

新智元报道
新智元报道
【新智元导读】大模型幻觉,究竟是怎么来的?谷歌、苹果等机构研究人员发现,大模型知道的远比表现的要多。它们能够在内部编码正确答案,却依旧输出了错误内容。
到现在为止,我们仍旧对大模型「幻觉」如何、为何产生,知之甚少。

最近,来自Technion、谷歌和苹果的研究人员发现,LLM「真实性」的信息集中在特定的token,而且并得均匀分布。
正如论文标题所示,「LLM知道的往往要比表现出来的更多」。

论文地址:https://arxiv.org/pdf/2410.02707
不仅如此,他们还发现,内部表征可以用来预测LLM可能会犯错的错误类型。
它的优势在于,未来有助于开发出针对性的解决方案。
最后,研究团队还解释了,大模型内部编码和外部行为之间存在的差异:
它们可能在内部编码了正确答案,却持续生成错误答案。
幻觉,如何定义?
事实错误、偏见,以及推理失误,这些统称为「幻觉」。
以往,大多数关于幻觉的研究,都集中在分析大模型的外部行为,并检查用户如何感知这些错误。
然而,这些方法对模型本身如何编码、处理错误提供了有限的见解。

近期另有一些研究表明,LLM内部状态其实「知道」那些输出可能是错误的,而且这种「知识」被编码在模型内部状态中。
这一发现可以帮助提高错误检测的性能,并进一步缓解这些问题。
不过其中一个缺陷是,这些研究主要集中了检验模型生成最后一个token、或提示符中最后一个token。
由于LLM通常会生成长篇的相应,因此这一做法可能会错过关键细节。
在最新研究中,研究团队采取了不同的方法:
不只是看最终的输出,而是分析「确切的答案token」,如若修改,将会改变答案的正确性的相应token。
最终证明了,LLM内部表征所包含的真实性信息,比以往要多得多。
但这种错误检测器难以在不同数据集之间泛化,这说明真实性编码并非统一的,而是多方面的。
更好的错误检测
给定一个大模型M,输入提示p、模型生成的响应ŷ,任务预测ŷ是正确还是错误的。
假设可以访问LLM内部状态(即白盒设置),但不能访问任何外部资源(如搜索引擎或其他LLM)。
数据集使用的是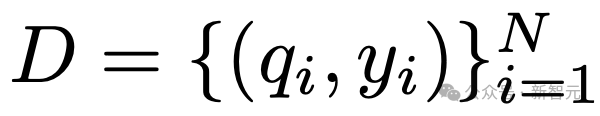 ,包含N个问题-标签对,
,包含N个问题-标签对,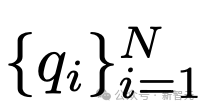 代表着一系列问题,
代表着一系列问题,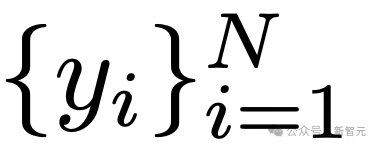 代表着对应的真实答案。
代表着对应的真实答案。
对于每个问题q_i,作者让模型M生成响应y_i,得到预测答案集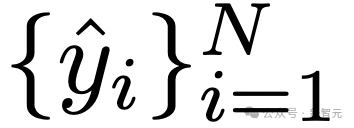 。
。
接下来, 研究人员构建了错误检测数据集,通过将每个生成的响应ŷ_i与真实标签y_i比较,以评估其正确性。
比较结果会产生出一个正确的标签z_i ∈ {0, 1}(1表示正确,0表示错误)。
这种比较可以通过自动启发式方法,在指令型LLM的协助下完成。
最终的错误检测数据集为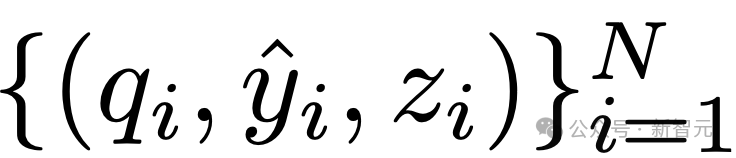 。其排除了LLM拒绝回答的情况,因为这些可以轻易地被分类为错误。
。其排除了LLM拒绝回答的情况,因为这些可以轻易地被分类为错误。
接下来,研究人员在Mistral 7B和Llama 2模型的四个变体上进行了实验。
这些模型跨越了十个数据集,涵盖了各种任务。
其中包括问答、自然语言推理、数学问题解决、情感分析。
他们允许模型生成不受限制的响应,来模拟真实世界的使用情况。
这里,一共用到了三种错误检测方法:Aggregated probabilities / logits、P(True)、Probing。
精确答案token
现有的方法经常忽略一个关键的细微差别:用于错误检测的token选择,通常关注最后生成的token或取平均值。
然而,由于大模型通常会生成长篇回复,这种做法可能会错过关键细节。
还有一些方法使用提示最后的一个token,但本质上是不正确的,因为大模型的单向性,未能考虑生成响应和丢失的情况,其中同一模型的不同采样答案在不同情况下,有所不同正确性。
对此,研究人员检查了以往未经检查的token位置:确切的答案token,代表生成响应中最有意义的部分。
他们将精确答案token定义为那些修改会改变答案的正确性token,而忽略了后续生成的内容。
如下图图1,说明了不同的token位置。

实验结果
真实性编码模式
研究人员首先专注于探索分类器,以了解LLM的内部表征。
具体来说,广泛分析了层和token选择对这些分类器激活提取的影响。这是通过系统地探测模型的所有层来完成的,从最后一个问题token开始,一直到最终生成的token。
下图2显示了Mistral-7b-Instruct各个层和token中经过训练的探测器的AUC指标。
虽然,某些数据似乎更容易进行错误预测,但所有数据集都表现出一致的真实性编码模式。
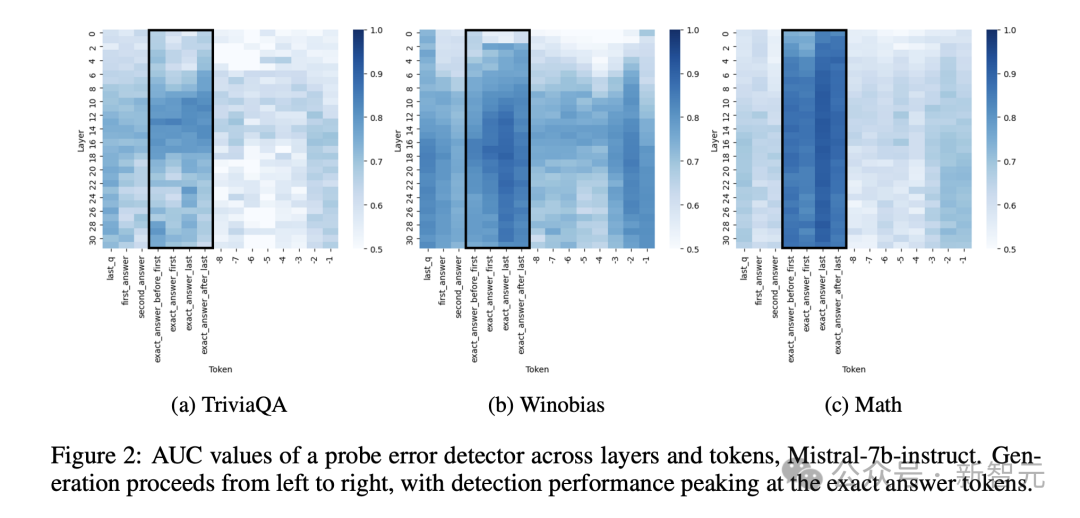
对于token来说,提示后立即出现了强烈的真实性信号,表明这种表征编码了有关模型正确回答问题的一般能力的信息。
对着文本生成的进行,该信号会减弱,但在确切的答案token处,再次达到峰值。
再生成过程即将结束时,信号强度再次上升,表明了该表征编码了整个生成过程的特征,尽管它仍弱于确切答案token。
错误检测结果
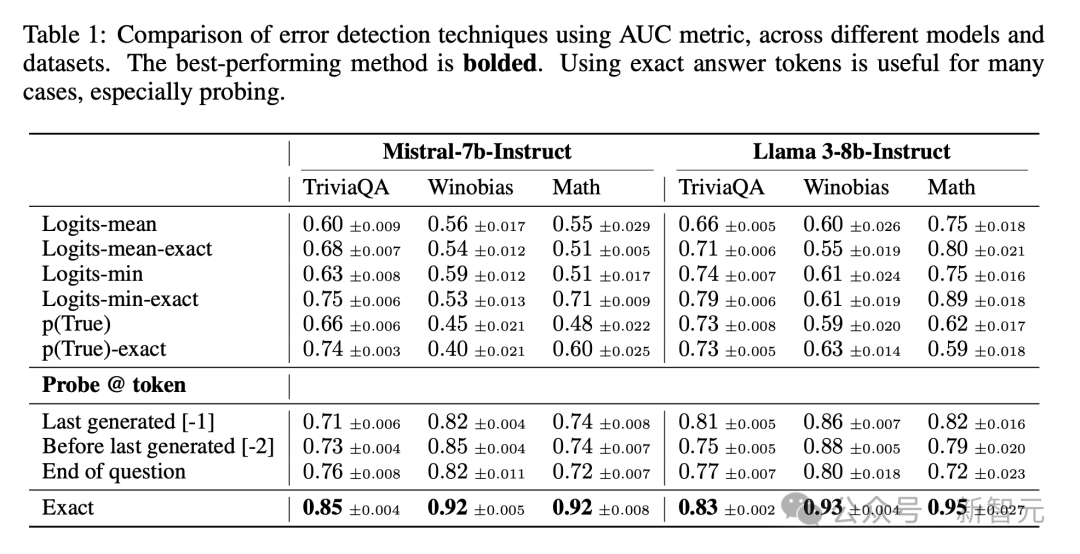
接下来,研究人员通过比较使用、不使用精确答案token的性能,来评估各种错误检测方法。
表1比较了三个代表性数据集的AUC。
在这里,他们展示了最后一个精确答案token的结果,它的性能优于第一个精确答案token及其前面的token,而最后一个精确答案token之后的token性能类似。
合并精确答案token,有助于改进几乎所有数据集中的不同错误检测方法。
任务之间的泛化
以上,探测分类器在检测错误方面有效性,表明了大模型对其输出的真实性进行了编码。
但目前仍不清楚的是,它们跨任务的通用性。
然而,理解这一点对于实际应用至关重要,因为错误检测器可能会遇到与训练时完全不同的示例。
因此,研究人员探讨在一个数据集上训练的探测器,是否可以检测其他数据集的错误。
如下图3显示了Mistral-7b-Instruct的泛化结果。在这种情况下,高于0.5的值表明泛化成功。
乍一看,结果似乎与之前的研究一致:大多数热图值超过0.5,这意味着跨任务具有一定程度的泛化性。
然而,再仔细检查,发现大部分性能可以通过基于logit的真实性检测来实现,该检测仅观察输出logits。
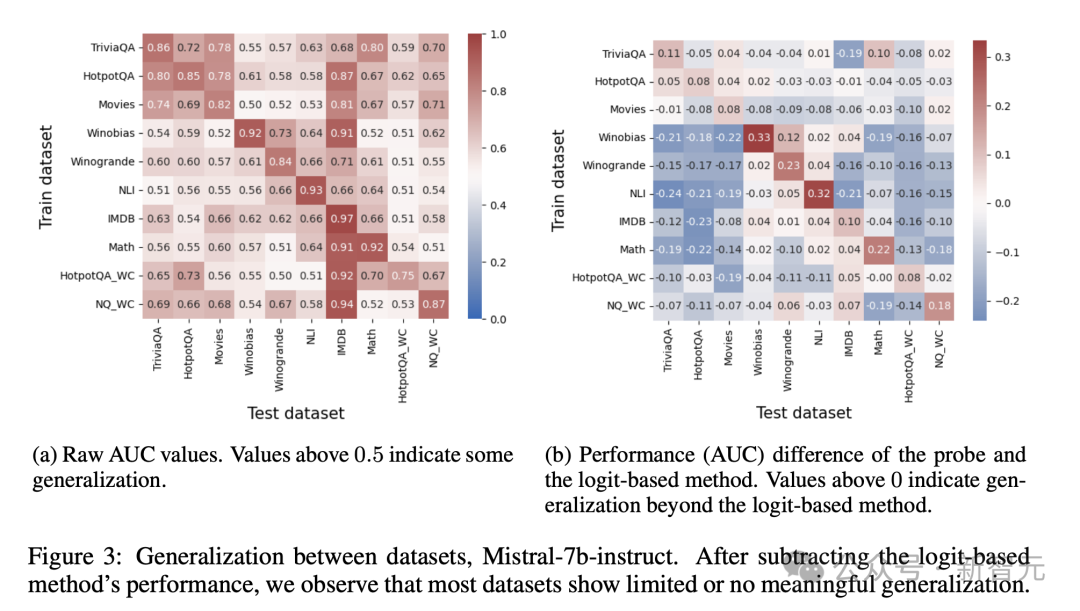
图3b显示了从最强的基于Logit的基线(Logit-min-exact)中减去结果后的相同热图。
这张 调整后的热图揭示了探测器的泛化能力很少超过单独检查 logits所能达到的效果。
这意味着明显的概括并非源于真实性的普遍内部编码,而是反映了已经可以通过逻 辑等外部特征获取的信息。
调查错误类型
在确定了错误检测的局限性后,研究人员转向错误分析。
错误分类
图4说明了,三种代表性的错误类型。
在其中一个(图4a)中,模型通常会给出正确的答案,但偶尔会出错,这意味着存在正确的信息,但采样可能会导致错误。
在第二种类型中(图4b),模型经常做出错误的响应,尽管它能够提供正确的答案,这表明尽管不断犯同样的错误,但仍然保留了一些知识。
在第三种类型中(图4c),模型生成了大多数答案都是错误的,反映出对任何生成的答案的信心较低。
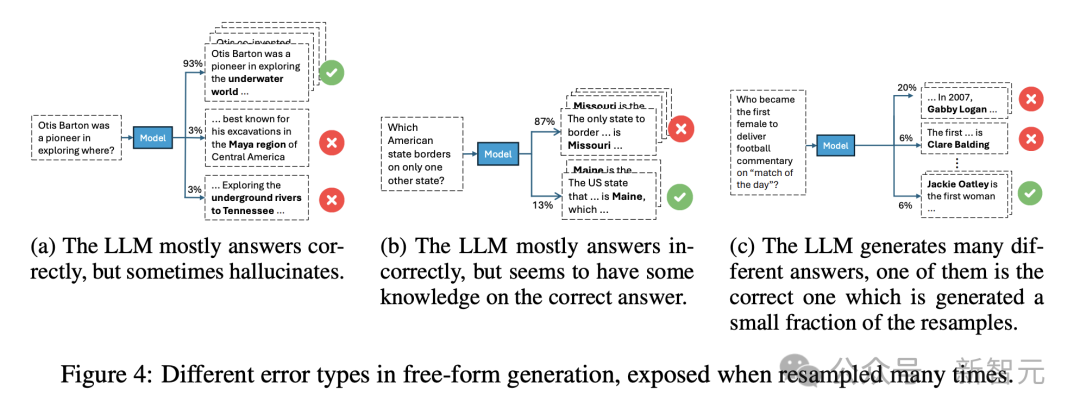
研究人员通过记录每个示例的三个特定特征来对错误进行分类:(a)生成的不同答案的数量;(b) 正确答案的频率;(c) 最常见的错误答案的频率。
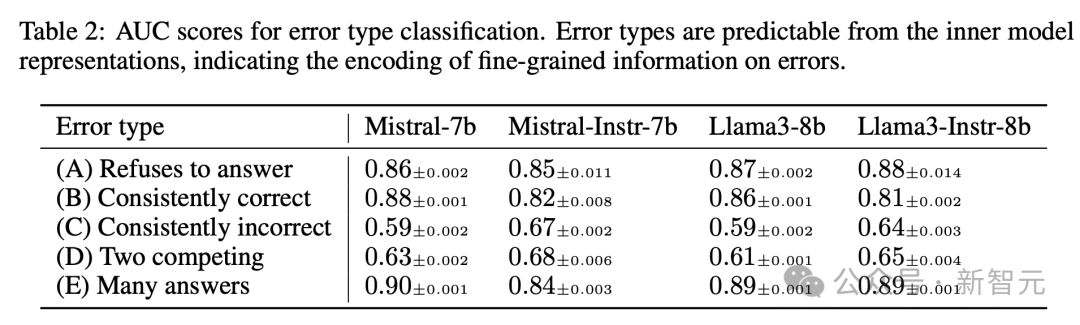
预测错误类型
表2列出了所有模型的测试集结果。
检测正确答案
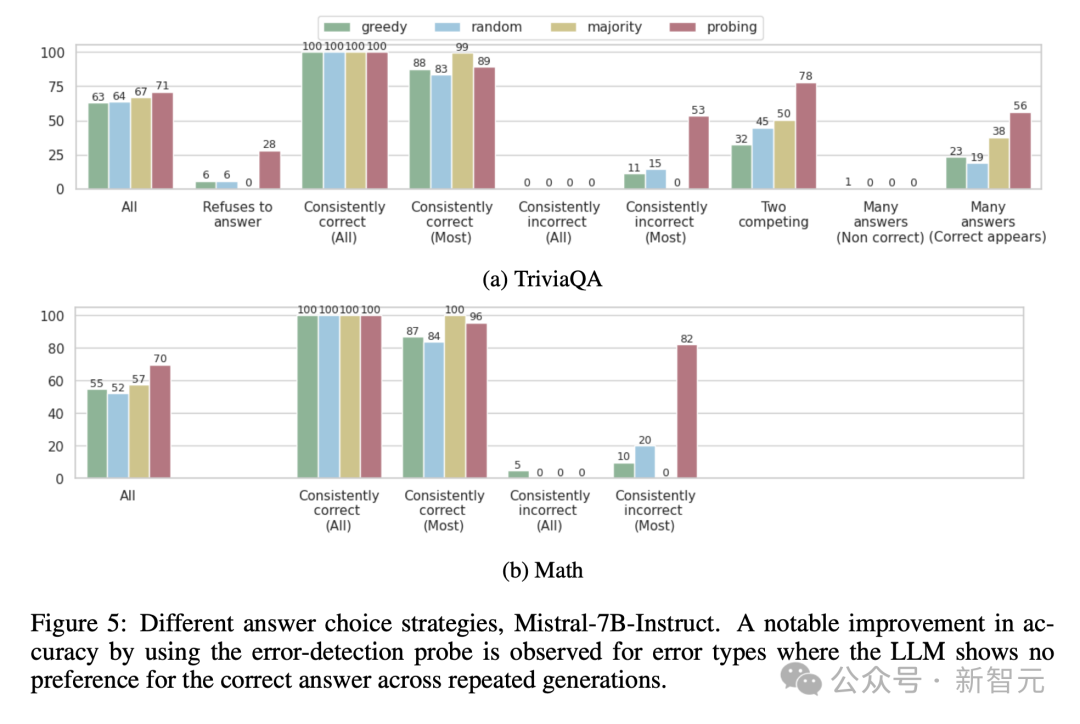
最后,在确定模型编码各种与真实性相关的信息后,作者又研究了这种内部真实性,如何在响应生成过程中,与外部行为保持一致。
为此,他们使用了探测器(5个经过错误检测训练),从针对同一问题生成的30个响应中,选择一个答案。
然后,根据所选答案来衡量模型的准确性。
Mistral-7b-instruct的结果如下图5所示,总体而言,使用探测器选择答案可以提高大模型在所有检查任务中的准确性。
总之,这项研究的发现,可以帮助未来研究人员去设计更好的幻觉环节系统。
遗憾的是,它使用的技术需要访问内部LLM表征,这也主要适用于开源模型的使用。
https://venturebeat.com/ai/study-finds-llms-can-identify-their-own-mistakes/



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢