

开放信息抽取(OpenIE)是自然语言处理中的一项关键任务,旨在从开放领域的非结构化文本中提取结构化的关系三元组。这项技术非常适合许多开放世界的自然语言理解场景,例如问答系统、知识库/知识图谱构建、显式推理和文本摘要。与在可预测领域中具有预定义本体结构的封闭信息抽取(IE)任务不同,OpenIE的目标是以开放形式提取简洁但具有意义的实体和关系。因此,所提取三元组中的关系、主语/宾语的格式更加灵活,从而增加了评估的难度。同时,OpenIE的模式学习也极具挑战性,因为缺乏充足的金标准训练数据。现有的OpenIE模型通常通过无监督或远程监督的方式进行训练,因此所学得的模式往往不如金标准的效果。
在本论文中,我们提出了多种创新方法以应对OpenIE模式学习中的挑战。我们方法的核心主题是利用各种类型的上下文来提升OpenIE的表现。首先,我们提出通过文档级上下文来改进OpenIE。作为一项新任务,我们引入了DocOIE,这是第一个用于评估文档级OpenIE系统的专家标注数据集。在此背景下,我们提出了一种名为DocIE的神经OpenIE系统,可以利用文档级上下文来提取关系三元组。其次,我们研究了如何使用额外的句法信息作为外部上下文来改进OpenIE。我们设计了一种新策略,将组成树中的短语级关系映射为词级关系,并通过句法路径信息增强每个词的表示。我们提出了SMiLe-OIE,这是第一个通过GCN编码器和多视角学习结合异构句法信息的神经OpenIE系统。第三,我们研究了如何提升OpenIE的效率和适应性。相应地,我们提出了一种新颖的"句子-块序列"(SaC)概念作为OpenIE的中间层,同时提出了Chunk-OIE,一种端到端的学习模型,该模型(i)将句子表示为SaC,并(ii)基于SaC提取三元组。通过与金标准三元组的数据分析,我们展示了块在OpenIE中提供了一种合适的标记跨度粒度。最后,我们提出并研究了一个新的研究任务,通过链接推测检测和OpenIE来检验OpenIE的可靠性。具体而言,我们提出检测三元组级推测,以确保OpenIE仅提取事实信息。为此,我们提出了SpecTup,一个用于检测三元组级推测的基线模型,结合语义(BERT)和句法(子依赖图)表示。
总之,尽管OpenIE问题已被确立并广泛研究,本论文为进一步改进OpenIE贡献了几个关键思想和概念。此外,本论文也为未来OpenIE的研究方向提供了有前景的启示。

论文题目:Incorporating contexts to open information extraction
作者:Dong, Kuicai
类型:2024年博士论文
学校:Nanyang Technological University(新加坡,南洋理工大学)
下载链接:
链接:https://pan.baidu.com/s/1deL_XdZjnggf4LPD-6qXNw?pwd=vetv
硕博论文汇总:
链接: https://pan.baidu.com/s/1Gv3R58pgUfHPu4PYFhCSJw?pwd=svp5
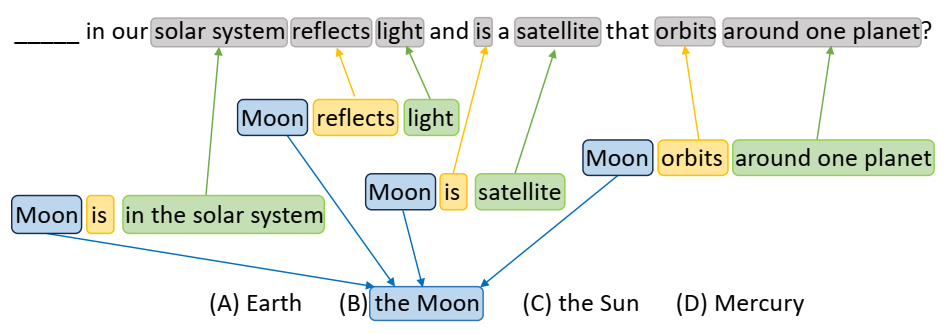 摘自阿拉斯加州科学测试的多事实推理问题 [1]。提供的插图描绘了一个支持图,该图建立了位于顶部的问题、源自 OpenIE 派生知识的四个彩色元组和一个潜在答案选项(“月亮”)之间的联系。
摘自阿拉斯加州科学测试的多事实推理问题 [1]。提供的插图描绘了一个支持图,该图建立了位于顶部的问题、源自 OpenIE 派生知识的四个彩色元组和一个潜在答案选项(“月亮”)之间的联系。
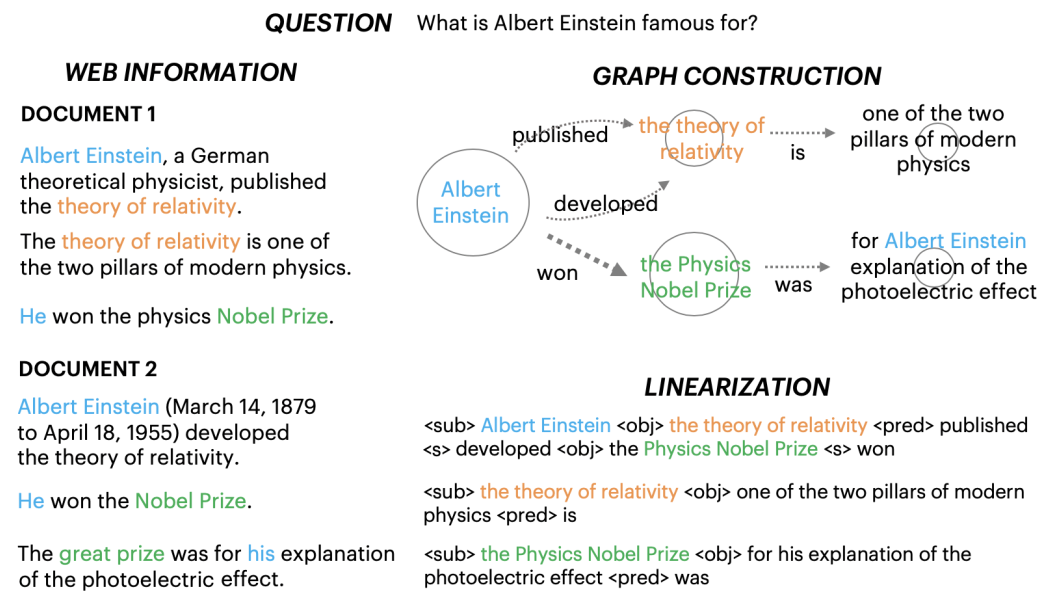 Fan 等人 [2] 的“文本到元组到图形”过程的说明。利用 OpenIE 和共指解析技术将多文档转换为结构化知识库。随后,将此知识库线性化为顺序格式,并作为模型的输入。
Fan 等人 [2] 的“文本到元组到图形”过程的说明。利用 OpenIE 和共指解析技术将多文档转换为结构化知识库。随后,将此知识库线性化为顺序格式,并作为模型的输入。
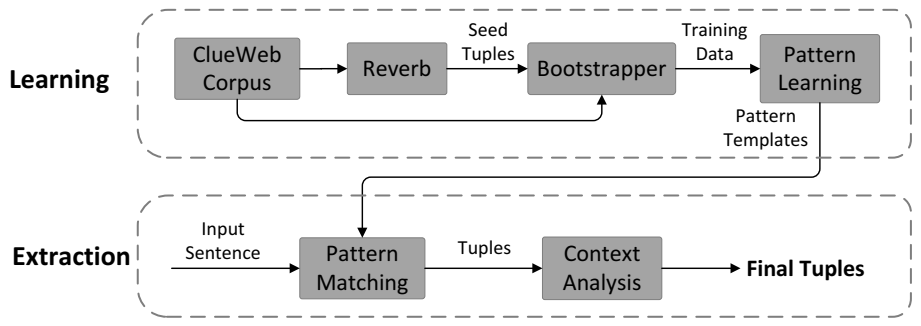 OLLIE的系统原理图[3]。
OLLIE的系统原理图[3]。
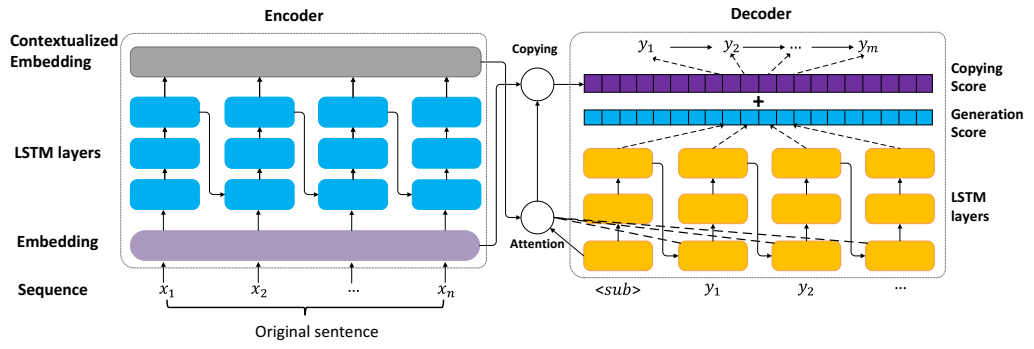 CopyAttention 的系统架构 [5]。编码器-解码器框架将输入序列编码为上下文化表示,并在解码器中使用它们来生成输出元组。注意机制用于获取解码的上下文向量,复制机制用于直接从输入序列中复制单词。
CopyAttention 的系统架构 [5]。编码器-解码器框架将输入序列编码为上下文化表示,并在解码器中使用它们来生成输出元组。注意机制用于获取解码的上下文向量,复制机制用于直接从输入序列中复制单词。
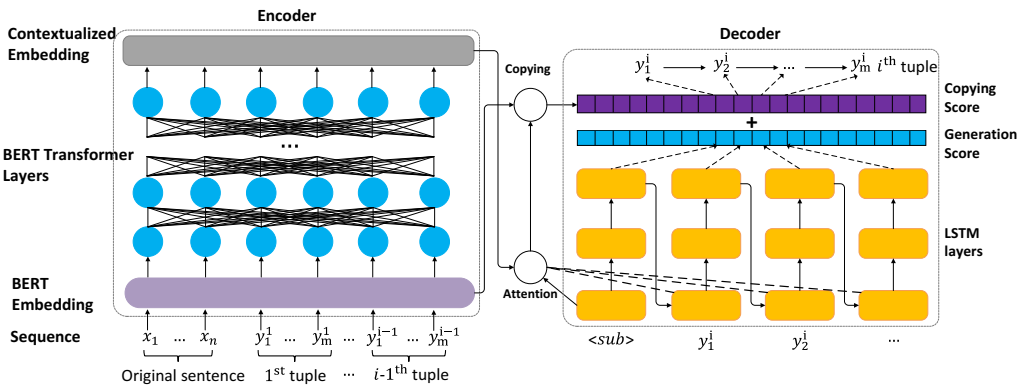 IMoJIE [6] 的系统架构。输入词的 BERT 嵌入和先前生成的元组被迭代解码以获取下一个元组。为了生成第 i 个元组,解码器采用原始输入序列和之前生成的所有元组 (1, . . . , i − 1)。
IMoJIE [6] 的系统架构。输入词的 BERT 嵌入和先前生成的元组被迭代解码以获取下一个元组。为了生成第 i 个元组,解码器采用原始输入序列和之前生成的所有元组 (1, . . . , i − 1)。
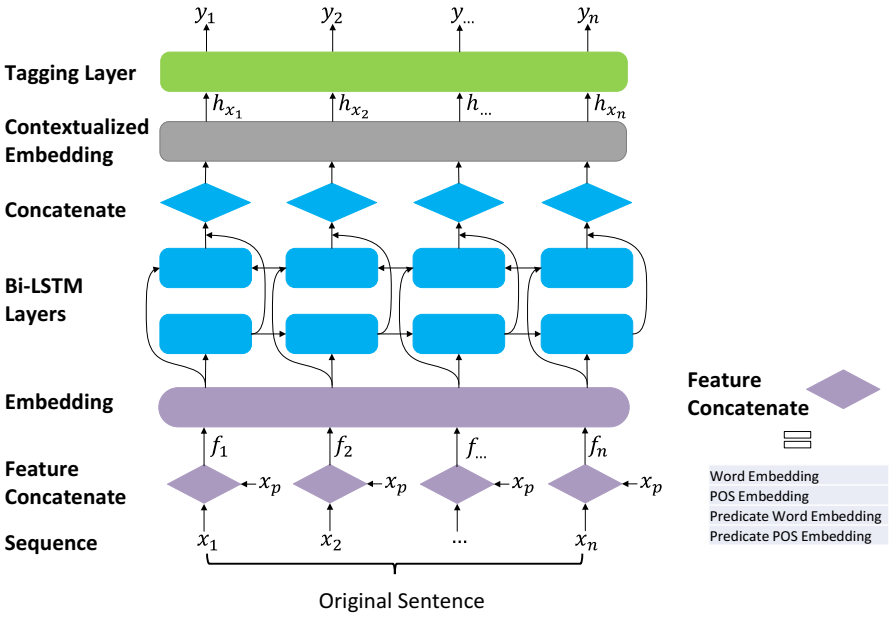 RnnOIE [7] 的系统架构。串联的特征嵌入被输入到 Bi-LSTM 网络中。上下文化的嵌入用于标记层中的每个单词,在每个标记下产生独立的概率分数。
RnnOIE [7] 的系统架构。串联的特征嵌入被输入到 Bi-LSTM 网络中。上下文化的嵌入用于标记层中的每个单词,在每个标记下产生独立的概率分数。
 SenseOIE [8] 的系统架构。输入词的特征向量在 Bi-LSTM 网络中聚合。Bi-LSTM 输出用于每个词的 softmax,在每个标签下产生独立的概率分数。
SenseOIE [8] 的系统架构。输入词的特征向量在 Bi-LSTM 网络中聚合。Bi-LSTM 输出用于每个词的 softmax,在每个标签下产生独立的概率分数。
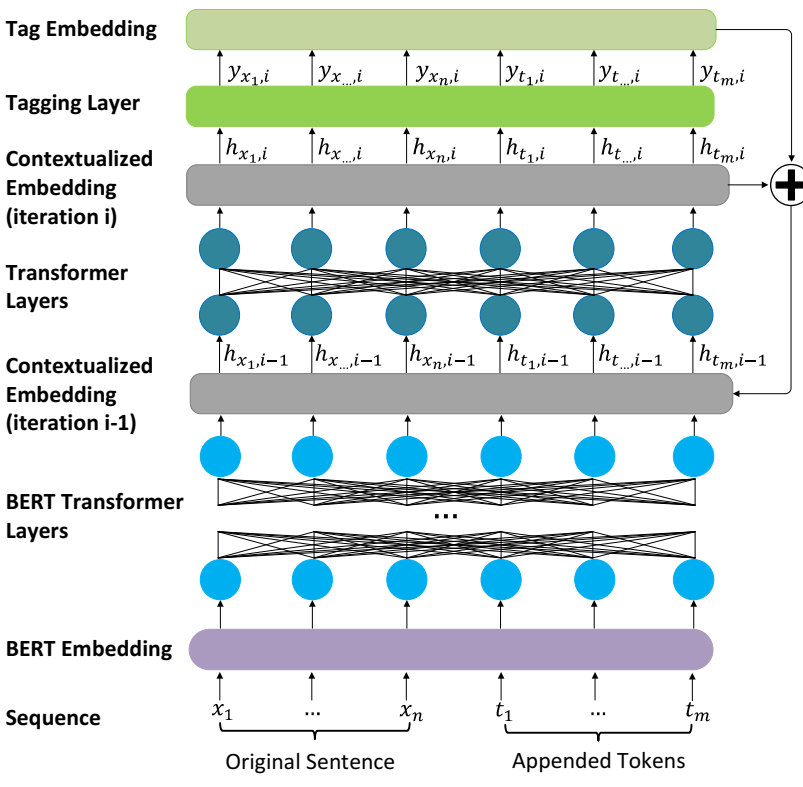 OpenIE6 [9] 的系统架构。输入序列的 BERT 嵌入迭代地通过转换器层。在第 i 次迭代期间,迭代 (i-1) 中生成的标签的嵌入被添加到上下文化嵌入中。更新后的上下文化嵌入被传递到转换器层和标记层以生成第 i 个元组。
OpenIE6 [9] 的系统架构。输入序列的 BERT 嵌入迭代地通过转换器层。在第 i 次迭代期间,迭代 (i-1) 中生成的标签的嵌入被添加到上下文化嵌入中。更新后的上下文化嵌入被传递到转换器层和标记层以生成第 i 个元组。
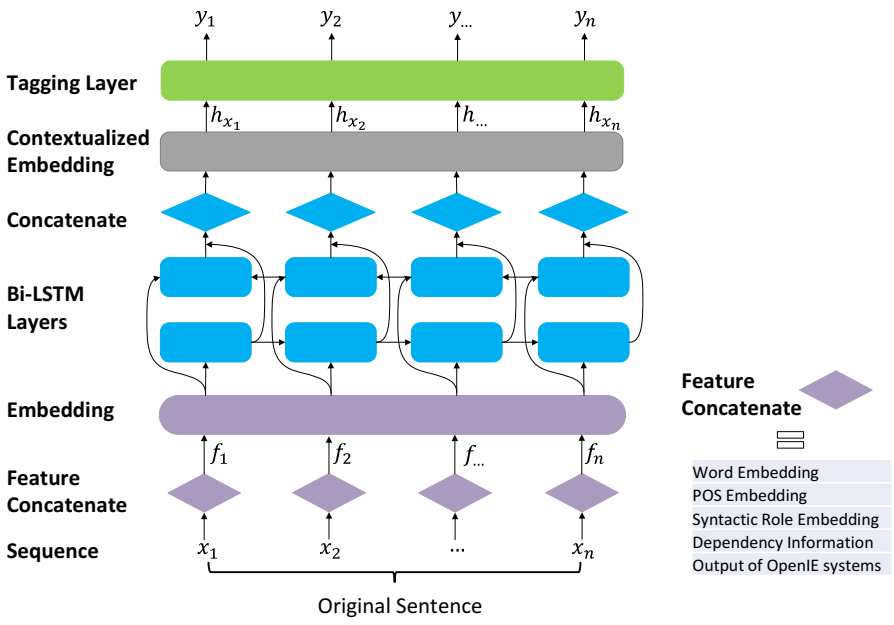
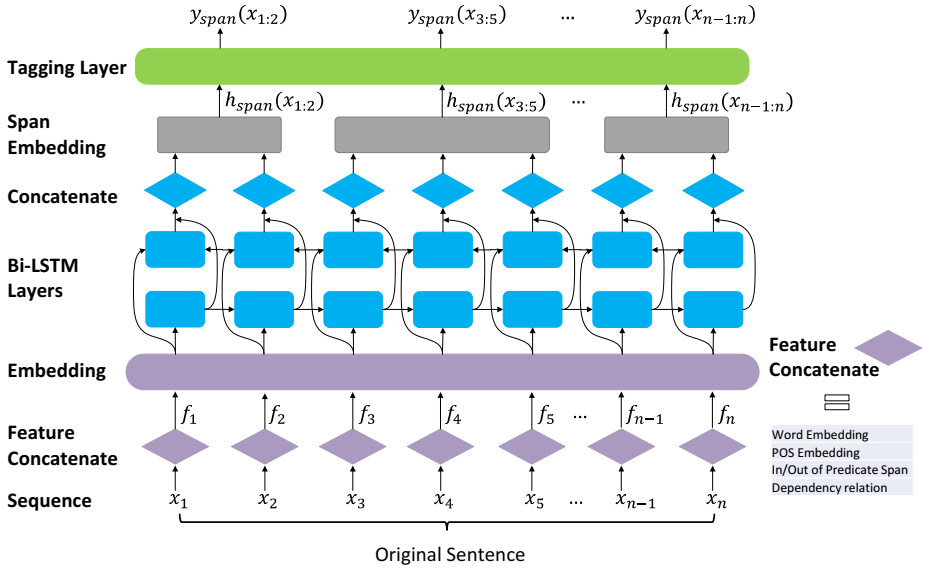 SpanOIE [10] 的系统架构。输入词的特征嵌入通过 Bi-LSTM 网络。然后通过连接来自 BiLSTM 层的跨度词的上下文化嵌入来获得跨度嵌入。最后,标记层计算每个跨度的不同标签的分数。
SpanOIE [10] 的系统架构。输入词的特征嵌入通过 Bi-LSTM 网络。然后通过连接来自 BiLSTM 层的跨度词的上下文化嵌入来获得跨度嵌入。最后,标记层计算每个跨度的不同标签的分数。
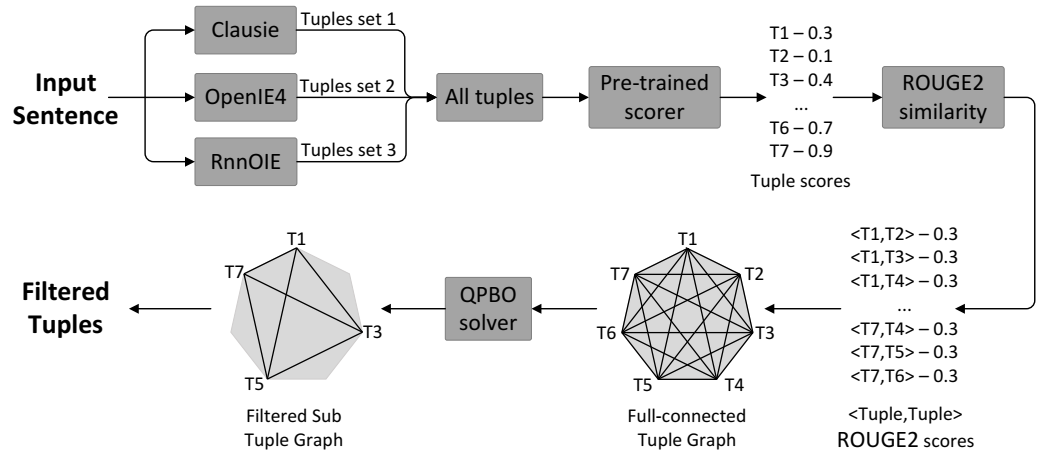 在 IMoJIE [9] 中以无监督的方式对从多个 OpenIE 系统中提取的元组进行排序和过滤。
在 IMoJIE [9] 中以无监督的方式对从多个 OpenIE 系统中提取的元组进行排序和过滤。
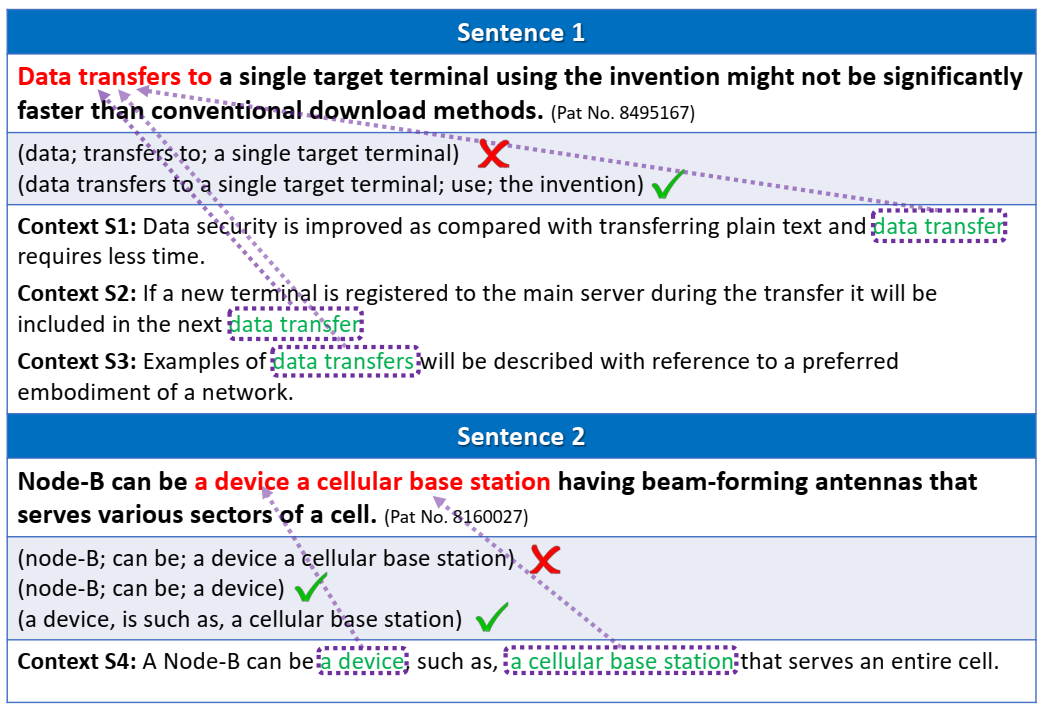 有歧义的例句。
有歧义的例句。
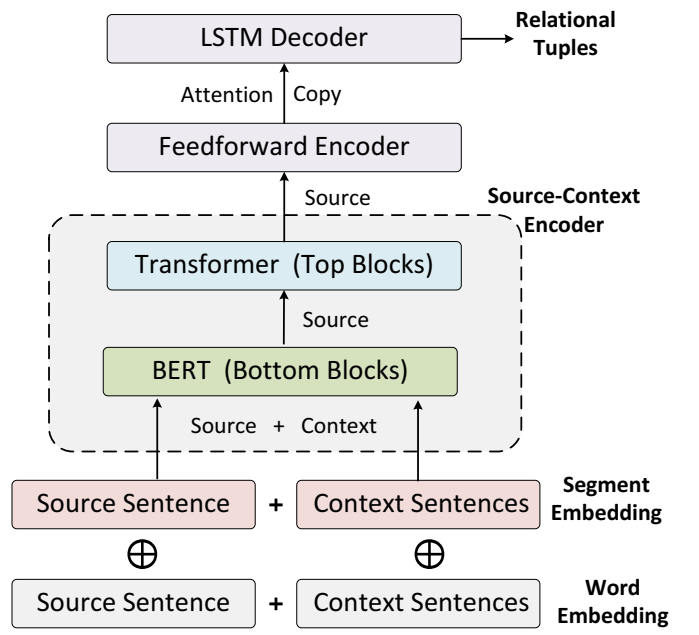 DocIE 的架构。
DocIE 的架构。
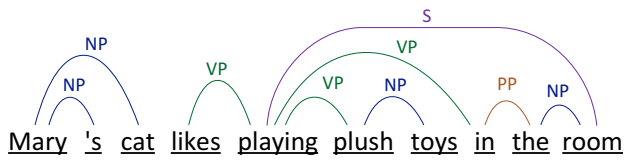
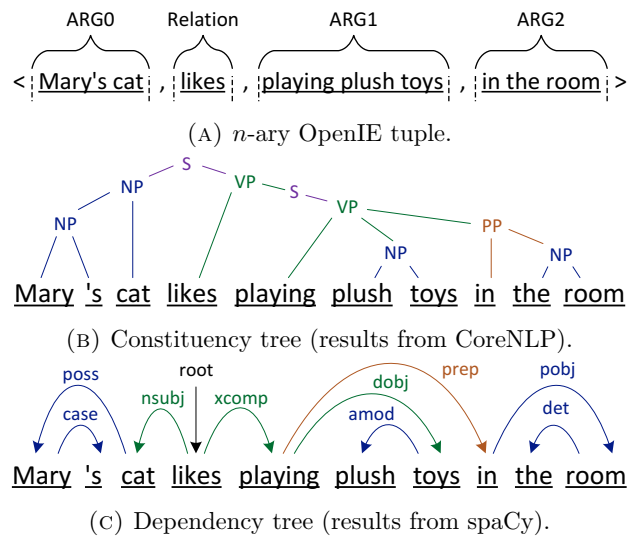 为句子提取的组成树、依存树和 n 元 OpenIE 元组的示例:玛丽的猫喜欢在房间里玩毛绒玩具。
为句子提取的组成树、依存树和 n 元 OpenIE 元组的示例:玛丽的猫喜欢在房间里玩毛绒玩具。
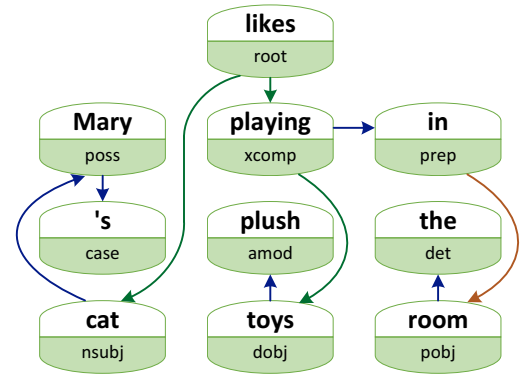
图4.1由词级依存关系构建的依存关系图。
 由组树的短语级关系转换成词级组关系。
由组树的短语级关系转换成词级组关系。
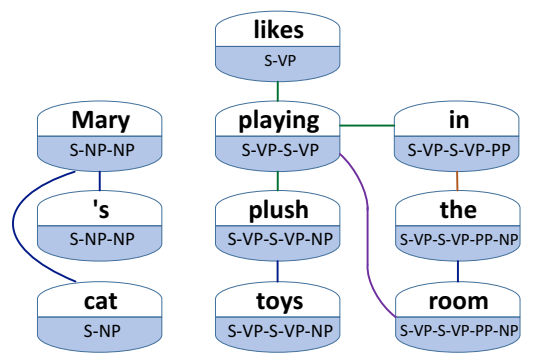
图 4.3 中由词级成分关系构建的成分图,以及表 4.1 中的层级成分路径。
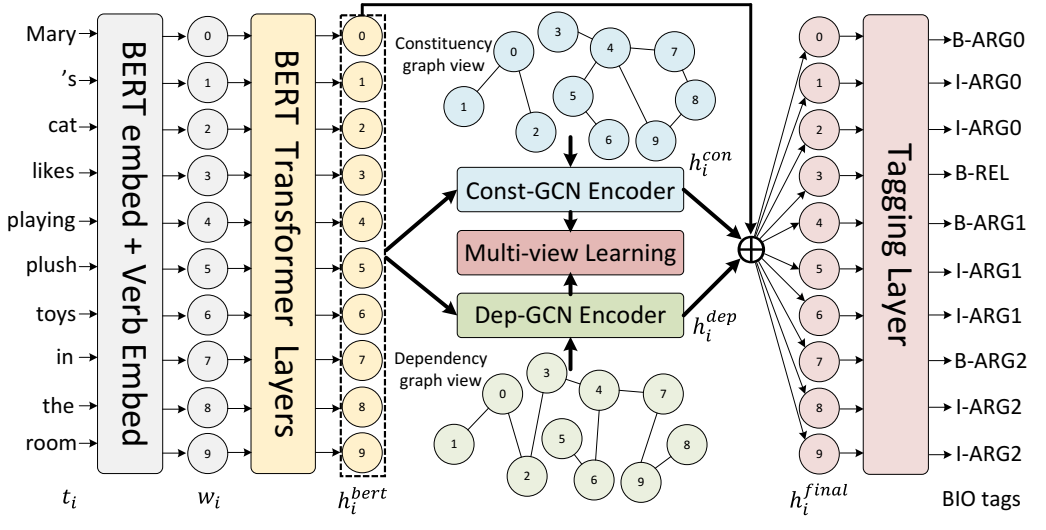 SMiLe-OIE 模型架构概述。
SMiLe-OIE 模型架构概述。
 一个句子中有不同的块序列。
一个句子中有不同的块序列。
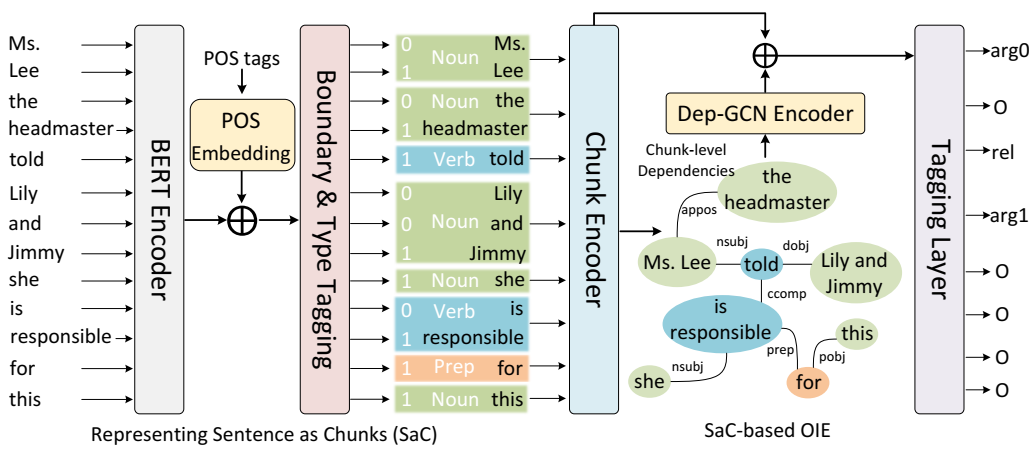 Chunk-OIE 概述。为了简洁起见,句子中的标点符号被忽略。Chunk-OIE 是一个端到端模型,其 (i) 将句子表示为 Chunks (SaC) 和 (ii) 基于 SaC 的 OpenIE 元组提取。
Chunk-OIE 概述。为了简洁起见,句子中的标点符号被忽略。Chunk-OIE 是一个端到端模型,其 (i) 将句子表示为 Chunks (SaC) 和 (ii) 基于 SaC 的 OpenIE 元组提取。
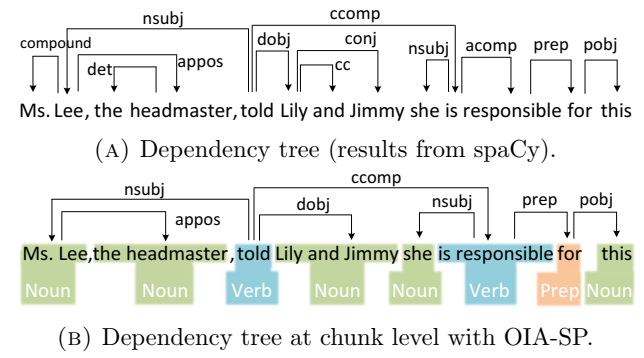 分别在标记级别和块级别(在 OIA 简单短语中)的依赖树。
分别在标记级别和块级别(在 OIA 简单短语中)的依赖树。
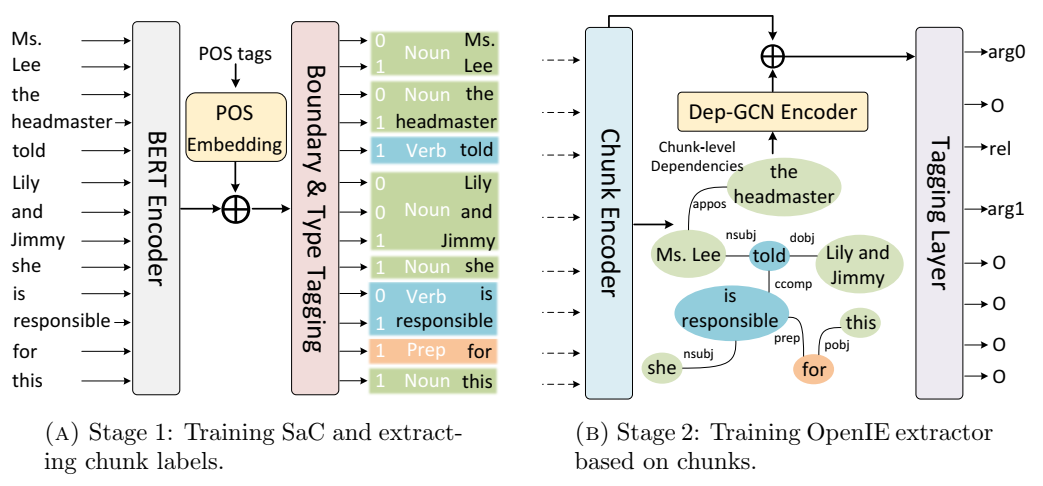 2 阶段 Chunk-OIE 概述。为了简洁起见,句子中的标点符号被忽略。请注意,第 1 阶段(句子分块)和第 2 阶段(OpenIE 提取)是分开训练的。
2 阶段 Chunk-OIE 概述。为了简洁起见,句子中的标点符号被忽略。请注意,第 1 阶段(句子分块)和第 2 阶段(OpenIE 提取)是分开训练的。
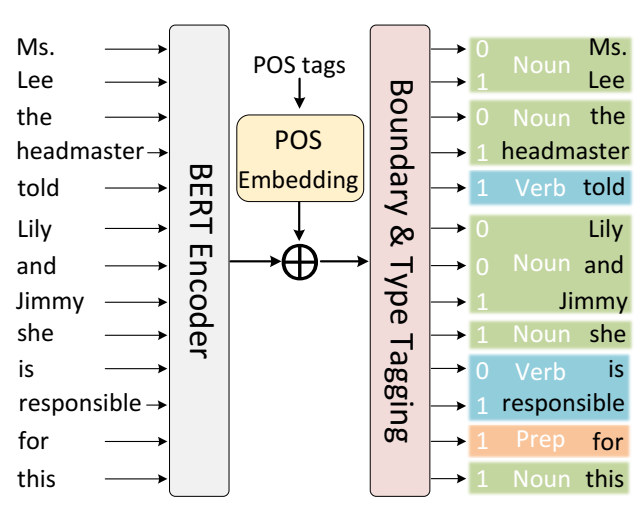 句子分块模型。它用于为 CoNLL 和 OIA-SP 提供分块标签。
句子分块模型。它用于为 CoNLL 和 OIA-SP 提供分块标签。
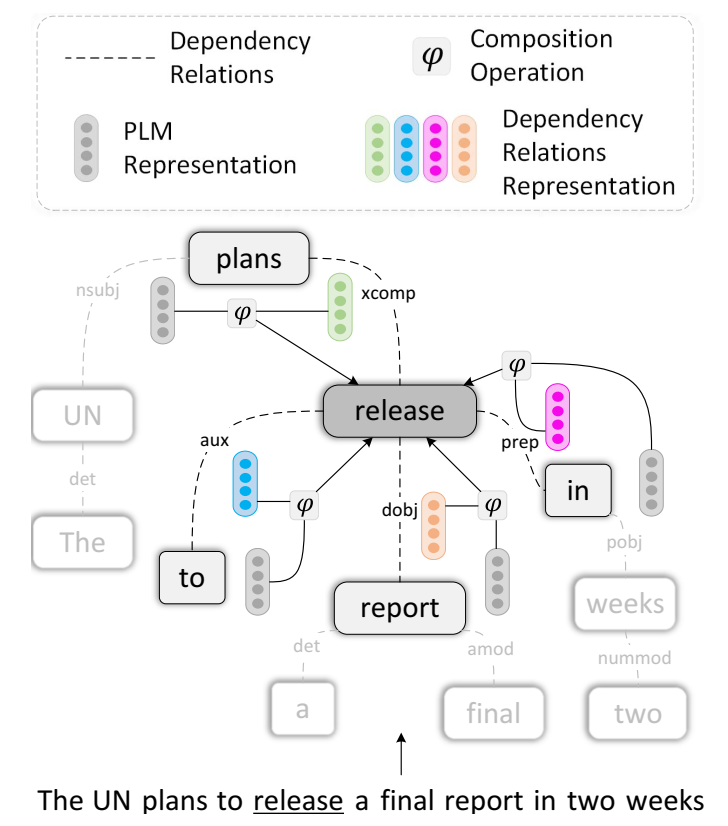 SpecTup 的基于关系的聚合。元组关系“release”根据不同的依赖关系自适应地聚合其邻居。
SpecTup 的基于关系的聚合。元组关系“release”根据不同的依赖关系自适应地聚合其邻居。







内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢