

01
简介
虽然大语言模型已经展现出作为基础模型的巨大潜力,但它们仍容易出现逻辑错误或产生幻觉,在复杂推理等场景中更是如此。为了提高大语言模型的生成质量,先前的工作[1, 2]提出了一种有效的解码算法,称为对比解码。在每个解码步中,对比解码使用一个业余模型(通常较小)生成的输出分布来与专家模型(通常较大)的输出分布进行对比。由于专家模型和业余模型通常具有相似的错误模式,这使得部分的错误可以在对比的过程中被抵消,减少了专家模型做出与业余模型类似错误的概率,从而使生成的内容更加合理连贯。
 图1:我们提出的跳层方法在非英语任务上优于直接解码和DoLa对比解码方法
图1:我们提出的跳层方法在非英语任务上优于直接解码和DoLa对比解码方法
但在实践中,很难找到一个合适的、规模更小且与专家模型共享词表的业余模型。为了进一步消除寻找额外业余模型的需求,先前的工作[3]提出了DoLa方法。该方法使用模型的较低层的Early Exit输出作为业余输出分布,将最终的输出分布作为专家模型输出分布,进行无需额外业余模型的对比解码。
尽管DoLa在提高英语生成方面很有效,但我们发现这种方法在非英语任务上表现不佳。我们发现这个问题源于Early Exit输出分布和最终输出分布之间的语言不匹配现象。我们观察到,Mistral 7B模型在早期层的Early Exit输出中并不会生成目标语言(如中文)的token,而是直到最后几层才会输出中文的token。这种语言不匹配使得对比解码失去了意义,进而导致DoLa在非英语任务上的表现不佳。
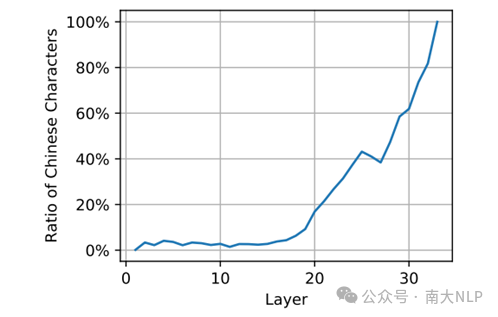
图2:Mistral 7B模型使用CoT回答中文MGSM问题时每一层输出中文token的比例
目前,一种对这种语言不匹配现象的理论解释将其归因于大语言模型的三阶段工作模式。在先前的工作[4]中,发现了大语言模型的前向计算可以大致分为三个阶段:理解上下文(上下文理解阶段)、生成下一个token的抽象概念(概念生成阶段),以及将抽象概念转换为目标语言token(token生成阶段)。其中,在以英文为中心的大语言模型中,抽象概念的表示更加接近英文token的表示空间,因而模型较低层的Early Exit输出总会是英文的。此外,在这个过程中,每个阶段模型输出分布的熵都有不同的变化趋势,可以用作区分不同阶段的一个指标。
表1:我们在MGSM数据集上进行的预实验的实验结果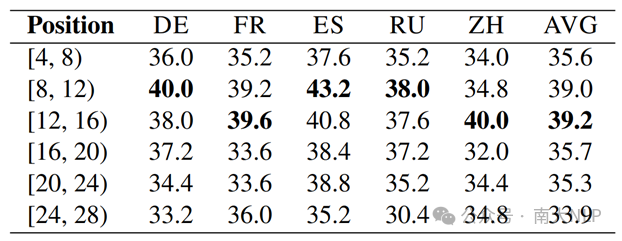
根据这一分析,Early Exit的输出跳过了进行语言转换的token生成阶段,导致业余输出分布和专家输出分布之间的语言不匹配。因此,一个合理的解决方案是仅跳过部分中间层,而保持靠近顶层的模型层的计算不变。为了验证这一想法,我们进行了一项初步研究(表1),通过在不同位置的跳层来观察对比解码的性能。结果表明,跳过模型下半部分(上下文理解阶段)的层产生了更有效的业余输出分布,而跳过顶层则显著地降低了性能。
02
方法
2.1 总体流程
基于我们之前的讨论,提出了一种基于跳过语言无关层的对比解码算法。我们的直觉是,当模型的计算在上下文理解阶段被扰动时(例如跳过某些层),由于特征提取不完善,它倾向于生成流畅但不合理的内容。这种扰动使得输出分布能够作为对比解码的合理的业余输出分布。
为了获得业余输出分布,我们的方法在前向计算时跳过模型的[m, n)层区间。执行跳层后,具有N层的Transformer模型的隐藏层状态计算过程可以写为以下形式:
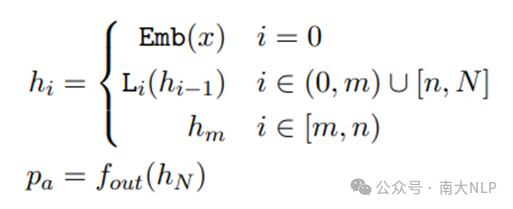
其中x表示输入token,L_i表示模型的第i层,h_i表示模型第i层输出的隐藏层状态。索引m和n标记了跳层区间的开始和结束。在最后一层,可以通过输出函数f_out将隐藏层状态h_N映射到输出嵌入空间来获得业余预测概率p_a。
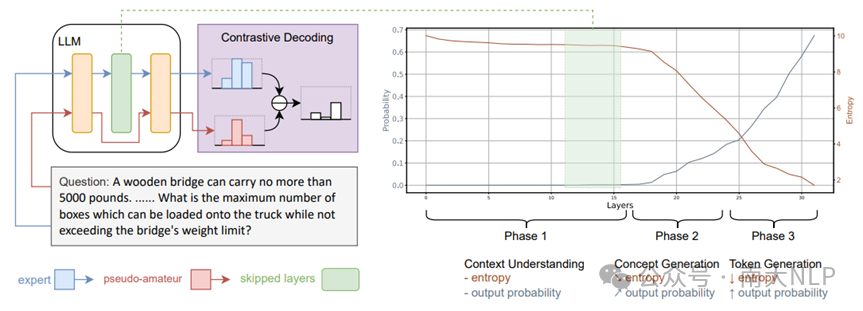 图3:对于“跳层”对比解码方法的示意图
图3:对于“跳层”对比解码方法的示意图
2.2 跳层策略
正确设置跳过区间[m, n)并非易事,我们提出了两种策略来选择跳过区间:
启发式跳层策略(SL-H, Heuristic Layer Skipping):考虑到在大语言模型三阶段工作模式中的上下文理解阶段基本包含了模型的下半部分的层,因此一个基本策略就是模型的下半部分随机跳过几层。实验中我们发现,如果跳过了模型最低的几层(如1~4层),模型的性能会受到很大影响,以至于无法流畅输出以及提供有意义的业余分布用于对比解码,因此我们排除了模型最低的4层,在剩余的上下文理解阶段随机选取若干层进行跳过。
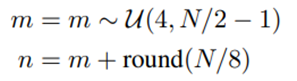
动态跳层策略(SL-D, Dynamic Layer Skipping):相比于随机选取跳层区间,精准地跳过上下文理解阶段末尾的几层是一个更好的选择,我们基于此提出了动态跳层策略。这种方法的通过计算模型输出分布的熵,找到其在上下文理解阶段和概念生成阶段之间的急剧下降,来确定两个阶段之间的边界,并在上下文理解阶段进行跳层。具体来说,我们会计算每一层输出分布的熵,并找到熵下降超过预定义阈值δ的位置,然后将跳过区间的结束位置n设置为该位置。具体计算如下:
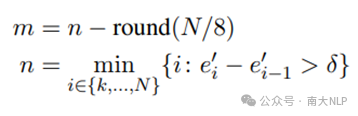
其中,e_i'表示第i-1层和第i层Early Exit输出分布的熵的平均值。k是使m > 6成立的最小整数,用于排除会对性能产生较大影响的早期层。
03
实验
在我们的实验中,我们对Mistral-7B、Baichuan2-7B、Deepseek-7B、LLaMA3-8B和LLaMA2-13B这4个模型进行了实验。并与三个基线方法进行了比较:
1、不使用对比解码。
2、DoLa对比解码方法:最新的无需业余模型的对比解码方法,使用Early Exit而不继续在模型上层的计算。
3、原始的对比解码方法:需要专家模型和额外的业余模型的原始对比解码方法。我们仅为Baichuan2-7B和LLaMA2-13B找到了合适的业余模型。
实验结果表明,跳层方法为对比解码提供了合理的业余输出分布:在表2和表3中,可以看到我们的方法(SL-H和SL-D)在平均值上大幅优于直接推理。在两种跳层策略中,动态跳层策略在大多数测试结果中的表现优于启发式策略。这些结果表明我们的跳层方法为对比解码提供了合理的业余输出分布。
表2:在MGSM上不同解码方式的性能。其中HRL和LRL分别表示在7个高资源语言和4个低资源语言上的平均性能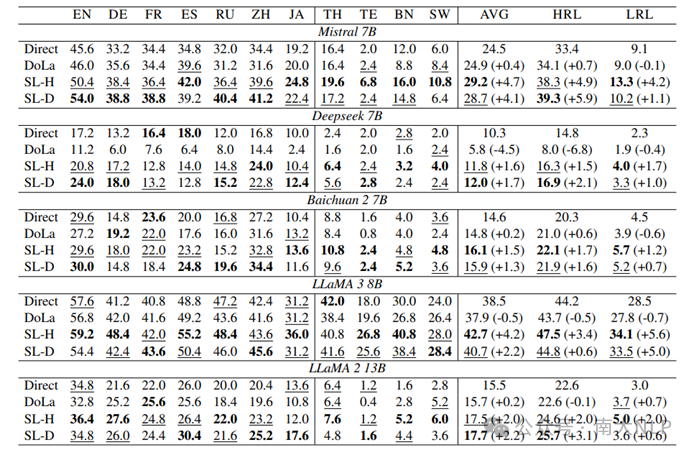
此外,我们设计的方法在多语言场景中表现更优:如表2所示,相比于基线对比解码算法,我们提出的方法在所有测试的大语言模型上都提高了推理准确率。值得注意的是,DoLa在多语言任务上表现不佳。这些结果证明了在对比解码过程中保持靠近顶层的计算的重要性。
表3:在英语数据集上不同解码方式的性能对比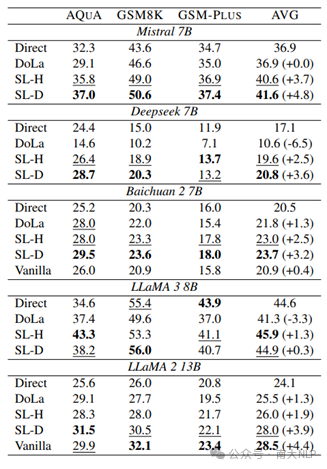
最后,我们提出的方法消除了寻找额外业余模型的需求:与原始对比解码方法相比,我们提出的方法不需要额外的业余模型,同时实现了相当的性能(表3)。这使得它在实际场景中更加适用。
04
结论
本文的动机来自于DoLa对比解码方法在多语言生成任务上失效的问题。我们通过实证分析,并从先前关于大语言模型三阶段工作模式的可解释性研究中获得启发,发现了DoLa的失效源于早期输出和最终输出之间的语言不匹配。为了解决这个问题,我们提出了一种改进的对比解码算法,通过跳过模型底部的一组层来进行扰动,并保留对语言转换至关重要的上层的计算,进而使得业余输出分布的语言与专家模型输出分布相匹配。我们在多语言和单语基准测试上进行了实验,实验结果证明了我们方法的有效性。
参考文献
[1] Li X L, Holtzman A, Fried D, et al. Contrastive decoding: Open-ended text generation as optimization[J]. arXiv preprint arXiv:2210.15097, 2022.
[2] O'Brien S, Lewis M. Contrastive decoding improves reasoning in large language models[J]. arXiv preprint arXiv:2309.09117, 2023.
[3] Chuang Y S, Xie Y, Luo H, et al. Dola: Decoding by contrasting layers improves factuality in large language models[J]. arXiv preprint arXiv:2309.03883, 2023.
[4] Wendler C, Veselovsky V, Monea G, et al. Do llamas work in english? on the latent language of multilingual transformers[J]. arXiv preprint arXiv:2402.10588, 2024.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢