

从正弦到 RoPE 和 ALiBi:高级位置编码如何克服 Transformer 中的限制
介绍
近年来构建的模型的迅猛发展与 Transformer 架构的出现息息相关。以前,人工智能科学家必须为手头的每项任务选择架构,然后优化超参数以获得最佳性能。限制其潜力的另一个挑战是难以处理数据的长距离依赖性,从而出现梯度消失、长序列上下文丢失以及由于局部性约束而无法捕捉全局上下文的问题。此外,传统模型缺乏可扩展性和并行性,减慢了对大型数据集的训练,阻碍了该领域的进步。
Transformer 架构通过其自注意力机制解决了这些问题,彻底改变了该领域。它使模型能够捕获长序列中的关系并有效地理解全局上下文,同时高度可并行化并适应各种模态,例如文本、图像等。在自注意力机制中,对于每个标记,将其查询与所有其他标记的键进行比较以计算相似度分数。然后使用这些相似性来衡量值向量,最终决定当前标记应该关注的位置。自注意力将所有标记视为同等重要,无论其顺序如何,都会丢失有关标记出现顺序的关键信息,换句话说,它将输入数据视为无序的集合。现在我们需要一种机制来对数据强制执行某种顺序概念,因为自然语言和许多其他类型的数据本质上是顺序的和位置敏感的。这就是位置嵌入发挥作用的地方。位置嵌入对序列中每个标记的位置进行编码,使模型能够保持对序列结构的感知。人们已经探索了各种编码位置信息的方法,我们将在本博文中介绍它们。
注意力机制
假设S = {wi}(其中i =1,…,N)是N 个输入 token的序列,其中wi表示第 i个 token。因此, S的相应 token 嵌入可以表示为E = {xi}(其中i =1,…,N),其中xi是token wi的d维 token 嵌入向量。自注意力机制将位置嵌入合并到 token 嵌入中,并生成查询、键和值表示,如下所示:

然后,根据查询和关键向量之间的相似性计算注意权重:
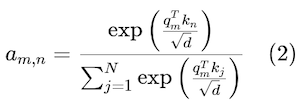
注意力权重决定了 token n对于 token m的重要性。换句话说,就是 token m应该对 token n投入多少注意力。token m的输出计算为值向量的加权和:
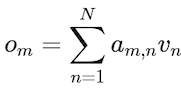
因此,注意力机制标记m从序列中的其他标记收集信息。
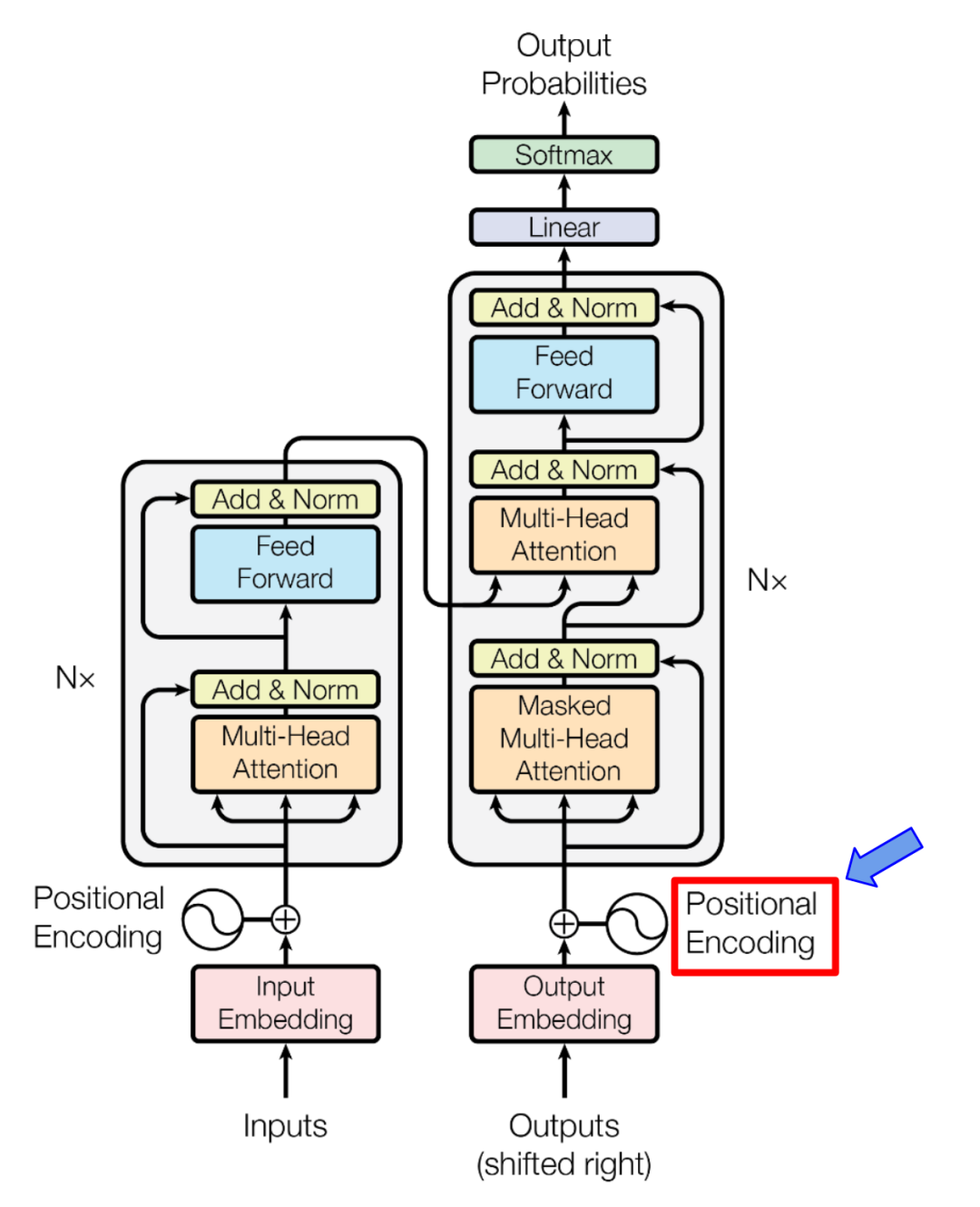
图 1. Transformer 架构中的位置编码。https://arxiv.org/pdf/1706.03762
1.绝对位置嵌入
方程(1)的典型选择是:
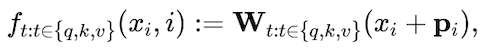
其中pi是一个d维向量,表示 token xi的绝对位置。正弦位置编码和学习位置编码是生成pi 的两种方法。
1.1 正弦位置编码
正弦位置编码是在“注意力就是一切”论文中引入的,其中提出了 Transformer 架构。正弦位置编码为输入序列中的每个 token 提供了唯一的位置表示。它基于具有不同频率的正弦和余弦函数,如下所示:
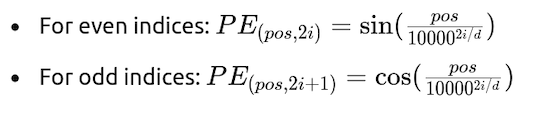
其中pos是 token 在序列中的位置,d是位置嵌入维度,i 是维度索引(0<=i<d)。
正弦位置编码中正弦和余弦函数的使用与傅里叶变换。通过使用一系列不同的频率来编码位置,Transformer 创建了类似于傅里叶变换的表示,其中:
高频分量(较低的i)使模型能够捕捉局部位置信息。这对于理解序列中相邻标记之间的关系(例如单词对)很有用。
低频分量(i值较高)可捕捉整个序列的更多全局模式。这有助于模型关注可能相距甚远的标记之间的更广泛关系,例如两个不同句子中单词之间的依赖关系。
这有助于模型通过比较标记的位置编码来理解标记的相对位置。正弦位置编码不需要额外的训练参数,同时在推理时可以推广到更大的序列长度。然而,其表达能力有限。
1.2 学习位置编码
学习位置编码是在“注意力就是你所需要的一切”论文中引入的,它被应用于BERT和GPT模型中,作为正弦位置编码的替代方案。在学习位置编码中,序列中的每个位置(例如第一个标记、第二个标记等)都分配有一个嵌入向量。这些位置嵌入在训练期间与其他 Transformer 参数一起学习。例如,如果模型的上下文长度为 512,标记嵌入大小为 768(即d =768),则大小为 512*768 的可学习张量将添加到其他可训练参数中。这意味着模型逐渐学习针对特定任务(例如文本分类或翻译)编码位置信息的最佳方式。
学习位置嵌入比正弦嵌入更具表现力,因为模型可以学习位置嵌入,这对其特定任务有效。然而,它们引入了更多可训练参数,这增加了模型大小和计算成本。
2. 相对位置嵌入
正弦和学习位置编码都关注标记的绝对位置。然而,注意力机制的工作原理是计算其他标记对于序列中每个特定标记的重要性。因此,这个过程取决于标记的相对位置(它们彼此相距多远),而不是标记的绝对位置。为了解决绝对位置嵌入的局限性,引入了相对位置编码。
RelativePosEmb不会将位置信息添加到 token 嵌入中。相反,它会修改每一层的 key 和 value 的计算方式,如下所示:

这里,r = clip(mn, Rmin, Rmax)表示位置 m 和 n 之间的相对距离。最大相对位置被截断,假设精确的相对位置在一定距离之外没有用处。截断最大距离使模型能够在推理时进行推断,即推广到训练期间未见过的序列长度。然而,这种方法可能会错过来自 token 绝对位置的一些有用信息(例如第一个 token 的位置)。
您可能会注意到fq缺少位置嵌入。这是因为我们正在对相对位置进行编码。在注意力公式中,查询和键值用于计算注意力权重,如公式 (2) 所示,因此我们只需要查询或键来包含相对位置嵌入。
这种编码已在Transformer-XL和T5等许多模型中使用。在论文[7]和[8]中可以找到应用相对位置编码的不同替代方案。
3. 旋转位置嵌入(RoPE)
与以前的方法不同,RoPE根据 token 的位置在多维空间中旋转向量。它不是将位置信息添加到 token 嵌入中,而是修改了在每一层计算注意力权重的方式,如下所示:

他们提出了一个针对任意偶数嵌入维数d 的广义旋转矩阵,如下所示:
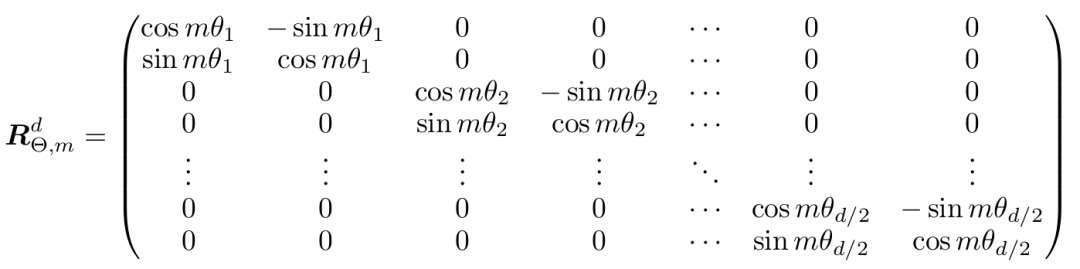
其中θi是预定义的:
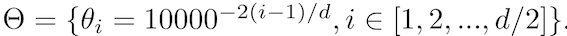
将RoPE应用于注意力权重可得出:
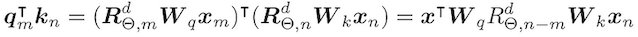
请注意,RoPE公式不会将位置信息添加到注意模块中的值中。注意模块的输出是值向量的加权和,由于位置信息未添加到值中,因此每个转换器层的输出没有明确的位置详细信息。
LLaMA和GPT-NeoX等流行模型正在使用RoPE。
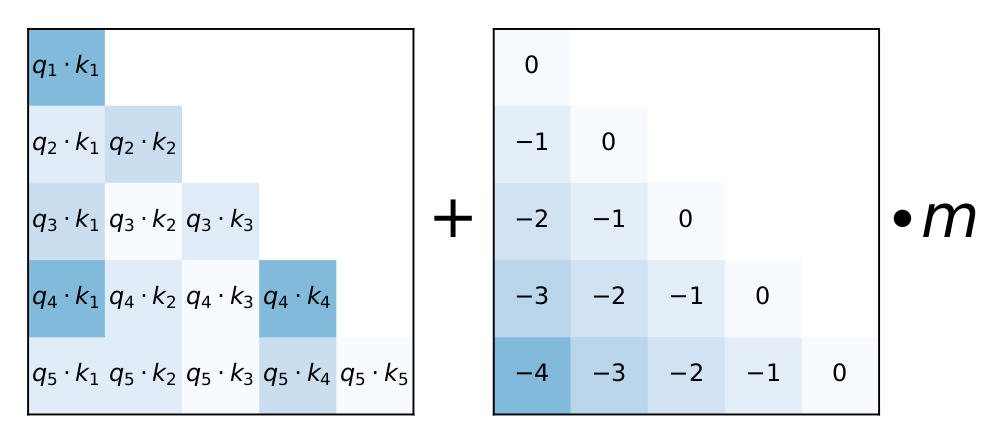
图 2:ALiBi方法可视化。https://arxiv.org/pdf/2108.12409
4. 线性偏差注意力机制(ALiBi)
ALiBi也没有在词向量中添加位置编码,而是在注意力权重分数中添加与 token 之间的距离成比例的惩罚。因此,每一层的两个 token i 和 j 之间的注意力分数计算如下:
Attention score = query_i . key_j — m.(i-j)
其中-m.(ij)是惩罚项,与 token i和j之间的距离成比例。标量m是在训练前固定的头部特定斜率,不同头部的斜率值按几何序列选择。例如,对于 8 个头部,m可能是:
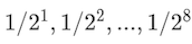
这意味着,第一个头的m相对较大,因此它会更多地惩罚相距较远的标记并关注最近的标记,而第 8 个头的m最小,因此它可以关注更远的标记。图 2 也提供了可视化效果。
ALiBi 在BloombergGPT和BLOOM中使用。
推理时的 Transformer 外推
推理时的 Transformer 外推是指模型能够很好地处理比训练时更长的输入序列。Transformer 机制与输入长度无关,这意味着在推理时,它可以处理更长的序列。但是,请注意,计算成本会随着输入长度的增加而呈二次方增长,即使 Transformer 层本身与输入长度无关。
ALiBi的作者证明了 Transformer 外推的瓶颈在于其位置嵌入方法。如图 3 所示,他们比较了不同位置嵌入方法的外推能力。由于学习到的位置嵌入不具备对大于训练长度的位置进行编码的能力,因此它不具备外推能力。
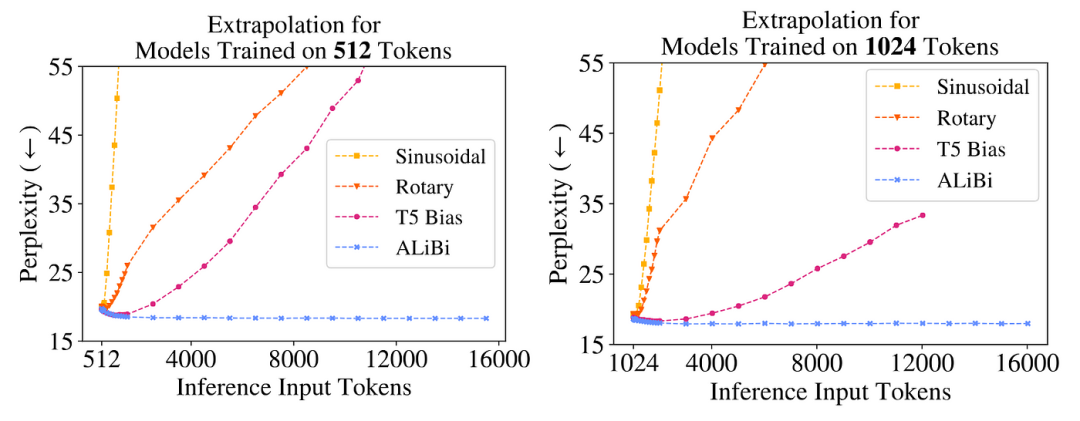
图 3:外推:随着输入序列变长(x 轴),正弦、RoPE和T5位置编码显示出困惑度降低(y 轴,越低越好),而ALiBi则没有。https://arxiv.org/pdf/2108.12409
图 3 表明,在实践中,正弦位置嵌入的外推能力非常有限。虽然RoPE 的表现优于正弦嵌入,但仍未取得令人满意的结果。T5偏差方法(相对位置嵌入的一种版本)比正弦嵌入和RoPE嵌入都能产生更好的外推效果。不幸的是,T5偏差的计算成本很高(图 4)。ALiBi的表现优于所有这些位置嵌入,内存增加量可忽略不计(0-0.7%)。

图 4:正弦、RoPE、T5和ALiBi位置编码的批量训练、推理速度和内存使用情况比较。https://arxiv.org/pdf/2108.12409
结论
总之,Transformer 架构中位置信息的编码方式显著影响了其理解顺序数据的能力,尤其是在推理时进行推断的能力。虽然绝对位置嵌入方法提供了位置感知,但它们通常难以进行 Transformer 推断。这就是为什么提出更新的位置嵌入的原因。相对位置编码、RoPE 和 ALiBi 具有在推理时进行推断的能力。随着 Transformer 继续集成到各种应用中,改进位置编码对于突破其性能界限至关重要。
参考
[1] Vaswani, A. “Attention is all you need.” (2017).
[2] BERT: Devlin, Jacob. “Bert: Pre-training of deep bidirectional transformers for language understanding.” (2018).
[3] GPT: Radford, Alec, et al. “Language models are unsupervised multitask learners.” (2019).
[4] RelativePosEmb: Shaw, Peter, et al. “Self-attention with relative position representations.” (2018).
[5] Transformer-XL Dai, Zihang. “Transformer-xl: Attentive language models beyond a fixed-length context.” (2019).
[6] T5: Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” (2020).
[7] Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” (2020)
[8] He, Pengcheng, et al. “Deberta: Decoding-enhanced bert with disentangled attention.” (2020).
[9] RoPE: Su, Jianlin, et al. “Roformer: Enhanced transformer with rotary position embedding.” (2024).
[10] LLaMA: Touvron, Hugo, et al. “Llama: Open and efficient foundation language models.” (2023).
[11] GPT-NeoX: Black, Sid, et al. “Gpt-neox-20b: An open-source autoregressive language model.” (2022).
[12] ALiBi: Press, Ofir, et al. “Train short, test long: Attention with linear biases enables input length extrapolation.” (2021).
[13] BloombergGPT: Wu, Shijie, et al. “Bloomberggpt: A large language model for finance.” (2023).
[14] BLOOM: Le Scao, Teven, et al. “Bloom: A 176b-parameter open-access multilingual language model.” (2023).



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢