


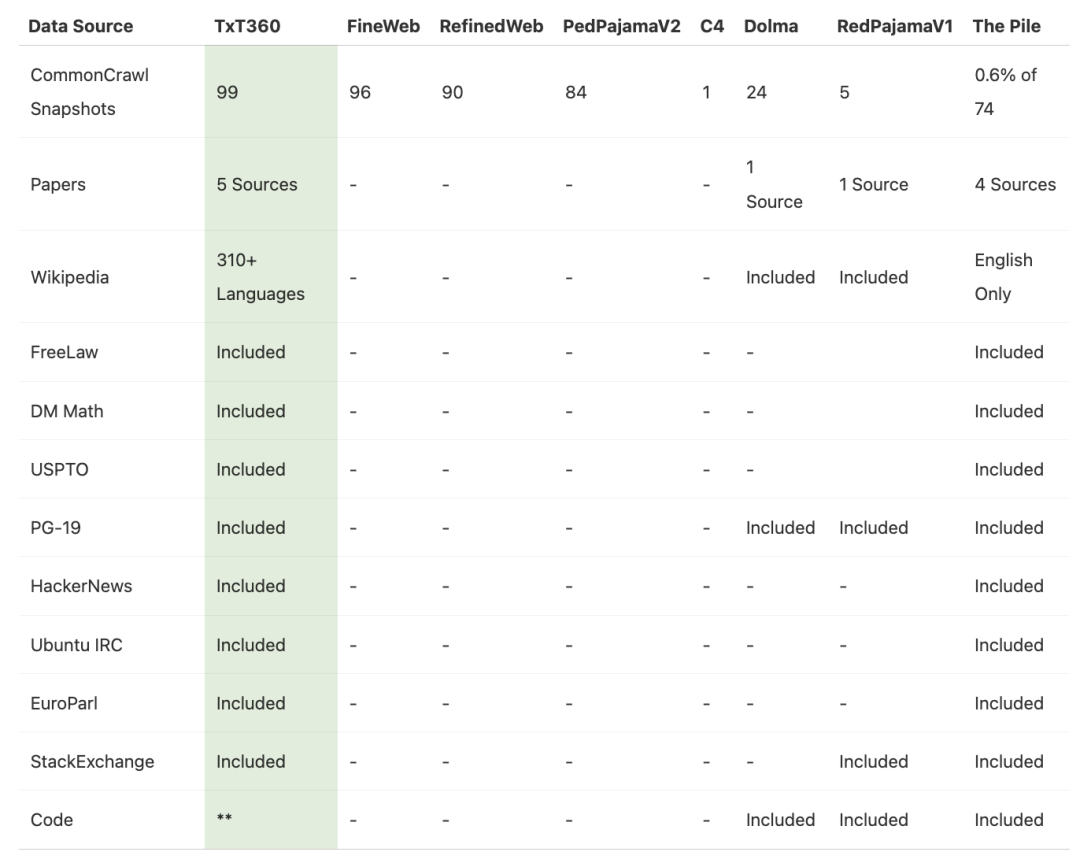
LLM360 是由 Petuum 和 MBZUAI 创建的开源大型语言模型项目、社区和不断发展的最佳实践及资源框架,现在隶属于该大学的基础模型研究所。该项目不仅分享其研究人员开发的模型和数据集,还分享详细的见解和方法论。 TxT360 数据集旨在通过提供大量高质量、多样化的数据来预训练大型语言模型。LLM360 研究人员设计了一个全面的数据处理流水线,用于清理数据并从 99 个 CommonCrawl 快照以及其他 14 个高质量来源中去除重复数据。 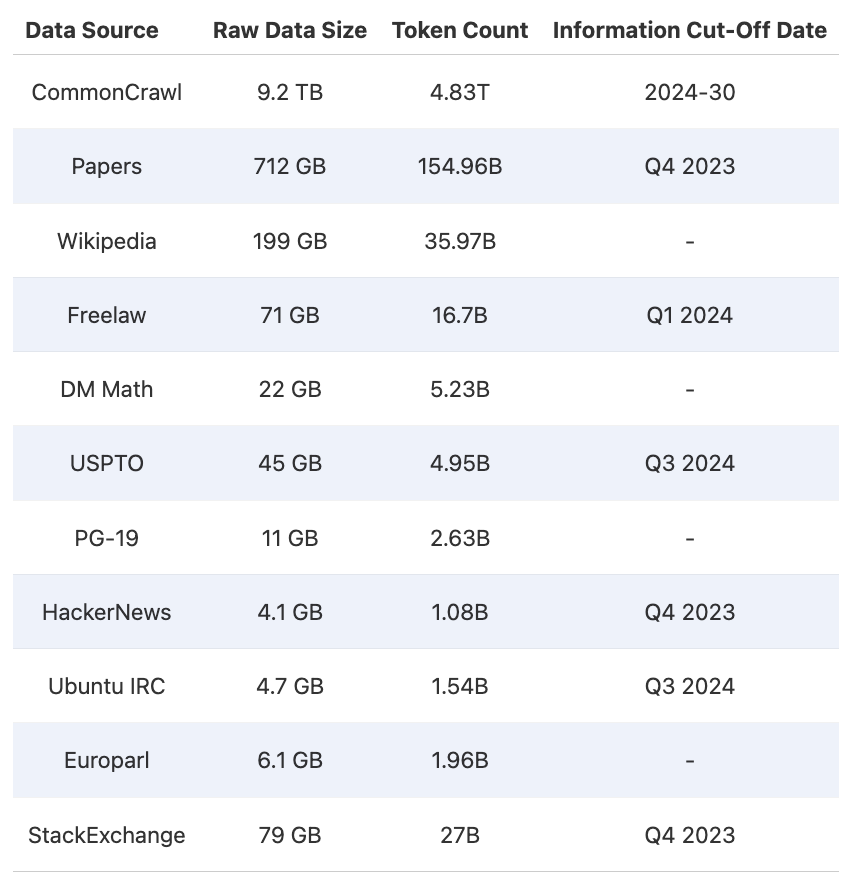
研究人员还特别关注数据加权(即了解哪些数据更重要,或对创建良好数据集至关重要)。通过一个简单但有效的上采样方法,创建了一个超过 15 万亿个 token 的语料库,该语料库在多个关键指标上优于之前的最佳数据集 FineWeb 15T(https://huggingface.co/datasets/HuggingFaceFW/fineweb)。 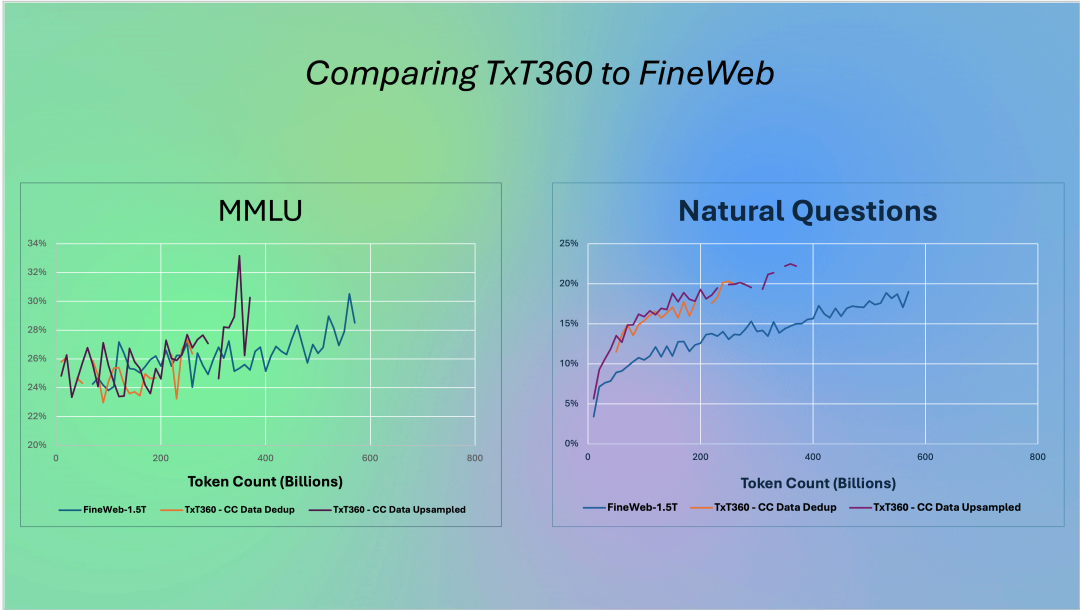
TxT360中存储了丰富的元数据,使得预训练者能够更精确地控制数据分布,从而探索更先进的加权技术,这是之前预训练数据集中不常具备的功能。 LLM360记录了所有详细的步骤、决策理由、统计数据、代码(即将发布)、分析结果等,为 LLM 开发者提供了一种宝贵的资源。该项目还提供了迄今为止最详细的关于预训练数据集管理的技术博客。 TxT360 目前在 Hugging Face 的超过 22 万份数据集列表中排名第一。
相关链接
TxT360,https://huggingface.co/spaces/LLM360/TxT360
LLM360 网站,https://www.llm360.ai/
LLM360 社区,https://huggingface.co/LLM360
LLM360 代码仓库,https://github.com/LLM360
(本文由OneFlow编译发布,转载请联系授权。原文:https://substack.com/@middleeastainews/p-150351752)
其他人都在看
邀请越多,Token奖励越多
siliconflow.cn/zh-cn/siliconcloud
扫码加入用户交流群

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢