
DRUGAI
今天为大家介绍的是来自美国国家卫生研究院的陆致用教授团队的一篇论文。临床试验中的患者招募是一项挑战。作者介绍了TrialGPT,一个基于大型语言模型的端到端zero-shot患者与试验匹配框架。TrialGPT包含三个模块:首先,TrialGPT-Retrieval模块进行大规模筛选,检索候选试验;接着,TrialGPT-Matching模块预测患者在各项标准上的适应性;最后,TrialGPT-Ranking模块生成试验级别的评分。作者在三个由183名合成患者组成的队列上进行了评估,试验包括超过75,000个试验注释。TrialGPT-Retrieval能够从初始集合中召回超过90%的相关试验,且仅使用不到6%的数据。对1015个患者-标准配对的人工评估显示,TrialGPT-Matching的准确率为87.3%,且其解释与专家的表现接近。TrialGPT-Ranking的评分与人工判断高度相关,并且在试验排名和排除方面超越了最优秀的竞争模型,提升幅度达43.8%。此外,用户研究表明TrialGPT能将患者招募的筛选时间缩短42.6%。总体而言,这些结果展示了使用TrialGPT进行患者与试验匹配的潜力。

临床试验旨在评估医学干预的有效性,但患者与合适试验的匹配过程复杂且费时。传统的手动匹配不仅劳动强度大,而且容易出错。近年来,人工智能(AI)在提高患者-试验匹配效率和准确性方面展现了潜力。匹配任务有两种主要方式:“试验到患者”匹配和“患者到试验”匹配。本文聚焦于患者为中心的“患者到试验”匹配,旨在帮助个体患者和转诊机构快速找到合适的临床试验。
现有方法多依赖神经网络将患者记录和试验标准编码成密集嵌入,通过相似性搜索进行匹配,但这种方法需要大量配对数据,并且不可解释,难以调试。为此,本文提出了一种基于大型语言模型(LLM)的端到端解决方案——TrialGPT,旨在通过试验检索、匹配和排序三个模块,提高患者-试验匹配的效率和透明度。TrialGPT首先通过关键词生成和混合融合检索从大量候选试验中找出相关试验,然后通过自然语言解释、定位相关句子和标准分类,预测患者在各项标准上的适应性。最后,TrialGPT通过试验级别的评分对试验进行排序,从而为患者提供最佳匹配的试验。
评估结果表明,TrialGPT-Retrieval能够召回超过90%的相关试验,仅使用不到6%的候选试验。TrialGPT-Matching在1015个患者-标准配对上达到了接近专家的准确率。TrialGPT-Ranking的评分与专家注释高度相关,能有效匹配符合条件的试验并排除不符合的试验,表现比最佳基线提高43.8%。用户研究表明,TrialGPT在临床试验匹配中能将时间缩短约42.6%,大大提高了匹配效率。
模型与数据集
TrialGPT的架构如图1所示。整体上,TrialGPT由三个组件组成:检索(图1a)、匹配(图1b)和排序(图1c)。TrialGPT-Retrieval的设计旨在从大量初始候选试验中筛选出大部分不相关的试验。具体而言,TrialGPT-Retrieval根据患者摘要生成关键词列表,并将其输入到混合融合检索器中,从可能庞大的初始试验集合中筛选出一个相对较小的子集,同时保持对相关临床试验的高召回率。这个检索步骤的设计旨在确保TrialGPT在实际应用中的可扩展性,比如在匹配多达23,000个正在进行的临床试验时。
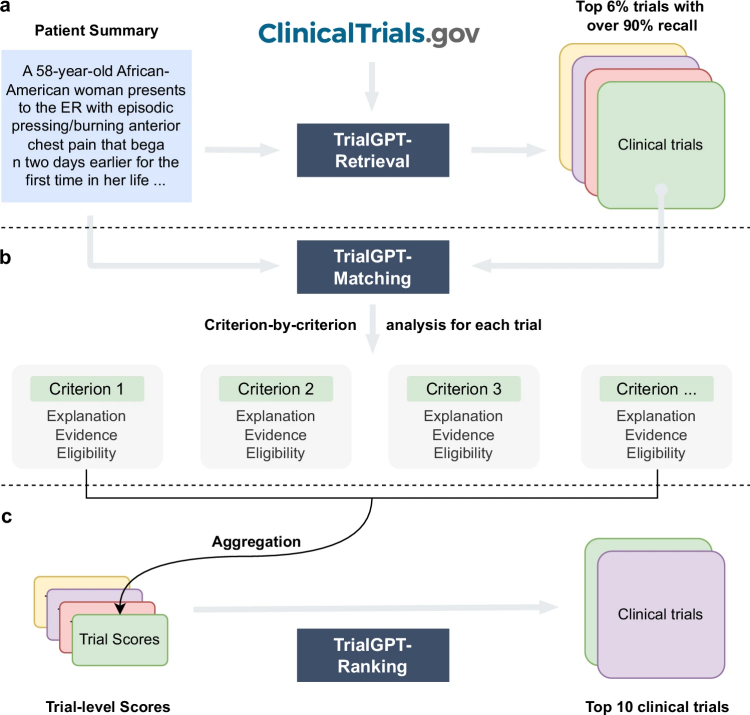
图 1
对于TrialGPT-Retrieval返回的每个候选临床试验,TrialGPT-Matching以逐项标准的方式分析给定患者的适应性。对于每一项标准,TrialGPT-Matching生成三个要素:(1)患者与标准的相关性解释;(2)在患者记录中与标准相关的句子位置;(3)患者-标准配对的适应性分类。最后,TrialGPT-Ranking将TrialGPT-Matching的标准级预测汇总,生成试验级别的评分,这些评分可以用于根据适应性对临床试验进行排序,并排除明显不符合条件的试验。
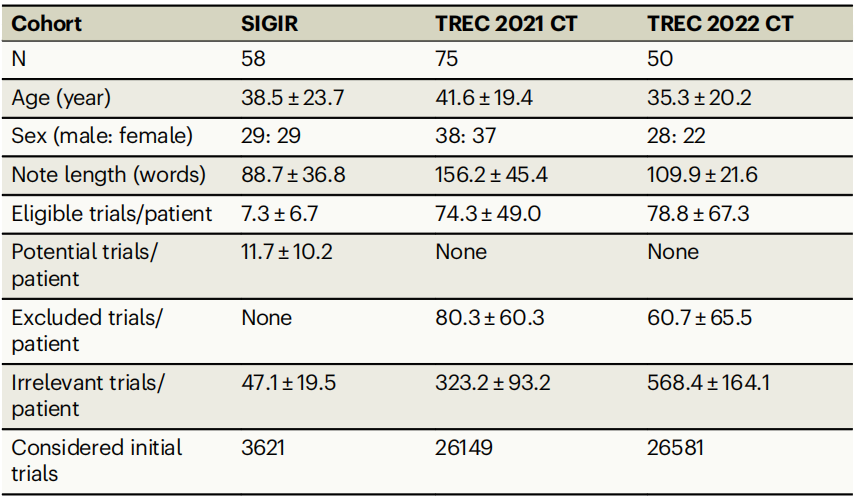
为了评估TrialGPT,作者使用了来自三个公开数据集的患者摘要和临床试验数据:2016年由信息检索特别兴趣小组(SIGIR)发布的患者-试验匹配测试集,以及2021年和2022年文本检索会议(TREC)临床试验(CT)赛道的数据。SIGIR数据集包含三种患者-试验适应性标签:无关(“不会将此患者推荐到该临床试验”)、潜在(“考虑进一步调查后可能推荐此患者参加该临床试验”)和合格(“非常可能将此患者推荐到该临床试验”)。TREC数据集也有三种适应性标签:无关(“患者与试验没有任何相关性”)、排除/不合格(“患者符合试验目标疾病,但排除标准使其不合格”)和合格(“患者符合参加试验的条件”)。患者队列的基线统计数据见表1。
表 1
TrialGPT-Retrieval可以生成有效的临床试验过滤的关键词
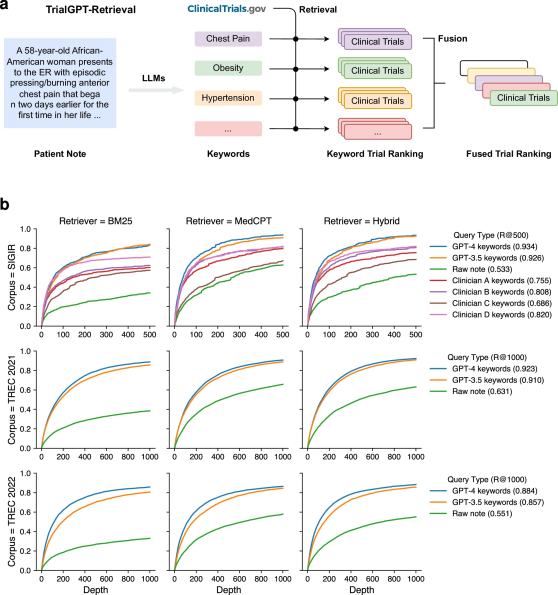
图 2
TrialGPT-Retrieval可以生成关键词,有效地筛选临床试验。图2a展示了在检索阶段,大型语言模型被用来生成用于初步筛选临床试验的关键词。每个关键词经过混合检索器匹配词汇和语义信息,从而获得相关临床试验列表,并通过互惠排名融合将结果合并为排名列表。作者使用三组数据集评估了由GPT-4和GPT-3.5生成的关键词的检索性能,并与直接使用原始患者记录进行试验检索进行了比较。图2b展示了在不同检索深度下,相关临床试验的召回率。
三组数据集中,GPT-4和GPT-3.5生成的关键词表现最好,而直接使用原始患者记录的性能最差。这表明,大型语言模型能够有效地从患者记录中生成关键词,用于临床试验检索。在检索器方面,语义MedCPT比词汇匹配的BM25检索器表现更好,混合检索器则取得了最佳表现。在SIGIR数据集中,临床医生生成的关键词表现介于LLM生成的关键词和原始记录之间,表明大型语言模型在临床试验检索中能生成比人类临床医生更好的关键词。
TrialGPT-Matching实现了较高的标准级预测精度
作者从SIGIR数据集中选取了105对患者-试验配对,这些配对包含1015个患者-标准配对,并由三位医生手动标注,评价GPT-4生成的标准级输出要素,包括:1)患者与标准相关性的解释正确性,2)患者记录中与标准相关的句子位置,3)标准级的患者适应性预测。通过专家标注的共识结果作为真实标签。
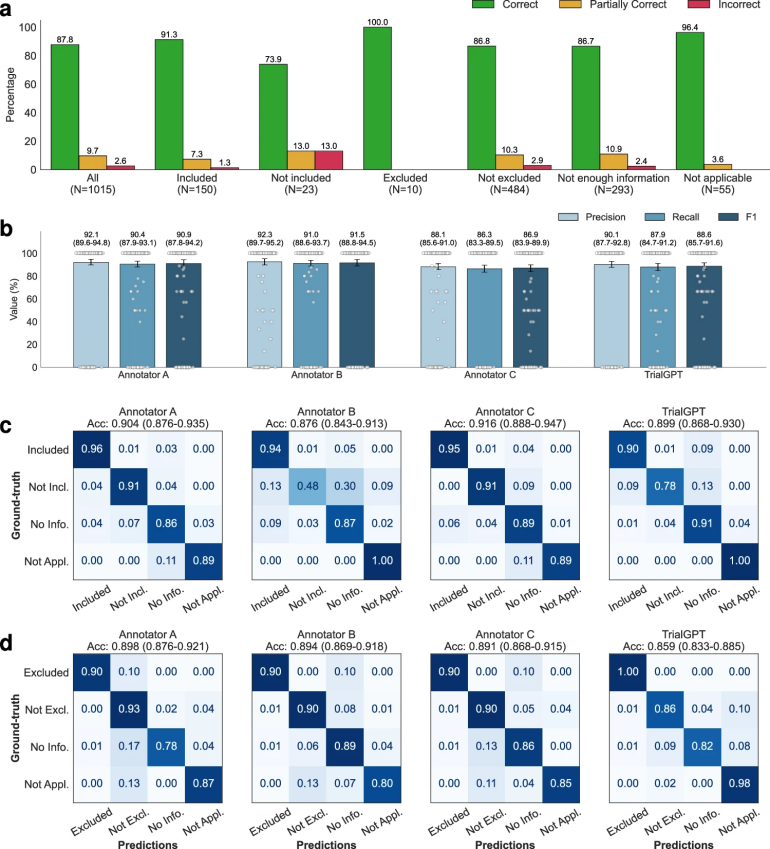
图 3
在评估相关性解释时,图3a显示了TrialGPT解释的“正确”、“部分正确”和“错误”的百分比。整体而言,87.8%的解释为“正确”,9.66%为“部分正确”,仅2.56%为“错误”。错误的解释大多发生在标注为“未纳入”和“未排除”的标准上,这通常需要隐性推理。图3b显示,TrialGPT预测的句子位置的精准度为90.1%,召回率为87.9%,F1分数为88.6%。这一表现接近人类专家的水平(86.9%至91.5%)。这表明TrialGPT能够准确定位患者记录中的相关句子,为专家提供强大的可解释性。
在评估适应性预测时,图3c和图3d展示了TrialGPT与专家标注的混淆矩阵。整体而言,TrialGPT-Matching在标准级预测准确度为0.873,接近专家的表现(0.887–0.900)。对于纳入标准,TrialGPT的预测准确度为0.899,位于专家的准确度范围(0.876至0.916)内。这表明,TrialGPT能够准确地预测患者在标准级的适应性,其表现接近人类专家。
TrialGPT-Ranking得分反映患者-试验适应性
在图1c中,TrialGPT-Ranking通过将标准级的预测结果汇总为试验级别的评分,来判断患者是否符合某个临床试验的条件。该模块分析了患者-试验适应性与试验级评分之间的相关性,试验级评分有两种计算方法:线性聚合和LLM聚合。在三组数据集中,作者对TrialGPT-Retrieval返回的前500个临床试验进行了分析,结果如图4所示。
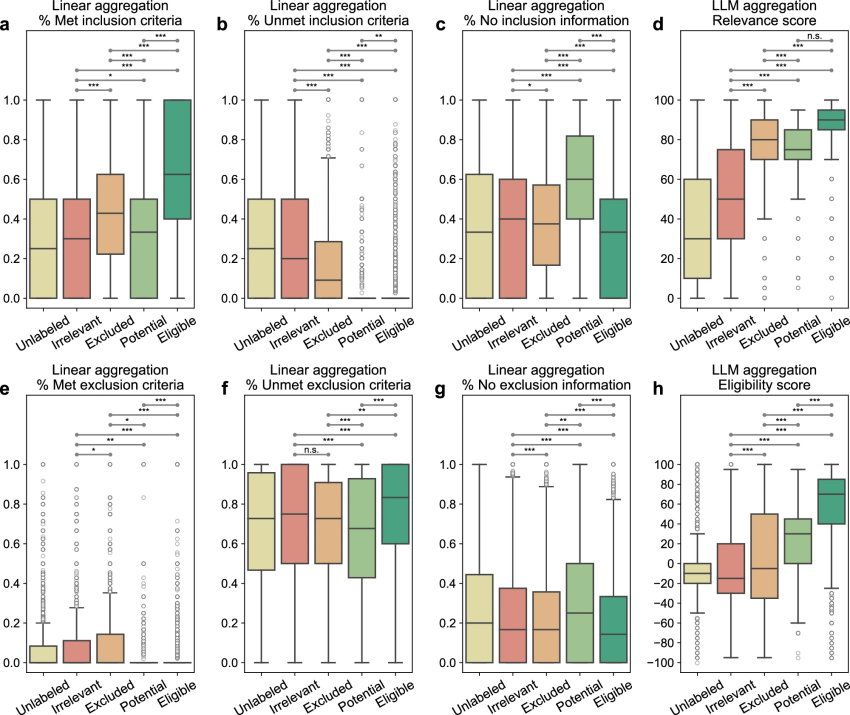
图 4
线性聚合:通过统计六种不同标准级适应性预测的百分比来计算六个评分。图4a展示了被预测为“纳入”的纳入标准百分比,结果表明,在合格的临床试验中,患者满足的纳入标准比例最高,而在无关的临床试验中则最低;对于相关但不合格的试验,满足的标准比例介于两者之间。图4b则展示了预测为“未纳入”的纳入标准百分比,其趋势大致与图4a相反。
LLM聚合:作者还使用LLM进一步聚合TrialGPT的标准级预测结果,得到一般相关性评分和适应性评分。图4d中的一般相关性评分显示,无关的患者-试验配对得分显著低于其他配对,而合格和不合格/潜在配对有一定重叠,但合格配对得分显著较高。图4h中的适应性评分表明,负分表示不合格,正分表示合格,0分表示中立。整体来看,LLM聚合的适应性评分与相关性评分的趋势相似,合格和排除(但相关)配对在适应性评分的分布上重叠最少,表明该评分能有效区分这两组配对。
总结来说,TrialGPT-Matching的标准级预测可以通过TrialGPT-Ranking聚合为试验级评分,这些评分与患者-试验适应性高度相关。线性聚合结果表明,合格的患者-试验配对有最高比例的满足纳入标准和未满足排除标准,而不合格的配对则表现出相反的特点。LLM聚合结果也与专家手动标注的适应性标签显著相关。这些结果表明,TrialGPT的聚合评分可以用于排序或排除临床试验,帮助患者招募。
TrialGPT-Ranking可以有效地对候选临床试验进行排序和排除
TrialGPT-Ranking通过将标准级预测聚合为试验级评分,用于排序和排除临床试验。根据相关性分析,设计了评分方法以生成试验级评分,结果在表2中展示。
表 2
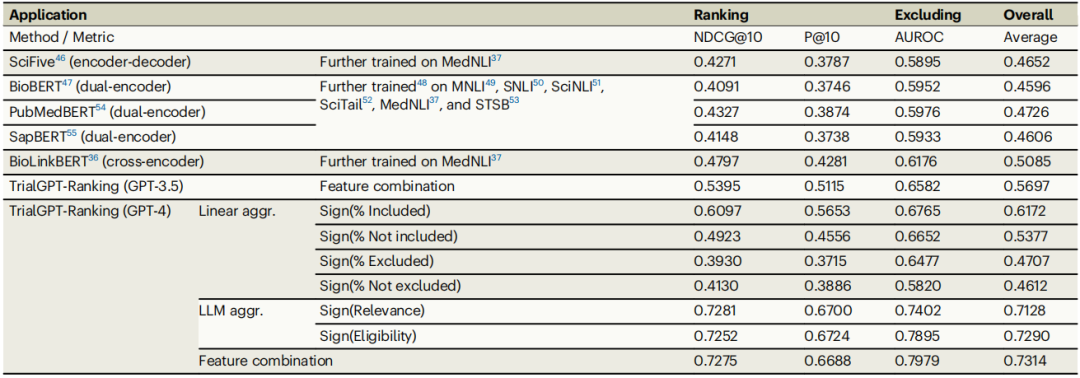
临床试验排序:TrialGPT-Ranking在NDCG@10和P@10指标上优于所有基线模型。GPT-4支持的TrialGPT使用LLM聚合适应性评分,其NDCG@10和P@10分别为0.7252和0.6724,比最佳基线(BioLinkBERT)高出显著幅度。结合线性聚合和LLM聚合的评分进一步提升了性能,NDCG@10达到了0.7275。
排除不合格试验:在排除不合格试验任务中,TrialGPT-Ranking也显著超越基线模型。GPT-4支持的TrialGPT-Ranking在AUROC指标上达到0.7979,比最佳基线(BioLinkBERT)的0.6176提升了43.8%。这一结果表明,TrialGPT能够有效区分合格和不合格的临床试验。
综上,TrialGPT-Ranking不仅在排序候选试验中表现卓越,还能高效排除不合格试验,从而优化患者匹配流程。
TrialGPT可以减少患者-试验匹配的筛选时间
为评估TrialGPT是否能协助临床医生提高患者-试验匹配效率,作者在图5a中进行了用户评估。评估包含六个肿瘤学临床试验,其中四个由国家癌症研究所进行,其他两个也有密切关系。医生们根据实际的患者转诊请求创建了六个半合成的病例,案例1至3为简短的患者摘要,案例4至6为更详细的描述。两位医生(标注员X和Y)进行匹配任务,其中一半患者-试验配对使用TrialGPT预测,另一半则不使用。结果显示,使用TrialGPT时,标注准确率提高到97.2%,而不使用时为91.7%,虽然差异在统计上不显著。
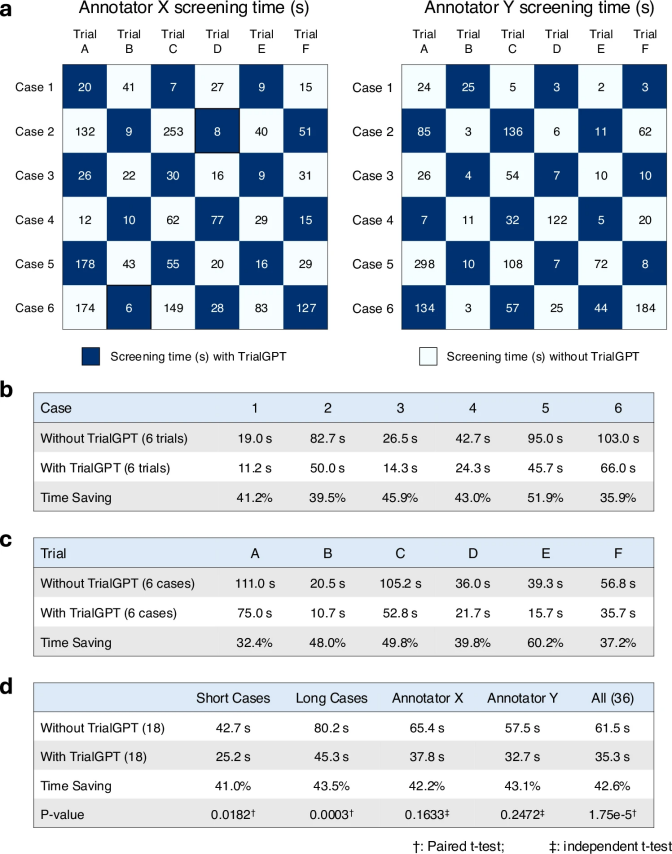
图 5
图5b展示了匹配效率的对比结果。使用TrialGPT时,两位标注员在筛选效率上没有显著差异(32.7秒与37.8秒,p=0.73),但在筛选时间上有明显的时间节省。不同患者的时间节省为35.9%至51.9%,不同试验的时间节省为32.4%至60.2%。总体来说,长案例比短案例节省的时间更多(长案例为43.5%,短案例为41.0%)。所有患者-试验配对的整体时间节省约为42.6%,这表明TrialGPT能显著提高患者招募的效率。
讨论
本文提出了TrialGPT,一个基于大型语言模型进行端到端患者-试验匹配的框架。其创新之处在于利用LLM完成三个关键任务:1) 初始筛选,筛除大部分无关试验;2) 标准级预测,通过解释进行患者与试验的匹配;3) 聚合标准级预测,生成试验级评分,用于排序和排除试验。与传统结构化方法相比,TrialGPT通过自然语言分析患者摘要和试验标准,提供了更大的灵活性。实验结果表明,TrialGPT能够有效回忆相关试验,并准确预测标准级适应性,同时显著减少42.6%的筛选时间。尽管存在一些限制,TrialGPT展示了在临床试验匹配中的潜力,未来可进一步探索开源LLM和多模态数据的整合。
编译|于洲
审稿|王梓旭
参考资料
Jin Q, Wang Z, Floudas C S, et al. Matching patients to clinical trials with large language models[J]. Nature Communications, 2024, 15(1): 9074.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢