
DRUGAI
今天为大家介绍的是来自英属哥伦比亚大学(UBC)Jorg Gsponer团队的一篇论文。由固有无序蛋白区域(IDRs)介导的相互作用在结构特征描述方面提出了严峻挑战。IDRs非常灵活,能够采用多种结构和结合模式。受到蛋白质结构预测领域最新进展的启发,作者开始探索AlphaFoldMultimer在多大程度上能准确再现涉及IDRs的相互作用复杂性。为此,作者收集了多个数据集,涵盖了IDRs结合模式的广泛范围,并利用这些数据集来测试AlphaFold-Multimer对IDR相互作用及其动态性的预测能力。分析显示,AlphaFold-Multimer不仅能以高成功率预测各种类型的结合IDR结构,还能通过适当使用AlphaFold-Multimer的内在评分来区分真实相互作用与假象,以及不可靠预测与准确预测。研究发现,对于更加异质、模糊的相互作用类型,预测质量会下降,这可能是因为界面疏水性较低和卷曲含量较高。然而值得注意的是,某些AlphaFold-Multimer评分,如Predicted Aligned Error和residue-ipTM,与结合IDR的结构异质性高度相关,使得可以清晰地区分模糊和更均匀结合模式的预测。最后,基准测试表明,在使用全长蛋白时也可以成功预测IDR相互作用,但不如使用对应的IDRs准确。为了便于识别给定伴侣的对应IDR,作者建立了“minD”,该工具可以定位全长蛋白中的潜在相互作用位点。作者的研究表明,AlphaFold-Multimer能够正确识别相互作用的IDRs,并预测它们与给定伙伴的结合方式。

真核细胞中,存在一类序列区域,这些区域的蛋白质无法独立形成独特的三级结构,被称为“天然无序蛋白区域(IDRs)”。这类蛋白在细胞信号传递和代谢控制等重要的细胞过程中发挥着关键作用。IDRs之所以对细胞生理功能重要,主要是因为它们能够与多种生物分子相互作用。它们的结合多样性源于这些区域中包含的各种易于相互作用的元素。其中,短线性基序(Short Linear Motifs,SLiMs)是一些长度为3到11个氨基酸的简短、保守的序列,这些基序能够识别并与特定的结构域结合。此外,另一类在IDRs中发挥相互作用功能的元素被称为分子识别特征(Molecular Recognition Features,MoRFs)。MoRFs的长度相对较短到中等,可达70个氨基酸。它们的显著特点在于缺乏明显保守的序列基序,且在与结合伙伴相互作用时往往会从无序结构转变为有序结构。此外,MoRFs还具有与不同伙伴结合并呈现不同结构的能力。
IDRs与其结合伙伴的相互作用方式多种多样,这反映出这些相互作用的序列元素具有多重特性。尽管SLiMs和MoRFs通常以特定方式与伙伴结合,采用一组均一的构象来与特定的相互作用表面结合,但IDRs在构象和结合方式上表现出更大的灵活性。IDRs与伙伴的结合关系往往带有较高的模糊性,表现为部分和动态的结合。这种模糊性表明结合并不固定在某一种明确的构象上,而是涉及动态变化和多个结合位点。在某些情况下,IDR的结合部分在结合后仍保持完全无序状态。
清晰理解IDRs复杂的相互作用模式,有助于深入了解这些区域在细胞通路功能中的具体作用。近年来,研究者为确定IDRs与结合伙伴形成复合物时的结构投入了大量精力。随着AI领域的快速进展,这一知识的探索可能将迎来重大突破。AlphaFold2和RosettaFold等先进的蛋白质结构预测模型展现出在结构预测上接近实验方法精度的卓越能力。尽管AlphaFold2最初仅以蛋白质单体结构的数据库(PDB)为基础进行训练,但其发布后不久便被证明也具有预测蛋白质复合物结构的能力。技术上,这些预测通过将两条蛋白质序列以多聚甘氨酸连接,或在不同链的残基索引上添加一个大数值来实现。尽管这些方法较为简单,但结果令人瞩目,表明尽管AlphaFold2的初始目标是预测单体蛋白质结构,它仍然学习到了关于蛋白质相互作用的知识。
AlphaFold2在预测蛋白质复合物结构方面的成功很快被AlphaFold-Multimer的推出所取代。这个官方扩展版本重新训练了AlphaFold2,增加了对多链优化和对称处理的原生支持。正如预期,这种方法显著优于此前未进行重新训练的AlphaFold2相关方法。随着AlphaFold-Multimer的发布,许多研究正在评估并尝试提高其预测不同类型蛋白质相互作用的能力。然而,对于AlphaFold-Multimer是否能准确预测包含IDR的复合物结构,了解较少。在此,作者使用多个数据集,探讨了AlphaFold-Multimer在预测包含IDR的蛋白质复合物结构方面的能力,并评估了在MoRF和模糊相互作用领域中的预测挑战的多个方面。
AlphaFold-Multimer预测包含IDR的复合物结构上成功率较高,但质量有所差异
作者首先评估了AlphaFold-Multimer v2.2的预测表现,使用的是PDB SEQRES记录中提供的受体和IDR的序列,即仅采用用于确定结构的序列片段。如果有多个实验结构,作者将AlphaFold-Multimer的预测结果与首次存入的模型进行比较,沿用了以往的方法。为衡量结构预测的成功率,作者基于DockQ定义了相互作用预测评估(CAPRI)分类指标,将预测结果按质量分为不可接受结构以及可接受、中等或高质量的结构。该分类基于一系列质量指标,如正确的天然界面接触比例和不同计算方法的RMSD值。
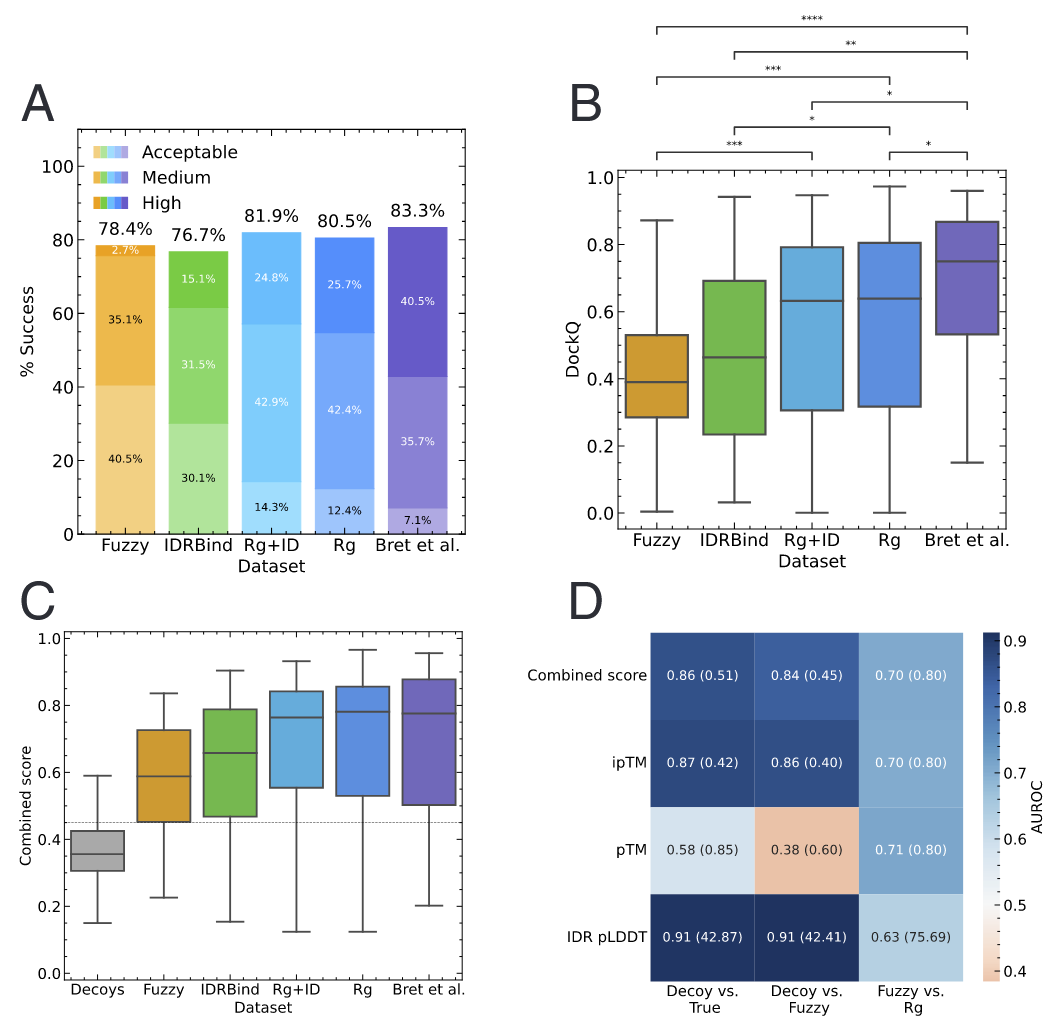
图 1
结果显示,AlphaFold-Multimer为作者收集的每个数据集中的样本生成正确复合物结构的成功率超过76%(图1A)。这一表现与Bret等人构建的蛋白质-肽数据集上的表现相当(图1A)。然而,正确预测的复合物结构在质量上存在显著差异。尽管Rg和Rg+ID集中的预测结构约有25%达到高质量,但在Fuzzy集中这一比例降至约3%。不同数据集的预测质量差异也体现在DockQ评分的分布上(图1B)。Rg和Rg+ID集的复合物的DockQ评分中位数约为0.65,而IDRBind和Fuzzy集的中位数则显著较低(P值分别为2.6 × 10−2和1.8 × 10−4,Mann–Whitney U检验)。总体而言,评估结果显示,AlphaFold-Multimer在预测包含IDR的蛋白质复合物结构上具有较高的成功率,但各数据集间的预测质量差异显著。
Fuzzy数据集中的所有结构和IDRBind数据集中的多数结构都是通过NMR光谱测定的,因此每个复合物都有多个结构模型。AlphaFold-Multimer生成的结构中得分最高的那个可能更接近于除首次提交的NMR模型外的任何一个。此外,AlphaFold-Multimer生成的结构中也可能有一个是所有提交的NMR模型中最准确的预测。因此,作者将所有预测结构与所有NMR模型进行对比,提取了两个新的评估指标:第一个取每个预测结构的最大DockQ值,用以衡量预测的准确度;第二个取每个NMR模型的最大DockQ值,用以评估AlphaFold-Multimer预测覆盖NMR构象的程度。从附录图S2可以看出,这种方法并未显著改变两个数据集的整体成功率,对预测质量也没有明显影响。
AlphaFold-Multimer的内在评分可用于区分虚假或低质量结构与高质量结构
AlphaFold-Multimer的自解释特性是其显著优势之一,因为它能够生成内在评分来指示预测结构的质量和可靠性。预测的局部距离差异测试(pLDDT)、预测对齐误差(PAE)和预测模板建模(pTM)评分是该功能的典型示例,分别用于评估残基层级的局部预测可信度、两个残基间相对位置的置信度以及整个结构的准确性。对于蛋白质复合物预测,特定的指标如界面-pTM(ipTM)和综合评分(计算公式为0.8 · ipTM + 0.2 · pTM)被开发出来,用于评估复合物成员间预测相对位置的准确性。综合评分尤为重要,通常用于对AlphaFold-Multimer的预测结果进行排名,评分最高的结构往往会被选用于进一步分析。
作者测试了综合评分在多大程度上反映预测的质量,并绘制了每个数据集的综合评分分布(图1C)。结果显示,各数据集的综合评分分布差异与DockQ评分所反映的预测质量分布差异一致。确实,综合评分和DockQ评分在每个数据集中均高度相关,但在Fuzzy数据集中的相关性较其他数据集略低。
接着,作者评估了AlphaFold-Multimer的评分是否能够区分真实复合物和虚假复合物。为此,作者比较了真实复合物和虚假复合物的综合评分分布。通过将受体-IDR配对中的无序结合部分替换为同一蛋白质中来源于同一结合体的其他IDR,作者生成了虚假复合物(。大多数真实复合物的综合评分在0.5以上,而虚假复合物的评分则低于0.5(图1C)。
为量化AlphaFold-Multimer对真实和虚假复合物的分类能力,作者计算了所有常见AlphaFold-Multimer内在评分的受试者工作特征曲线下面积(AUROC)(图1D)。同时确定了使真阳性率与假阳性率差异(TPR − FPR)达到最大时的评分阈值。在真实和虚假复合物分类中,综合评分、ipTM和IDR的pLDDT均表现良好,尤其是IDR pLDDT表现突出(AUROC = 0.91,阈值=42.9,图1D第一列)。由于Fuzzy数据集中所有真实复合物的综合评分最低,作者特别评估了AlphaFold-Multimer在该数据集上区分虚假复合物的能力。在此分类任务中,IDR pLDDT同样表现出色(AUROC = 0.91,阈值=42.4,图1D第二列)。
最后,作者测试了不同AlphaFold-Multimer评分在区分不准确和准确的复合物结构预测(CAPRI分类)上的能力。多种评分中,综合评分在此任务中表现最佳(AUROC = 0.81,阈值=0.62)。总体而言,这些测试表明,AlphaFold-Multimer对IDR与受体相互作用的预测中,综合评分高于0.62的结果不仅是真实的,而且是准确的。
AlphaFold-Multimer的结构大多与NOE衍生的距离一致,且捕捉到了多样的结合模式
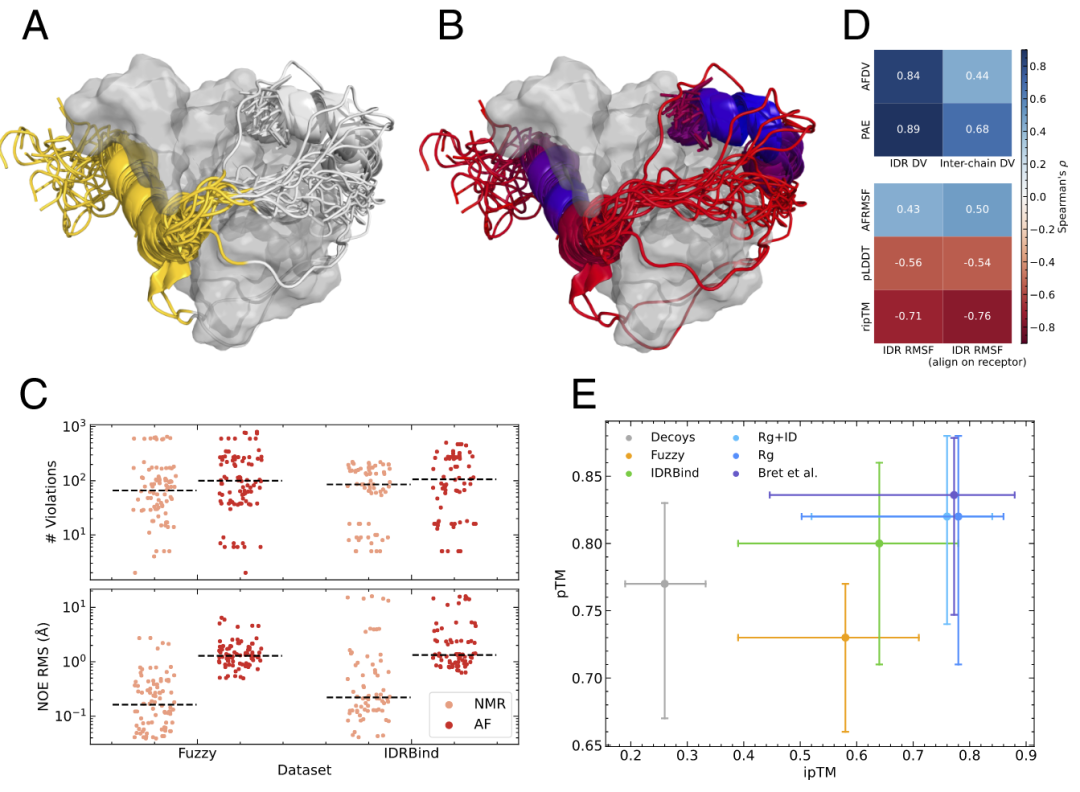
图 2
使用DockQ和CAPRI评估预测质量存在局限性,这可能是导致Fuzzy和IDRBind数据集中的复合物被归为低质量的原因之一。DockQ和CAPRI指标设计上是以特定的三维原子排列为基准,因此无法有效评估动态结合模式(如模糊复合物)的结构质量(图2A和B)。因此,作者采取了进一步步骤来评估AlphaFold-Multimer在这类结构上的表现。考虑到Fuzzy和IDRBind数据集中很大一部分为NMR结构,作者分析了NMR约束的违背情况,特别是NOE衍生的质子间距离。简言之,在AlphaFold-Multimer结构中添加氢原子后,作者使用PdbStat软件分析了约束违背情况。
分析结果显示,存入PDB的结构集群的中位数违背次数略低于AlphaFold-Multimer预测的模型(图2C)。不过,计算NOE RMS违背值显示,AlphaFold-Multimer生成的结构整体上存在更高的距离偏差。AlphaFold-Multimer的中位NOE RMS违背值在两个数据集中均约为1.5 Å,而Fuzzy和IDRBind数据集中NMR模型的RMS违背值分别为0.2 Å和0.3 Å。尽管如此,在这两个数据集中有多个复合物,其存入的NMR模型与不同的AlphaFold-Multimer预测的违背情况相当。
鉴于模糊复合物在结合后包含高度动态区域,作者研究了AlphaFold-Multimer在其结果中如何重现这些特性。为此,作者计算了Fuzzy数据集和AlphaFold-Multimer模型中每个样本的RMSF和距离变异(DV)。前者用于衡量每个残基的波动,而后者则用于监测蛋白质或复合物内的成对波动,即某一区域相对于其他部分的动态程度。作者将预测结构视为同一蛋白质复合物的不同构象,并直接从这些构象中提取RMSF和DV。计算出的AlphaFold-Multimer预测的IDR链的DV与Fuzzy数据集结构的Spearman相关性很高(0.84)(图2D,上图)。然而,链间DV的相关性较低。此外,IDR的RMSF相关性也较低(图2D,下图)。深入分析AlphaFold-Multimer预测和PDB模型计算的RMSF显示,预测中的波动幅度普遍较小,即AlphaFold-Multimer预测的结构更为均一,总体拓扑差异较小,与已存储的模型相比差异明显。值得注意的是,AlphaFold-Multimer的内在评分,如ripTM(每个残基的ipTM评分)和PAE,与RMSF和DV具有较高的相关性(图2D)。换句话说,RMSF或DV较高的IDR区域分配了较低的ripTM和较高的PAE评分。最重要的是,出于功能原因被识别为动态的IDR段,即那些促使这些相互作用被包含在Fuzzy数据集中的片段,其ripTM评分显著低于IDRBind数据集的IDR。这些结果表明,在蛋白质复合物中具有较高结构变异性的IDR被AlphaFold-Multimer赋予较低的置信评分,说明AlphaFold-Multimer对包含IDR的复合物中的更多动态部分具有内在的了解。
这些发现表明,AlphaFold-Multimer评分可能可以区分均一结合和非均一结合。事实上,pTM能够将模糊复合物与Rg集合的均一结合模式区分开来(AUROC=0.71,阈值=0.8,图1D第三列)。此外,将不同数据集的预测结构投影到pTM与ipTM空间中,清晰地显示出模糊复合物的pTM评分低于其他复合物(图2E)。ipTM评分进一步区分了真实复合物和具有更低维度值的虚假结构。因此,在pTM和ipTM空间中的投影提供了一种直观的方式,展示了AlphaFold-Multimer如何将异质性IDR结合模式与均质性结合模式,以及虚假结构与真实相互作用分开。
AlphaFold-Multimer在预测包含IDR复合物结构时的精度决定因素是什么?
鉴于作者观察到不同数据集之间的预测质量差异显著,因此研究了各个数据集中富集的特性,并考察它们与AlphaFold-Multimer预测质量的相关性。与之前的结果一致,作者发现包含IDR的小界面复合物的DockQ得分显著低于大界面复合物(图3A,P值:9.6 × 10⁻⁸,Mann–Whitney U检验)。然而,界面大小似乎不是作者分析的数据集中导致预测质量差异的关键因素,因为Fuzzy、IDRBind和Bret等人数据集的界面大小分布非常相似(图3D)。
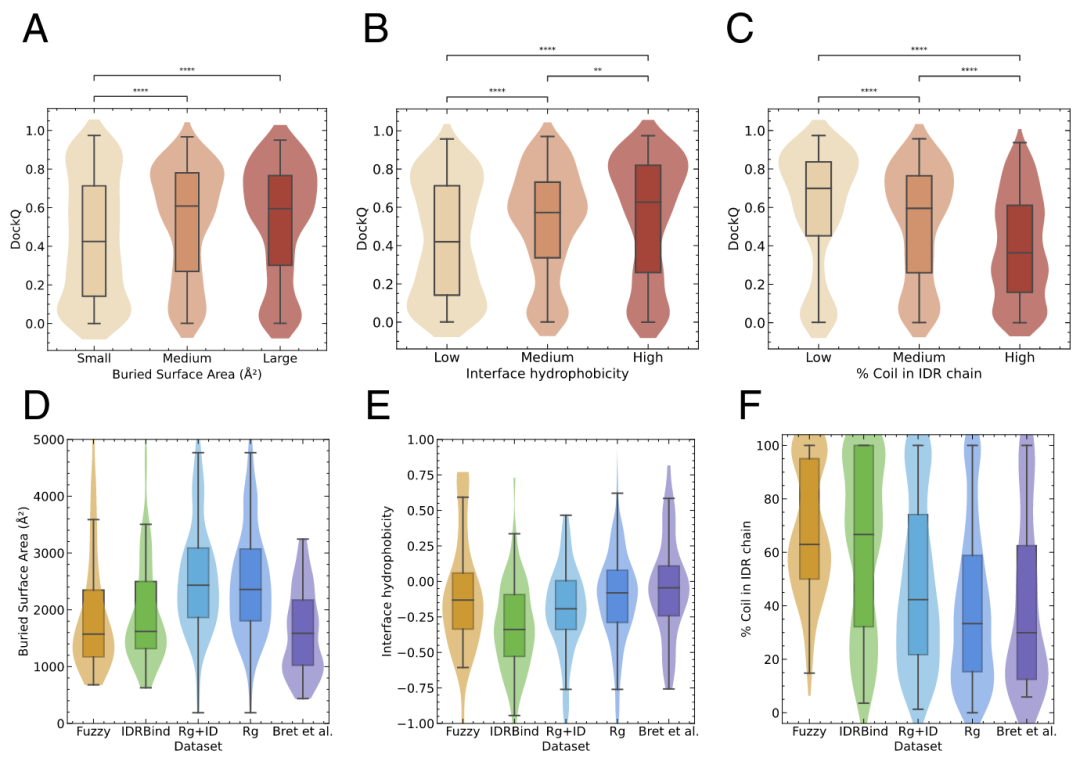
图 3
作者此前已表明,涉及IDR的界面富含疏水性残基,且IDR中大量带电残基对相互作用特异性的确定起到重要作用。因此,作者测试了界面疏水性、IDR和受体中的电荷含量对AlphaFold-Multimer预测质量的影响。最显著的效果出现在界面疏水性上。具有高疏水性和中等疏水性界面的复合物,其DockQ得分显示出预测更准确,而低疏水性界面的复合物预测质量较低(图3B,P值:8.5 × 10⁻¹⁵和3.6 × 10⁻⁸,Mann–Whitney U检验)。与这一结果一致,作者发现极性和带电残基含量高的复合物界面,预测质量普遍较低。类似地,AlphaFold-Multimer从Fuzzy到Bret等人数据集的预测质量逐步提高,除了Fuzzy数据集外,这些数据集的复合物界面中的疏水性也逐渐增加(图3E)。
次级结构含量也与AlphaFold2预测质量差异有关。类似地,作者发现,当结合时的折叠使IDR区域具有较高的α螺旋含量时,包含IDR的复合物预测更准确。与此结果一致且在此背景下尤为显著的是,缺乏次级结构对预测结构的质量有显著影响。作者发现,与受体结合的IDR区域中,如果线圈结构含量较低,其预测质量明显高于结合后具有中等或高线圈含量的IDR(图3C,P值:4.9 × 10⁻⁹和7.3 × 10⁻⁴³,Mann–Whitney U检验)。有趣的是,Fuzzy和IDRBind数据集中的IDR具有所有数据集中最高的线圈结构含量(图3D)。综上所述,这些发现表明,具有高线圈含量和低疏水性的IDR区域(这类特征通常出现在以多模式方式暂时相互作用的片段中)可能更难被AlphaFold-Multimer精确建模。
AlphaFold-Multimer能够识别全长蛋白中的结合IDR
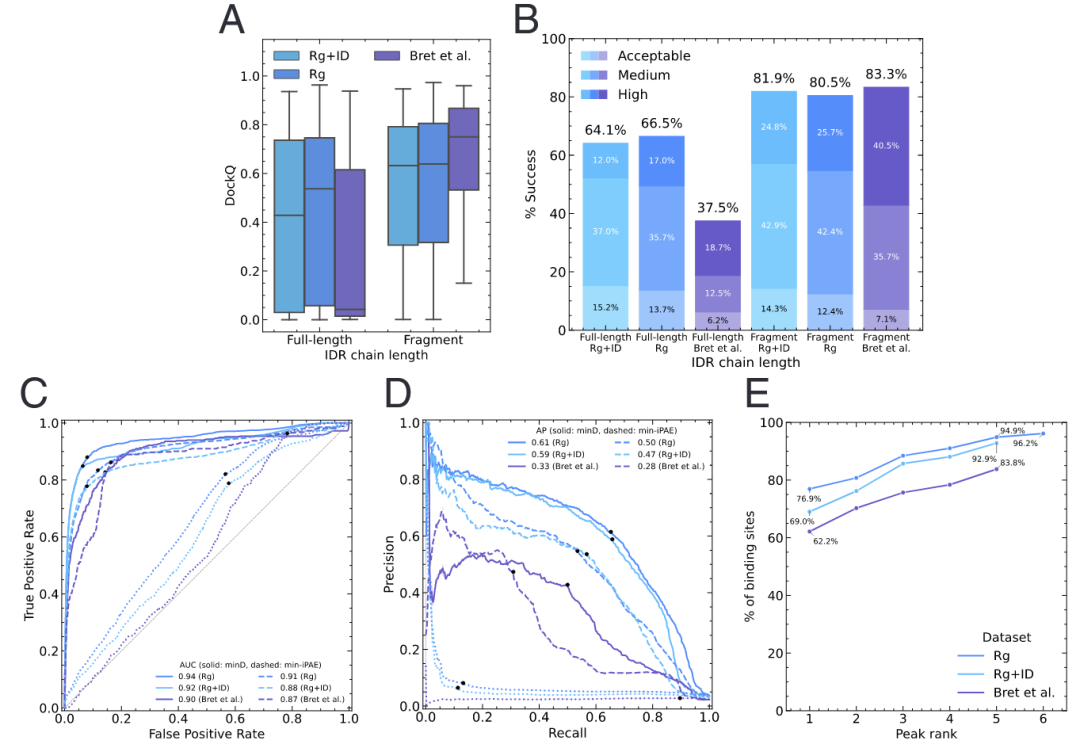
图 4
到目前为止,作者的基准测试仅使用了PDB结构中的IDR序列,而未使用IDR来源的完整蛋白序列。为探究AlphaFold-Multimer是否能够同时识别与特定受体结合的蛋白中的正确IDR并预测复合物结构,作者将Rg和Bret等人数据集中的IDR序列替换为其来源的完整蛋白序列,并将这些序列与相应的受体序列一起用于AlphaFold-Multimer预测。根据DockQ对预测结构进行评估,结果显示相比仅使用IDR序列片段的预测结果,预测质量显著下降(图4A和B)。在Bret等人数据集中,这种预测质量的下降尤为显著。这些结果表明,AlphaFold-Multimer的预测精度对相互作用伙伴的定义边界非常敏感。
值得注意的是,AlphaFold-Multimer在使用全长蛋白时,能够为Rg和Rg+ID集合中的大多数样本生成正确的复合物结构。这一结果表明,AlphaFold-Multimer常常可以在全长蛋白中准确定位与特定受体结合的IDR区域。为评估这种情况的频率,作者测试了不同的AlphaFold-Multimer指标,以判断它们在识别全长蛋白中与特定受体结合的区域(IDR残基)方面的效果。这里测试的重点是,在已知蛋白质相互作用的前提下,是否能够准确定位结合区域。
在测试的不同指标中,min-iPAE和minD在此预测任务中表现最佳。例如,对于Rg数据集,min-iPAE(即包含IDR的全长蛋白每个残基与所有受体残基之间的最小PAE值)在此任务中表现出色,达到0.91的AUROC值(图4C)和0.5的平均精度(AP)(图4D)。在使用Distogram数据时,识别与特定受体结合的IDR残基的效果更佳。Distogram head是AlphaFold-Multimer中的一个模块,可将对称化的成对表示投影到2到22 Å的64个区间内,用于预测残基之间的真实距离,因此在应用于不同蛋白链时可直接预测蛋白界面。作者计算了全长IDR蛋白中每个残基与受体所有残基之间的最小期望距离评分(minD)。结果显示,minD在识别与特定受体结合的IDR方面非常准确(Rg数据集的AUROC分别为0.94和0.92,AP分别为0.61和0.59)(图4C和D)。
尽管精度略低,minD在Bret等人数据集上也表现良好。鉴于这些肽复合物的界面残基较少,以及在该数据集中使用全长蛋白时AlphaFold-Multimer的表现较差(图4A和B),这一能力尤为值得关注。
minD指标的高表现促使作者进一步研究Distogram head的输出。深入分析Distogram head数据后发现,对于给定蛋白质,常能观察到多个峰值,这表明可能存在多个潜在的相互作用位点。作者对归一化的minD进行了系统的峰值分析,以识别潜在的相互作用位点并对其进行排序。对每个预测的所有峰值进行排序后发现,在Rg、Rg+ID和Bret等人数据集中,分别有95%、93%和84%的样本在前5个峰值中包含真实的结合位点(图4E)。有趣的是,在77%的Rg样本中,最高峰值准确识别了正确的结合区域,而AlphaFold-Multimer仅对65.3%的样本生成了正确的结构(图4A)。在SI附录图S10中,作者展示了AlphaFold-Multimer如何在一个全长蛋白(约1,400个氨基酸)中准确找到正确的结合区域,同时生成了一个似乎不正确的复合物结构(DockQ = 0.009)。
研究表明,AlphaFold-Multimer预测可用于识别迄今未知的相互作用伙伴。为此,可以根据结构域边界将潜在的相互作用伙伴序列分割,并对所有可能的配对运行AlphaFold-Multimer。作者的结果表明,min-iPAE和minD有助于识别可能包含相互作用位点的片段,从而减少计算成本。如果这些指标在不与受体结合的蛋白中未识别出错误的相互作用位点,其实用性将进一步提升。为验证这一点,作者创建了一个平衡的负面测试集,随机将全长蛋白与受体配对,并通过包含非结合残基的额外负面数据计算AUROC。结果表明,在识别正确的相互作用位点方面,三个测试数据集的性能仅有小幅下降。此外,作者发现真实的结合物和非结合物在minD峰值数量上相似,但在真实结合物中,排名靠前的峰值得分显著高于非结合物。
编译 | 黄海涛
审稿 | 王梓旭
参考资料
Omidi, A., Møller, M. H., Malhis, N., Bui, J. M., & Gsponer, J. (2024). AlphaFold-Multimer accurately captures interactions and dynamics of intrinsically disordered protein regions. Proceedings of the National Academy of Sciences, 121(44), e2406407121.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢