
药物研发一直是科学界最具挑战的领域之一。面对着多个目标的优化需求,如药物的吸收、分布、代谢、排泄(ADMET)等,传统方法往往受限于数据稀缺性和模型迁移性。近期,中南大学曹东升和湖南大学曾湘祥的研究团队在Journal of Medicinal Chemistry发表了一篇题为“MPCD: A Multitask Graph Transformer for Molecular Property Prediction by Integrating Common and Domain Knowledge”的论文,为分子属性预测领域带来全新视角。
MPCD模型的成功展示了如何结合领域知识与多任务学习,应对数据稀缺的挑战。

MPCD通过整合通用知识与领域知识,解决了分子预训练模型在下游任务中的“优化目标不匹配”问题,大幅提高了预测性能,尤其在数据稀缺场景中优势明显。
多任务学习(MTL):利用任务之间的相关性,在数据量有限的情况下,提升预测精度并增强模型的鲁棒性。
关系感知自注意力机制:全面捕捉分子的局部与全局结构信息,赋予模型更强的分子表征能力。
该模型在ADMET属性预测、分子物理化学性质和活性悬崖预测中表现出色,在了小数据集和不平衡数据集上效果瞩目。
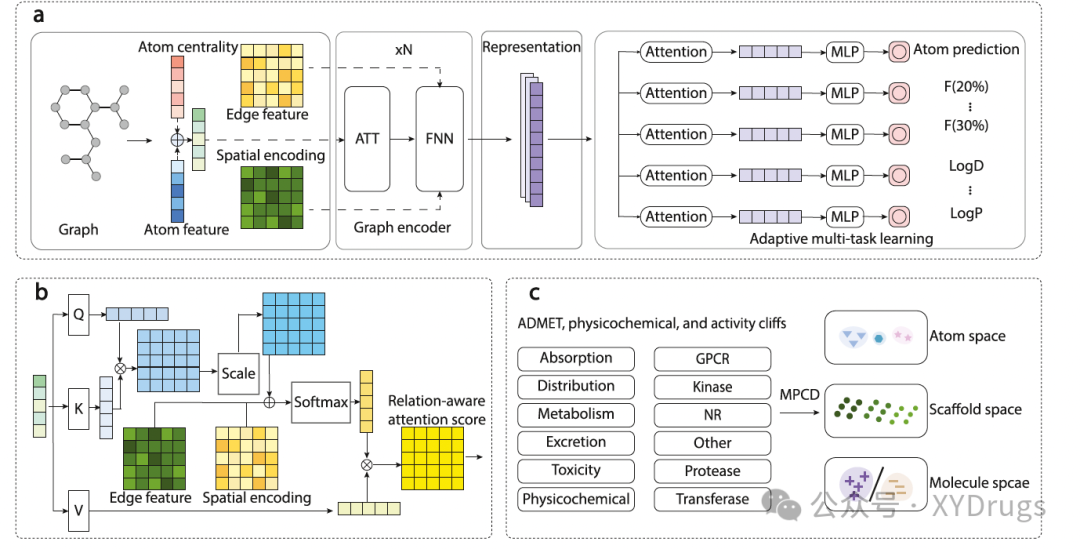
MPCD框架(图1a)包含两个主要组件:一个具有关系感知自注意力机制的图编码器和一个带有注意力权重的自适应MTL模块。具体来说,关系感知自注意力机制将原子特性(例如原子类型和中心性)作为Query-Key矩阵的输入特征,同时将节点的空间信息和边的编码作为关系偏置(图1b)。此外,MPCD能够在不同层次上区分原子、骨架和分子(图1c)。
预训练:
利用掩码节点预测(Mask Node Predictions),通过随机替换图节点并预测其原始类型,模型能够在无标注数据上学习分子图的通用特征。同时将分子化学性质描述符(如分子量和TPSA)融入预训练目标,提升模型对化学特性的感知能力,进一步优化后续任务的表现。
微调:
使用多个ADMET和物理化学性质的分类和回归数据集对模型进行微调,特别是在高数据量、低数据量和不平衡数据场景下,MPCD模型表现出较强的鲁棒性与泛化能力。此外,利用MoleculeACE数据集评估了模型在预测化合物生物活性(特别是活性断崖)方面的能力,结果表明模型在不同任务中具有一致的高性能。
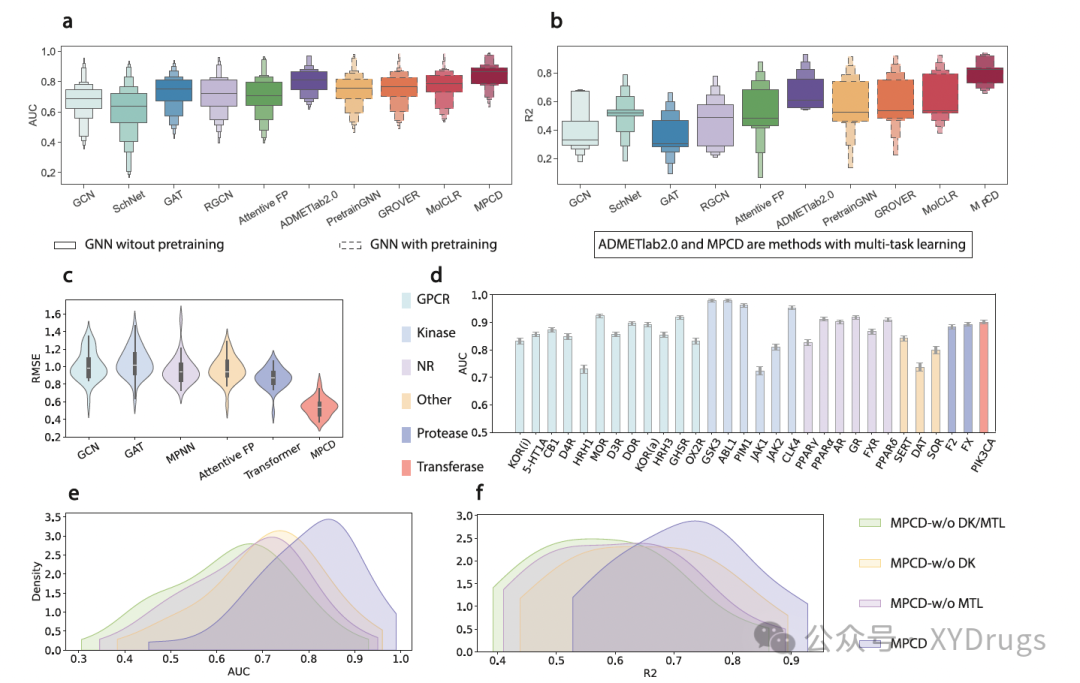
我们首先在数据量较大的ADMET和物理化学数据集上评估了我们的MPCD方法,与基线方法进行比较,这些数据集每个都有超过1000个数据点。分类(图2a)和回归(图2b)任务的结果显示,MPCD在41个数据集上表现优异。与其他九种图神经网络(GNNs)相比,MPCD在所有数据集上都展示了6.79%的分类任务提升和27.4%的回归任务提升,此外,其他度量的平均提升范围在5.99%到32.07%之间。MPCD的表现相比于从头训练的GNN方法(如GAT、GCN、Attentive FP等)和自监督学习方法(如PretrainGNN、GROVER、MolCLR)在所有数据集中具有更低的方差和更强的鲁棒性,体现了其有效性。
在评估MPCD在活性悬崖数据集(activity cliffs)上的表现时,我们发现MPCD在这类数据集上也表现出色。活性悬崖数据集中,两个结构相似的分子即使稍有结构变化,也可能导致其生物活性发生显著变化。MPCD在30个数据集上的整体相对提升为37.20%(均方根误差RMSE为0.54)。此外,MPCD能够有效识别活动差异分子,其平均曲线下面积(AUC)为84.27%。
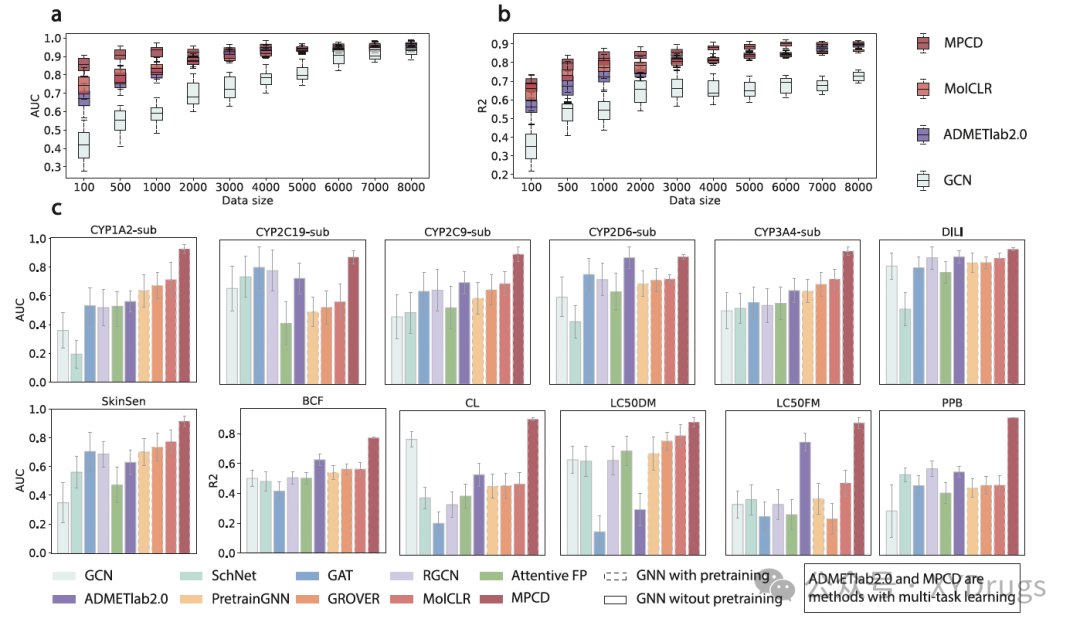
在现实世界的应用中,用于分子属性的标记数据量各异,分布情况也不同。低数据空间指的是数据集的规模小于1000,无法为深度学习提供完整的数据分布来学习通用模型,这会导致训练数据的过拟合。一些现有的方法使用数据增强技术来扩展训练数据的分布空间,但分子的增强需要一定的专业知识,且耗时不经济,而我们的方法无需数据增强即可解决这个问题。
由于获取实验数据集的困难和高成本,应用分子表征模型有效处理有限规模数据集变得尤为重要。为此,我们进一步分析了MPCD和基线方法在小规模数据集上的表现。实验评估了在缩小版训练数据集上应用MPCD和基线方法的有效性,训练集的大小范围从100到8000,分别在hERG和LogD任务上进行了评估。图3a和图3b中的结果分析显示,随着数据集大小的减少,AUC和R2指标的表现有所下降。尽管训练样本减少导致性能下降,但在有限规模数据集上,我们的方法始终表现出与基线方法竞争的结果。具体来说,当数据集大小为100时,MPCD在hERG和LogD任务上的提升分别为78.8%和66.77%,超出最佳基线方法17.9%和13.2%。
这些发现强调了预训练任务和自适应多任务学习(MTL)的优势,使MPCD对标记数据的依赖减少。类似的结论也从原始低数据空间的观察中得出,这与随机抽样的低数据空间有所不同。在这种情况下,数据集通常具有显著的分布偏差。例如,对于数据集大小小于1000的低数据空间任务,包括CYP 1A2/2C19/2C9/2D6/3A4 sub、DILI、SkinSen、BCF、CL、LC50DM和LC50FM,MPCD平均超出基线27.02%(见图3c)。这些结果表明,MPCD提供了一个在小规模和不平衡数据集上表现良好的统一属性预测框架。
更具挑战性的场景是数据分布不平衡。例如,PPB数据集的标签分布从0到100,且中位数为93。这表明数据在93到100之间的分布比在0到93之间的分布更为密集,因此PPB数据集是一个低数据空间和不平衡标签分布的例子。MPCD在PPB数据集上超出基线12.33%,证明了MPCD在处理低数据空间和不平衡数据集中的有效性(见图3c)。
MPCD在低数据环境下的显著提升主要归因于两个因素:其使用的领域知识和MTL。首先,领域知识在大规模无标记数据上添加了图级预训练任务,这弥补了化学空间的缺乏,并为下游任务提供背景信息,有助于提升模型性能。其次,MTL通过利用任务之间的相关性和相关任务的信息,有效帮助低数据空间任务提升性能。
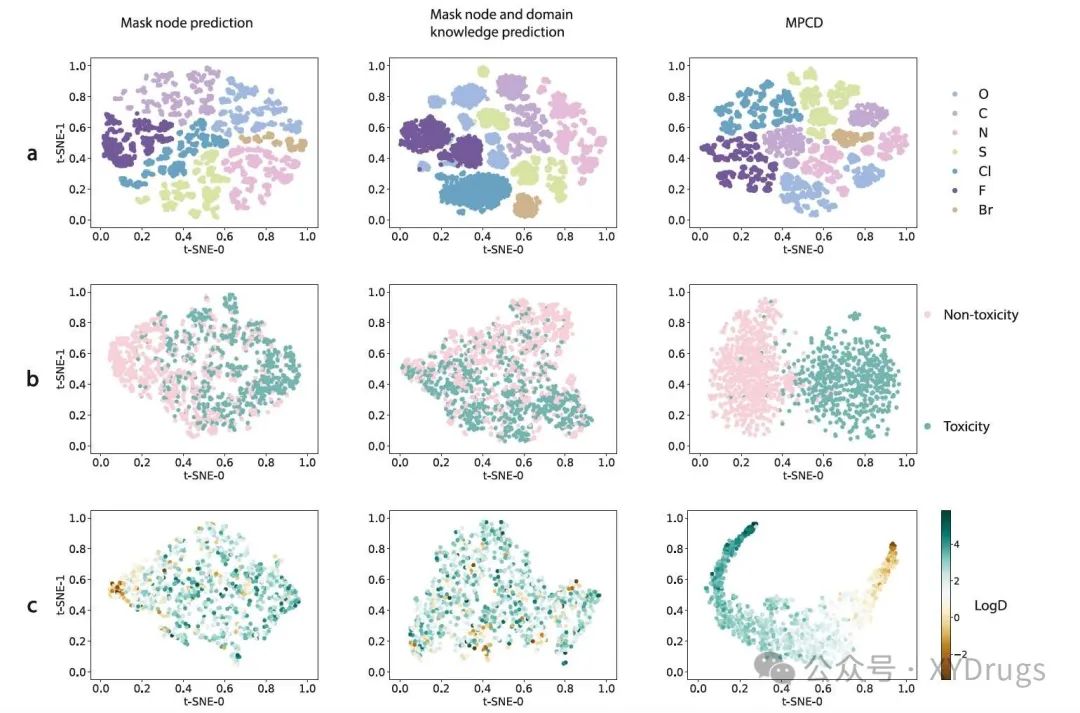
分子表征模型通常采用对原子或者分子表征的非线性映射或分子表征的ReLU映射来进行属性预测。理解原子和分子表征至关重要,因为这直接影响分子表征模型的预测能力。因此,我们进行了额外的研究,探讨在不同设置下原子和分子表征的分布。此研究旨在揭示MPCD表现优异的根本原因,并验证表征中知识的可靠性。
在原子表征方面,我们从hERG测试集中随机选择了1000个不同原子的嵌入用于可视化(图4a)。不同类型的原子聚类明显,使其易于区分,展示了原子类型在其表征中的有效区分。接下来,我们比较了不同设置下的原子嵌入,以展示知识的演变。在第一种设置(遮蔽节点预测)中,不同原子之间的边界清晰。相同类型的原子之间紧密聚类。在第二种设置(遮蔽节点和领域知识预测)中,与第一种设置下的嵌入相比,原子的分布发生了变化。第一次变化涉及到同类型的原子因功能变化而在不同中心聚集。第二次变化则是不同类型的原子因其相似的功能而聚集在一起。原子功能受局部结构和全局语义的影响。与第一种基于邻居聚合的设置不同,第二种设置结合了领域知识,将原子表征嵌入了有关分子的全局语义信息。在药物发现中,轻微的结构变化可能导致显著的属性变化,如活性悬崖。此外,不同的原子可以具有相似的功能,例如各种卤素元素容易发生氧化反应。因此,领域知识通过语义信息丰富了原子嵌入,使得功能不同的原子更易于区分,或者功能相似的原子更加相似。与第二种设置相比,MPCD专注于ADMET和物理化学属性,使得原子嵌入的分布更加集中,同时仍保留了对原子功能的关注。第三种设置下的原子嵌入表现出比第二种设置少的方差,比第一种设置多的方差。这表明,丰富了领域知识的原子嵌入与与ADMET和物理化学属性相关的嵌入差异较小,进一步说明领域知识如何缩小优化差距。
接下来,在分子表征方面,我们在hERG和LogD测试集上进行了分子嵌入(图4b和图4c)。具体而言,我们将上述三种设置应用于hERG和LogD测试集,并利用t-SNE可视化分子表征。结果表明,从遮蔽节点和领域知识表征中导出的分子嵌入与ADMET和物理化学属性值没有直接的线性相关性,表明领域知识预测提供了全面和系统的药物相似性信息,而不仅仅是拟合标签。此外,经过微调后,MPCD成功区分了心脏毒性和非心脏毒性分子的表征,并区分了LogD值与分子表征之间的相关性。这表明该系统能够学习具有不同属性的分子的独特特征。
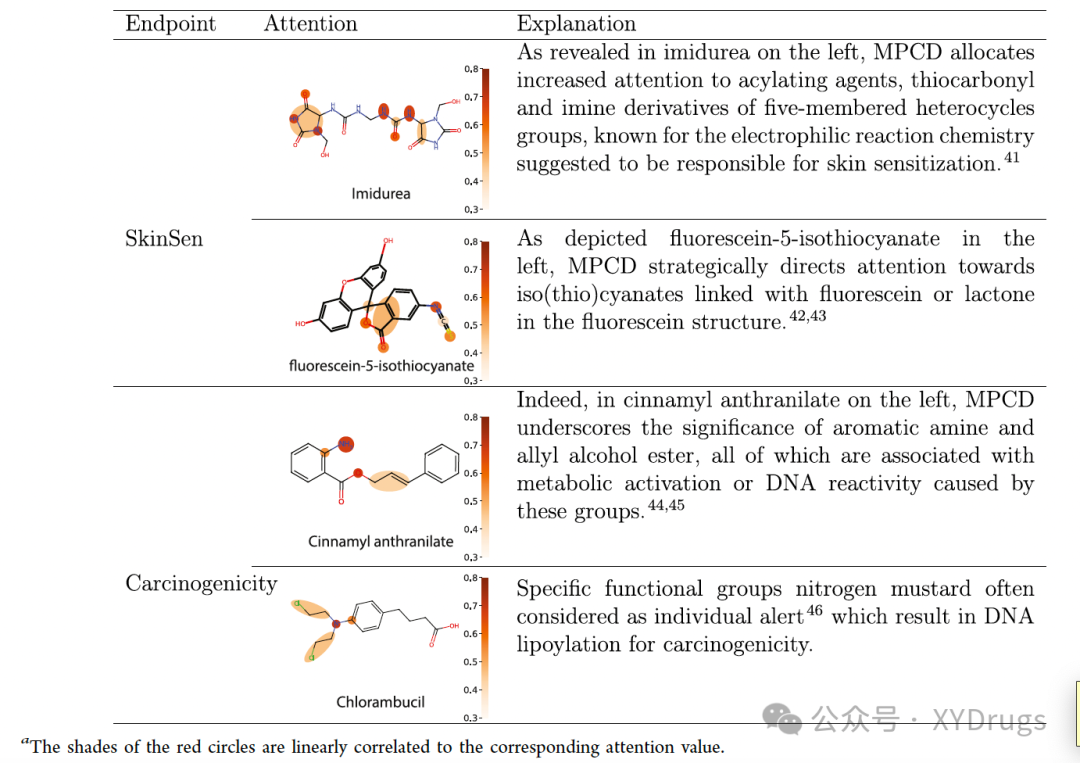
为了获得化学上合理的解释,分子属性预测结果需要易于理解。因此,我们接着探讨了注意力权重在属性预测中捕获的重要功能基团的能力。注意力权重捕获的功能基团显示了对应功能基团对分子属性的贡献,这为化学家判断预测值提供了辅助参考。为了不失一般性,我们使用了皮肤致敏(SkinSen)和致癌性作为示例,并突出了由注意力权重值定义的重要功能基团(见表1)。颜色突出显示了决定分子属性的功能基团。颜色越深,功能基团的重要性越高。注意力权重是模型框架图1a中的“Attention”,是一种可学习的权重,应用于分子的每个原子表征。不同的原子,如果注意力差异不超过0.02,则会聚合成一个功能基团。
结果表明,节点级注意力机制有效地引导模型集中注意力在显著影响ADMET属性的核心功能基团上。观察显示,功能基团的注意力与化学知识一致,展示了MPCD对类药物分子的强大学习能力和可解释性。此外,MPCD的可解释性对于化学家寻找可信的分子并潜在发现影响分子属性的新范式是有帮助的。我们的方法可以扩展到其他属性。只需取出图1a中的“Attention”,将其与原子对应,并根据规则聚合,就可以获得与分子属性相关的功能基团,然后探索其相关性。
本文介绍了MPCD,专为高数据量和低数据量场景下的分子属性预测设计,其性能优于现有模型。尤其是在低数据量场景下,当现有方法性能大幅下降时,MPCD依然能够展现出竞争力。该模型通过整合精心设计的领域知识预测和自适应多任务学习(MTL)技术,实现了卓越的性能。MPCD在预训练阶段引入领域知识,缓解了预训练与微调之间的优化目标差距,从而增强了模型的迁移能力。同时,自适应注意力机制结合MTL,将不同分子属性预测模型整合为一个统一的框架,从而高效预测多种类型的分子属性。
此外,MPCD的可视化分析表明,模型生成的原子、骨架和图级别的嵌入与现有专家知识高度一致,为化学家提供了重要的参考,并提升了模型的理解能力。同时,任务相关性分析揭示了任务之间的内在关系及其对模型效率的影响。最后,MPCD通过注意力权重识别出影响皮肤致敏性(SkinSen)和致癌性的功能基团,为化学家验证研究发现的可信度或识别新型警示结构提供了依据。
未来,研究团队计划将MPCD应用于专有和湿实验数据集,并与工业合作伙伴及学术研究团队展开合作。此外,还将探索更多的解释性方法,包括通过梯度分析评估特征敏感性,以及开发面向全局和局部的解释性技术。
参考资料
Yang, X.; Duan, Y.; Cheng, Z.; Li, K.; Liu, Y.; Zeng, X.; Cao, D. MPCD: A Multitask Graph Transformer for Molecular Property Prediction by Integrating Common and Domain Knowledge.Journal of Medicinal Chemistry 2024. DOI: 10.1021/acs.jmedchem.4c02193.
代码连接
https://github.com/XIXIYOUNG2018/MPCD
投稿人:杨喜喜
责任编辑:许燕红
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢