

[2024 Best AI Paper] Graph Machine Learning in the Era of Large Language Models (LLMs)
 本博客的目的是了解图和 LLM 协同工作的现状和局限性。我将首先关注大型语言模型 (LLM) 时代的图机器学习。本文的目的是
本博客的目的是了解图和 LLM 协同工作的现状和局限性。我将首先关注大型语言模型 (LLM) 时代的图机器学习。本文的目的是详细介绍图机器学习 (Graph ML) 的历史以及使用 Graph ML 和 LLM 的当前状态
查找 Graph ML 与 LLM 结合使用的主要类别及其优点和局限性以及可能的解决方案。
现在,我们如何开始处理图?我们确实希望获得某种图的矢量表示,以便进行机器学习。但是,我们如何处理潜在的指数级节点和边数?
随机游走
这是斯坦福大学 2016 年发表的“node2vec:可扩展的网络特征学习(node2vec: Scalable Feature Learning for Networks)”中提出的基本思想。但前提是
我们想要对图中的节点和边进行分类,有点像推荐系统,给出你喜欢的电影的图,以及你是否会喜欢这部新电影等等。
为此,我们需要以向量的形式获取每个节点的特征,然后我们可以以无监督的方式进行分类,因为我们假设缺少标签。
这些特征可以利用随机游走的概念来实现。
我们正在研究无向无加权图
随机游走的理念非常简单。基本上,你从图中的一个节点开始,然后通过随机边对图进行随机游走,访问其他节点。
那么这对寻找嵌入有何帮助?
我们首先假设距离较近的节点是相似的/位于同一邻域。例如,
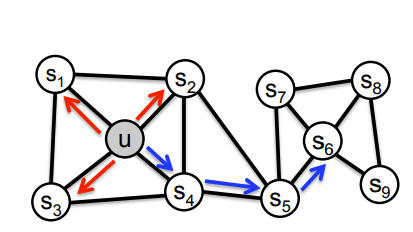
上面,u 和 s1 到 s4 相似/在同一个邻域,而 u 和 s6 应该是相异/不同的社区。
现在,随机游走论文提出的下一个想法是让我们进行大量这样的随机游走并记录访问的节点。所以我们有
你,s1,s2
你,s4,s5
s3、s4、你
等等。全部都是随机游走。现在,如果你看看上面的内容,它确实类似于英语中的标记或单词。从单词中,已经有一种称为 word2vec 的已知技术可以获取每个单词的向量嵌入,称为 skip-gram!
Skip-gram
我主要从这里学到了这个想法,我强烈建议大家去看看,但这个想法是
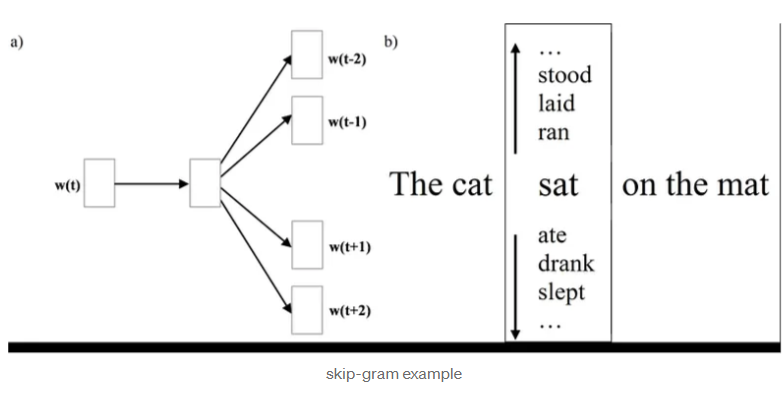
我们从随机游走句子中选择一个随机目标单词/节点,窗口大小假设为 5 个节点。因此,所选节点之前有 2 个节点,所选节点之后有 2 个节点。
使用该词嵌入,我们有一个隐藏层,然后有一个softmax来查看那 4 个未提及的节点是什么。
我们优化了嵌入,以便它可以可靠地预测它连接到哪些节点
因此,从本质上讲,随机游走背后的想法只是将图问题转换为 NLP,然后从那里解决。
但是,我想你可能注意到了,这非常简单。仅让一个神经网络在一次迭代中完成一次预测听起来太简单了。
事实上这是真的。有一种新技术可以处理图,称为图神经网络(GNN)。
图神经网络GNNs
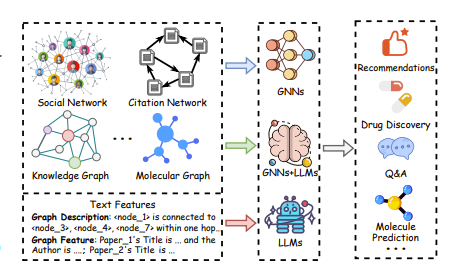
这篇论文重点介绍了两种类型的 GNN。第一种类型称为“基于邻域聚合的模型(Neighborhood Aggregation-based Model)”,我之前对此进行过一些研究。特别是来自一篇名为House-GAN(https://arxiv.org/abs/2003.06988)的论文,所以我将通过这种视角解释基本 GNN 的概念,因为我发现论文中的可视化在学习这些类型的 GNN 时非常有用。
HouseGAN 试图解决房间布局设计的问题。具体来说,考虑到我们想要某些类型的房间,以及关于哪个房间与哪个房间相连的一些图信息,我们希望生成布局图像!有点像下面这样:
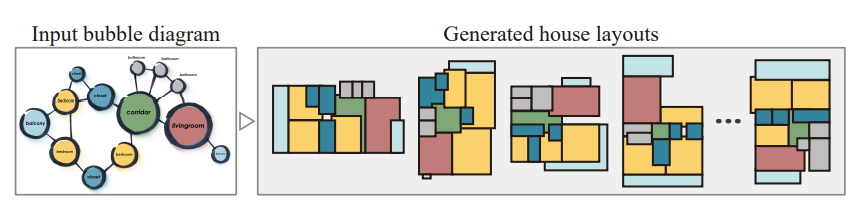
现在,我们将如何做到这一点?如果我们直接这样做并一次性生成图像,那么将很难同时提供房间数量和房间连接的受限信息。为了解决这个任务,本文决定,为什么不让输入图的每个节点都变成一个房间的图像,就像这样
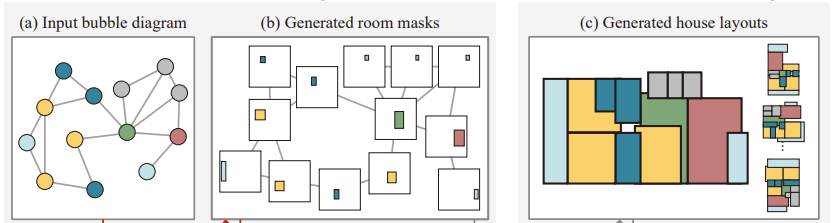
因此,我们可以将所有节点中的所有房间合并成一张图像,以获得最终图像!但是,有一个显而易见的问题,即节点如何知道将房间放在哪里,以免重叠或与我们想要的完全错误的位置。或者更具体地说,我们确实会根据真实数据训练我们的模型,以便它尝试在正确的位置生成,但它如何知道生成房间图像所需的周围信息?
这就是消息传递这一重要概念对于 GNN 的意义所在。
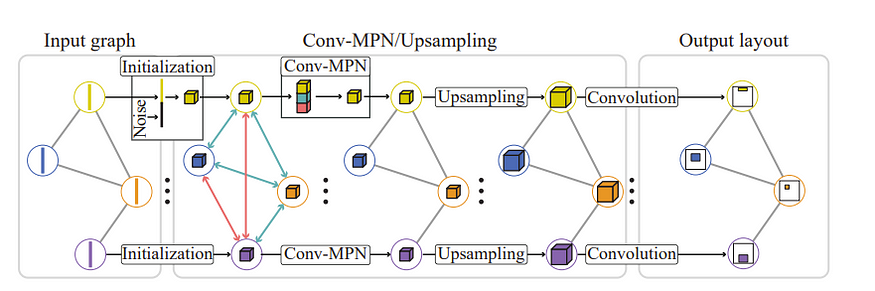
GNN 中消息传递的主要思想是,我们试图让给定节点了解其周围当前正在发生的事情。为此,在本文中,我们首先用向量随机初始化每个节点。这不是典型的 GNN 做法,但本文是关于 GAN 的,所以这就是随机初始化的原因。我们称此表示为 g,并让当前房间为 r
然后,我们得到想要更新的当前向量表示 g。
对于邻近的表示,我们得到
直接连接到 r 的节点表示的总和(如果您是计算机科学爱好者,您可能会注意到这与将所有表示乘以邻接矩阵相同)
所有不与 r 相连的节点的表示的总和
最后,我们通过神经网络(在本例中为 CNN)来更新 r。
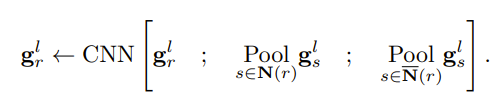
如果我们在多次迭代中对每个节点都执行此操作,我们可以让每个节点了解周围环境并能够在正确的位置生成房间!
正如这篇调查论文所述,有两个阶段,邻居的聚合和更新
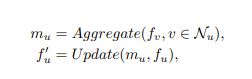
这里有一个有趣的改进,我们观察到,我们对哪些信息应该关注、哪些信息应该忽略给出了一些归纳偏差。例如,我们忽略了上面 2 个邻居之外的节点!因此,在“图注意力网络Graph Attention Networks(https://arxiv.org/abs/1710.10903)”中,这个问题通过让我们的模型来判断应该对哪个节点给予多少关注来解决。
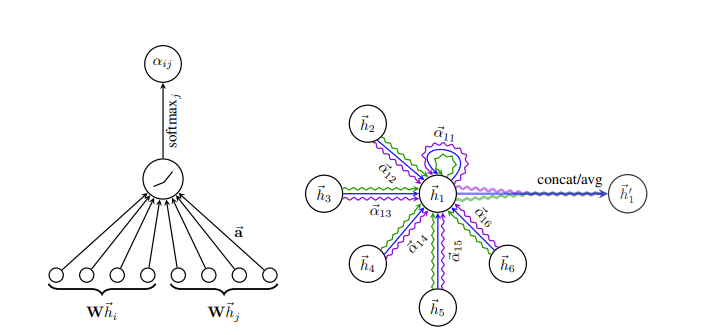
然而,这里的局限性也很明显。如果图很大,虽然这种方法可以获得有关每个节点局部邻域的信息,但该网络至少在没有大量迭代的情况下无法表示非常大的图。为此,本文提出了“基于图变换器的模型”
下面我假设您了解变压器的基础知识,但我可能会在这里编辑以添加初步介绍。
基于 Graph Transformer 的模型
Graph Transformer 模型的领先论文之一是微软的“Transformer 真的对图表示表现不好吗?(Do Transformers Really Perform Bad for Graph Representation?)” 。
这篇论文发表的时间大约是 2021 年,当时 NLP 和 CV 任务正在取得进展,而对于图任务,还没有人成功找到正确使用 Transformer 的方法。在图排行榜上,典型的基于邻域的 GNN 占据主导地位,而注意力机制可能在聚合中使用了一点,但在其他方面用得不多。
为了解决这个问题,作者通过使用编码将“图的结构信息纳入模型(structural information of graphs into the model)”改进了图编码!
基本思想如下:
对于典型的 Node 特征自注意力,在这种情况下不使用基于邻域的特征,数据上没有归纳偏差。因此,自注意力很难更新节点特征。我发现这很有趣,因为我记得在计算机视觉中也发生过同样的事情,直到 Swin Transformer 出现并给出了这种归纳偏差。
作者想到的第一个归纳偏差是使用一种称为中心性编码的技术来强调节点的重要性。具体来说,具有高度的节点应该比没有太多连接的节点更有价值。因此,他们为每个节点添加了有关进入该节点的节点数量和离开该节点的节点数量的特征信息,如下所示
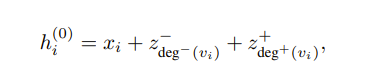
其中每个 z 都是一个经过学习的嵌入,将数字映射到向量。
接下来,如果你了解 transformers,你可能会好奇我们对位置嵌入做了什么。例如,通常在文本中,我们会将位置嵌入添加到模型的输入中,以表示这个单词是单词编号 1,这个单词是单词编号 2 等等,因为 transformers 无法区分哪个单词是哪个单词!即使对于图像,我们也可以将左上角设为标记编号,然后逐行进行。
然而,图的有趣之处在于我们不一定能做到这一点。因为我们不一定知道图从哪里开始,所以我们永远无法说出哪个节点是 1。事实上,从技术上讲,图节点上的任何位置嵌入顺序都可能是正确的。
因此,作者想到了进行空间编码。这个想法很简单,为什么我们不直接使用两个节点之间的最短路径来表示每个节点之间的“距离”?然后我们可以像上面一样将该距离嵌入到嵌入向量中,并将其添加到注意矩阵中!我们在此阶段这样做的原因是注意矩阵的大小为节点乘以节点。所以它的大小匹配。
最后,作者添加了边编码,我认为这主要是为了他们专注于分子预测的任务。据我所知,他们希望边缘信息成为某种相关性指标,我认为可以说明连接的重要性。那么它的计算方式是
我们有从节点 i 到节点 j 的最短路径
我们沿着最短路径选取边,并学习它们的嵌入
我们将每个边与每个节点的原始特征进行点积。
我们将这个常数添加到注意力矩阵索引 ij 中,因此我们得到
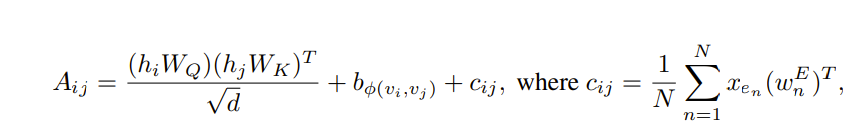
总体来说如下所示!
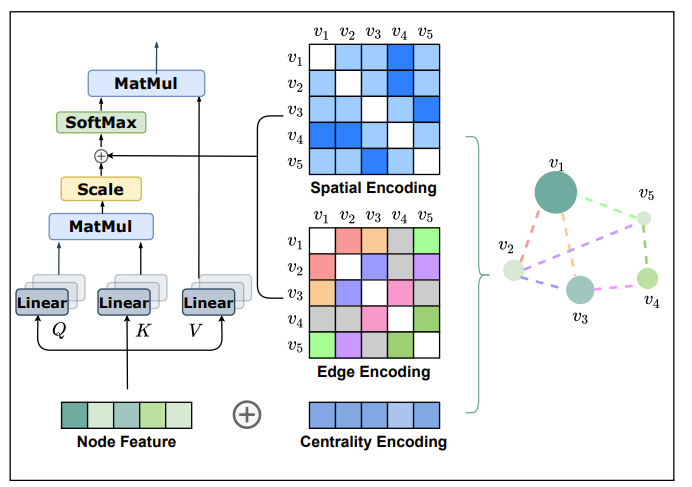
因此,本质上这些类型的 GNN 的主题似乎是在自我注意力中添加一些结构信息,我们可以提供一些弱归纳偏差以使 Graph Transformers 表现良好。
然而,与任何基于注意力的模型一样,这种方法虽然表现良好,但也存在自身的问题,即我们需要对注意力矩阵进行 O(N²) 计算。这个问题可以通过诸如“Graph-Mamba:面向具有选择性状态空间的长距离图序列建模( Graph-Mamba: Towards Long-Range Graph Sequence Modeling with Selective State Spaces )”之类的模型来解决,该模型应用了一种名为 Mamba 的模型,该模型可以近似注意力,但对于大序列而言内存消耗要少得多。但我认为现在说还为时过早。
现在我们有了一种方法,可以获得更合适的表征,我们可以让它们变得更好吗?主要方法似乎是通过自我监督学习!
自监督图学习
图对比学习
“增强图对比学习(Graph contrastive learning with augmentation)”所展示的理念非常简单。与任何对比学习项目一样,我们稍微扰动数据并尝试使表示尽可能接近原始数据!
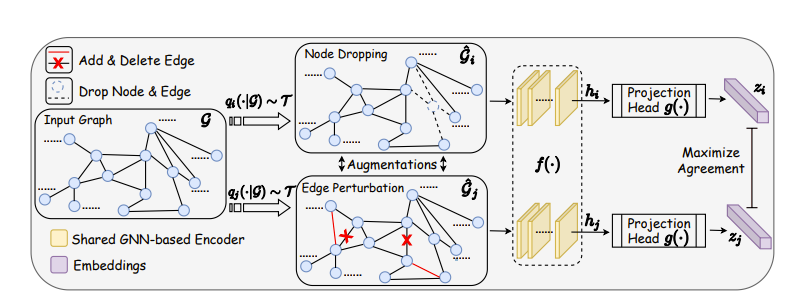
如果我们在图中这样做,主要有趣的部分是,我们可以进行节点级对比学习以及整个图的对比学习。然而,这里的一个明显问题是,一旦我们训练了这样一个对比学习模型,我们就不能将输入图的大小增加到 2 或 3 倍,至少目前还不能。
我想强调的另一部分是,上述内容仅在假设图/特征空间中的细小变化不会对图造成太大改变的情况下才有效。
图生成
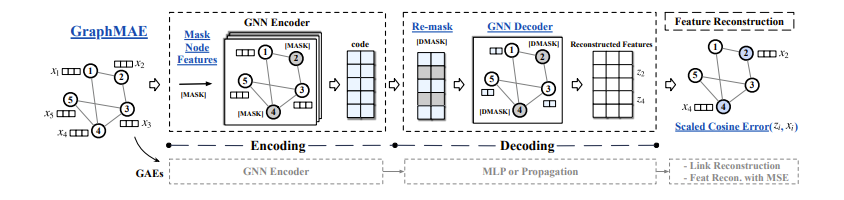
受蒙版图像建模的启发,论文“GraphMAE:自监督蒙版图自动编码器(GraphMAE: Self-Supervised Masked Graph Autoencoders)”着手隐藏某些节点的特征,然后尝试使用 GNN 重建它们,以便最终节点特征与输入特征相似!
那么 LLM 如何在图学习中发挥作用呢?
第一种方法是在使用 GNN 之前,先完善图及其特征
LLM 帮助完成 GNN 任务
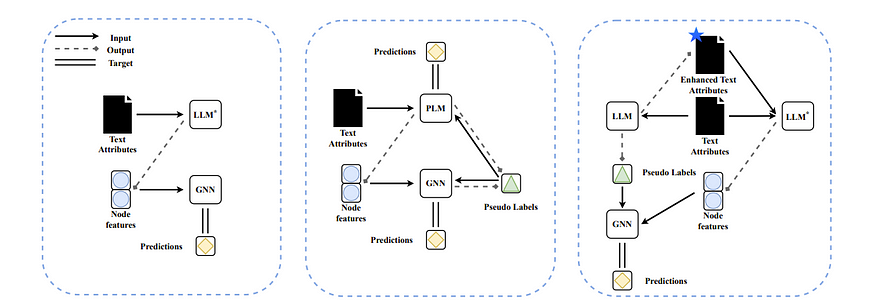
例如,对于“探索大型语言模型 (LLM) 在图学习中的潜力(Exploring the Potential of Large Language Models (LLMs) in Learning on Graphs)”,其想法似乎很简单,即使用具有可见嵌入的 LLM 来编码文本,或者使用 ChatGPT 等来制作比编码更好的文本,然后 GNN 再对其进行处理
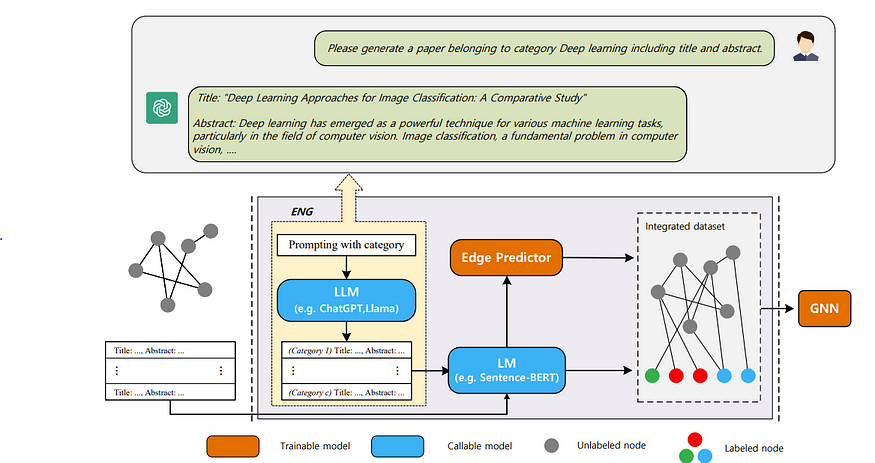
我发现的一个更有趣的方法是“使用大型语言模型(LLM)支持文本属性图学习(Empower Text-Attributed Graphs Learning with Large Language Models (LLMs))”,它使用 LLM 在插入 GNN 之前预测缺失边!
此外,如果我们希望我们的 GNN 能够跨多个任务工作,似乎有一种方法可以做到这一点。例如,“One for All:为所有分类任务训练一个图模型(One for All: Towards Training One Graph Model for All Classification Tasks)”提出了一种统一任务的方法,并将特征图与提示图相结合以指导 GNN
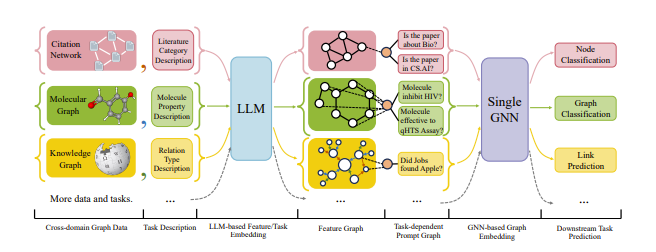
现在,自监督方法并不那么重要,但这种方法也有自己的局限性,即需要标记数据来训练 GNN。那么,我们能否完全放弃 GNN,让 LLM 自己解决图任务呢?或者更具体地说,我们如何将图插入 LLM,以便 LLM 能够解决图问题?
使用 LLM 解决图问题
似乎有很多工作要做,只是为了弄清楚哪种文本最适合表示图。
一些有趣的论文包括“语言模型能解决自然语言中的图问题吗?(Can Language Models Solve Graph Problems in Natural Language?)”,其中作者要求LLM根据文本描述构建图
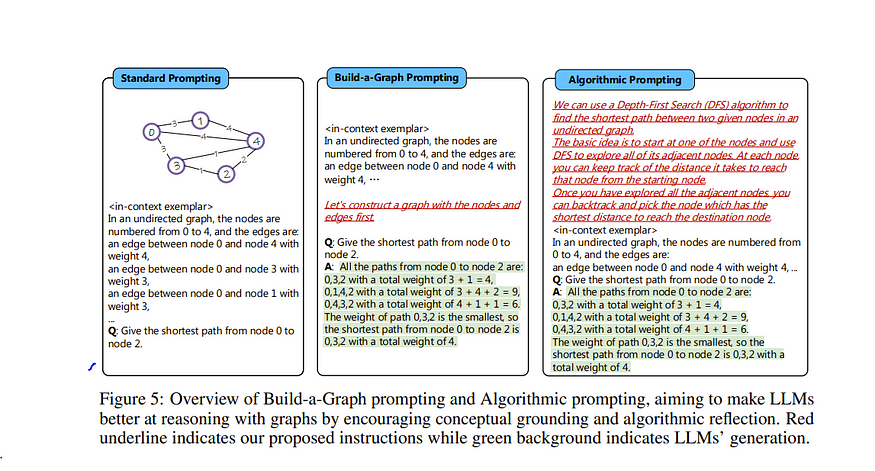
这会像上面一样提高 LLM 对图的理解。我从论文中学到的另一个策略是,有一种称为“GPT4Graph:大型语言模型可以理解图结构化数据吗?实证评估和基准测试(GPT4Graph: Can Large Language Models Understand Graph Structured Data? An Empirical Evaluation and Benchmarking)”的图标记语言,它与自我提示一起使用,以在最终输出之前提高对输入的图理解。
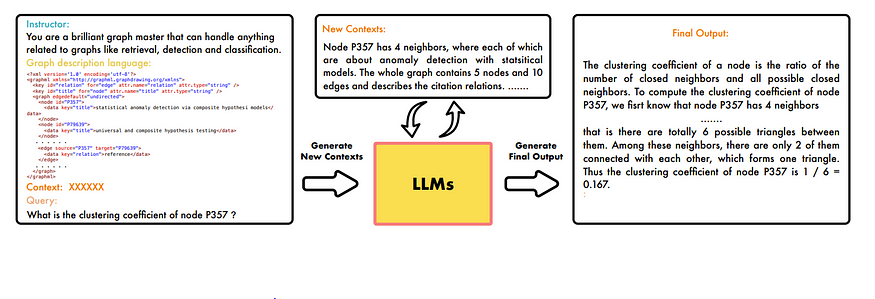 因此,总体而言,对于这种将图输入 LLM 的方法,主要策略似乎是输入数据,让 LLM 理解图,然后提出问题。然而,其局限性也很明显。由于上下文长度的原因,这种方法无法扩展到大型图。此外,论文强调,对于新任务,可能需要新的提示,这需要创造力和努力才能实现。
因此,总体而言,对于这种将图输入 LLM 的方法,主要策略似乎是输入数据,让 LLM 理解图,然后提出问题。然而,其局限性也很明显。由于上下文长度的原因,这种方法无法扩展到大型图。此外,论文强调,对于新任务,可能需要新的提示,这需要创造力和努力才能实现。
然后,我们想要的是一个经过专家预训练的 GNN 来以某种方式定制 LLM 的输出。
将 GNN 与 LLM 相结合
为此,我们可以从BLIP 2(https://arxiv.org/abs/2301.12597)中获得灵感,了解如何精确地结合文本和图像特征!
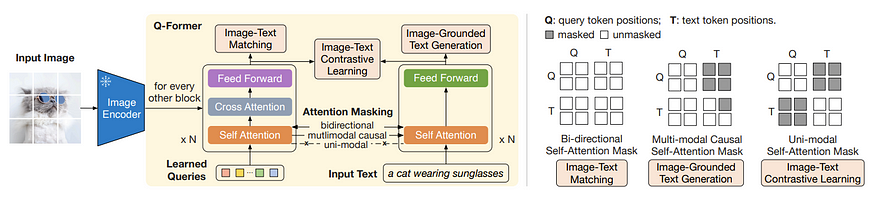
这个想法很简单。
我们有一个用于图像的transformer网络和另一个用于文本的transformer网络
我们不是直接将图像标记输入到图像transformer网络中,而是输入学习到的查询标记,并通过交叉注意添加图像信息。根据论文,我们这样做的原因是充当信息瓶颈,从图像编码器特征中获取信息,并以某种方式像 vae 一样压缩它们。
通过这种相当简单的技术,我们可以将图像和文本结合起来,并进行一些巧妙的注意力掩蔽,以生成有关图像的文本,并制作像 CLIP 这样的良好的图像和文本表示。
那么现在的问题是,我们能否使用从 GNN 中学到的特征将这种技术应用于图形?答案是肯定的。在“GIT-Mol:具有图、图像和文本的分子科学多模态大型语言模型(GIT-Mol: A Multi-modal Large Language Model for Molecular Science with Graph, Image, and Text)”中,正是使用 Q-former 提出了这种图、图像和文本模态融合的想法!如下所示,即使只是基于图像作为模态,也可以进行分类甚至字幕制作。从某种意义上说,它几乎是终极的转换器。
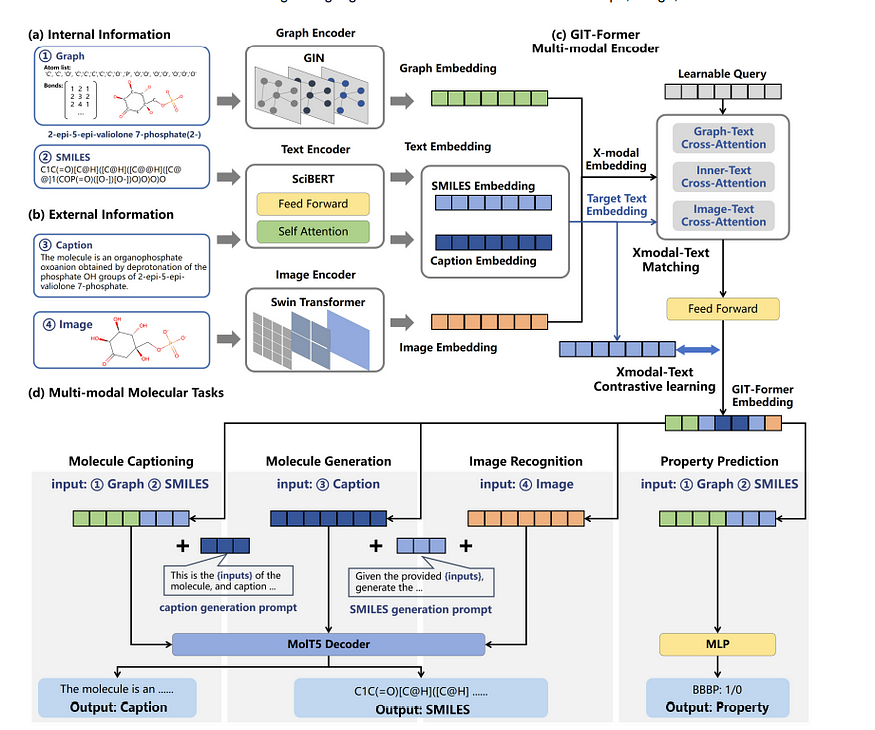
另一种有趣的方法是我们将图标记化以用于 LLM。例如,在“Gimlet:用于基于指令的分子零样本学习的统一图文本模型(Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning)”中,图使用基于我们之前提到的最短距离的位置嵌入进行标记!然而,与常规 NLP 的一个细微差别是,它被添加到注意矩阵中,而不是隐藏节点状态(与上面的图transformers的 PE 相同),就像这样
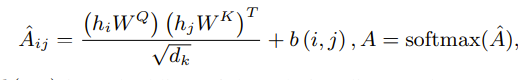
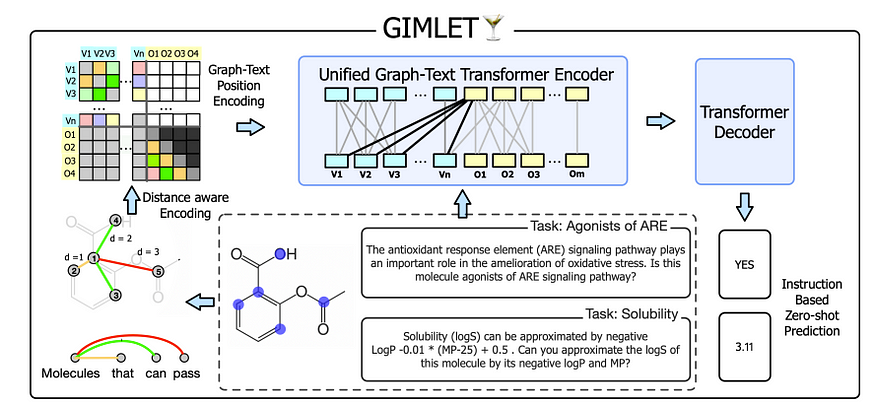
另外,这里的一个重要部分是,在我看来,图“标记”实际上并没有被标记化。我们只是有图嵌入,然后向其中添加位置嵌入。
然而,这个想法有一个局限性。那就是它受到 GNN 性能的限制。论文提到,如果
相邻节点缺乏相似性,这是假设之一
它们无法推广到分布外的数据
总的来说,似乎有一些工作使用 LLM 来解决这个问题,我认为与上述统一模型相比,这个想法不那么令人兴奋。
现在,最后,我们如何使用图来消除幻觉?这就是知识图谱发挥作用的地方。
知识图谱
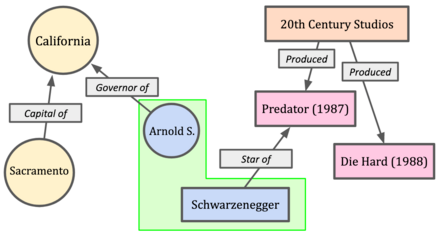
如上图所示,知识图谱 (KG) 由三组事实组成。例如,(阿诺德,加利福尼亚州州长)就是一个事实。那么我们的想法是,我们能否将 LLM 与这一系列事实结合使用,使输出更加符合事实?
使用 KG 增强训练数据以进行 LM 训练
我们可以使用 KG 的第一种方法是修改训练数据。一项特别有趣的工作“K-BERT:使用知识图谱实现语言表示(K-BERT: Enabling Language Representation with Knowledge Graph)”采用了输入句子,并通过添加知识图谱中的细节来增强它,如下所示
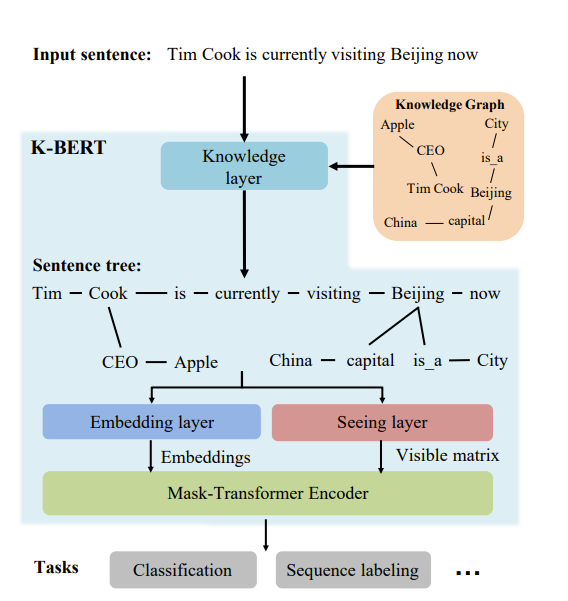
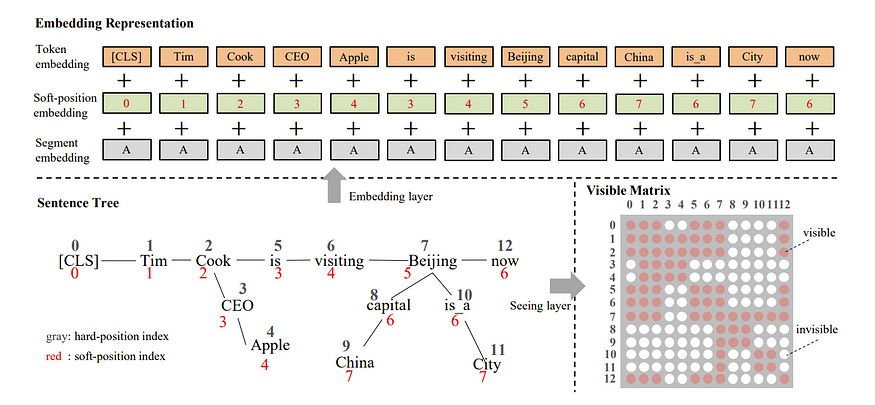
有趣的是,这使用了注意力掩蔽,以便 KG 只能从受其影响的特定标记中可见,就像这样!
另一个更有趣的方向是将知识图谱直接编码到架构中,例如“ERNIE:使用信息实体增强语言表示(ERNIE: Enhanced Language Representation with Informative Entities)”,它首先提出了将实体直接编码到我们的 token 中的想法。例如,在上面,每当提到 Apple 时,就对 Tim Cook 进行编码,如下所示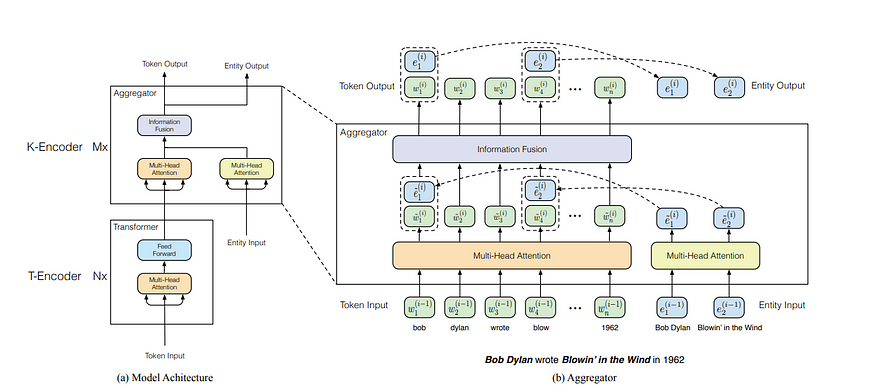
因此,这里 bob 的 token 被编码为 Bob Dylon,而 blow 则被编码为 Blowin' in the Wind,这些 token 均来自 KG 的元组对!请注意,这里的 token 输入和实体输入不必具有相同的大小。事实上,假设我们取 bob,1 个 token,并将其与 Bob Dylan 的 2 个实体 token 连接起来。然后我们可以执行下面的前馈网络结构,然后在信息融合阶段之后将它们分开。这里不存在大小问题!
对于信息融合,它由以下公式给出,其中 wj 是输入标记,eks 是相关实体。
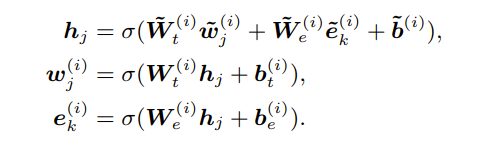
在这方面已经有了改进,例如腾讯的KLMO(https://aclanthology.org/2021.findings-emnlp.384.pdf)也对 KG 的关系部分进行了编码,但我认为 Ernie 对这种方法给出了足够的想法。
然而,上述方法也存在一些问题,因为我们正在对 LLM 进行重大修改,因此训练成本会很高。我们能不能做点类似 LORA 的事情呢?答案是可以的。在“KALA:知识增强语言模型自适应(KALA: Knowledge-Augmented Language Model Adaptation)”中,
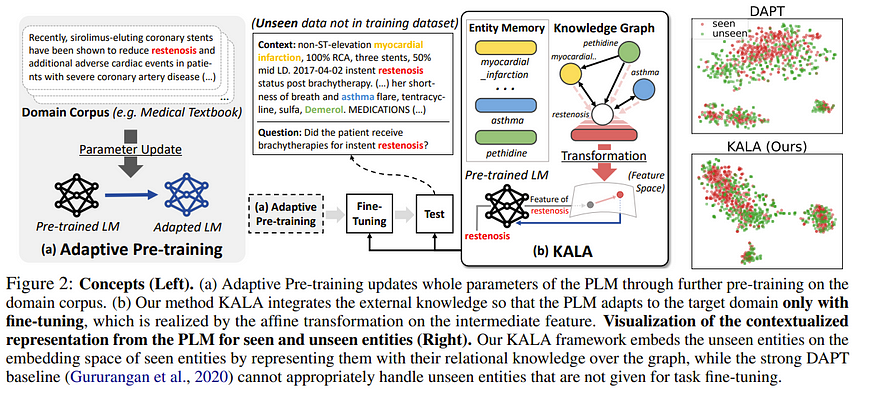
在本文中,目标是根据输入 x 预测标签 y,因此我们有
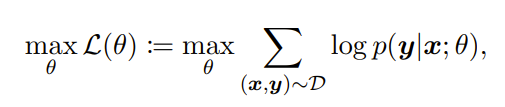
因此,KG 的目标变成了使用知识图谱嵌入来实现上述目的。为此,作者使用网络根据提示中找到的实体来找到应用于中间层的尺度和偏差,就像这样!(有机会时,我会尝试添加 KFM 的功能/嵌入的具体内容)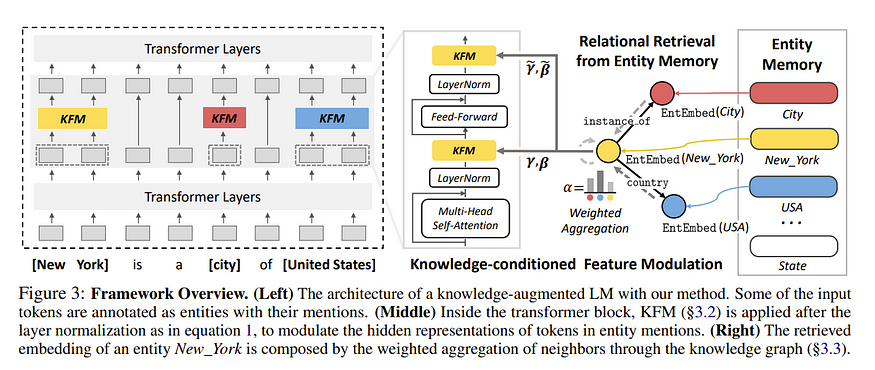
还有一些方法可以修改相关任务,我们尝试通过随机用其他实体替换某些实体,让模型使用知识图谱猜测缺失的实体。但我现在将跳到下一节。
使用 KG 进行推理!这可能是那些没有太多资源的人会感兴趣的事情。我们怎样才能使用 KG 来改进 GPT 4 的提示输出?
用于推理的知识图谱
论文中强调的第一种方法是使用 KG 来查看提示中是否有可以添加的上下文,然后对其执行类似 RAG 的操作,如下所示
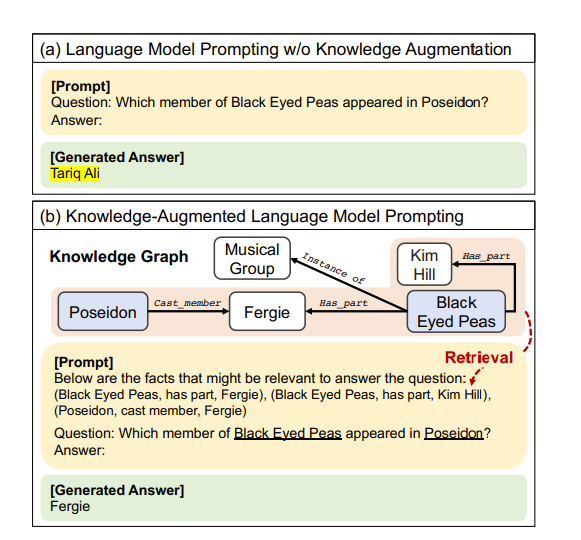
然而,这确实在很大程度上依赖于 LLM 本身对图结构的理解。关于这项任务的论文似乎都指向使 LLM 的推理过程更加清晰和以知识图为基础的方向。此外,像“通过基于自主知识图的改造减轻大型语言模型幻觉(Mitigating Large Language Model Hallucinations via Autonomous Knowledge Graph-based Retrofitting)”这样的论文通过首先让 LLM 输出草稿答案,然后提取声明,验证直到答案看起来正确,从而防止 LLM 产生幻觉。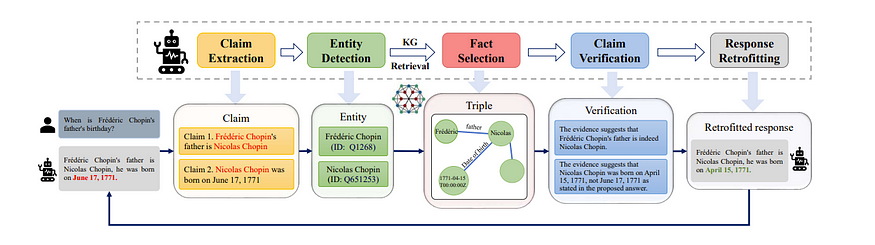
最后,“ChatGraph:通过将 ChatGPT 知识转换为图来实现可解释的文本分类(ChatGraph: Interpretable Text Classification by Converting ChatGPT Knowledge to Graphs)”首先使用 ChatGPT 将非结构化文档/提示转换为知识图对,然后使用经过训练的 GNN 从这些 KG 构建的图中预测标签,我认为这非常有趣。基本上,如果你无法训练 LLM,就可以减轻工作负担。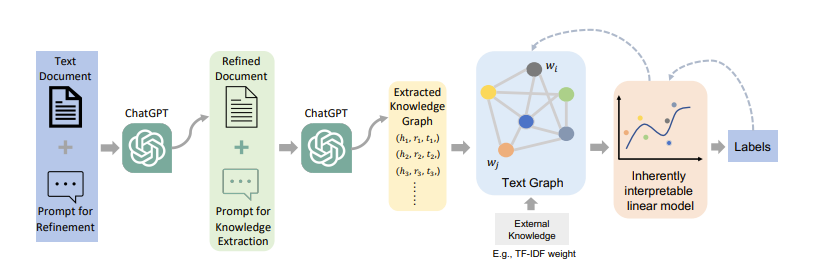
最后,让我们探索一下当前领域缺少什么
普遍性
GNN 受到 OOD 样本的影响。LLM 似乎在这方面有所帮助,但目前尚不清楚 GNN 是否是最佳的泛化架构,或者是否会有一些新的图基础模型。为此,本文建议在文本/图/图像数据集中进行更多的多模态研究
2. 效率
尤其是图的大小会随着每个节点的增加而呈指数增长,这使得使用 LLM(例如 GPT4)的成本非常高。需要提高效率。
最后,就我个人而言,我确实觉得这项调查很有趣,但我有点惊讶的是,调查中似乎没有太多关于
约束生成 + 图或 LLM 规划图Constrained generation + graphs or graphs for planning for LLMs
使用图提高数学能力/逻辑Increasing math capability/logic using graphs
量化图Quantizing graphs



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢