
本文分享阿里妈妈智能创作与AI应用团队关于视频解说生成的探索与实践,相关工作已应用在多个核心广告场景。基于该项工作整理的论文已被 ACL 2024 录用,欢迎阅读交流。
论 文:Synchronized Video Storytelling: Generating Video Narrations with Structured Storyline
作 者:Dingyi Yang, Chunru Zhan, Ziheng Wang, Biao Wang, Tiezheng Ge, Bo Zheng, Qin Jin
下 载:https://arxiv.org/abs/2405.14040
代 码:https://github.com/alibaba/alimama-video-narrator
1. 背景
在短视频时代,视频剪辑是视频创作的核心环节,如何迅速抓住观众的注意力,传达关键信息、有效地组织视频内容是剪辑的关注的核心,人工剪辑依赖丰富的视频制作经验,剪辑的时间成本高。我们针对自动化视频剪辑方案做了长期探索,通过视频理解、视频结构分析、解说生成等多个模块,将视频剪辑的链路自动化,实现利用已有视频素材创造出新的叙事方式和视觉体验;将多个主题或事件结合在一起,呈现出更全面、丰富的内容,提升视频的多样性。与传统的视频拆分后直接拼接的方案相比,我们可以生成高质量的解说旁白,并与画面展示内容匹配,保证视频的逻辑完整和叙事一致,自动剪辑出高质量视频。
在电商领域,视频的解说内容与商品高度相关,基于电商场景视频的结构特点,我们重新定义、设计了基于故事线结构的视频脚本生成算法,利用多模态大模型生成高质量的电商视频解说。
2. 任务定义
Synchronized Video Storytelling:基于给定的商品信息、视频以及剧本结构,生成商品的解说旁白。要求旁白介绍的内容需要与商品相关、内容丰富、解说旁白连贯、视频画面与解说有相关性等。
目前常见的相关任务有 Dense Video Captioning、Video Storytelling等,不同任务的对比如下图所示:

各个任务间具体差异为:
Dense Video Captioning :为视频中的多个事件生成相应的叙述。各个片段之间没有直接相关性 ,所有的描述(caption)都是独立的。
Video Storytelling:目标是形成一个连贯的故事,根据视频的画面描述出现的人物和动作。
Synchronized Video Storytelling:生成同步的、信息丰富的和连贯的叙述,作为视频的解说,解说可以直接作为视频播放的旁白,需要对视频画面背后的行为有深入理解。
3. 核心亮点
面向目前短视频制作过程中面临的实际问题,我们提出了新的视频故事线生成任务、数据集和生成算法(VideoNarrator),以素材理解为基础,保证解说的连贯性和内容丰富度。核心亮点包括:
1)我们引入了一个新的任务——视频解说生成,这一任务更加具有挑战性,因为它要求为给定视频生成一个与画面匹配的、信息丰富的和连贯的解说内容。
2)为了支持这一任务,我们在广告领域构建了一个数据集,即E-SyncVidStory,该数据集包含丰富的标注内容,包括标视频内容、片段标签、解说等内容。并且该数据集可以支持视频叙事(Video Storytelling)等相关任务的研究。
3)我们提出了一个有效的视频解说生成模型(VideoNarrator),通过输入相关知识和视频序列,即可生成视频解说,同时支持基于故事线控制视频解说的生成结构。
4)我们设计了一套系统化的评估指标,用于全面衡量解说生成的质量。最后通过自动和人工评估的方式验证了该方法的有效性。
4. 数据集(E-SyncVidStory Dataset)
4.1 数据收集
我们选择高点击率的高质量广告视频,并理解视频的逻辑结构以及相关的商品信息。主要的环节如下:
商品相关信息:包括商品名、成分、使用人群、效果等,针对不同的类目具有不同的信息抽取逻辑。
视频:我们利用视频事件理解算法自动将每个视频切分为顺序视频片段,每个片段内部描述同一个事件标签(如:商品外观介绍、成分说明等)。
音频:通过自动语音识别(ASR)获得视频的解说和每句话对应的时间点。
矫正:ASR识别的解说内容可能存在少量错误,我们使用GPT-4来纠正错误并为每个解说内容按照脚本标签分类。接着,我们招募众包人员再次检查和修正解说内容,校正脚本标签。
通过这种方式,我们构建了E-SyncVidStory数据集,其整体结构如下图所示:
4.2 数据集统计与分析
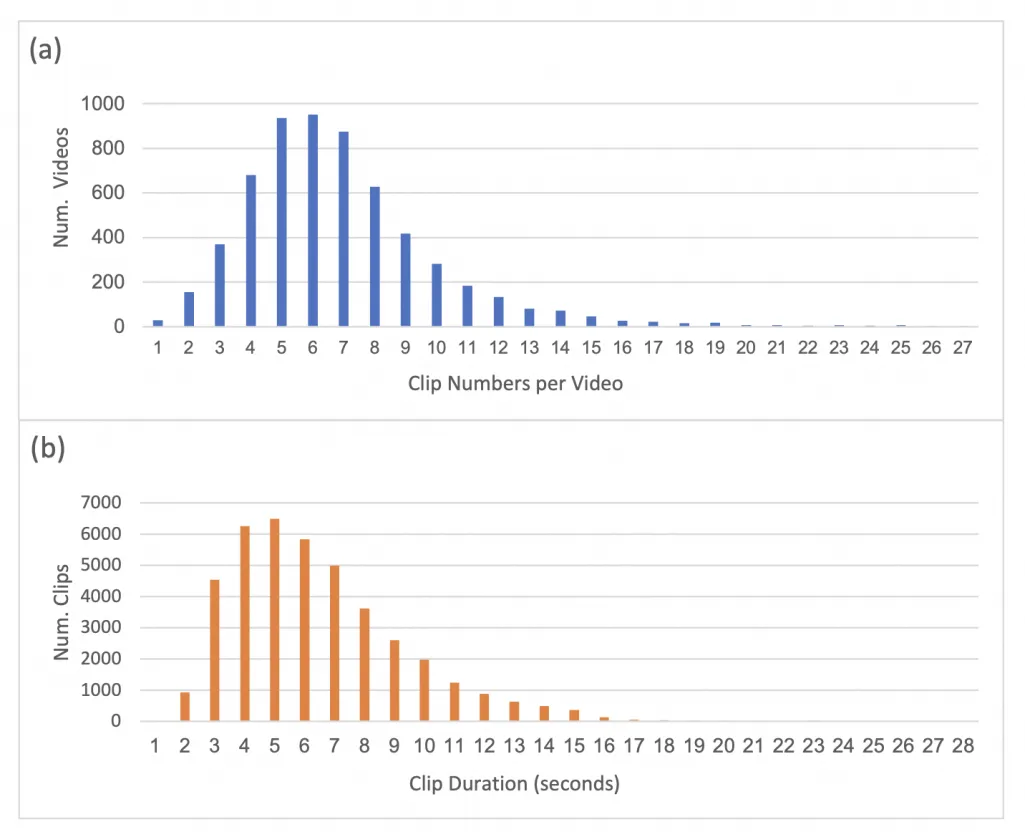
E-SyncVidStory包含6,032个视频,总计41,292个视频片段。其内容覆盖了多个电商类目,包括个人护理、美妆、男女服饰、家居用品、母婴以及电子产品等多个行业。视频长度从2秒到220秒不等,平均长度为39秒,平均文本长度为194个单词。如下图(a)所示,每个视频中的片段数量差异很大。因此我们在模型设计时应用了视频片段相位置embedding。视频片段的持续时间显示下图(b)中:
5. 方案设计
在有了一定的画面展示的基础上,我们认为在用户观看视频的过程中,主要关注点在于视频解说,解说可以串联整个视频,并且为观看者提供主线和主题的关键信息。生成解说主要有两个步骤:
1)预处理:理解商品信息,并抽取商品名、成分、功效等关键信息;分析商品相关视频,对视频内容进行理解和拆分,主要依赖视频事件检测和转场检测等基础算法(数据结构可参考数据集构建部分)。
2)解说生成:我们设计了VideoNarrator 多模态架构,该架构基于视觉特征提取器、视频编码和LLM几个部分。
视频输入:对每个视频片段取帧,以图片embedding的方式输入到LLM中,一个视频的多个片段embedding拼接在一起。
特征提取:在为视频片段N生成解说时,之前的帧被组合成固定长度的视频tokens,并与当前帧的tokens拼接在一起。我们设计了一个投影模块,将视觉特征和相对视频剪辑位置embedding输入到视频投影器(Video Projector),生成完整的视频embedding。基于视觉embedding和其他文本信息,LLM将生成一个合适的脚本标签,并应用它来指导解说的生成。
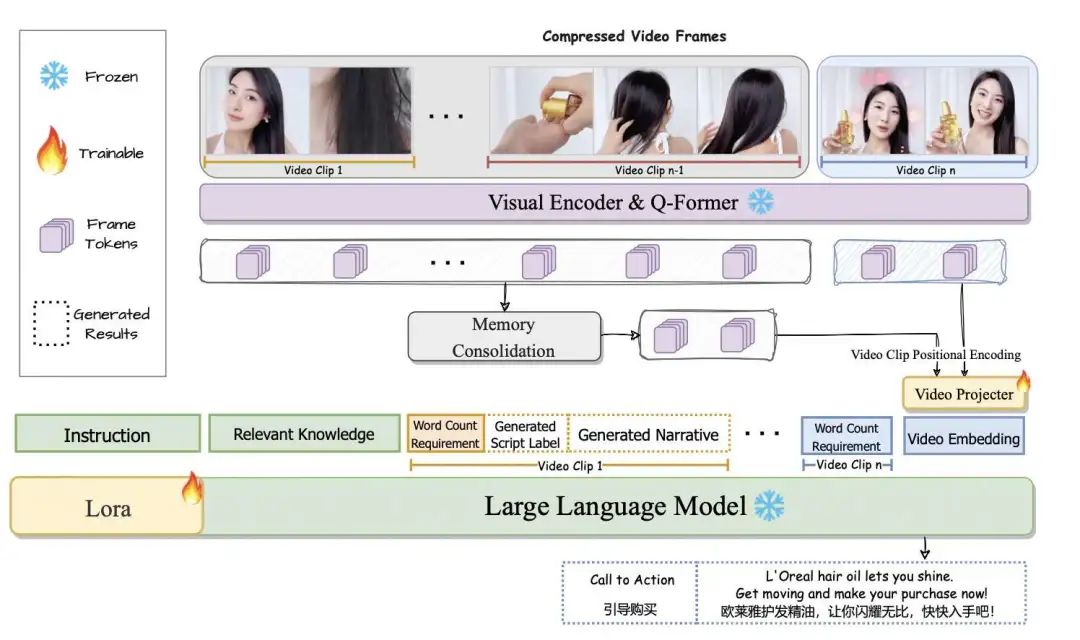
详细方案
视觉编码器:采用CLIP-L/14,对从视频选出的每一帧进行编码。
视觉投影方案:利用BLIP-2的Q-Former模块提取视频特征,这些特征已经与文本模态很好地对齐。
视频token拼接:由于输入所有视频帧会导致显著的计算复杂性和内存使用。但是在生成后续的解说时,需要参考到前一步的结果,所以我们将来自先前剪辑的视觉信息拼接到当前所使用片段的前面。
视频压缩:考虑到视觉信息的冗余性,我们首先通过去除相似度高于阈值 τ 的相邻帧,来压缩视频片段。重复这个过程,直到每对相邻帧之间的相似度降到 τ 以下。
记忆整合:对于由多个视频片段组成的长视频,在为当前片段 vi 生成叙述时,我们只需要之前视频片段的更简洁信息。我们通过合并最相似的视觉标记来进行记忆整合,维持固定长度的token作为视觉记忆单元。在处理每个片段时都会重复合并过程,直到之前视频片段的记忆标记达到要求的长度。
视频片段位置编码:每个视频片段的相对位置在视频故事生成中是很重要的。例如,当接近视频末尾时,更需要激发观众的购买欲望,而不是介绍产品。因此,我们提出了相对片段位置嵌入embedding,并将其添加到视频embedding中。如果一个片段位于整个视频的 p% 位置,那么 p 就是它的相对位置。这个值 p 会经过一个位置嵌入层,该层的参数在训练过程中会被更新。然后,将编码后的位置信息添加到视觉嵌入中。
LLM提示词(Prompting):对于每个视频片段,强调模型应主要使用提示中提供的信息,避免使用 LLM 中无关或与商品不符合的世界知识。prompt示例如下:

6. 实验效果
6.1 方案对比
我们将我们的模型与以下baseline进行比较:
1)多模态大模型:我们应用 LLaVA为视频片段生成描述,并利用 GPT-3.5 进行zero-shot 和few-shot 生成。
2)端到端 MLLMs(不微调):包括 Video-ChatGPT、Video-LLaVA和 VTimeLLM,LLM选择 7B。这些模型将视频作为输入,并以端到端的方式生成解说。
3)端到端MLLMs(微调后):我们微调了 VTimeLLM 模型,该模型在密集视频理解(dense video comprehension)方面效果显著,并支持中文生成。
数据结果如下: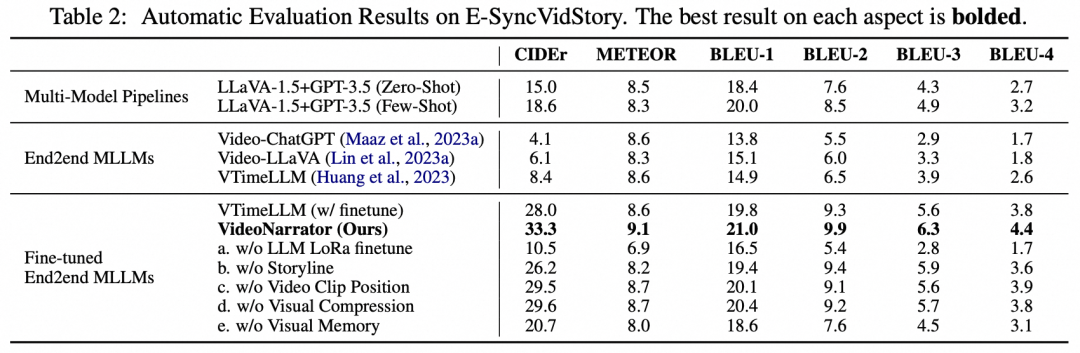
6.2 人工评估
我们在三个指标上进行人工评估:
1)视觉相关性:衡量生成的叙述与视频镜头之间的关系。
2)吸引力:衡量故事多大程度上能引起用户的兴趣。
3)连贯性:衡量句与句之间的连贯性。
在这几个指标中,人工评估质量整体上优于GPT4V+GPT4的结果:

6.3 通用领域(非电商)视频解说生成
为了验证我们提出的VideoNarrator的有效性,我们在通用领域的视频讲述数据集上进行了实验。我们对数据集进行了小幅调整,以适应当前任务设置(将标签中的文本长度作为解说的长度要求,并使用视频主题作为输入到LLM的“相关知识”)。实验表明我们的模型超过了SOTA,证明当前方案可在更广泛的领域生成优质视频解说。在Video Storytelling任务上测试的结果:

6.4 可视化结果
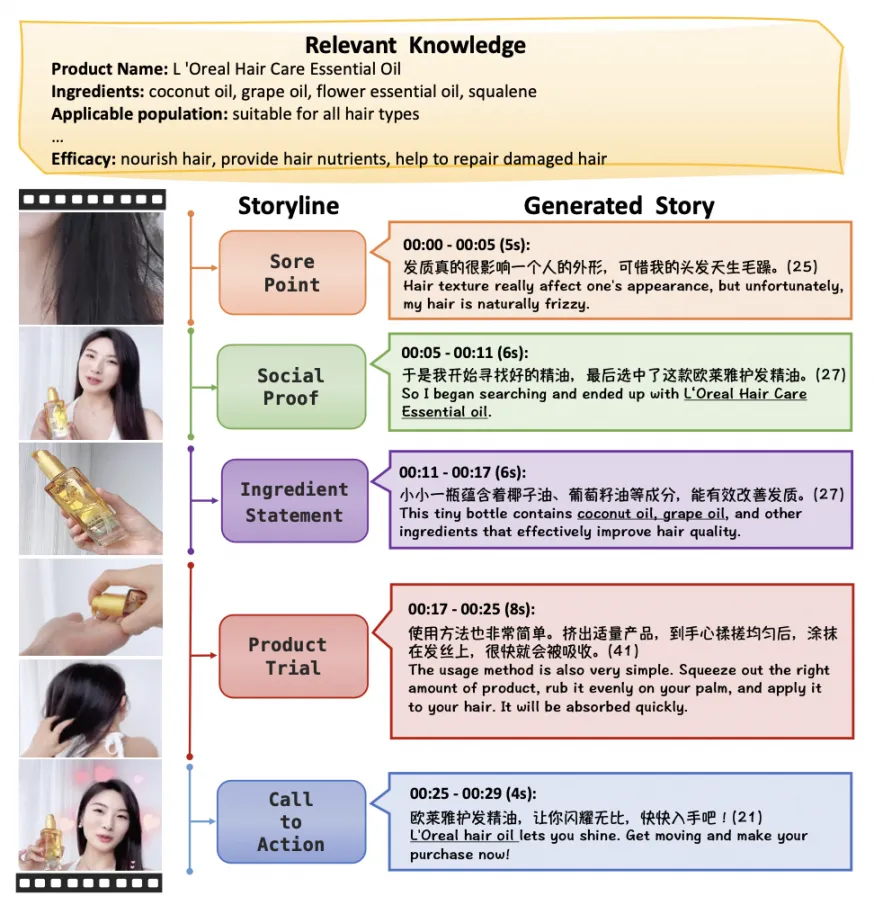
下面是一段完整的生成视频(截取部分画面作为参考),生成的解说可以跟视频内容较好地匹配,符合电商场景介绍商品的特点,与数据集(E-SyncVidStory)中介绍商品的逻辑和风格一致。

7. 总结与展望
电商视频解说算法直接应用于视频剪辑工具、素材推荐、黑盒投放等多种形式, 广泛应用于电商广告投放场景。我们基于给定视频序列,为其生成优质的解说,实现自动化地制作高质量的剪辑视频。然而当前仍然面临一些多模态大模型应用过程的普遍问题,如模型容易产生幻觉、指令遵循能力弱等。未来我们考虑加入更多的约束条件,探索更加合理的视频理解和解说生成架构,持续提升自动剪辑的视频质量。
▐ 关于我们
我们是阿里妈妈智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入我们!
✉️ 简历投递邮箱:alimama_tech@service.alibaba.com

也许你还想看

喜欢要“分享”,好看要“点赞”哦ღ~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢