

01
研究背景与动机
大语言模型往往在以英语为中心的语料上进行训练,训练语料中其余语言数据只占很少的比例。尽管如此,现有的LLM仍然展现出了一定的多语言性能。这是因为LLM执行多语言任务的能力与模型多语言对齐能力(为平行文本生成相似的表示)正相关,而近来的研究表明,LLM可以自发形成一定程度的多语言对齐。然而,这种自发形成的对齐能力仍然相对较弱,这导致模型在跨语言知识检索和跨语言行为一致上仍然存在较大问题。
近年来,有一些工作尝试为多语言大模型显式注入对齐信息,以增强模型的多语言对齐能力。这些方法可以分成两类:(1)构造翻译、语码转换等跨语言预测目标训练模型(2)直接训练模型为平行文本产生对齐的表示。然而,这些方法要么是在漫长的预训练过程中逐步建立多语言对齐,要么是在预训练之后建立多语言对齐,这就会导致模型在训练早期无法受益于对齐的多语言表示,影响跨语言迁移效果。
02
方法
本文提出PreAlign方法,以解决过往工作中多语言对齐过晚的问题。与过往工作最大的不同是,PreAlign将多语言对齐的建立提前到预训练之前,并在整个预训练过程中都尝试保持较高的多语言对齐程度,从而显著增强模型在预训练早期阶段的跨语言迁移,从而有助于跨语言知识的学习。
具体而言,PreAlign 的执行分成两个阶段:(1)预训练之前的多语言对齐注入(2)预训练过程的多语言对齐保持。执行过程如图1所示。
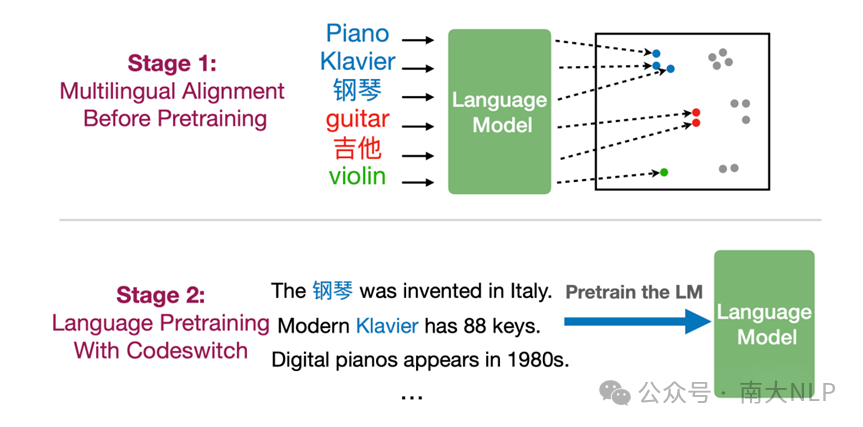 图1 PreAlign示意图
图1 PreAlign示意图
预训练之前的多语言对齐注入 我们会首先收集多语言翻译表作为多语言对齐信号,这种翻译表既可以采用现存的多语言词典,也可以使用机器翻译模型进行构建。在本文中,我们首先从单语数据中获得单词表,然后使用GPT-4为每个单词获得5个翻译。在获得翻译表之后,本文使用对比学习方法,优化一个随机初始化的模型,希望让它产生多语言对齐的表示。具体而言,给定一个英文词和它所有的翻译,PreAlign会收集这些词在每一层的表示,

然后使用一个对比学习目标来建立起不同语言对应词之间的对齐:
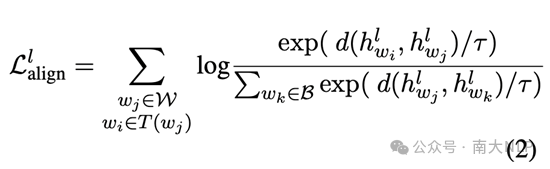
同时,为了防止仅使用对比学习找到的初始化不适合语言模型,我们添加了一个额外的语言建模目标一同优化:
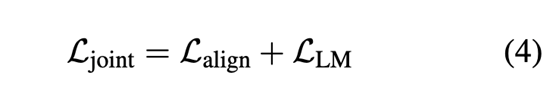
预训练过程中的多语言对齐保持 为了防止在前一阶段注入的多语言对齐知识被遗忘,我们采用Codeswitching策略来继续在预训练阶段保持多语言对齐关系。具体而言,我们会使用前一阶段收集的多语言翻译表,随机将英文文本中的单词替换为其对应的翻译。由于过往工作发现Codeswitching策略会导致较为严重的语言混合问题,我们进一步提出一个改进版本的策略,其只替换输入文本的单词,而不会影响到预测目标,具体如图2所示。
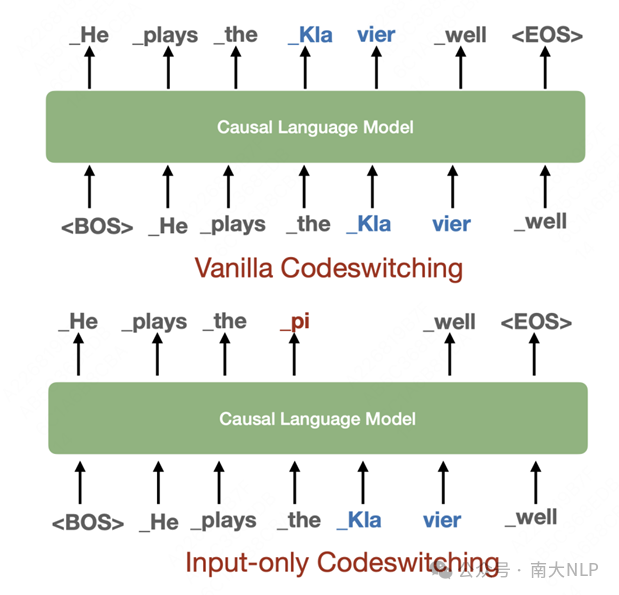 图2 Input-only Codeswitching示意图
图2 Input-only Codeswitching示意图
03
跨语言迁移能力的评估框架
为了验证PreAlign的有效性,我们考虑以英文为中心的预训练场景。此场景中,非英文数据只占较少比例,因此模型在非英文语言上的性能可一定程度反映不同方法对模型跨语言迁移能力的影响。
本文主要考虑两种语言迁移场景。第一种场景是从英文迁移到克隆英文的场景。克隆英文的词法、句法与英文完全一致,只不过不与英文共享词表映射。我们认为这种场景是最简单的迁移场景,可以作为跨语言迁移方法的合理性验证。第二种场景则是从英文迁移到中文、法文、阿拉伯文和俄文,这用来测试PreAlign方法在真实迁移场景下的性能。
本文考虑三种测试模型跨语言迁移能力的任务,分别是语言建模任务、跨语言零样本迁移任务和跨语言知识应用任务。语言建模任务衡量模型的通用语言能力,由于不同方法使用的目标语言数据相同,这个指标也能间接地评估语言能力从英文向目标语言迁移的效果。跨语言零样本迁移任务首先使用英文的下游任务监督数据微调模型,然后直接在目标语言的测试集上进行测试,这可以评估下游任务能力的迁移效果。跨语言知识应用任务在预训练阶段注入英文的知识,然后在测试阶段使用目标语言的前缀询问该知识,可以评估知识的跨语言迁移效果。
04
实验结果与分析
英文->克隆英文的实验结果
表1 中展示了PreAlign方法与基线模型在迁移到克隆语言场景的实验结果。从表中可以看到,PreAlign 相比于直接混合训练(Joint Training) 在三种测试任务上都得到了显著的提升。其中,在语言建模任务上,PreAlign通过从英文的迁移,仅使用0.1B的克隆英文数据,就能获得与10B数据相近的困惑度。在CLKA任务上,我们可以看到,Joint Training 的表现接近随机,而PreAlign则显著地提升了性能水平。
表1 PreAlign与基线模型在从英文迁移到克隆英文设置的性能比较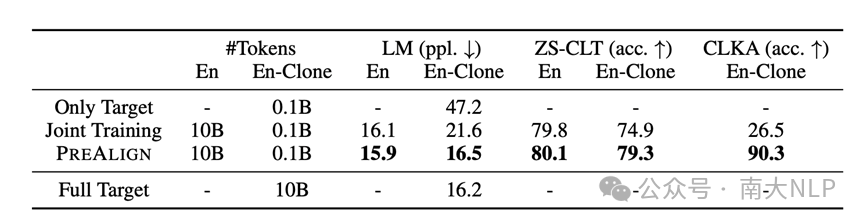
为了进一步分析模型在训练过程中CLKA性能的变化动态,我们将训练过程等分成每250步一个时间窗口,在每个时间窗口注入新的知识,然后在时间窗口结束后对该知识的准确率进行测试。我们交叉考察了 (Train: En, Test: En), (Train:En, Test: En-Clone), (Train:En-Clone, Test: En), (Train: En-Clone, Test: En-Clone) 四种情况。下图中展示了对应结果。从左上图(Train: English, Test: English)中可以看到, 随着模型语言能力的上升,其学习新知识的速度也在变快,这说明了模型的知识学习能力与语言能力正相关。在右下图(Train: English-Clone, Test: English)中,我们观察到PreAlign的知识准确率随着训练进行逐渐上升,但Joint Training始终停留在25%-30%的水平,这证明了PreAlign在提升模型知识迁移方面的能力。
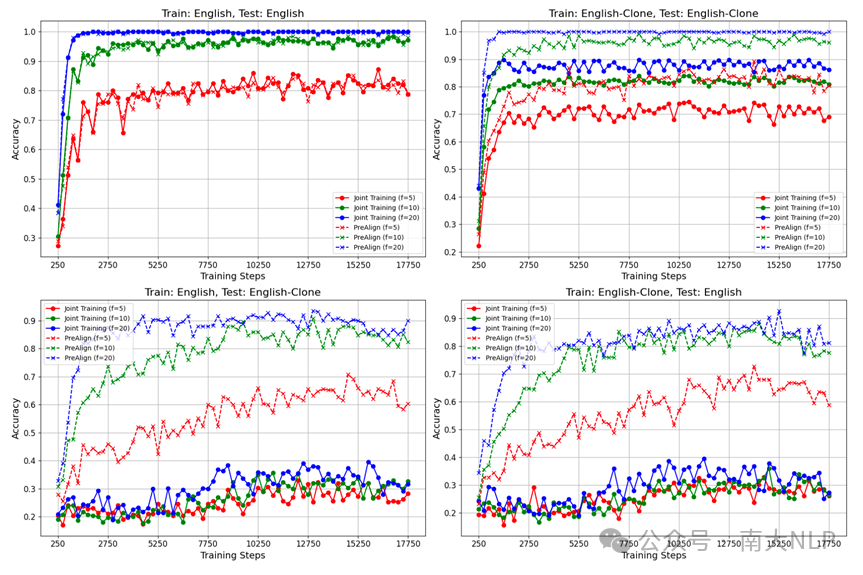 图3 跨语言知识应用准确率在训练过程中的变化情况
图3 跨语言知识应用准确率在训练过程中的变化情况
消融实验
下表展示了对于PreAlign方法中的设计细节的消融实验。从表中可以看到,本文提出的在预训练之前做预对齐以及改进的Codeswitching策略对于模型性能都有帮助。其中,预对齐对于CLKA的能力提升具有至关重要的作用。
表2 PreAlign的消融实验
表示对齐性分析
下图中展示了PreAlign 模型与Joint Training模型在训练过程中表示对齐性的变化情况。可以看到,尽管Joint Training能够自发地形成一定程度的多语言对齐,但其最终仍然收敛到一个较低的水平;而对于PreAlign而言,其在预训练之前注入的多语言对齐信息虽然会在预训练过程中有一定程度的下降,但始终保持在较高的水平。
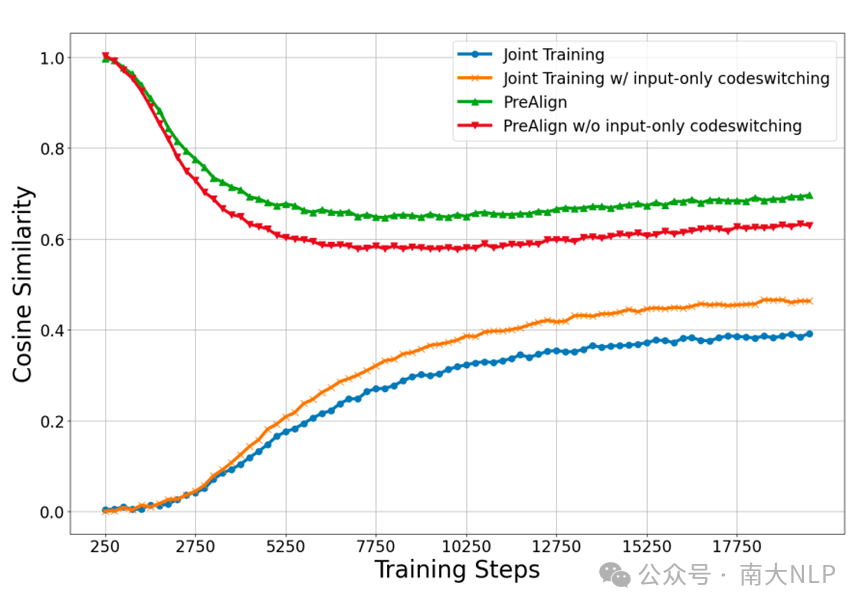 图4 词向量对齐程度在训练过程中变化情况
图4 词向量对齐程度在训练过程中变化情况
对齐可泛化性分析
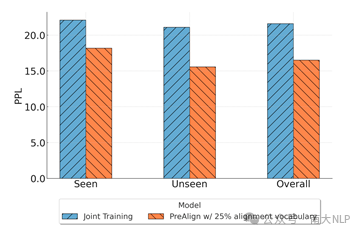
建立完整的多语言翻译表在现实生活中代价较大,为此,我们探究了在仅使用部分翻译表的情况下,词语之间的对齐能否从见过的词对泛化到没见过的词对。下表是对应的实验结果。从表中可以看到,当仅使用25%的翻译表时,模型仍然可以相比于Joint Training保留大部分的性能提升。我们进一步分析了模型在见过词对和未见词对的建模困惑度,结果展示了下图中,可以看到,对于目标语言未在翻译表中出现的词,其困惑度相较于Joint Training仍然显著下降,这验证了PreAlign能够实现对齐的词对间泛化。
表3 在使用部分翻译表时,PreAlign的结果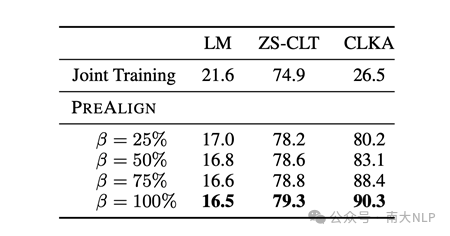
真实语言场景的实验结果
下表展示了Joint Training与PreAlign在真实语言场景下的性能比较。从表中可以看到,PreAlign在真实语言迁移场景下仍然能够相较于Joint Training 获得明显的性能提升,这证实了PreAlign在实际应用中的价值。
表4 PreAlign在真实语言迁移场景下的性能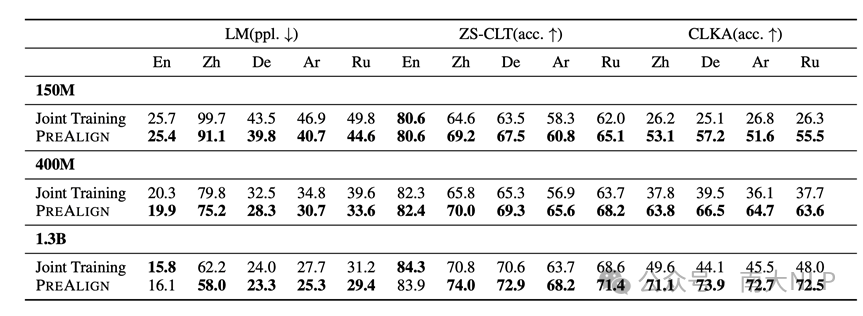
05
结论
本文提出了PreAlign框架,通过将对齐建立的阶段提前到预训练之前,来更好地实现跨语言的迁移效果。实验和分析都验证了PreAlign的有效性。未来潜在的研究方向在于更加有效的多语言对齐建立方式和在更大规模场景下的评估。
论文:https://aclanthology.org/2024.emnlp-main.304
代码:https://github.com/NJUNLP/PreAlign
B站视频讲解:
https://www.bilibili.com/video/BV1khSKYSEKT/?
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢