
论文名称:Reinforcement Learning Control of Constrained Dynamic Systems with Uniformly Ultimate Boundedness Stability Guarantee
作者:Minghao Han, Yuan Tian, Lixian Zhang, Jun Wang, Wei Pan
提交日期:2020.11.13
论文链接:https://arxiv.org/abs/2011.06882
推荐理由:
作者提出了一种基于数据的方法来分析学习控制系统的统一极限有界稳定性。 根据理论结果,开发了两种无模型的强化学习算法,即Lyapunov安全行为准则和Lyapunov约束策略优化。 所提出的算法是在一系列具有安全约束的机器人连续控制任务上进行评估的。 与现有的RL算法相比,该方法可以可靠地确保各种挑战性连续控制任务的安全性。 作为稳定性的定性评估,在存在外部干扰的情况下,该方法显示出不错的稳定性。
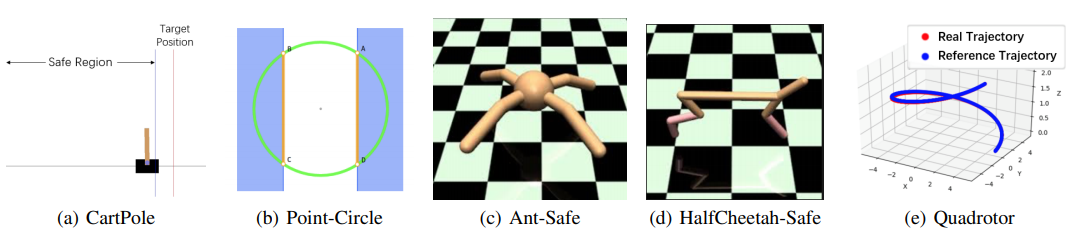 强化学习(RL)有望解决复杂的随机非线性控制问题。在不使用数学模型的情况下,可以通过反复试验从某些性能标准评估的数据中学习最佳控制器。但是,基于数据的学习方法因不能保证稳定性而臭名昭著,这是任何控制系统的最基本属性。本文在理论结果的基础上,提出了一种新的基于数据的基于UUB的定理,基于行为者批评算法和策略优化算法,分别提出了基于策略的偏离策略,以学习具有UUB保证的控制器。 本文的贡献可归纳如下:提出了一种新颖的,有原则的方法来构造基于数据的Lyapunov函数,以分析以MDp为特征的随机非线性系统的闭环稳定性。概括了UUB的经典定义以处理控制任务。 在状态上具有安全约束实用算法旨在通过UUB保证来搜索最佳安全策略,同时在学习和开发过程中保证安全。与现有的RL算法相比,该方法在保持安全性方面可以达到较高的性能。作为稳定性的定性评估,在存在外部干扰的情况下,该方法显示出了不错的抗性。
强化学习(RL)有望解决复杂的随机非线性控制问题。在不使用数学模型的情况下,可以通过反复试验从某些性能标准评估的数据中学习最佳控制器。但是,基于数据的学习方法因不能保证稳定性而臭名昭著,这是任何控制系统的最基本属性。本文在理论结果的基础上,提出了一种新的基于数据的基于UUB的定理,基于行为者批评算法和策略优化算法,分别提出了基于策略的偏离策略,以学习具有UUB保证的控制器。 本文的贡献可归纳如下:提出了一种新颖的,有原则的方法来构造基于数据的Lyapunov函数,以分析以MDp为特征的随机非线性系统的闭环稳定性。概括了UUB的经典定义以处理控制任务。 在状态上具有安全约束实用算法旨在通过UUB保证来搜索最佳安全策略,同时在学习和开发过程中保证安全。与现有的RL算法相比,该方法在保持安全性方面可以达到较高的性能。作为稳定性的定性评估,在存在外部干扰的情况下,该方法显示出了不错的抗性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢