
Datawhale干货
作者:小羊向前冲
AI+安全的实践系列分享来了!


赛道二出题人代表点评
“小羊向前冲”的方案展现了清晰的工作逻辑与良好的团队执行力。团队结合逐步优化与全局平衡的策略,深入分析了数据集特性,针对不同凭证类型和篡改手法,灵活应用开源库AIGC生成、Aibu数据增强和离线伪标签等多维数据增强技术,并创新构建了全自动、即插即用的篡改pipeline,有效提升了模型在多样化篡改场景下的鲁棒性。在应对文字篡改区域小、痕迹弱的难题时,团队采用预标注与多任务学习策略,显著增强了文字篡改检测能力。整套方案设计逻辑清晰,为学术研究与工业领域篡改检测技术的融合与落地提供了较强的参考价值。
复盘分享
写在前面
擅长方向:目标检测,医学图像
赛题背景
金融领域交互式自证业务中涵盖用户开户、商家入驻、职业认证、商户解限等多种应用场景,通常都需要用户提交一定的材料(即凭证)用于证明身份信息、所有权信息、交易信息、资质信息等,而凭证的真实性一直是困扰金融场景自动化审核的一大难题。随着数字媒体编辑技术的发展,越来越多的AI手段和工具能够轻易对凭证材料进行篡改,大量的黑产团伙也逐渐掌握PS、AIGC等工具制作逼真的凭证样本,并对金融审核带来巨大挑战。为此,本赛题开设了AI核身-金融凭证篡改检测赛道。赛题发布了大规模的凭证篡改数据集,参赛队伍需要在给定的大规模篡改数据集上进行模型研发,同时给出对应的测试集用于评估算法模型的有效性。
赛题分析
数据集分析
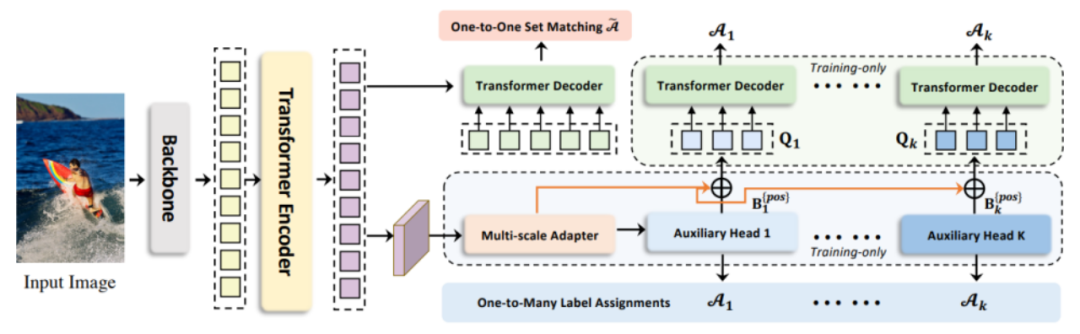
本次比赛发布了超大规模自研光鉴凭证数据集,该数据集整合了大量开源的图像数据和内部的业务数据。数据的构建方式为在原始图像数据上针对文字区域采用copy move,splicing,removal,局部AIGC等方式进行数字篡改编辑。模型的泛化性也将是此次比赛重要的衡量指标,因此本次的测试集将比训练集包含更多的凭证类型和篡改编辑手法。一些窜改实例图如下:
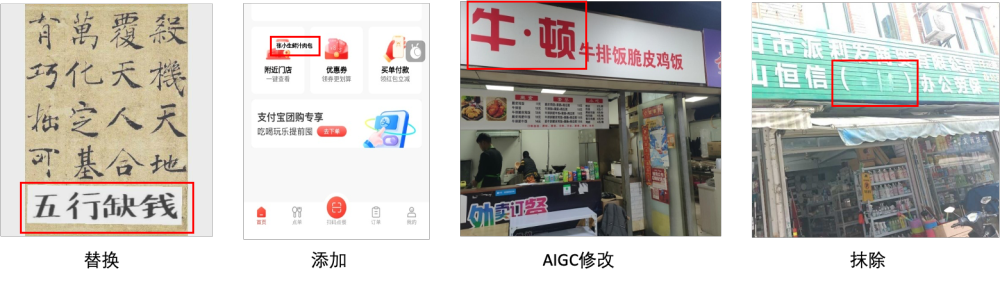

具体方案
将其定义为传统的水平目标检测任务,模型采用Co-DINO-Swin-L,使用Object365预训练模型在640x640的尺度进行训练,轮次大约为3轮。
篡改预准备
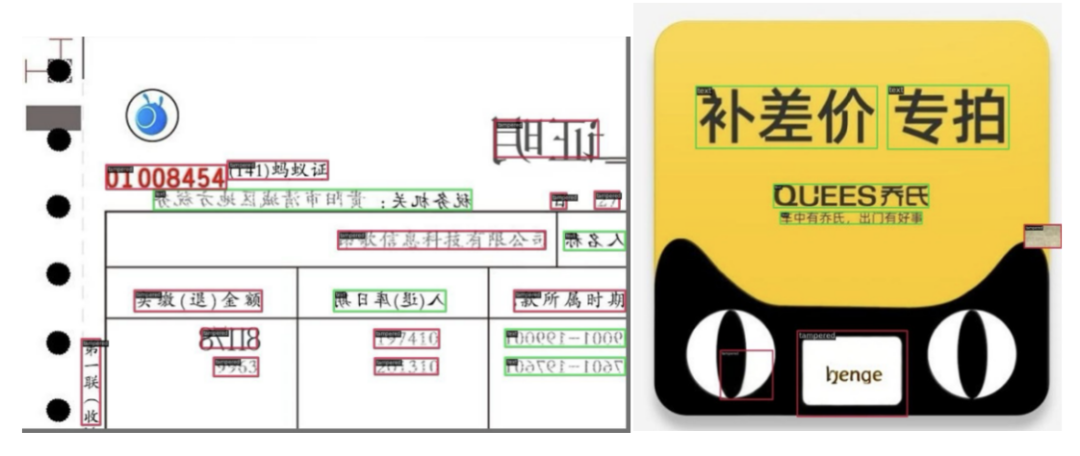
我们用PaddleOCRv4多卡推理得到每张图片都文字行标注,融合原来的篡改类别与正常文字行类别作为新的训练标注文件(在数据输入到模型之前,算法会自动丢弃Text类别,防止造成不利影响)。这样一来我们后续可以同时利用两种标注进行自定义的窜改,极大地丰富了窜改形式。
下图为标注和可视化,红色的框代表原有的篡改类别,绿色的框代表Text框类别。
篡改构造(模仿攻击方)
我们自定义了四个数据增强方法,并构建了一个全自动的,即插即用的篡改pipeline,用于增加模型的鲁棒性。
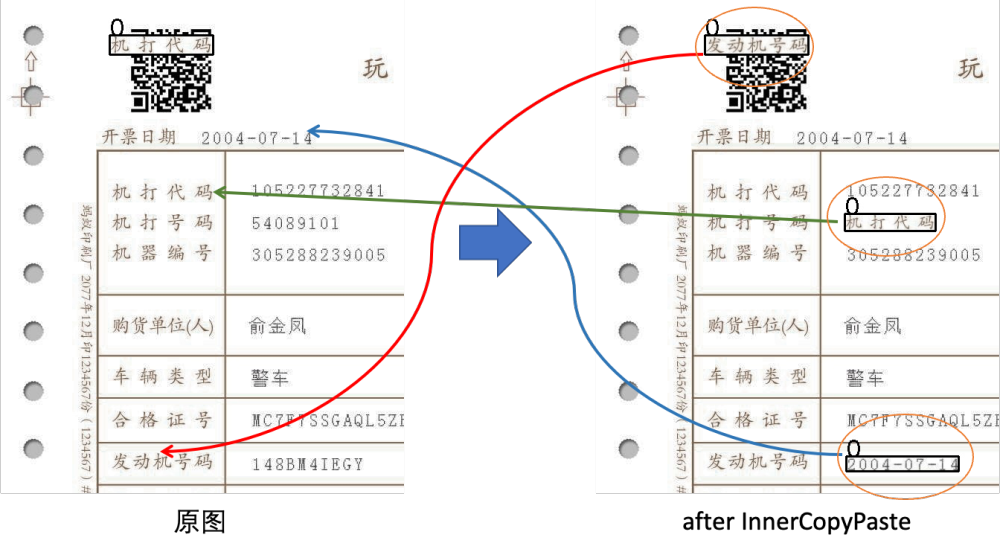
InnerCopyPaste 图片内文字替换
左图为原图,右图为经过图片内文字替换操作后的结果,图片中包括原本存在的篡改bbox和text区域,我们将这两种框做大小匹配,将大小相似的内容进行互换,同时将类别替换为篡改,这将丰富原图中的篡改类型,尤其是针对于发票和税,截图有很好的效果。
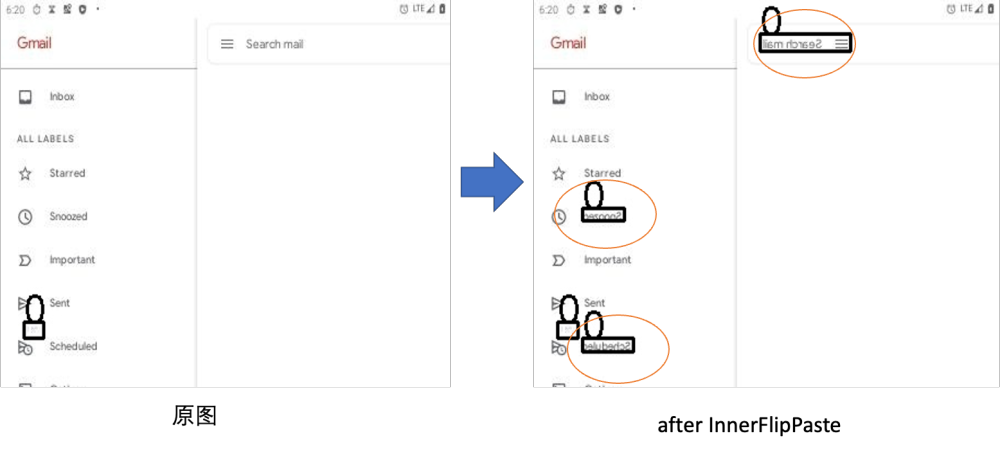
InnerFlipPaste 原地镜像
我们选择随机的框进行上下或者左右翻转
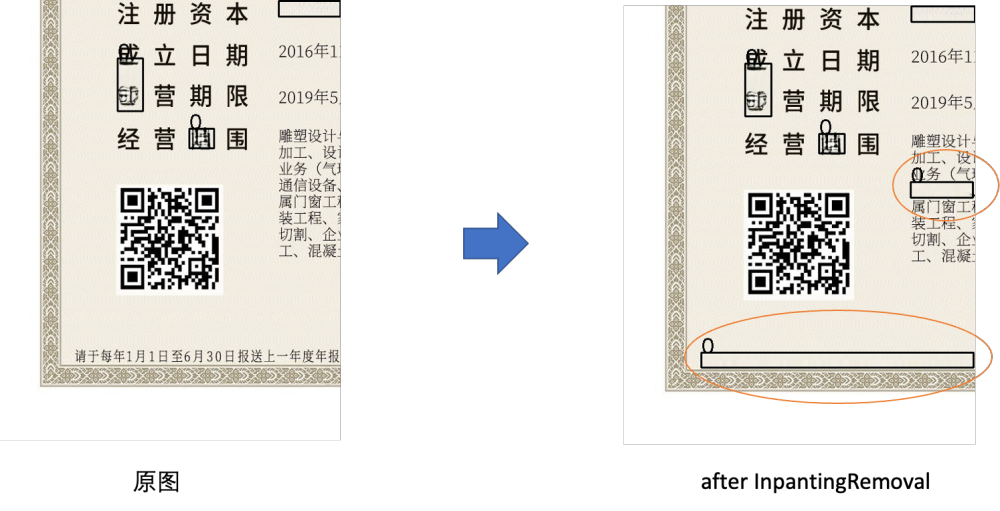
 InpantingRemoval 基于OpenCV的移除
InpantingRemoval 基于OpenCV的移除
我们选取随机文字内容进行抹除
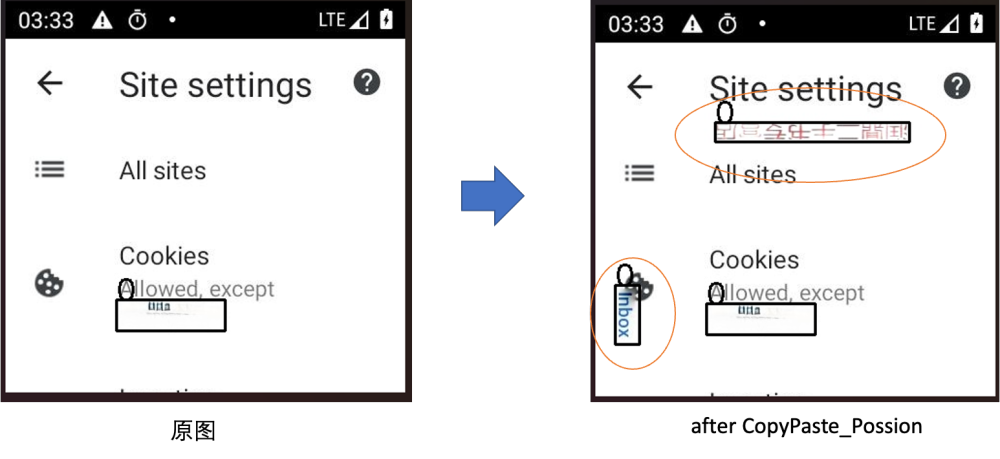
CopyPaste_Possion 基于泊松融合的copypaste增强 + Cache+随机旋转,缩放
之前的三个方法为同图间窜改,我们还做了跨图窜改,具体来说设计了一个基于缓存队列和柏松融合的CopyPaste方法,我们首先设置一个缓存队列,大小设置为300,每次遍历到图片中的所有篡改目标或者OCR识别的目标将会存储在其中,队列维护一个最大长度,使得其中的目标具有全局随机性。在数据增强环节,算法会随机选择CopyPaste的目标数量,并加上随机缩放(0.9-1.1),随机旋转翻转操作后,粘贴到该张图片的任意位置,本方法设置了copy,mixup_copy, possion_copy三种粘贴策略,出于效果考虑,最终选取泊松融合作为粘贴手段,该方法能较好的处理复制图片的边缘信息,使得融合更为自然。
prompt = ["background", "change the text font", "change the text's color"]

总结与感想

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢