

序列建模基元(Sequence modeling primitives)一直是自然语言处理(NLP)和基因组学(genomics)等领域取得突破的关键。尽管取得了这些进展,但现有的基元仍然难以对从物理传感器获取的大量信号数据进行建模。这些数据具有独特的特性,使其难以建模:信号数据分辨率会影响模型的训练和泛化,信号数据以高速率采样,导致具有长距离依赖性的密集数据,并且信号数据高度多样化,应用领域包括医疗保健、视频处理和工业传感。所有这些特性都提高了通用数据建模方法的标准。本论文开发了一套使用状态空间模型(state space models)对信号数据进行建模的新方法。首先,我们引入了一个名为 S4 的序列模型,它是对信号数据进行建模的通用构建块。其次,我们将这个建模层推广到图像和视频等多维信号,从而在 ImageNet 等大规模基准上产生了第一个最先进的信号模型。将 S4 整合到多尺度架构中,可以对极长的音频序列进行建模,包括之前未解决的涉及无条件自回归生成原始音频样本的任务。最后,我们展示了我们的方法对各种信号数据的广泛适用性,包括涉及用于诊断胃食管反流病的阻抗传感器数据的实际应用。总而言之,这套新方法提供了一套通用且多功能的基元,用于对各种多维信号进行建模。

论文题目:Beyond text : applying deep learning to signal data
作者:Karan Goel
类型:2024年博士论文
学校:Stanford University(美国斯坦福大学)
下载链接:
链接:https://pan.baidu.com/s/1QIFFzSFi2dcFmkJetjpsFg?pwd=50ud
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
物理传感器获取的数据占全球收集的所有数据的很大一部分。这些数据被称为信号数据,代表了一个引人入胜且至关重要的研究领域,涵盖了各种科学、工程和工业应用。信号数据涵盖各种形式,例如音频、视频、温度读数和磁共振成像 (MRI)。例如,在医疗保健领域,处理来自医疗传感器的信号可以显著提高患者诊断的准确性和速度。同样,在能源管理中,通过信号数据分析用电量波动可以实现更具适应性和更高效的电网运营。
深度学习方法在理解许多数据模式(例如文本、图像、音频和时间序列数据)方面取得了重大进展。在这些方法中,称为序列模型的深度学习模型尤其重要。序列模型使用参数化的序列到序列转换将文本、音频和视频等序列数据转换为丰富的语义表示,以捕获输入数据的结构 [150, 111, 11, 70, 35]。流行的序列模型的示例包括卷积神经网络 (CNN)、循环神经网络 (RNN) 和 Transformer 架构。
序列建模层(例如自注意力 [164])在当今的机器学习应用中得到了广泛使用。这些层是创建深度学习架构的通用构建块。然后可以对架构进行端到端训练,以执行各种任务,例如分类、回归和数据生成。
 (信号数据分析中的挑战)该图说明了信号数据的三个关键特征,这些特征带来了独特的挑战。首先,与离散的文本数据不同,信号本质上是连续且平滑的,需要能够以不同分辨率捕获它们的模型。其次,信号的高采样率导致长序列,其数量大但信息稀疏,因此需要高效的远程建模技术。第三,现实世界应用中信号的多样性增加了一层复杂性,因为模型必须足够强大和灵活才能处理信号数据的变化。这些因素强调了对能够适应真实信号数据复杂性的分辨率不变建模策略的需求。
(信号数据分析中的挑战)该图说明了信号数据的三个关键特征,这些特征带来了独特的挑战。首先,与离散的文本数据不同,信号本质上是连续且平滑的,需要能够以不同分辨率捕获它们的模型。其次,信号的高采样率导致长序列,其数量大但信息稀疏,因此需要高效的远程建模技术。第三,现实世界应用中信号的多样性增加了一层复杂性,因为模型必须足够强大和灵活才能处理信号数据的变化。这些因素强调了对能够适应真实信号数据复杂性的分辨率不变建模策略的需求。
尽管机器学习领域取得了这些进步,但有效建模信号数据方面仍然存在重大挑战。这些挑战是由于信号数据的独特性质而产生的,现有的建模方法尚未充分解决这些挑战。
挑战 1:信号的连续性
第一个挑战源自信号数据的连续性。信号数据是使用物理传感器从连续值信号中获取的。根据信号的不同,收集的数据可能是一维的(例如音频或传感器数据)、二维的(例如图像)或更高维的(例如视频或 MRI)。
与文本等离散数据类型不同,信号数据具有固有的分辨率,因为它们是连续信号的数字采样。数据采集过程中的一个关键选择是采集数据的分辨率。分辨率是连续信号的采样速率——采样越密集,数据分辨率越高,而采样越稀疏,信号数据的分辨率越低。
这一事实引发了一些有趣的现实世界考虑,例如模型学习到的表示是否独立于训练数据的分辨率。如今,模型无法推广到它们训练时的分辨率之外,例如,一个训练用于检测 5 毫秒传感器采样数据中的心律失常的模型,将无法推广到 2 毫秒的数据。因此,将机器学习应用于此类数据的一个重要问题是将任何训练过的模型推广到新的设置。通常,对于信号数据,新的设置将以数据采集策略的变化为特征。本论文考虑了仅限于数据采集分辨率的变化——其他变化可能包括采集数据的分布,以及传感器噪声和采样策略的变化。
重要的是,经过训练的模型能够优雅地处理分辨率的变化,而不会显著降低性能。这样的模型可能会超越特定的传感器选择(例如,麦克风设置中的音频采样率选择,或手机摄像头的选择),从而可以部署跨设备推广的模型。我们不想诉诸诸如子采样(例如,当面对比模型可能训练的分辨率更高的数据时)或插值(例如,当面对较低分辨率的数据时)之类的策略。对于前者,我们冒着丢失模型可能被训练识别的更细粒度信息的风险(例如,在 16kHz 和 8kHz 音频上训练并在 12kHz 音频上测试的模型)。而对于后者,我们冒着引入导致性能不佳的虚假特征的风险。
大部分机器学习文献根本不处理分辨率问题,而是将信号数据与离散数据等同对待——音频和文本被同等对待,尽管它们本质上根本不同。因此,信号数据机器学习的一个关键要求是开发对数据分辨率不敏感的序列模型。
挑战 2:信号数据的长度
第二个挑战来自于这样一个事实:信号数据代表着一长串不间断的信息流,因此很难在不丢失重要的空间或时间特征的情况下对其进行处理。信号数据通常非常长,因为它对应于连续值的物理信号,并且由于在获取此类数据时选择(通常)高采样率。大多数信号都包含高频信息,根据奈奎斯特采样定理 [112],保存这些信息需要使用高采样率。例如,由于声音中存在高频,因此音频(尤其是音乐)的采样率为 48kHz。
而且,即使信息主要存在于较低频率中,数据中仍可能存在非常长距离的依赖关系。例如,大气中的运动模式出现在非常不同的大空间和时间尺度上。建立一个准确的大气演变模型需要能够模拟这种长距离依赖关系的模型。
这些因素的结合导致了数据实例的长而密集的采样,而深度学习架构必须有效地处理这些数据实例。机器学习模型一直难以对这种长距离依赖关系进行建模——构成现代机器学习主力的标准模型系列并不能充分解决这些问题。例如,单个音轨的 20 秒就相当于近 100 万个音频样本——而如今的深度学习方法无法直接对其进行建模。而在组织病理学中,高分辨率成像可以产生千兆像素的图像,而这同样无法直接对其进行建模。在这两种情况下,模型都必须采用启发式方法来预处理输入以减少其长度,例如基于音频的傅里叶变换或基于图像块的先验。
总体而言,当今的机器学习不太适合长格式信号数据的需求。因此,处理长或大型信号数据实例时的一个关键要求是高效且高性能的建模架构。
挑战 3:信号数据的多样性
最后一个挑战是信号数据类型的多样性,每种类型都有独特的特征。这大大增加了通用或适应性机器学习模型的开发难度。这种多样性在过去要求采用量身定制的方法,以适应每种信号类型的特定细微差别,从音频频率的变化到 MRI 扫描中的复杂模式。特别是,序列模型系列更加专业化。例如,RNN 主要用于自然语言处理和时间序列建模,但并未广泛用于处理图像数据。另一方面,CNN 在图像建模方面非常受欢迎,但由于其局部背景,在对时间序列中的长距离模式进行建模方面通常效率较低。虽然过去几年,从业者所采用的建模架构已经有所整合,但对于信号数据,仍然没有通用的方法。
这与机器学习的长期目标形成鲜明对比,即提供可以用于任何类型数据的通用建模方法——“端到端”的概念很好地体现了这一点。这延伸到被建模数据的性质,无论它来自哪个领域。因此,最终的愿望是创建用于信号数据的通用建模技术,并展示它们对各种领域的适用性。
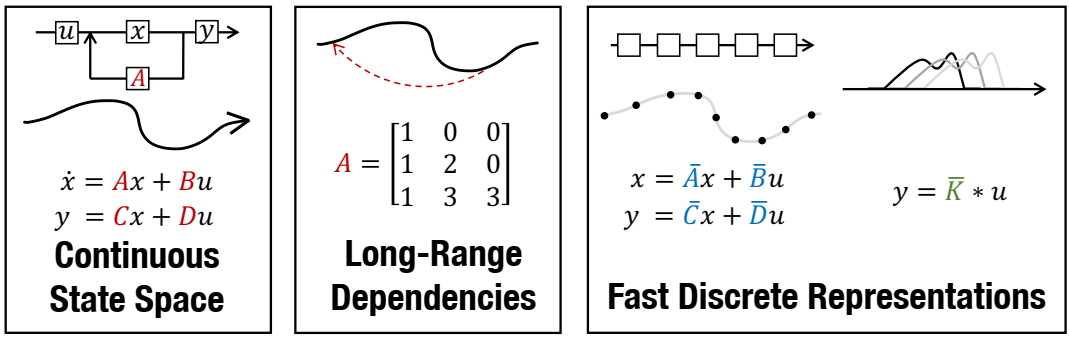 (左)由矩阵 A、B、C、D 参数化的状态空间模型 (SSM) 通过潜在状态 x(t) 将输入信号 u(t) 映射到输出 y(t)。(中)关于连续时间记忆的最新理论推导出特殊的 A 矩阵,允许 SSM 在数学和经验上捕获 LRD。(右)SSM 可以计算为递归(左)或卷积(右)。然而,实现这些概念视图需要利用其参数的不同表示(红色、蓝色、绿色),而这些表示的计算成本非常高。S4 引入了一种新颖的参数化,可以在这些表示之间高效切换,使其能够处理广泛的任务,在训练和推理方面都很高效,并且在长序列方面表现出色。
(左)由矩阵 A、B、C、D 参数化的状态空间模型 (SSM) 通过潜在状态 x(t) 将输入信号 u(t) 映射到输出 y(t)。(中)关于连续时间记忆的最新理论推导出特殊的 A 矩阵,允许 SSM 在数学和经验上捕获 LRD。(右)SSM 可以计算为递归(左)或卷积(右)。然而,实现这些概念视图需要利用其参数的不同表示(红色、蓝色、绿色),而这些表示的计算成本非常高。S4 引入了一种新颖的参数化,可以在这些表示之间高效切换,使其能够处理广泛的任务,在训练和推理方面都很高效,并且在长序列方面表现出色。
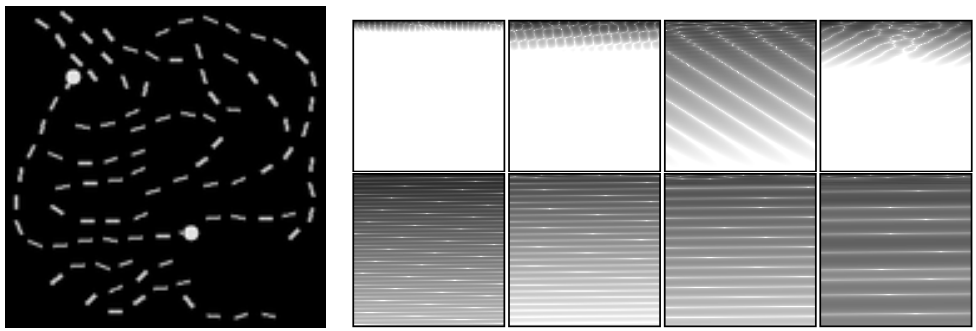
在 LRA Path-X 上对经过训练的 S4 模型进行可视化。SSM 卷积核 K ∈R16384 被重塑为 128 × 128 图像。(左)Path-X 任务中的示例,其中涉及推断标记是否通过路径连接(顶部)来自第一层的过滤器(底部)来自最后一层的过滤器。
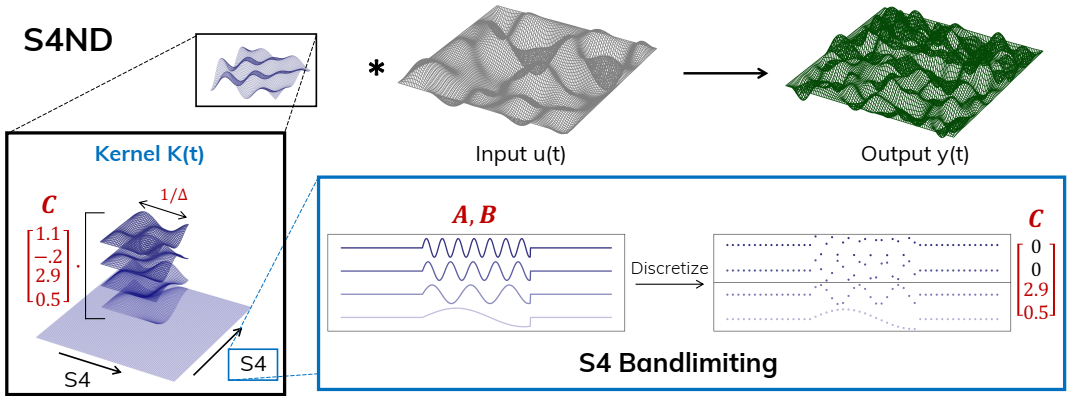 (S4ND。)(红色参数。)(顶部)S4ND 可以被视为深度卷积,它通过连续卷积核(蓝色)将多维输入(黑色)映射到输出(绿色)。(左下)内核可以解释为具有灵活宽度(由步长 ∆ 控制)的基函数(由 A、B 控制)的线性组合(由 C 控制)。对于结构化 C,内核可以进一步分解为 1D 内核的低秩张量积,并且可以解释为每个维度上的独立 S4 变换。(右下)适当地选择 A、B 可产生具有可控频率的傅立叶基函数。为了避免最终离散内核中的混叠,可以简单地屏蔽掉 C 中与高频相对应的系数。
(S4ND。)(红色参数。)(顶部)S4ND 可以被视为深度卷积,它通过连续卷积核(蓝色)将多维输入(黑色)映射到输出(绿色)。(左下)内核可以解释为具有灵活宽度(由步长 ∆ 控制)的基函数(由 A、B 控制)的线性组合(由 C 控制)。对于结构化 C,内核可以进一步分解为 1D 内核的低秩张量积,并且可以解释为每个维度上的独立 S4 变换。(右下)适当地选择 A、B 可产生具有可控频率的傅立叶基函数。为了避免最终离散内核中的混叠,可以简单地屏蔽掉 C 中与高频相对应的系数。
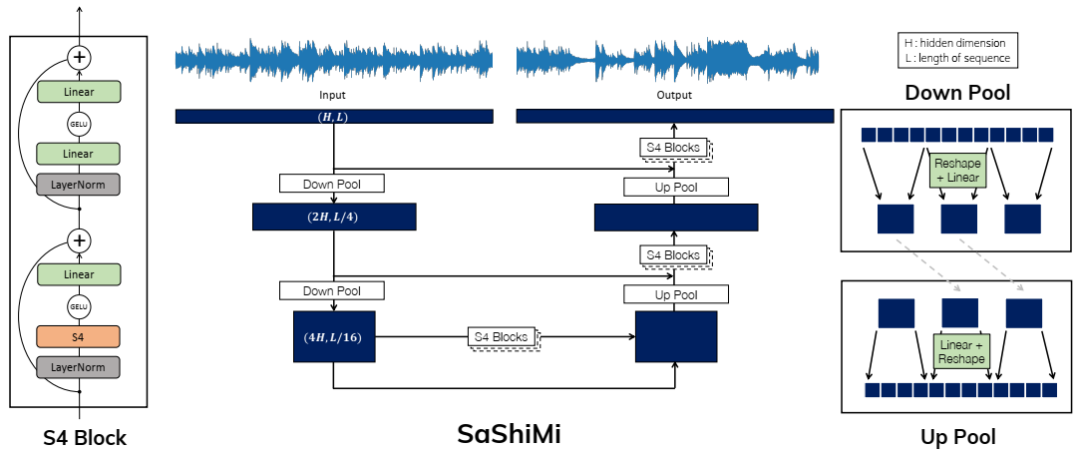
SaShiMi 由一个简单的重复块与多尺度架构相结合而成。(左)基本 S4 块由 S4 层与标准逐点线性函数、非线性和残差连接相结合而成。(中)深蓝色矩形表示输入的形状。输入通过池化层逐渐转换为更短更宽的序列,然后使用 S4 块堆栈转换回来。更长距离的残差连接有助于通过网络传播信号。(右)池化层是位置线性变换,并带有移位以确保因果关系。
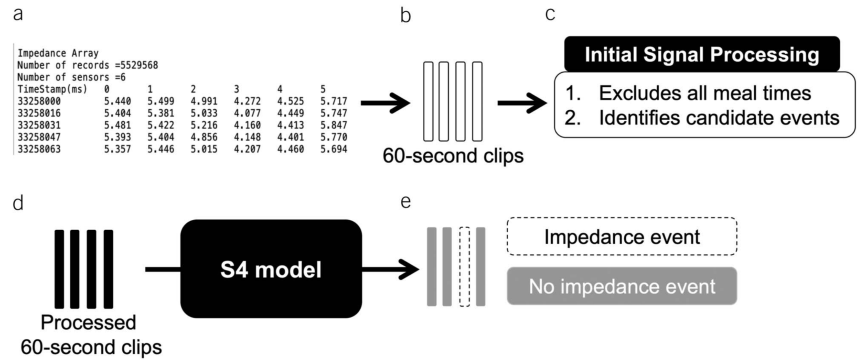 机器学习系统从 24 小时 pH/阻抗研究中检测阻抗事件的机制。(a) 从 6 个传感器的阻抗值阵列研究中提取阻抗数据,每个时间戳的阻抗值以毫秒 (ms) 为单位。(b) 这些数据被压缩为 60 秒的阻抗数据片段。(c) 初始信号处理步骤排除所有进餐时间,并通过使用峰值查找算法评估阻抗片段的阻抗降低来识别候选事件。(d) 将处理后的片段输入到 S4(结构化状态空间堆栈)模型中。(e) 该模型输出每个片段内是否发生阻抗事件的预测。
机器学习系统从 24 小时 pH/阻抗研究中检测阻抗事件的机制。(a) 从 6 个传感器的阻抗值阵列研究中提取阻抗数据,每个时间戳的阻抗值以毫秒 (ms) 为单位。(b) 这些数据被压缩为 60 秒的阻抗数据片段。(c) 初始信号处理步骤排除所有进餐时间,并通过使用峰值查找算法评估阻抗片段的阻抗降低来识别候选事件。(d) 将处理后的片段输入到 S4(结构化状态空间堆栈)模型中。(e) 该模型输出每个片段内是否发生阻抗事件的预测。
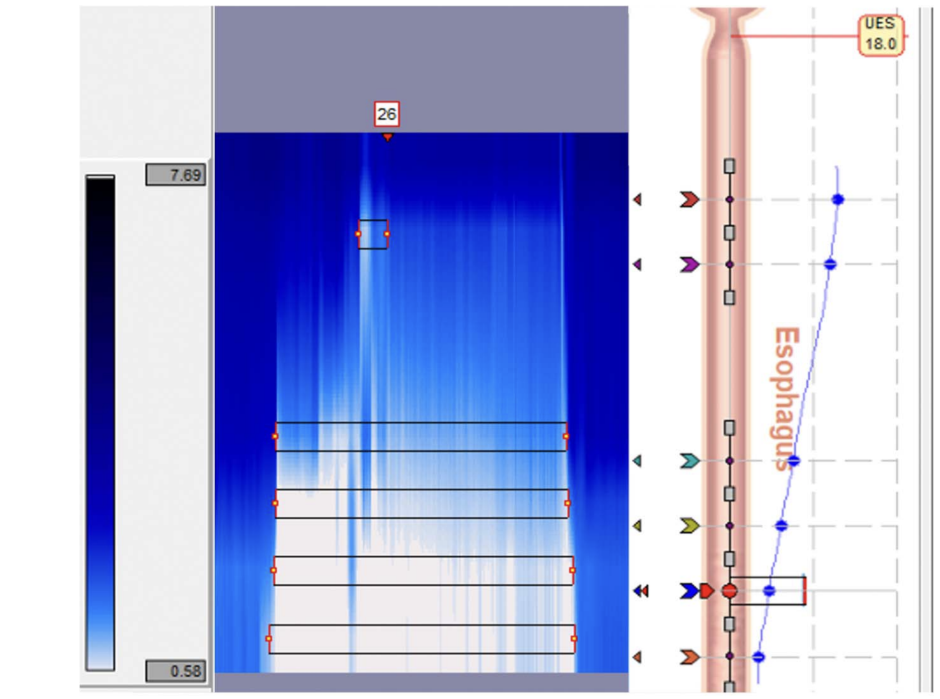 Reflux Reader v6.1 (Medtronic) 中 24 小时 pH/阻抗研究中的阻抗事件示例。阻抗下降(由阻抗图中的白色区域表示)表示发生反流事件。Reflux Reader v6.1 中的自动化软件可识别可能的反流事件,并以数字标记。此示例显示事件编号 26。UES,上食管括约肌。
Reflux Reader v6.1 (Medtronic) 中 24 小时 pH/阻抗研究中的阻抗事件示例。阻抗下降(由阻抗图中的白色区域表示)表示发生反流事件。Reflux Reader v6.1 中的自动化软件可识别可能的反流事件,并以数字标记。此示例显示事件编号 26。UES,上食管括约肌。
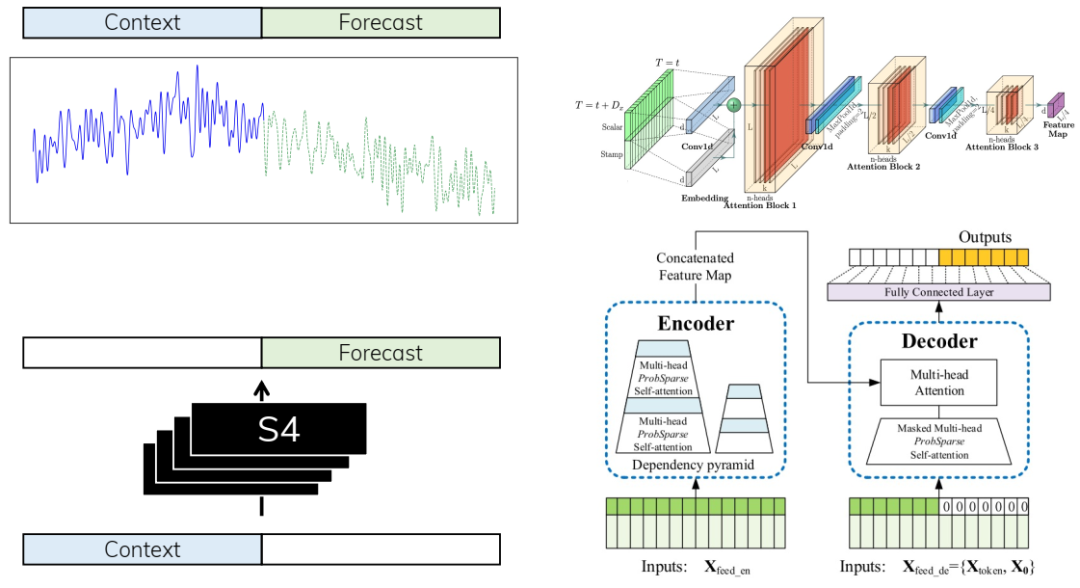 S4 与用于预测任务的专用时间序列模型的比较。(左上)预测任务涉及根据过去的背景预测时间序列的未来值。(左下)我们使用序列模型(例如 S4)作为黑匣子执行简单预测。(右)Informer 使用专为预测问题设计的编码器-解码器架构,涉及定制的注意力模块。
S4 与用于预测任务的专用时间序列模型的比较。(左上)预测任务涉及根据过去的背景预测时间序列的未来值。(左下)我们使用序列模型(例如 S4)作为黑匣子执行简单预测。(右)Informer 使用专为预测问题设计的编码器-解码器架构,涉及定制的注意力模块。







内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢