

- CoRL 2025论文发布合辑-
科研成果速览


在即将举行的机器人研究领域的顶级学术会议2024 Conference on Robots Learning中,清华大学助理教授赵行、高阳、陈建宇、许华哲各研究组共计发布9项最新科研成果。人形机器人跑酷,带有基础先验的强化学习框架,通过层次化的机器人变压器模型增强机器人操作控制,跨多种视觉干扰类型进行泛化的通用框架等创新成果,为机器人操作和人机协作等领域研究提供了新思路。本期呈现陈建宇、许华哲助理教授研究组成果。
HiRT:基于分层机器人变压器的机器人操作控制框架
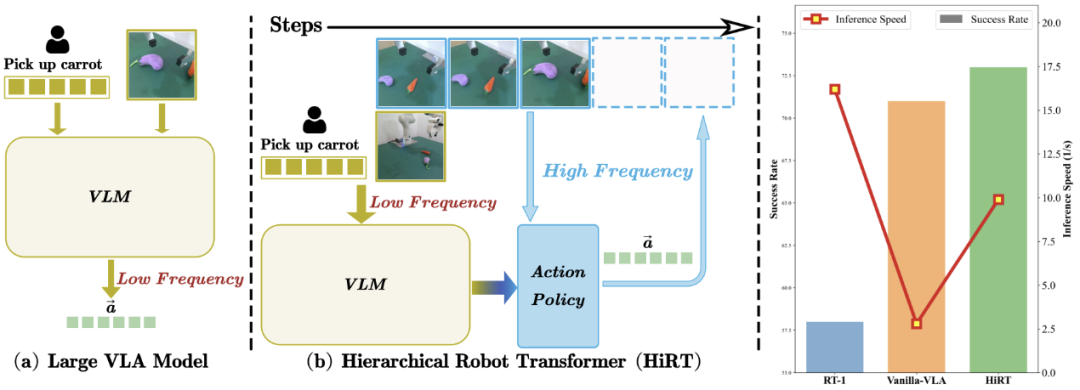
图| HiRT通过层次化变压器模型来解决大模型推理慢的问题
大型视觉语言模型(VLM)虽然在机器人控制中展现了巨大的潜力,但由于大模型计算成本高、推理速度较慢,可能导致机器人动作延迟,执行速度慢或在动态跟随任务上表现较差。
陈建宇研究组探究了这个问题,提出了一种新颖的机器人操作控制模型框架HiRT—分层机器人变压器框架,来解决具身多模态大模型推理慢的问题。
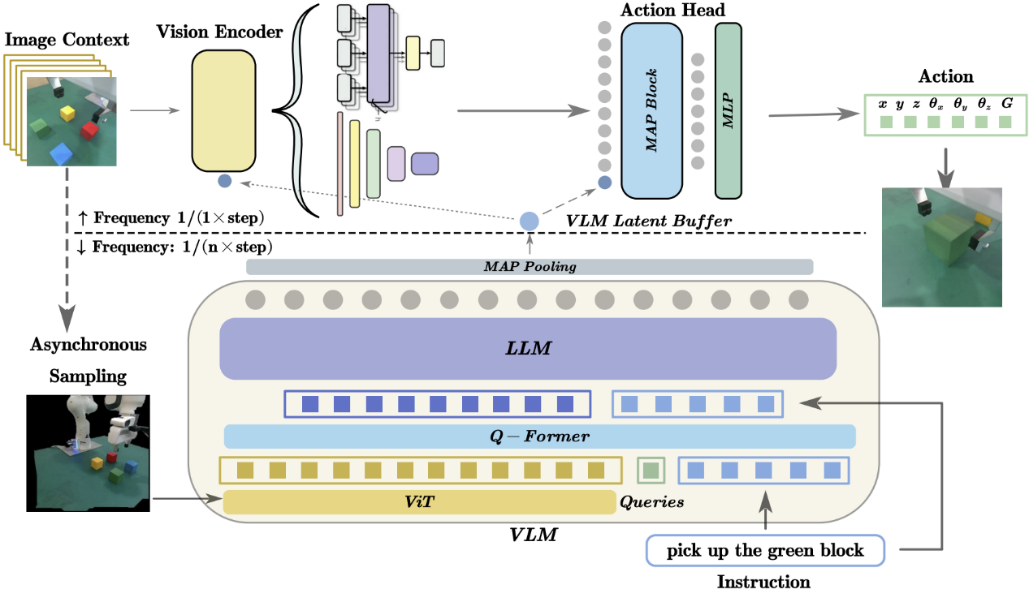
图|HiRT使小型策略模型与大模型异步执行,
兼顾泛化能力和推理效率
研究组创新地使用该框架将高频的视觉控制策略与低频的大型视觉语言模型(VLM)解耦,前者负责通过视觉信息快速与环境交互,后者则负责提供长期的场景理解与指导。为了能够兼顾模型的泛化性能和推理速度,研究组提出了新的条件化策略,使上层的快速交互模型能够异步地使用VLM提供的具有广泛语义信息的表征,使模型能够快速地输出机器人动作并具有较强的语义泛化能力。
研究组在仿真的机械臂环境和真实场景的机械臂环境中进行了大量实验。在静态操作类任务中,新的方法展示出了模型具有很好的泛化能力,例如模型能够抓取训练数据中未涉及的新物体,并且能够通过调整异步频率平衡模型推理速度的性能,实现兼顾大模型泛化能力和小模型快速推理的目标。同时在真机环境中的动态任务上,新方法具有相比于基线方法更高的成功率和完成速度,例如可以更快地跟随移动的目标物体,这体现出提升具身模型的推理速度能够使机器人更好地在动态场景中执行任务。实验表明,HiRT在静态任务中将控制频率提升了一倍,并在动态任务中将成功率从48%提高到75%。
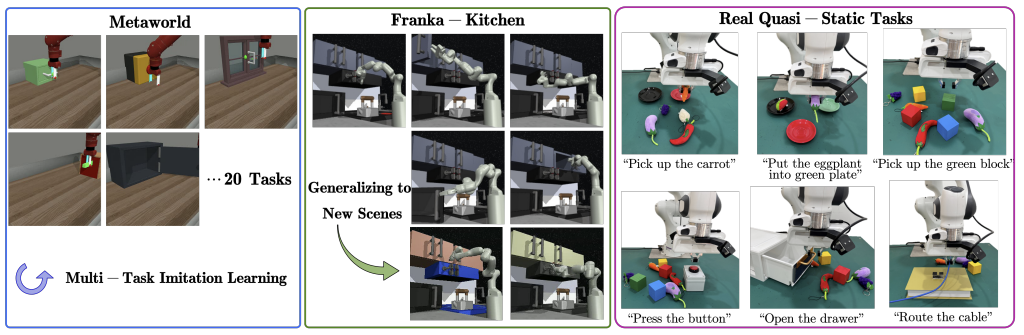
图 | 实验环境:仿真机械臂、真机机械臂硬件平台
(静态任务和动态任务)
HiRT有潜力发展为通用的基于视觉语言端到端具身模型框架。该论文共同第一作者为清华大学交叉信息院2024级博士生张荐科、2022级博士生郭彦江,通讯作者为清华大学助理教授陈建宇。
项目论文:
HiRT: Enhancing Robotic Control with Hierarchical Robot Transformers, Jianke Zhang∗, Yanjiang Guo∗, Xiaoyu Chen,Yen-Jen Wang, Yucheng Hu, Chengming Shi, Jianyu Chen†, https://arxiv.org/abs/2410.05273, CoRL 2024.
学习在任何地点操作:一种视觉泛化强化学习框架
如何让智能体具备在多个视角下进行操作的能力是机器人走向落地的关键。许华哲研究组设计了在层之间的一个multi-view的表征学习目标函数,去捕捉不同视角下的correspondence和alignment。同时也去插入STN模块,并把affine transformation改成了perspective transformation的形式,辅助网络更好的理解不同视角下的图像。利用该种方式将同一时刻不同视角的表征都投影到特征空间的相似位置。

图 | Maniwhere框架能够训练出能够跨各种视觉变化有效泛化的视动机器人
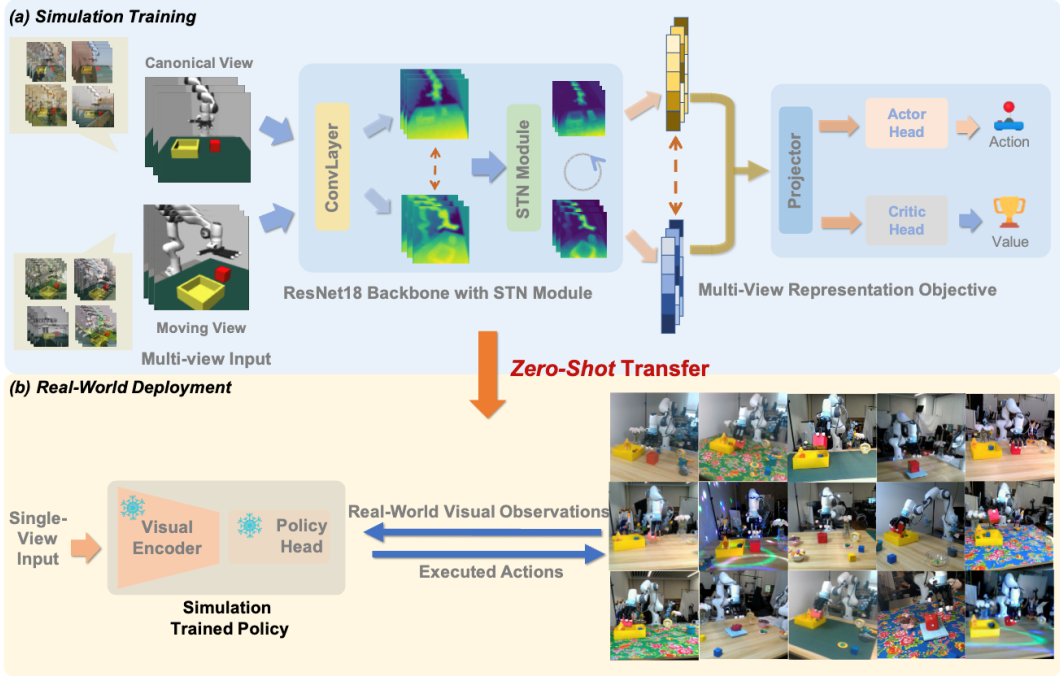
图 | Maniwhere概览
在具备了视角泛化能力后,研究组又设计了一种可泛化框架可以将多种视觉泛化的先验知识融入到智能体中。研究组使用基于课程学习的数据增强与域随机化方法,将纹理,具身形态等多种其他视觉泛化类型也融入到网络中。同时利用该种方式也可以更好的扩展训练数据的分布,以便于从模拟仿真器至现实环境的迁移。
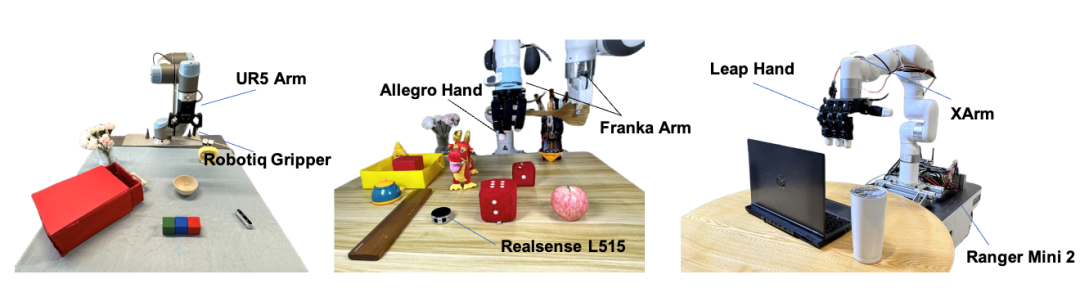
图 | 真机实验设置
为了验证方法的有效性,研究组设计了8种任务,在3个硬件平台上执行了sim2real的实验。结果表明,该方法效果在所有的任务上都取得了最佳的泛化表现。
本论文第一作者为清华大学交叉信息院2023级博士生袁哲诚、清华大学本科生韦天铭,通讯作者为清华大学交叉信息院助理教授许华哲。其他作者作者包括清华大学交叉信息院2024级博士生张谷,香港大学程水齐,北京大学陈源培。
项目论文:
Learning to Manipulate Anywhere: A Visual Generalizable Framework For Reinforcement Learning, Zhecheng Yuan*, Tianming Wei*, Shuiqi Cheng, Gu Zhang, Yuanpei Chen, Huazhe Xu†, https://gemcollector.github.io/maniwhere/, CoRL 2024.
无需点云分割的近实时三维特殊欧式群等变机器人操作
基于三维视觉的机器人模仿学习算法近年来得到不断提升,但是模仿学习的样本效率和空间泛化性能一直是制约其广泛应用的挑战。为了提升样本效率和泛化性,过去的方法要么使用任务特定的数据增强方式,要么将问题建模为复杂的等变优化问题。这些方法不仅缺乏任务普适性,而且增加了系统的复杂性、降低了推理速度,限制了机器人操作性能的进一步提高。
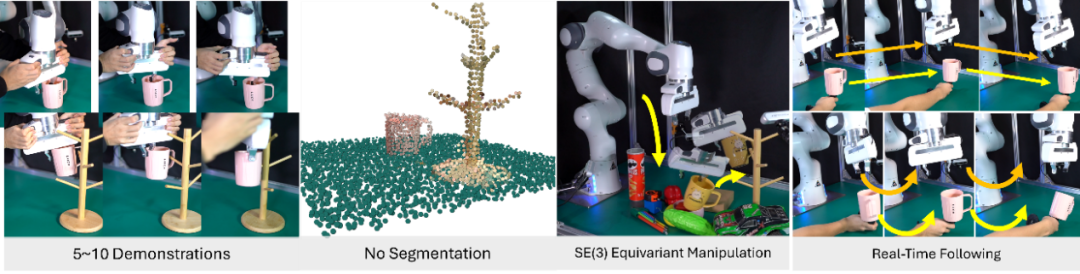
图 | RiEMann概览
针对这一问题,许华哲研究组提出了一个创新的端到端等变形学习框架,首次实现了端到端的三维特殊欧式群(SE(3))上的机器人模仿学习。如图1所示,该方法选择将机器人的动作空间分解为平移部分和旋转部分,并基于等变向量场理论,分别将平移部分建模为点云上0类向量场的加权和、将旋转部分建模为点云上的1类向量场的正交和,实现了端到端的基于点云的机器人等变模仿学习框架,解决了之前工作需要将等变模仿学习建模为复杂优化问题导致的低效学习和推理过程。
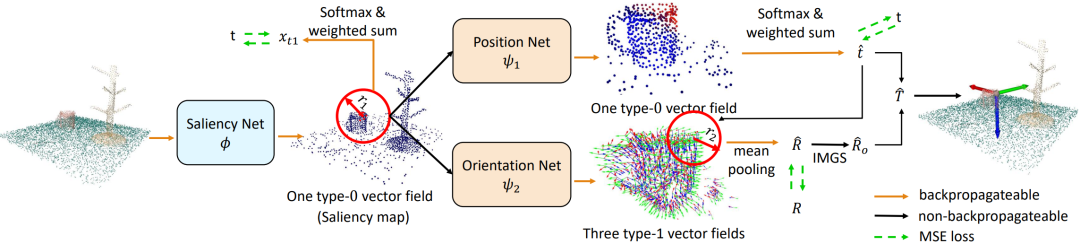
图 | 三维特殊欧式群等变的机器人模仿学习
同时,由于等变的神经网络具有内存占用大的问题,这使得其训练成本高昂。针对这个问题,许华哲研究组设计了显存高效的点云学习网络。该方法针对占用主要显存的旋转动作空间学习过程,能够动态地在学习过程中抽取空间点云中的小部分进行旋转动作空间的1向量场的学习,避免了在全场景点云上端到端学习的高昂成本,实现了高效训练和近实时的推理速度。
为了验证提出的方法有效性,研究组在ManiSkill的15种仿真环境和真实世界中基于Franka Panda机械臂的10种真实任务上进行了实验,包括抓取-挂上马克杯、抓取-放置飞机模型等。结果表明,该方法效果在所有任务上都优于4个基线,尤其在定量的测地线距离和推理时间上有显著效果提升。该方法能够使得机器人模仿学习算法泛化到新的物体几何实例(NI)、新的物体三维位姿(NP)、抵抗空间中的干扰物体的视觉干扰(DO)、以及所有因素的组合(ALL),并且能够有效地学习到0类平移向量场和1类旋转向量场。
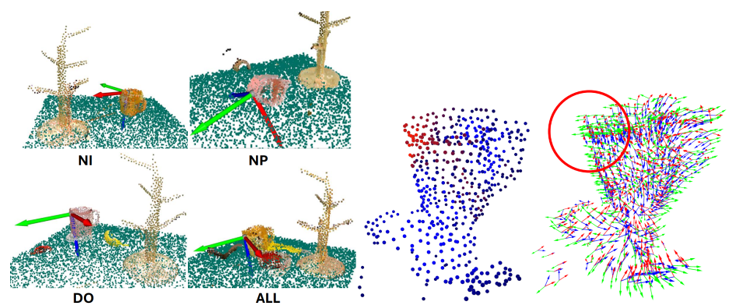
图 | RiEMann能够在多种泛化条件下有效学习到良好的操作动作
本研究有潜力提高机器人基于三维视觉的模仿学习样本效率和空间泛化性。本论文第一作者为清华大学交叉信息院访问学者高崇凯,通讯作者为清华大学交叉信息院助理教授许华哲。其他作者包括清华大学交叉信息研究院2023级博士生薛峥嵘、2024级硕士生梁天海,清华大学本科生邓舒颖、杨思琪,新加坡国立大学助理教授邵林。
项目论文:
RiEMann: Near Real-Time SE(3)-Equivariant Robot Manipulation without Point Cloud Segmentation, Chongkai Gao, Zhengrong Xue, Shuying Deng, Tianhai Liang, Siqi Yang, Lin Shao, Huazhe Xu†, https://riemann-web.github.io/, CoRL 2024.
编辑 | 姜月亮
审核 | 吕厦敏
学术顾问 | 陈建宇、许华哲
总审核|马雄峰

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢