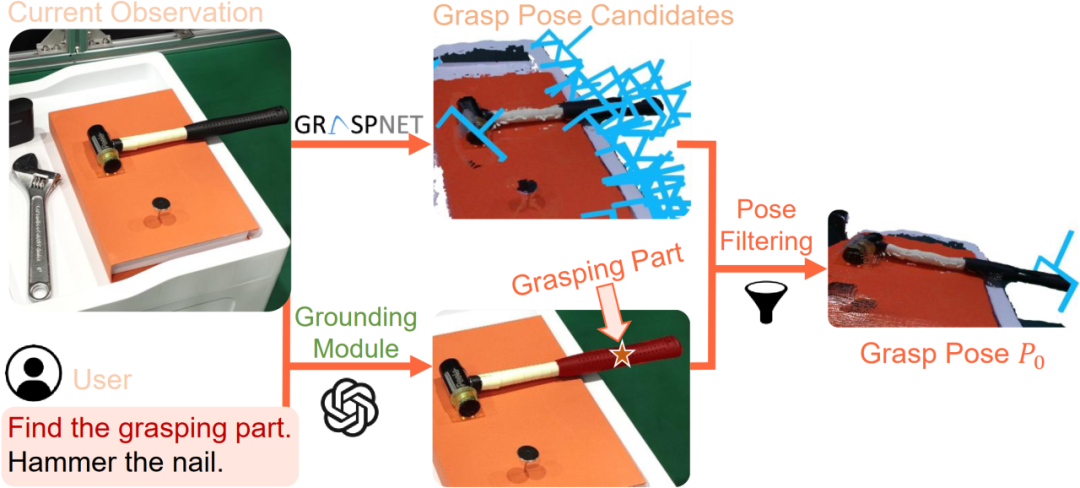
图| 任务导向抓取阶段示意图

图| 任务导向运动规划阶段示意图
CoPa将操作任务分成两个阶段:任务导向抓取阶段和抓取后任务导向运动规划阶段。在抓取阶段,抓取物体部位定位模块,利用视觉语言大模型定位待抓取物体部位的掩膜,用以过滤预训练抓取模型生成的候选抓取位姿,得到最终的任务导向抓取位姿。在任务导向运动规划阶段,先使用定位模块定位任务相关的物体部位;然后让视觉语言大模型描述部位间应当满足的空间几何约束;最后使用一个优化问题求解器解得目标位姿序列,使用路径规划算法得到运动轨迹。CoPa使用部位间空间约束作为连接视觉语言大模型和机器人的桥梁,可以很好地利用视觉语言大模型中的知识常识,并且具有精细的物理理解能力,同时又可以利用传统的控制算法,实现精准流畅的操作。
研究组在真机实验平台上验证了这个框架的有效性。CoPa在 10 个任务中取得了 63% 的平均成功率,显著高于基准方法 VoxPoser。在消融实验中,通过与 3 个变种的对比,展现了框架中视觉语言大模型、由粗到细的定位设计和空间约束的表示方式的重要性。最后,CoPa还与高层任务规划算法ViLa集成,完成了复杂长周期操作任务。
CoPa为机器人通用操作提出了一种新的可能。本论文共同一作为清华大学交叉信息院2024级博士生黄浩栩、林凡淇,通讯作者为高阳助理教授。其他作者包括交叉信息院2021级博士生胡英东、2023级博士生王圣杰。
项目论文:
CoPa: General Robotic Manipulation through Spatial Constraints of Parts with Foundation Models, Haoxu Huang, Fanqi Lin, Yingdong Hu, Shenjie Wang, Yang Gao†, https://copa-2024.github.io/, IROS 2024.
MQE:通过多智能体机械狗环境以展现机器人协作能力
机器人之间的合作能力是将机器人应用在现实生活中必不可少的要求,为了合作完成复杂的任务,或是降低多个机器人之间互相带来的负面作用,都需要机器人能够感知并且主动协作。近年来对于机械狗底层控制的研究在可并行的模拟器以及深度强化学习的帮助下取得了突飞猛进的发展,但由于动作空间的定义问题,在模拟器中往往只会考虑单只机械狗的情况,使得相关研究大多只能局限于机械狗的运动控制问题,与日常生活中的应用仍相去甚远。

图|多智能体机械狗环境中12个预定义的任务
高阳研究组提出了多智能体机械狗环境(Multi-agent Quadruped Environment),使得对该问题的研究变得可行。多智能体机械狗环境提供了一套模块化设计多机械狗任务的流程,使得在模拟器中加入多只机械狗,拼合提前定义好的地形,加入可以自行驱动的物体易于操作,为多智能体机械狗的研究提供了一个方便的平台。同时,多智能体机械狗环境定义了12个需要多只机械狗协作的任务,以探索不同多智能体强化学习(Multi-Agent Reinforcement Learning)算法在解决中的效果。

图| 协作成功与失败案例
在尝试解决这些定义好的任务时,研究组使用了分层强化学习,将控制多只机械狗完成任务拆成了控制机械狗以及多机械狗协作两个任务。首先训练一个接受连续指令的底层运动控制策略,再基于该策略训练一个发出显性指令的顶层策略,两个策略相结合以实现从顶层到底层对于机械狗的控制,极大地降低了学习难度。
研究在“爬跷跷板”以及“牧羊”等任务上验证了分层强化学习的有效性,相较于直接使用深度强化学习实现了从失败到成功的突破。虽然分层强化学习能够快速地解决部分问题,仍然存在对环境感知不足,底层控制策略不适配任务的问题。期待未来能够有更多相关研究。
多智能体机械狗环境有潜力加速机器人协作能力的发展。本论文第一作者为清华大学交叉信息院2020级本科生熊子言,通讯作者为高阳助理教授。其他作者包括北京邮电大学研究生陈波、博士生导师何召锋,智谱华章研究员黄世宇,第四范式研究员涂威威。
项目论文:
MQE: Unleashing the Power of Interaction with Multi-agent Quadruped Environment, Ziyan Xiong, Bo Chen, Shiyu Huang, Wei-wei Tu, Zhaofeng He, Yang Gao†, https://ziyanx02.github.io/multiagent-quadruped-environment/, IROS 2024.
DoReMi:基于检测和恢复的大语言模型规划框架
大语言模型涌现出对物理世界的认知和推理能力,非常适合帮助机器人完成上层规划。但是由于环境扰动和不完美的控制器,机器人的下层执行策略可能偏移语言模型的上层规划。
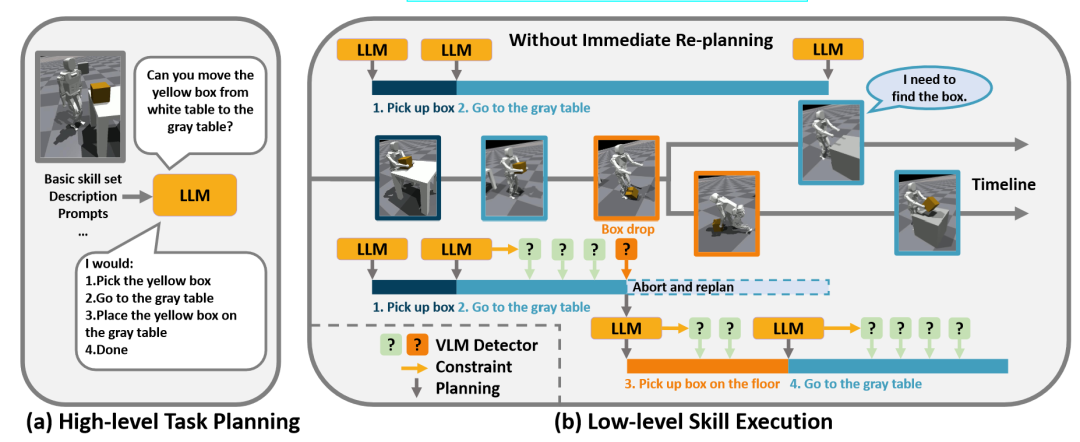
图 | DoReMi框架概览
陈建宇研究组探究了这个问题,提出一种新颖的框架来解决上层规划和执行不对齐的问题。基于语言模型的推理能力,在产生规划的同时,也让语言模型输出规划的约束。为了自动化地检测这些约束,研究组使用视觉语言大模型统一地检测各种约束。同时为了让视觉语言模型更好适配不同机器人型号,研究组使用少量数据对视觉语言模型进行微调,使得其回答更加准确。
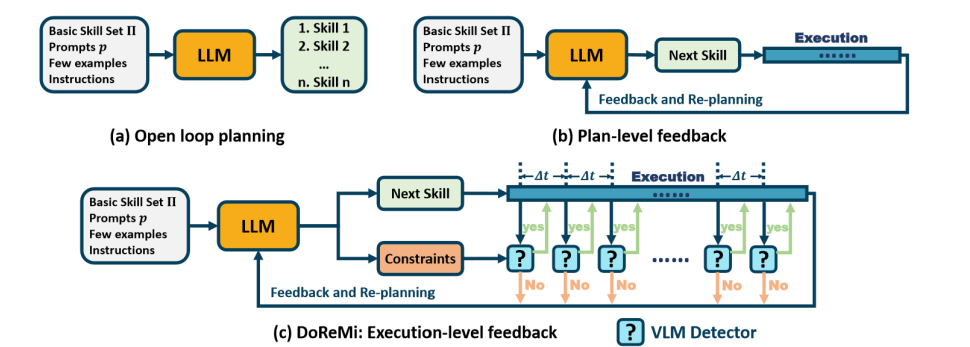
图|DoReMi使用LLM产生规划和约束,
并用微调的视觉语言模型检测异常
在实验中,研究组在仿真的机械臂环境,仿真的人型机器人环境都进行了大量实验,该框架展示了良好的恢复能力,能从各种异常中自动回复,例如可以自动从瘫倒的积木,掉落的物品等情况进行恢复,从而完成复杂的长时间域任务规划。

图|丰富的实验环境:仿真机械臂、仿真人型环境,小星人型机器人硬件平台
DoReMi有潜力发展为通用的规划-执行框架。论文共同第一作者为清华大学交叉信息院2022级博士生郭彦江、2021级硕士生王彦仁(现加州伯克利大学博士生),清华大学未央书院本科生查理涵(现普林斯顿大学博士生),通讯作者为陈建宇助理教授。
项目论文:
DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment, Yanjiang Guo*, Yen-Jen Wang*, Lihan Zha*, Jianyu Chen †, https://sites.google.com/view/doremi-paper, IROS 2024.
Whleaper:一款10自由度的高性能双腿轮足机器人
Whleaper的双腿轮足结构结合了足式机器人的灵活性和轮式机器人的高效性,既能够在复杂地形上展现出卓越的适应能力,同时在平坦地面上实现高效快速的移动。相比传统的轮式机器人,Whleaper具有更强的地形适应性,能够轻松越过障碍;而与纯足式机器人相比,其滑行模式则使得其在平坦地形上的速度和效率大幅提升。这种双模式的设计使得Whleaper不仅可以在多种环境中灵活自如地应对任务,还具备了执行复杂操作时的稳定性和可靠性。
相比传统的轮足机器人,Whleaper的10自由度设计,尤其是每条腿的髋关节拥有3个自由度,不仅扩展了机器人的运动姿态范围,还改善了在各种地形下的足地接触,能够实现更为精确的运动控制。
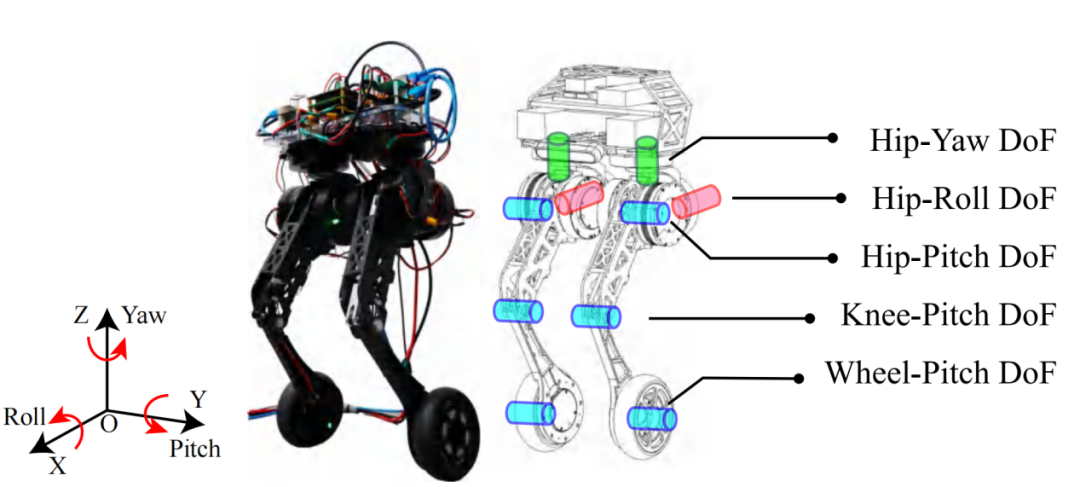
图 | Whleaper机器人的整体结构和自由度配置
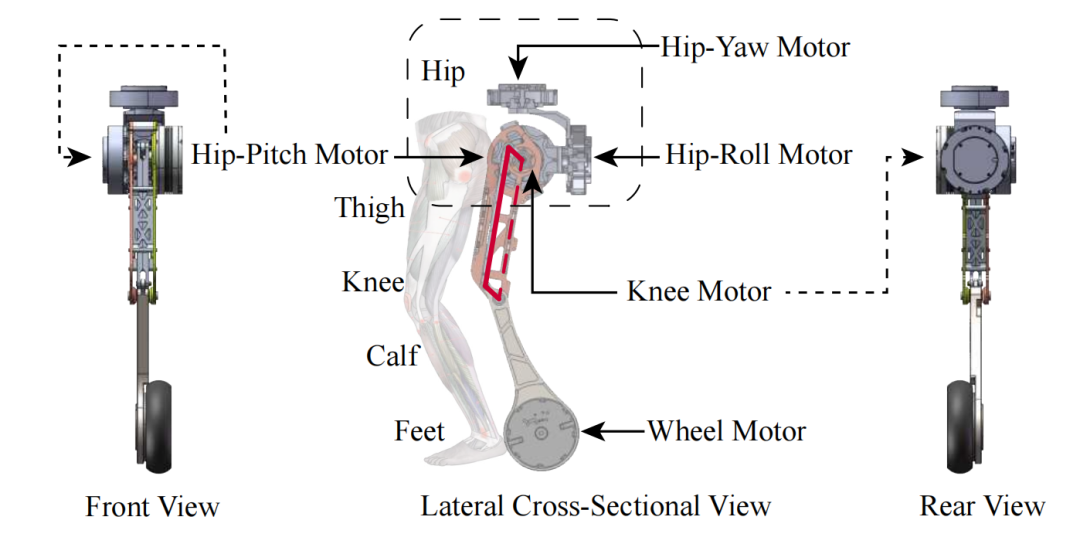
图 | Whleaper机器人的腿部结构
Whleaper的硬件系统集成了高精度IMU传感器、10台高扭矩电机以及高速的CAN和EtherNet通讯架构,确保其在实时环境中能高效进行反馈控制。
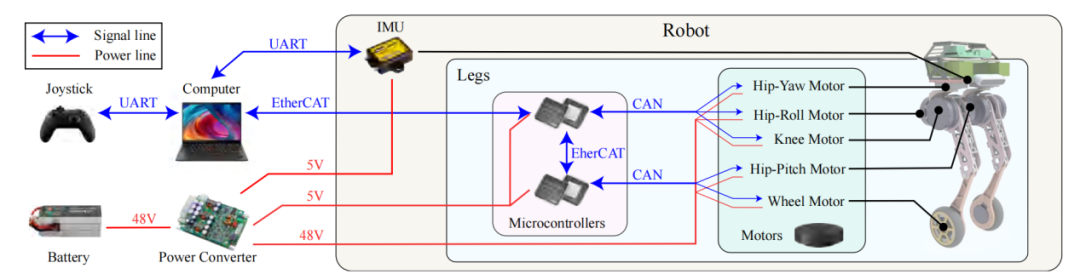
图|Whleaper 控制系统的硬件架构
Whleaper的控制系统集成LQR和RL算法,分别针对滑行、平衡控制以及行走、跳跃等运动任务进行了专门优化。LQR主要用于提升行进过程中的平衡性,RL则扩展了机器人运动模式,使其能够更灵活地应对多种复杂任务。
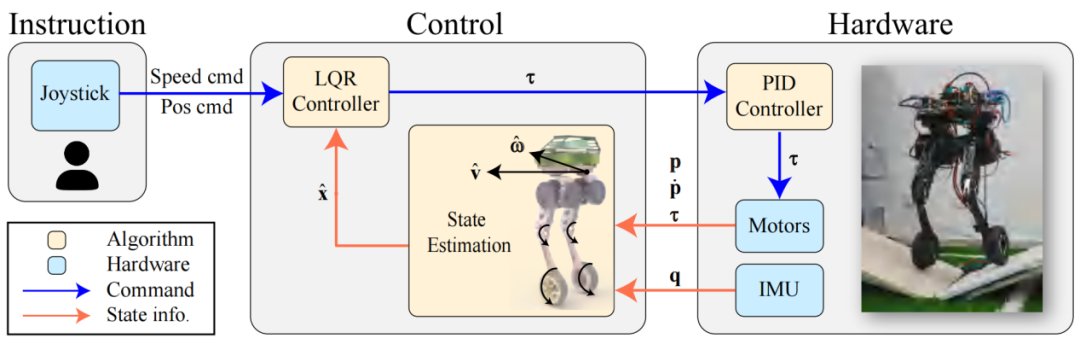
图|Whleaper 的控制框架
Whleaper具备出色的多模态运动能力,通过精细控制其10个自由度,能够灵活执行各种复杂的运动任务。对比实验结果表明,髋关节的高自由度设计显著提升了机器人的灵活性,使其在复杂场景中能够更高效地应对避障需求。
在实际场景中,Whleaper同样表现出色,能够顺利完成包括跨越障碍、快速转弯和避障滑行等动作,充分展示了其在多样任务和真实应用中的巨大潜力。该机器人专注于高自由度的结构设计及控制方法,也为双腿轮足机器人领域提供了新的发展思路。

图|Whleaper 机器人在不同自由度下的仿真实验

图| Whleaper 机器人在仿真与现实中的运动表现
本论文第一作者为清华大学博士生朱颖雷,清华大学本科生何思晓,通讯作者为陈建宇助理教授。其他作者包括清华大学本科生齐政皓,雍卓远,秦一骅。
项目论文:
Whleaper: A 10-DOF High-Performance Bipedal Wheeled Robot, Yinglei Zhu, Sixiao He, Zhenghao Qi, Zhuoyuan Yong, Yihua Qin, Jianyu Chen†, https://rasevents.org/presentation?id=146224, IROS 2024.
RST:通过机器人生成数据来学习可泛化的视觉机器人操作
在人工智能领域,基于海量数据预训练基础模型已成为一种流行趋势。然而,如何收集足够且高质量的机器人轨迹数据依然面临挑战。相比于图像或文本数据,机器人轨迹的收集更为昂贵,因为它们不仅需要涵盖机器人的状态信息,还必须包含有效的控制动作。传统方法往往依赖于人类专家进行数据收集,限制了数据的多样性和数量。
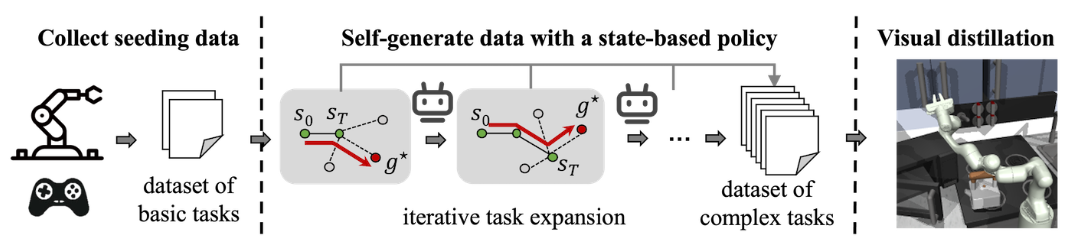
图 | RST框架概述
吴翼研究组研究了这个问题,并提出一种名为“机器人自我教学”(Robot Self-Teaching, RST)的框架,使机器人能够自我生成有效且丰富的训练数据,从而减少对于人类专家采集数据的依赖。研究组通过训练一个独立的数据生成策略,使机器人能够自动生成复杂性不断增加的轨迹数据。该方法首先从一个小规模的种子数据集中获取基本任务的示范,然后通过数据生成策略在状态空间中探索新任务。其关键创新在于引入了任务扩展机制,该机制利用数据生成策略的价值函数作为进展指标,逐步识别可达且具有挑战性的目标状态。通过不断发现和生成难度合适的新任务,RST框架实现了一个开放式的任务课程,使其最终学习到的视觉控制策略能够在零样本条件下,对从未见过的目标具有强组合泛化能力。

图|由RST框架产生的数据训练得到的可泛化操作策略在真实机器人上部署的效果
研究组在两个测试平台上验证了机器人自我教学框架。在一个包含多个长方体的物块堆积任务中,该方法从最初的单块移动数据集逐步生成建筑结构。当在设计新目标结构时,最终的视觉策略在零样本测试中取得了超过40%的成功率。研究组还在一个流行的离线强化学习基准“Franka厨房”中评估了此框架。其能够实现需要与厨房中四个组件互动的长期目标,而基于规划的离线强化学习基线则完全无法解决这些复杂任务。
RST框架赋予机器人在开放世界中的持续创新能力,对于自主生成机器人预训练数据有重要价值。本论文共同第一作者为清华大学交叉信息院2020级博士生李云飞、2020级本科生袁樱,通讯作者为吴翼助理教授。其他作者包括交叉信息院2024级本科生崔景植、2021级博士生傅炜、2023级博士生高嘉煊等。
项目论文:
Robot Generating Data for Learning Generalizable Visual Robotic Manipulation, Yunfei Li∗, Ying Yuan∗, Jingzhi Cui, Haoran Huan, Wei Fu, Jiaxuan Gao, Zekai Xu, Yi Wu†, https://irisli17.github.io/publication/iros24/rst.pdf, IROS 2024.
在基于强化学习的足式机器人运动控制中引入对称性
自然界中的动植物通常具有形态上的对称性,如左右镜面对称的人类和旋转对称的水母。同样,机器人也常常被设计为对称结构,最常见的是镜面对称。然而,现有的强化学习算法大多将机器人视为黑盒处理,忽视了其内部的对称性,这往往导致机器人产生不对称且不自然的动作。
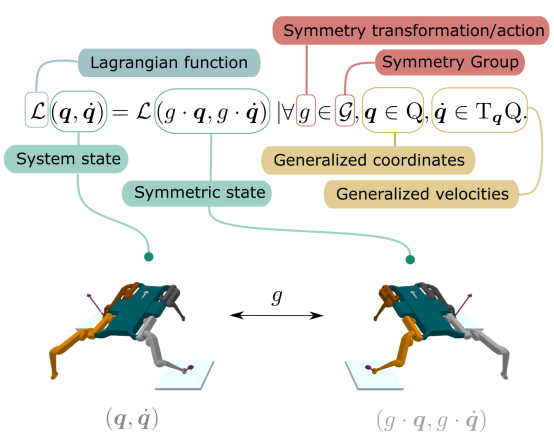
图 | 四足机器人的镜面反射对称性
吴翼研究组研究了这一问题,并探索了在强化学习中引入对称性的两种算法。第一种算法PPOaug通过数据增强(data augmentation)为PPO算法提供了对称性的软约束。第二种算法PPOeqic则直接强制约束策略神经网络(policy neural network)的等变性(equivariance)以及价值神经网络(value neural network)的不变性(invariance)。
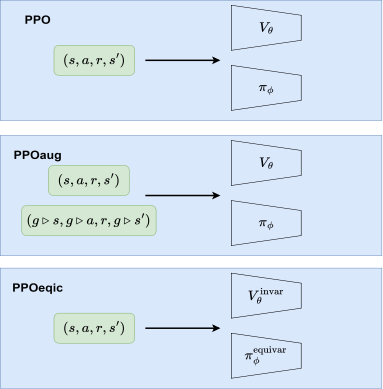
图|考虑对称性的强化学习算法PPOaug和PPOeqic
研究组在Isaac Gym仿真环境中设计了四个具有挑战性的双足运动和运动操控任务,以验证这两种算法的有效性。结果显示,PPOeqic不仅提高了训练的样本效率,还增强了控制策略的对称性和性能表现。
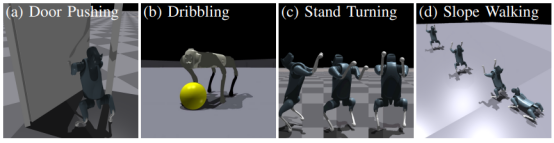
图|Isaac Gym 中的四个任务:推门、运球、二足旋转、二足斜面行走
此外,研究组还将这些在仿真中训练得到的控制策略部署到现实机器人上。结果表明,采用对称性策略的机器人能够实现从仿真到现实(sim-to-real)的无缝迁移,无需进一步的微调训练,同时在现实环境中展现出更对称、更鲁棒的表现。

图|训练得到的策略在现实中也能展现出更对称、更鲁棒的表现
本论文共同第一作者为清华大学交叉信息院2022级本科生苏智,加州大学伯克利分校博士生黄晓宇。其他共同作者为意大利技术研究院博士生Daniel Ordoñez-Apraez,清华大学交叉信息院2020级博士生李云飞,加州大学伯克利分校博士生李钟毓,清华大学助理教授吴翼等。通讯作者为加州大学伯克利分校教授Koushil Sreenath。
项目论文:
Leveraging Symmetry in RL-based Legged Locomotion Control, Zhi Su∗, Xiaoyu Huang∗, Daniel Ordoñez-Apraez, Yunfei Li, Zhongyu Li, Qiayuan Liao, Giulio Turrisi, Massimiliano Pontil, Claudio Semini, Yi Wu, Koushil Sreenath, https://suz-tsinghua.github.io/SymmLoco-page/
从示范中学习实现四足机器人移动操纵
四足机器人的移动能力近年来得到不断的提升,但在四足机器人技术中,同时实现移动与多任务的操控一直是一个巨大的挑战。传统方法依赖于机械臂来实现复杂的操控任务,这不仅增加了系统的复杂性,而且限制了机器人的运动能力。
针对这一问题,许华哲研究组提出了一个创新的分层学习框架,结合高层的视觉行为克隆规划器和低层的动态控制强化学习控制器,实现了四足机器人通过腿部执行复杂操控任务的能力。这种方法同时发挥了强化学习对高动态系统控制的优势,以及行为克隆对多任务学习的优势。
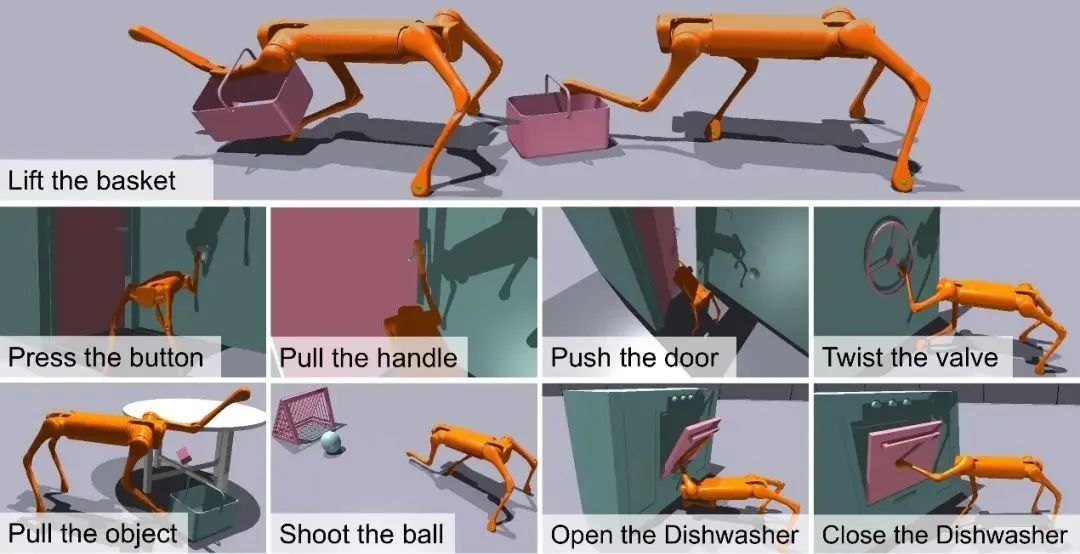
图 | 训练机器人完成的9个运动操作任务概述
同时,模仿学习的算法通常需要大量的数据收集和测试,这在真实环境中执行时成本高昂且效率低下。为了解决这一问题,我们的研究组在仿真环境中通过大规模并行仿真采集数据,通过模拟复杂的操纵任务来生成大量的训练数据。利用这些数据,我们训练了能够精确规划和执行复杂移动操纵任务的模型。然后,通过简单的后处理,我们将现实和仿真中的点云进行对齐,实现了仿真到现实的迁移。
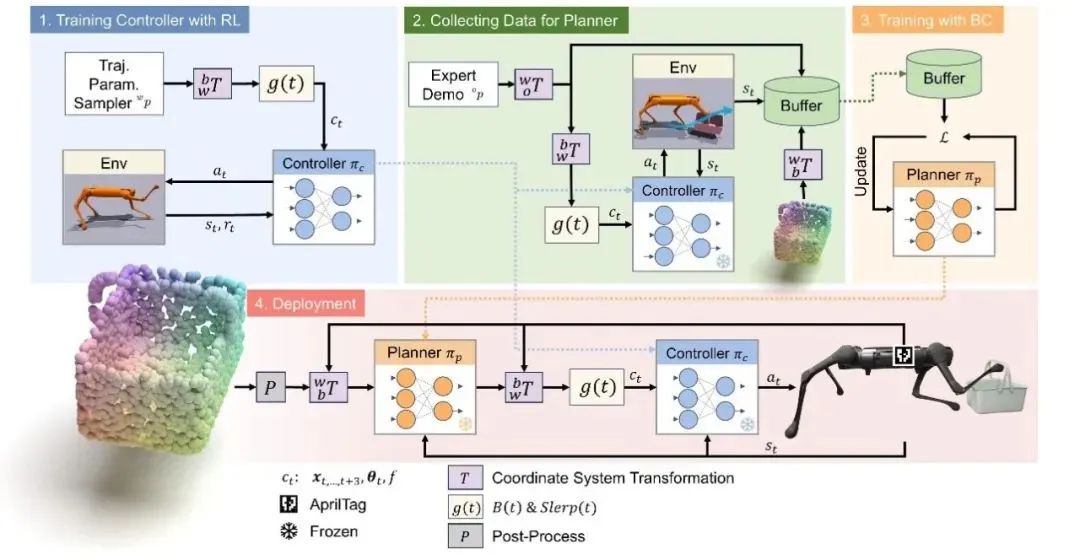
图|分层学习框架示意图
为了验证研究组提出的框架有效性,研究组根据足式操纵器的运用场景和实际需求,设计了9个不同的任务,包括提篮子、踢足球、推门等,并在Isaac Gym仿真器钟进行了实验。结果表明,许华哲研究组的方法效果在所有任务上都优于3个基线。
本研究有潜力加速足式机器人多任务操作技能的发展。本论文第一作者为上海期智研究院实习生何政茂,通讯作者为许华哲助理教授。其他作者包括上海期智研究院硕士后雷坤、学士后迮炎杰,加州大学伯克利分校副教授Koushil Sreenath,加州大学伯克利分校博士生李钟毓。
项目论文:
Learning Visual Quadrupedal Loco-Manipulation from Demonstrations, Zhengmao He, Kun Lei, Yanjie Ze, Koushil Sreenath, Zhongyu Li, Huazhe Xu†, https://zhengmaohe.github.io/leg-manip, IROS 2024.
编辑 | 姜月亮
审核 | 吕厦敏
学术顾问 | 高阳、陈建宇、吴翼、许华哲

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢