
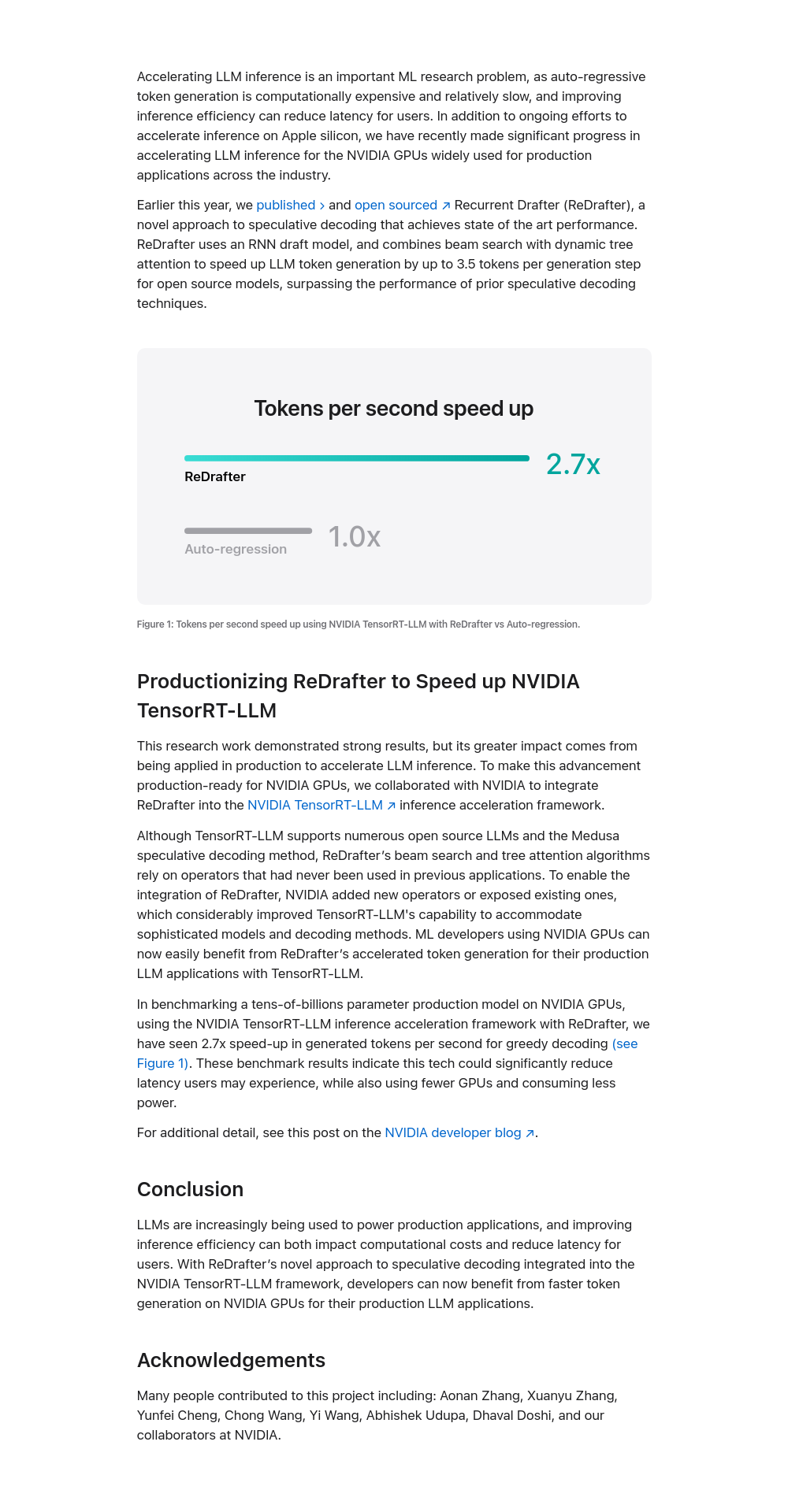
加速大型语言模型(LLM)推理是重要的机器学习研究课题,因为自回归生成计算成本高且速度较慢,提高推理效率可以减少用户延迟。近期,我们在加速NVIDIA GPU上的LLM推理方面取得了显著进展。今年早些时候,我们发布了并开源了Recurrent Drafter(ReDrafter),这是一种新颖的推测解码方法,实现了最先进的性能。ReDrafter使用RNN草稿模型,结合波束搜索和动态树注意力技术,将开源模型的每步生成速度提升至最高3.5个令牌,超越了之前的推测解码技术。测试结果显示,ReDrafter的令牌生成速度提升了2.7倍。
本专栏通过快照技术转载,仅保留核心内容
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢