
1. 概述
阿里妈妈智能创作与AI应用团队近期开源了两项 FLUX 文生图模型的的实用配套模型。Black Forest Lab 的 FLUX [1] 文生图模型具有更高的生成画面质量和指令遵循能力,一经推出便受到业界广泛关注,也有很多优秀的控制插件和 Lora 微调模型陆续跟进。但是,通过修复(Inpainting)进行可控生成的插件还未有公开可用的模型,另一方面 FLUX 12B 的参数量会带来显著的推理时耗和计算开销。
我们针对这一行业需求进行了相关探索,开源了两个基于FLUX(FLUX.1-dev)的配套模型:ControlNet 图像修复模型 以及 8步加速的 Turbo 模型。更进一步,两个模型可互相兼容配合使用,达到更快的修复生图。两项开源模型收到了社区积极反馈,在 HuggingFace 社区居于趋势榜前列。本文介绍基于 FLUX 的 ControlNet 修复模型及蒸馏加速模型的设计思路,欢迎阅读交流和试用反馈。
🏷 FLUX修复ControlNet主页(已更新至Beta版本):
Huggingface地址:https://huggingface.co/alimama-creative/FLUX.1-dev-ControlNet-Inpainting-Beta
ModelScope地址:https://www.modelscope.cn/models/alimama-creative/FLUX.1-dev-ControlNet-Inpainting-Beta
🏷 FLUX8步加速LoRA主页(Alpha版本):
Huggingface 地址:https://huggingface.co/alimama-creative/FLUX.1-Turbo-Alpha ModelScope 地址:https://www.modelscope.cn/models/alimama-creative/FLUX.1-Turbo-Alpha
2. 图像修复 ControlNet模型
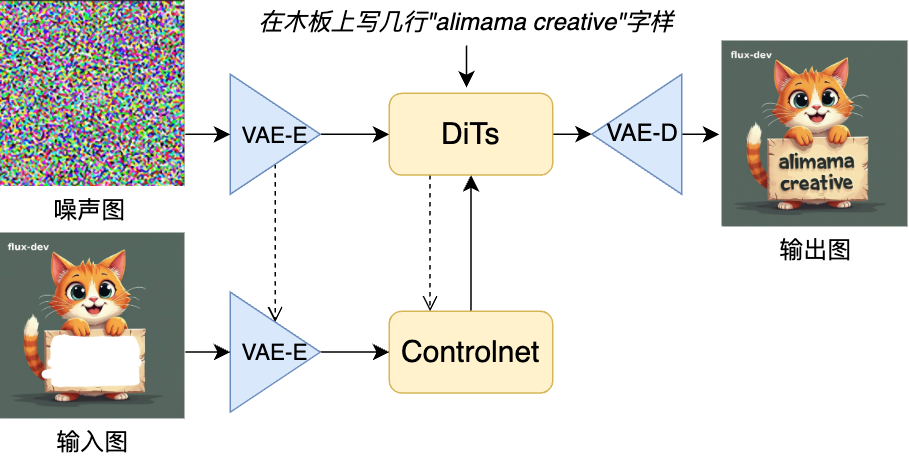
图像修复(Image Inpainting)对图像的指定区域根据指令进行重新生成。在创意设计领域,设计师可以利用该模型快速修复或改变图像中的特定元素;在个人照片编辑领域,普通用户可以轻松去除照片中不想要的元素或添加新的内容。毫不夸张地说,图像修复的 ControlNet 是 FLUX 基础模型用于图像可控生成的关键插件,同时相较于其他控制条件(线稿、姿势、深度图等)有较高的训练难度,对模型在丰富场景中的泛化能力、预测合理性和稳定性有较高要求。
因此,我们从 FLUX 模型采用的 DiT 模型结构和 Flow Matching [2] 训练机制出发,在嵌入的ControlNet模型结构和训练流程方面进行尝试。
2.1 ControlNet模型结构探索
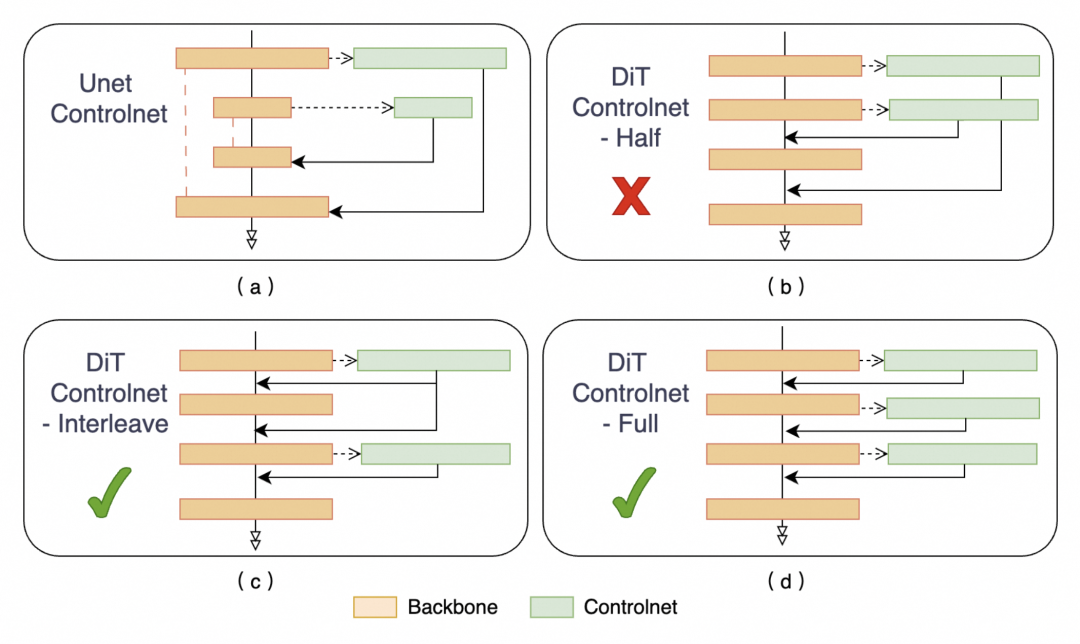
社区普遍使用的 Unet ControlNet [3] (图a) ,直接迁移到 DiT 架构上需要将前一半的特征加到后一半上面。不同于传统的基于 Unet 的文生图结构,DiT 的文生图模型由一系列的 Transformer Block 堆叠而成,没有显式的 Encoder-Decoder 结构,因此直接迁移效果不好。我们在同样是 DiT 框架的 SD3 Inpainting 上实验发现,更多控制层数的 Full 结构相较于 Half 与 Interleave 结构收敛更快。由于训练时显存限制,FLUX 的Inpainting 采用 Interleave(图c)结构进行训练,在模型收敛效果和显存&计算量取得平衡。
2.2 由粗到细的多阶段训练
从公开的图文对数据集和内部数据集过滤出千万量级数据用于训练,并对其中的图片通过多模态大模型进行长Caption重打标。我们先在768分辨率进行训练得到Alpha版本,然后在1024分辨率进行继续训练得到 Beta 版本。相比于 Alpha 版本相比,Beta 图像修复模型提升了以下特性:
1)从768图像分辨率升级到1024:能够直接处理和生成1024x1024分辨率的图像,无需额外的放大步骤,提供更高质量和更详细的输出结果。得益于多通道VAE的强大重构能力,生成的结果中非重绘区域依然能高保真复原。
2)增强细节生成:经过微调以捕捉和重现修复区域的更精细细节。
3)改进提示词控制:减少额外的控制信号对 FLUX.1 底模能力的影响,使模型对生成内容提供更精确的控制。
2.3 修复效果对比
我们对比 Diffusers 官方开源的基于 SDXL 的 Inpainting 模型 [4],FLUX-Inpainting 模型继承了 FLUX 更好基础能力,在指令跟随、文字生成、画面效果方面都有突出优势,其中最新的 Beta 版相比一个月前的 Alpha 版效果有进一步提升。以下是对比结果(均没有进行原图贴回操作):

与其他扩散模型一样,直接使用Inpainting模型仍需进行多步迭代推理(28步)才能达到比较满意的结果,为加快推理速度,我们进行了加速扩散方法的尝试。
3. 蒸馏加速模型
扩散模型由于需要多步去噪的推理生成方式,使得图片生成速度缓慢,计算资源需求高。尤其是对于 FLUX 模型来讲,其高达12B的参数量,在实际使用中具有较大困难。针对推理加速这个问题,已经有不少优秀的工作在 SD1.5 或 SDXL 上进行了降低采样步数的相关研究,但是对于 Flux 的相关加速工作还较少。
由此,阿里妈妈智能创作与AI应用团队探索训练出了一个8步蒸馏模型,使得 FLUX 在8步的采样步数下,接近原本 FLUX 30步左右推理的效果,我们的模型对于修复也适配良好,能够在接近原修复质量的同时实现更快的推理。
3.1 技术介绍
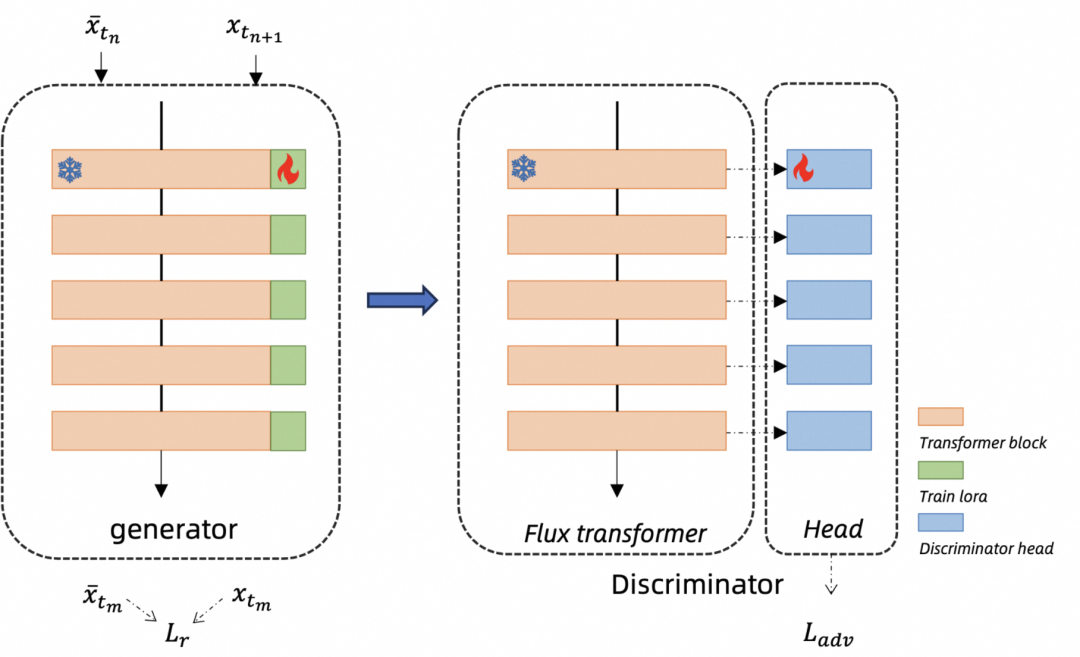
我们采用改进的一致性蒸馏算法 [5],并使用了对抗训练来提升蒸馏的效果。对于对抗训练所需的判别器模型,我们设计了一种多头的判别器模型,在固定原始 FLUX 的 Transformer 的权重,在每一层 Transformer Block 后接一个可训练的由几层 MLP 构成的 Head,如图所示。判别器的输出由所有Head的均值决定,这样的Head设计,充分利用了FLUX Transformer 的不同层级特征,能够更加有效的监督蒸馏后的效果。
3.2 效果&加速对比
我们在文生图任务上进行了尝试,对比原始 FLUX.1-dev 28步的结果,我们 8步 LoRA加速后的结果几乎逼近原始结果。可以看到,我们的模型在通用场景、人像场景、电商场景都取得了不错的效果。

4. 图像修复叠加蒸馏加速
我们的加速模型配合修复模型能够在接近原始修复效果的情况下实现更快的修复速度。在H20机器,使用 T5xxl-fp16 结合 FLUX.1-dev-fp8 模型进行测试,在 true_cfg 设置为1的情况下,原始 30step 需要约26s,叠加加速模型后只需要约8s,推理速度提升了约三倍,效果损失微小。

5. 总结
本文介绍了阿里妈妈技术团队基于 FLUX 开发的 Controlnet 修复模型和蒸馏加速模型,该项工作填补了社区空白并提升了 FLUX 的实用性和效率。未来,我们将着力提高复杂纹理和结构的理解生成能力,增加多尺寸支持,探索4步生图的加速方案。我们相信,持续创新将使 FLUX 在AI创意生成等众多领域发挥更大潜力。也期待通过社区的力量,共同加速模型能力的迭代,发现更多应用场景,创造更多可能。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入我们!
✉️ 简历投递邮箱:alimama_tech@service.alibaba.com
▐ 引用
[1] https://github.com/black-forest-labs/flux
[2] Lipman Y, Chen R T Q, Ben-Hamu H, et al. Flow matching for generative modeling[J]. arXiv preprint arXiv:2210.02747, 2022.
[3] Zhang L, Rao A, Agrawala M. Adding conditional control to text-to-image diffusion models[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 3836-3847.
[4] https://huggingface.co/diffusers/stable-diffusion-xl-1.0-inpainting-0.1
[5] Luo S, Tan Y, Huang L, et al. Latent consistency models: Synthesizing high-resolution images with few-step inference[J]. arXiv preprint arXiv:2310.04378, 2023.

也许你还想看

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢