
Datawhale分享
嘉宾:张林芳,科大讯飞Maas平台总监

大模型的浪潮:技术革新与应用突破
近年来,大模型技术迅猛发展,从 ChatGPT 到星火大模型,它们正在以惊人的速度重塑我们的生活与工作方式。自 2022 年 11 月发布以来,ChatGPT 在短短两个月内用户量突破 1 亿,而今年 5 月的访问量更是达到 23 亿次,日均调用 7700 万次。同样,星火大模型也在多个应用场景中实现了调用量的爆发式增长。
解锁大模型的应用之路:从技术到落地
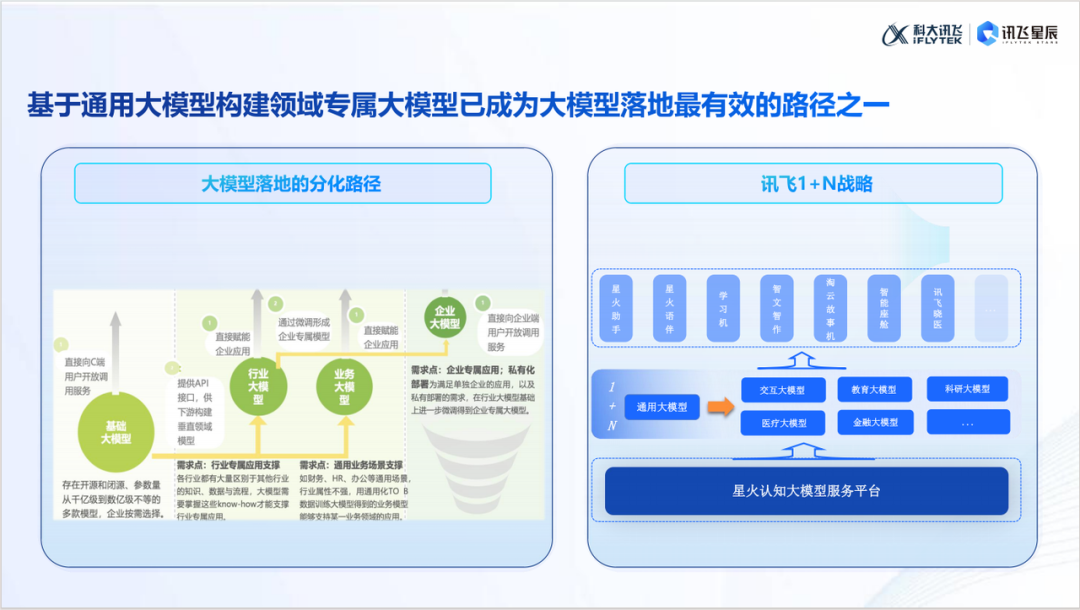
如何让大模型快速落地?张林芳老师从技术发展路径出发,为我们描绘了清晰的应用蓝图:
技术大模型阶段 这一阶段的核心是构建开放性和适应性强的通用大模型,既服务于 C 端用户的日常需求(如星火 APP),也为开发者通过 API 接口实现多场景应用提供基础支持。
通用大模型 + X 阶段 此阶段大模型逐步结合特定场景或行业需求,形成以下三种主要应用方向:
行业优化:融入行业专属数据,为金融、医疗等垂直领域提供更精准的解决方案。
场景定制:围绕业务场景优化,如办公协作和财务管理,满足广泛的需求。
企业定制:根据企业专属需求开发,提升数据处理和内部效率。
张老师指出,行业巨头倾向于开发通用大模型以占据市场高地,而创业公司则更适合聚焦垂直领域,解决特定场景的核心问题。通过结合行业数据与场景需求,基于通用模型快速构建专属解决方案,是推动大模型高效落地的关键策略。
探索大模型精调:从理论到实践
要实现大模型在特定领域的深度应用,精调是必不可少的关键环节。张林芳老师通过深入浅出的讲解,帮助我们理解精调过程中的核心概念:
预训练:相当于为模型奠定基础知识。通过大量通用数据的训练,模型具备了广泛的理解和生成能力。
精调:在预训练模型的基础上,针对特定领域或任务进行深度优化,使其更契合实际应用需求。
SFT(监督微调):通过高质量的训练数据指导模型学习,帮助其提升特定任务的表现。
JSON 格式:用于组织和呈现数据的标准形式,通过清晰的结构化设计,帮助模型更高效地理解和处理信息。
从数据构建到模型评估,大模型精调的全过程需要系统化的规划和强大的执行力。通过精调,可以让通用模型成为特定领域的“专家”,从而实现从理论到应用的全面突破。
数据构建:大模型精调的基础
明确数据需求:数据内容需逻辑清晰且信息完整,以确保训练数据符合模型预期的输出目标。 多样化数据输入:增加表达方式的多样性,提升模型的泛化能力,使其能适应更多实际场景。 标准化输出:采用如 JSON 格式等结构化形式整理数据,降低模型的理解复杂度,提升回应的准确性。
模型选择:找到最适合的工具
场景适配性:确保模型能满足具体场景的需求。 模型尺寸与性能:在性能与计算资源之间找到平衡点。 数据量级需求:选择能有效处理既定数据规模的模型。 训练成本与时长:在预算范围内优化训练效率。
低代码精调:适合新手和快速开发场景,仅需调整核心变量即可完成模型精调。 Notebook 模式:为有技术基础的开发者提供完全可控的精调环境,可深入调整所有训练参数。
模型训练与评估:精调的核心环节
准备阶段:包括数据构建和模型选择。这一步为后续训练奠定了坚实的基础。 训练阶段:需要配置训练环境(如 GPU/TPU 平台)、调整训练参数(如学习率、Batch Size、Epoch 等),并根据任务类型(如文本生成、意图分类、实体抽取等)设计训练任务。 结果检查:实时监控训练进度,观察损失曲线的变化。一条理想的曲线应呈现出快速下降后逐渐平稳的趋势,避免出现过拟合等问题。 输出模型:完成训练后,将精调模型保存为可用的文件格式,供后续应用。
Datawhale AI 冬令营是一个在冬季举办的大规模 AI 学习活动,旨在汇聚产学研资源和开源社区力量,为学习者提供丰富的学习和实践机会,提升他们的专业能力和就业竞争力。第二期冬令营报名将于 12 月 22 日正式启动,如果你也希望掌握最新 AI 应用的核心技能,欢迎关注公众号信息。
教程开源地址:
 一起“点赞”三连↓
一起“点赞”三连↓内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢