

01
简介
LLMs具有丰富的知识以及具备强大的上下文推理能力,但其利用训练数据中的知识进行推理(Out-of-Context reasoning)的能力仍受质疑。本论文研究了Out-of-Context reasoning的一个重要方面——Out-of-Context Knowledge Reasoning (OCKR),即通过组合训练集中的多项知识推断新知识。作者针对性设计了包含多个任务的合成数据集来评估LLMs的OCKR能力,结果显示其能力有限。显式训练知识检索对一个任务有帮助,表明模型OCKR能力受限于检索相关知识方面的困难。作者还将跨语言知识迁移视为一种特殊的OCKR形式,结果显示模型在跨语言知识迁移能力上同样表现不佳。该研究揭示了大语言模型在知识推理方面的难点问题,希望能推动相关研究,克服知识检索瓶颈,提升大语言模型的知识推理能力。
02
Out-of-Context reasoning(OCKR)问题定义
在IN-context reasoning情景中,我们会给一些信息(知识)在prompt中,让模型推理出新的知识。目前的模型已经能在IN-context中解决很多推理问题。而Out-of-Context reasoning则是指,目前在训练数据中,模型已经学习了很多的知识,模型能不能直接通过组合训练数据集中的知识去推理出一些新的训练集中没有的知识。以下是一个对比示意图。
 图1:Out-of-Context情景介绍。左边是IN-context,其在context中包含推理所需的知识,直接推理获得答案。右边是Out-of-Context,其需要结合训练数据集中的知识进行推理,进而获得答案。两种场景的训练数据和prompt中都没有直接的答案
图1:Out-of-Context情景介绍。左边是IN-context,其在context中包含推理所需的知识,直接推理获得答案。右边是Out-of-Context,其需要结合训练数据集中的知识进行推理,进而获得答案。两种场景的训练数据和prompt中都没有直接的答案
OCKR问题的正式定义如下公式所示。T1-n是训练集中的知识,其可以推理出右边的T-,并且T-没有在训练集中出现。
 进一步的,我们希望讨论一个较为简单的二元OCKR的场景(n=2)。这是运行知识在不同实体之间传递的最简单场景。
进一步的,我们希望讨论一个较为简单的二元OCKR的场景(n=2)。这是运行知识在不同实体之间传递的最简单场景。
03
构造 Inference Dataset for OCKR(ID-OCKR)
在二元OCKR的场景中,每个知识可能是属性类知识(e.g. x的出生年,缩写为A),也可能是关系知识(e.g. x和y的出生年相等,缩写为R)。基于这两种类型的知识,可以进行排列组合,理论上会产生八种可能的组合。经过去重和排除不可能的情况后,最终剩下三种有效的组合---A∩A->R,A∩R->A,R∩R->R。具体过程如表1所示。
表1:二元OCKR可行的推理组合方式
由于在模型训练数据集中很难判断特定知识是否已经出现,因此我们构造了一个全虚拟的数据集,以确保这些知识未出现在模型的训练数据中。我们先使用GPT-4生成虚拟实体和模板,然后通过代码生成相应的数据集。根据上述三种可能的组合,我们分别构造了simple和hard版本的数据集。具体的三元组构成见表2。
表2: ID-OCKR中的三元组构成
04
实验设置
我们默认使用LLaMA2-13B-Chat模型,并在数据集上采用LoRA方法进行训练。为了确保模型能够正确回答已训练知识,我们为每个知识点设计了十个不同的模板,并充分训练模型,使其在已见过的知识上达到90%以上的准确率。由于问题的答案通常位于一个有限的范围内(例如,"yes" 或 "no"),因此我们将模型的输出结果与随机选择的答案进行比较,以评估其性能。
05
实验结果
实验结果展示在表3中。Separate是正常的设定,可以看到,Separate与random的表现差异不显著,这表明模型在基础OCKR任务上的能力较弱。而Adjacent是一种特殊设定,假设相近的知识在训练样本中相对接近。例如,如果两个人的出生年出现在同一个训练样本中,模型可能更容易推理出两人出生年相等。然而,实验结果显示,将相近知识放在一起训练并未超越random,表明该设定并没有显著提升模型的推理能力。
在In-context设定下,这些任务的准确率较高,并且从人的角度来看,这些任务本身是相对简单的。这些结果进一步表明,模型的基础OCKR能力较弱。
表3:Basic OCKR实验结果
此外,我们还测试了LLaMA2-7B-Chat、LLaMA3-8B-Instruct的全量训练和LoRA训练,以及Baichuan2-13B-Chat和Pythia-12B模型。实验结论与LLaMA2-13B-Chat的一致
06
辅助OCKR实验设置
先前实验发现,模型在基础OCKR任务中的能力较弱。因此,我们尝试了一些方法来增强模型的OCKR能力。具体而言,模型在完成OCKR任务时,可能需要先检索相关知识,再进行推理。那么我们可以分别从推理,检索等方向进行增强。
对于推理:我们通过增加完整的推理数据集,旨在提高模型的推理能力。该数据集包括了一些实体的出生年信息,以及这些实体之间出生年相等和不相等的关系(对于A∩A→R的样例,不同数据集有所不同)。希望模型能够通过学习这些数据中的推理规律,并将其应用到其他数据中。
对于检索:我们使用了特定的Cot的模板去训练模型,让模型先检索出推理所需的知识,再进行回答。样例如表4所示。
表4:Cot样例
07
辅助推理实验结果
实验结果展示在表5,其表明即使在训练中增加了完整的推理数据集,模型性能的提升仍然非常有限。这表明仅通过补充完整推理样例并不足以显著增强模型的OCKR能力,推理能力的提升对解决此类任务的瓶颈作用有限。
表5:辅助推理实验结果
08
辅助检索实验结果
表6中的实验结果表明,使用链式推理(CoT)模板训练模型可以显著提升其检索属性类知识的能力,属性知识相关任务的准确率达到了较高水平。然而,当任务涉及检索关系类知识时,模型的检索准确率明显较低,最终性能也未见显著提升。
我们认为检索准确率低的原因这可能和“逆转诅咒” (A is B cannot infer B is A)类似,即模型能够利用两个实体推导出其关系,但却难以通过实体与关系反向检索出另一实体。这种单向学习限制成为模型处理关系知识推理的瓶颈。
综合上述的实验结果,模型在In-context中表现很好,基础OCKR的能力很弱,提升推理的作用有限,而提升检索能力也可以在一种类型任务中显著的增强性能,说明模型OCKR的瓶颈在检索知识。
表6:辅助检索实验结果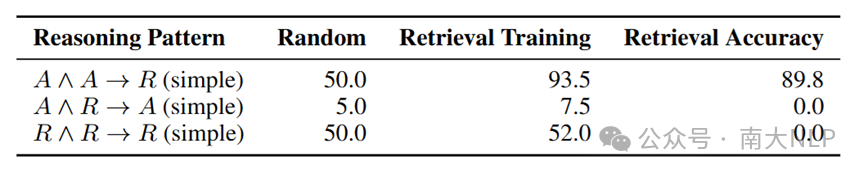
09
跨语言OCKR实验结果
我们将跨语言知识迁移视为一种特殊的OCKR任务(如“Xiaoming born in?”与“小明出生于2000年”间的推理)。结果表明,无论是Separate还是Adjacent训练模式,模型准确率均远低于预期(约10%),且在语言间存在显著性能差异。
表7:跨语言OCKR实验结果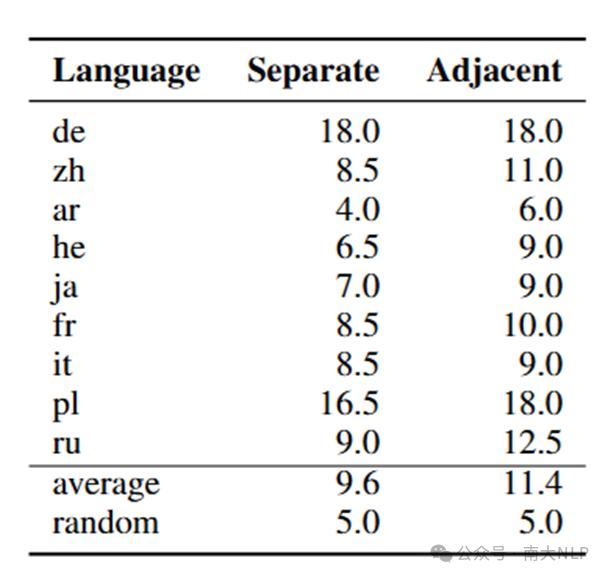
10
结论
综上所述,当前大语言模型在脱离上下文知识推理(OCKR)方面表现出明显的局限性,主要体现在以下两个方面:
第一,模型难以检索出关系知识,这与“逆转诅咒” (A is B cannot infer B is A)类似,解决方式可参考:Reverse Training(Berglund et al., 2023b), Semantic-aware Permutation Training (Guo et al., 2024), or Bidirectional Causal Language Modeling Optimization。
第二,模型难以检索非直接相关的知识,这可能与其在预测下一token时的计算路径限制有关。模型在这个过程中获得每个token结果的计算路径是有限的,而检索非直接相关知识所需的路径远多于检索直接相关知识。所以目前的预训练方式可能难以学会检索非直接相关知识的能力。
解决方式: 1.对每个任务进行特定的Cot训练,进而可以先检索知识,再回答 2.在需要检索非直接相关知识时插入特定数量的pause token,使得模型在需要检索非直接相关知识的时候,可以有足够的计算路径。
论文:https://aclanthology.org/2024.findings-emnlp.178.pdf
代码:https://github.com/NJUNLP/ID-OCKR
参考文献
[1] Krasheninnikov D, Krasheninnikov E, Krueger D. Out-of-context Meta-learning in Large Language Models[C]//ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models. 2023.
[2] Allen-Zhu Z, Li Y. Physics of language models: Part 3.2, knowledge manipulation[J]. arXiv preprint arXiv:2309.14402, 2023.
[3] Berglund L, Stickland A C, Balesni M, et al. Taken out of context: On measuring situational awareness in LLMs[J]. arXiv preprint arXiv:2309.00667, 2023.
[4] Gao C, Hu H, Hu P, et al. Multilingual pretraining and instruction tuning improve cross-lingual knowledge alignment, but only shallowly[J]. arXiv preprint arXiv:2404.04659, 2024.
[5] Berglund L, Tong M, Kaufmann M, et al. The reversal curse: Llms trained on" a is b" fail to learn" b is a"[J]. arXiv preprint arXiv:2309.12288, 2023.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢