

阅读本文前请先对LLM、注意力机制以及Transformer有基本的了解。完整的源代码可在 GitHub 上获取:yalm(另一个语言模型,https://github.com/andrewkchan/yalm)。
(本文作者Andrew Chen是技术专家社区South Park Commons软件工程师,毕业于加州大学伯克利分校。本文由OneFlow编译发布,转载请联系授权。原文:
https://andrewkchan.dev/posts/yalm.html)
1
回顾:LLM架构与推理
几乎[2]每个主要的开源权重LLM都使用相同的架构[3](序列transformer模块),自GPT-2以来有一些细微的变化/创新:
分组查询注意力(以及多查询注意力)
基于混合专家的前馈网络
基于门控线性单元(GLU)而非多层感知器(MLP)的前馈网络
前馈网络的不同激活函数
不同的层归一化
旋转位置嵌入
1.1 推理概述
/* PSUEDOCODE */void generate(Model& model, std::string prompt, int steps) {std::vector<int> encoded = tokenizer.encode(prompt);InferenceState s(model);// 1. Prefill step: Forward the model on each prompt token, discarding// the output. This lets the model read the prompt and hydrates the KV// cache.for (int token : encoded) {model.forward(s, token);}// 2. Decode step: Forward the model repeatedly, generating 1 token at a time.for (int i = 0; i < steps; i++) {model.forward(s, encoded.back());int next_token = sampler.sample(s.logits);encoded.push_back(next_token);std::cout << tokenizer.decode_one(next_token) << std::flush;if (next_token == tokenizer.EOS) {break;}}}
/* PSUEDOCODE */// InferenceState is the minimum set of buffers needed to// hold state during the forward pass and exists to avoid// extra allocationsvoid Model::forward(InferenceState& s, int token) {// The embedding table maps token IDs to embedding vectors,// which are copied into a buffer of the inference states.x = copy_embedding(token, this->token_embedding_table);// Models consist of a sequence of transformer blocks which// mutate the inference state in orderfor (Block& b : this->blocks) {b->block(s);}// Usually there is a layer norm right before the final classifiers.x = layernorm(s.x, this->lm_head_prenorm_weights);// Typically we end with a linear transform from (dim) -> (vocab_size)s.logits = linear(s.x, this->lm_head_classifier_weights);}void Block::block(InferenceState& s) {s.x_resid = layernorm(s.x, this->att_prenorm_weights);// Multi-head attention typically includes:// 1. RoPE on input (element-wise mutation w/ sines/cosines)// 2. QKV matmuls and updating the KV cache// 3. Causal self-attention, softmax, and value mixing// 4. Projection back into the residual streams.x_resid = multi_head_attn(s.x_resid,this->wq,this->wk,this->wv,this->key_cache,this->value_cache);s.x += s.x_resid;s.x_resid = layernorm(s.x, this->ffn_prenorm_weights);// On modern architectures like Llama, this is a GLU feedforward// with 3 linear transforms, not a simple MLP:// -> w2(F.silu(w1(x)) * w3(x))// Some architectures also split the FFN into a mixture of experts.s.x_resid = ffn(s.x_resid, this->w1, this->w2, this->w3);s.x += s.x_resid;}
1.2 瓶颈与基准
每次我们生成一个词元时,都需要读取整个模型,而对每个权重仅执行少量的浮点运算。
现代CPU和GPU在浮点运算方面速度极快。关键指标是每秒浮点运算次数(FLOPs)与内存带宽的比率(FLOPs / byte)。例如,AMD Ryzen 7950X的这一比率约为40∶1,而英伟达RTX 4090的比率为82∶1。我服务器的AMD EPYC 7702P的这一比率没那么亮眼,但也较为可观,为10∶1。
EPYC 7702P的最大带宽 [4]:204.8GB / 秒
RTX 4090的最大带宽 [5]:1008GB / 秒
带有4096(4k)上下文窗口以及32位浮点数(FP32)键值缓存的Mistral - 7B - Instruct - v0.2 模型大小为 29516398592 字节
204.8×10⁹字节 / 秒 ÷29516398592字节 / 词元≈6.9 词元 / 秒(针对EPYC 7702P)
该模型无法装入RTX 4090的24GB显存中,所以我们跳过这部分计算。
带有4096(4k)上下文窗口以及16位浮点数(FP16)键值缓存的Mistral - 7B - Instruct - v0.2模型大小为15020875776字节
204.8×10⁹字节 / 秒 ÷15020875776字节 / 词元≈13.6 词元 / 秒(针对EPYC 7702P)
1008×10⁹字节 / 秒 ÷15020875776字节 / 词元≈67.1 词元 / 秒(针对 RTX 4090)

2
CPU上的推理
2.1 多线程
static void matmul(float* xout, float* x, float* w, int n, int d) {// W (d,n) @ x (n,) -> xout (d,)int i;for (i = 0; i < d; i++) {float val = 0.0f;for (int j = 0; j < n; j++) {val += w[i * n + j] * x[j];}xout[i] = val;}}

// F16C code technically operates on 16-bit unsigned short integerstypedef uint16_t f16_t;// matmul supporting float16 weights via the F16C extension, which allows// conversion into float32 values before calculations.static void matmul(float* xout, float* x, f16_t* w, int n, int d) {// W (d,n) @ x (n,) -> xout (d,)assert(n % 16 == 0);int i;for (i = 0; i < d; i++) {// Vectorized dot product of w[i][:] and x[:] where w is a packed float16 array.__m256 sumlo = _mm256_setzero_ps();__m256 sumhi = _mm256_setzero_ps();for (int j = 0; j < n; j+=16) {// Extract the next set of 16 float16 weights from `w` and store them// to two separate float32 vectors of width 8 (`wveclo_ps`, `wvechi_ps`)__m256i wvec = _mm256_loadu_si256((__m256i*)&w[i * n + j]);__m128i wveclo = _mm256_extractf128_si256(wvec, 0);__m128i wvechi = _mm256_extractf128_si256(wvec, 1);__m256 wveclo_ps = _mm256_cvtph_ps(wveclo);__m256 wvechi_ps = _mm256_cvtph_ps(wvechi);// Extract the next two float32 vectors of width 8 `xveclo`, `xvechi` from `x`__m256 xveclo = _mm256_loadu_ps(&x[j]);__m256 xvechi = _mm256_loadu_ps(&x[j + 8]);// Compute vectorized FMAs: sumlo += wveclo * xveclo, sumhi += wvechi * xvechisumlo = _mm256_fmadd_ps(wveclo_ps, xveclo, sumlo);sumhi = _mm256_fmadd_ps(wvechi_ps, xvechi, sumhi);}// Horizontally reduce width-8 float32 vectors sumlo, sumhi to a scalar.__m256 sum8 = _mm256_add_ps(sumlo, sumhi); // sum8[0:8] = sumlo[0:8] + sumhi[0:8]__m128 sum4 = _mm_add_ps( // sum4[0:4] = sum8[0:4] + sum8[4:8]_mm256_extractf128_ps(sum8, 0),_mm256_extractf128_ps(sum8, 1));__m128 sum1 = _mm_dp_ps(sum4, _mm_set1_ps(1.0f), 0xf1); // sum1[0] = dot(sum4, [1,1,1,1])xout[i] = _mm_cvtss_f32(sum1);}assert(false && "float16 not supported on this platform");}
3
GPU上的推理
每个线程接收与其他线程相同的函数参数,但可以创建自己的局部变量,并且被分配一个独立的threadIdx,可以用来确定它负责的任务。
线程被组织成块(block),每个块有一个独立的blockIdx和固定数量的线程(blockDim)。同一块中的线程可以通过共享内存高效地合作,而共享内存的访问速度比网格中的所有线程可能访问的全局内存要快。
在调用kernel时,通过三重尖括号<<< numBlocks, threadsPerBlock >>>来指定块数和每块的线程数,可以是int或dim3类型。
3.1 简单的CUDA移植
// mix self.w2(F.silu(self.w1(x)) * self.w3(x))// Note this is a feedforward with a GLU, not a simple MLP.matmul<<<c.hidden_dim, WARP_SIZE>>>(w1(), s.xb(), c.dim, c.hidden_dim, s.hb());matmul<<<c.hidden_dim, WARP_SIZE>>>(w3(), s.xb(), c.dim, c.hidden_dim, s.hb2());glu_gelu<<<(c.hidden_dim + MAX_THREADS_PER_BLOCK - 1)/MAX_THREADS_PER_BLOCK,MAX_THREADS_PER_BLOCK,>>>(s.hb(), s.hb2(), s.hb());matmul<<<c.dim, WARP_SIZE>>>(w2(), s.hb(), c.hidden_dim, c.dim, s.xb2());// ffn residual back into xadd_residuals<<<(c.dim + MAX_THREADS_PER_BLOCK - 1)/MAX_THREADS_PER_BLOCK,MAX_THREADS_PER_BLOCK>>>(s.x(), s.xb2(), c.dim, s.x());
// mix self.w2(F.silu(self.w1(x)) * self.w3(x))// Note this is a feedforward with a GLU, not a simple MLP.matmul(s.hb(), s.xb(), w1<T>(), c.dim, c.hidden_dim);matmul(s.hb2(), s.xb(), w3<T>(), c.dim, c.hidden_dim);for (int i = 0; i < c.hidden_dim; ++i) {s.hb()[i] = gelu(s.hb()[i]) * s.hb2()[i];}matmul(s.xb2(), s.hb(), w2<T>(), c.hidden_dim, c.dim);// residual connection back into xfor (int i = 0; i < c.dim; ++i) {s.x()[i] += s.xb2()[i];}
3.2 高效矩阵乘法
__global__void matmul(const float* A, const float* x, int n, int d, float* out) {// A (d,n) @ x (n,) -> out (d,)int i = blockIdx.x * blockDim.x + threadIdx.x;if (i >= d) return;float sum = 0.0;for (int j = 0; j < n; j++) {sum += A[n * i + j] * x[j];}out[i] = sum;}/* usage */int MAX_THREADS_PER_BLOCK = 1024;matmul<<<(d + MAX_THREADS_PER_BLOCK - 1)/MAX_THREADS_PER_BLOCK,MAX_THREADS_PER_BLOCK>>>(A, x, n, d, out);
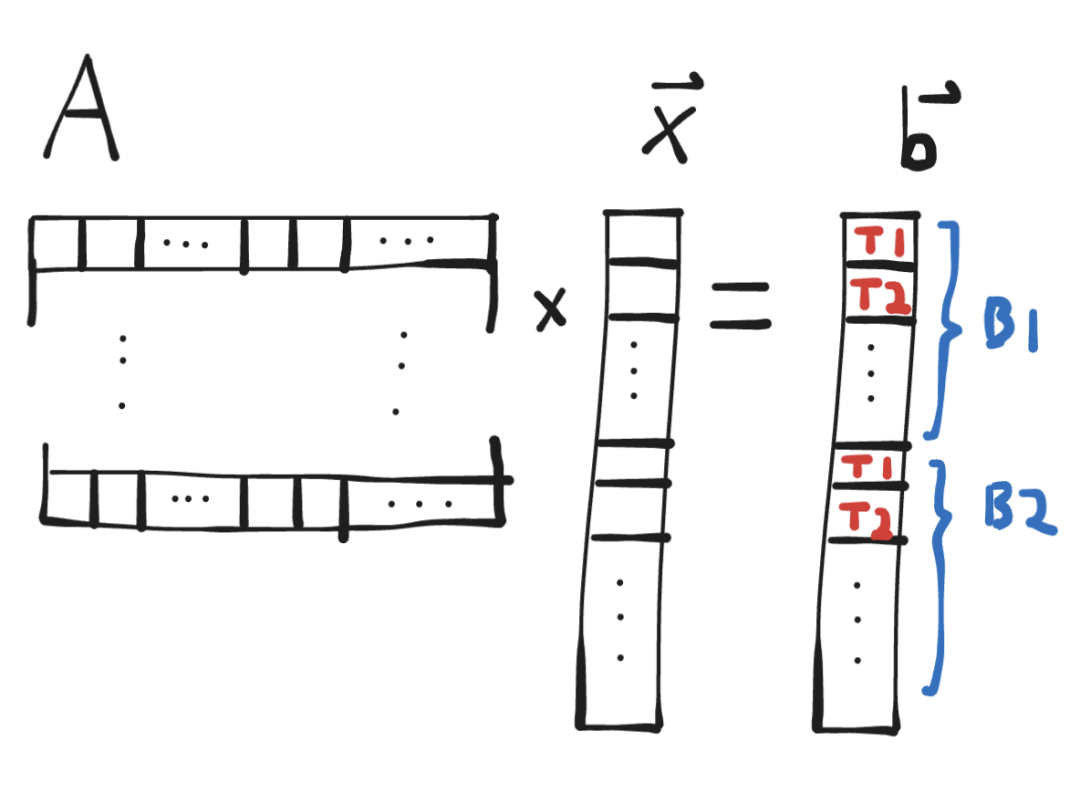
这种方法有一个很大的问题:它无法充分利用我们的CUDA核心。以Mistral-7B为例,其transformer的输入/输出维度为4096,因此,如果我们计算输出之前的最后一个matmul,我们将启动4096个线程。但是,RTX 4090可以同时支持16384个线程!这意味着许多核心将处于空闲状态,我们无法达到最大浮点运算能力(FLOPs/s)。
__device__inline float warp_reduce_sum(float val) {for (int offset = WARP_SIZE / 2; offset > 0; offset /= 2)val += __shfl_down_sync(0xffffffff, val, offset);return val;}__device__inline float matmul_row(const float* row, const float* x, int offset, int dim) {float sum = 0.0;for (int j = offset; j < dim; j += WARP_SIZE) {float v = row[j] * x[j];sum += v;}return warp_reduce_sum(sum);}__global__void matmul(const float* A, const float* x, int n, int d, float* out) {// A (d,n) @ x (n,) -> out (d,)// PRECOND: Blocks are 1-D and same size as warp.int i = blockIdx.x;if (i >= d) return;int offset = threadIdx.x;float rowSum = matmul_row(&A[n * i], x, offset, n);if (threadIdx.x == 0) {out[i] = rowSum;}}/* usage */int BLOCK_SIZE = WARP_SIZE;matmul<<<d, BLOCK_SIZE>>>(A, x, n, d, out);
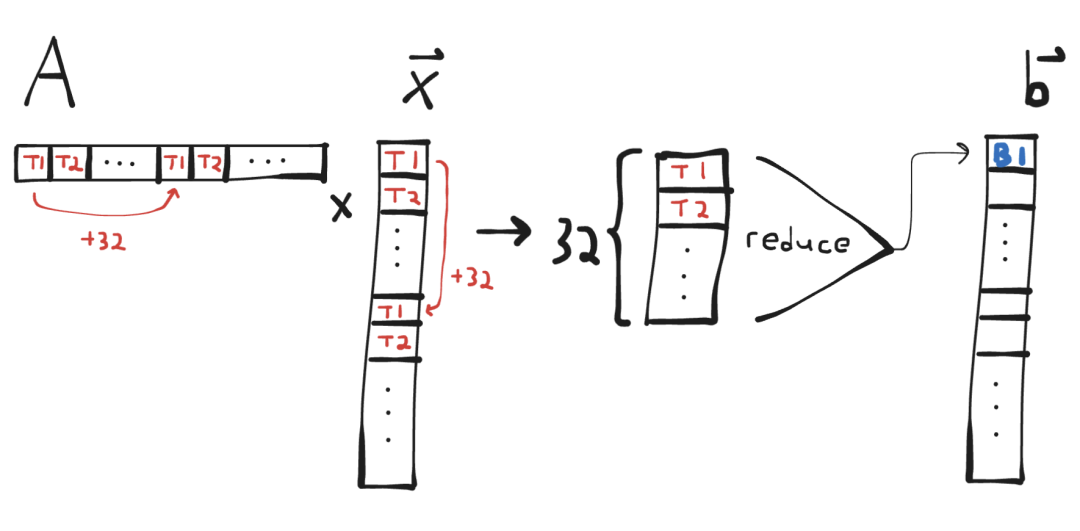
我们也可以将上述kernel扩展到支持多个线程束的块(最简单的方法是保持每行1个线程束)。我将把这个问题和为什么这样做是更好的处理方式留给读者作为一个练习。:)
3.3 融合和更高效的矩阵乘法
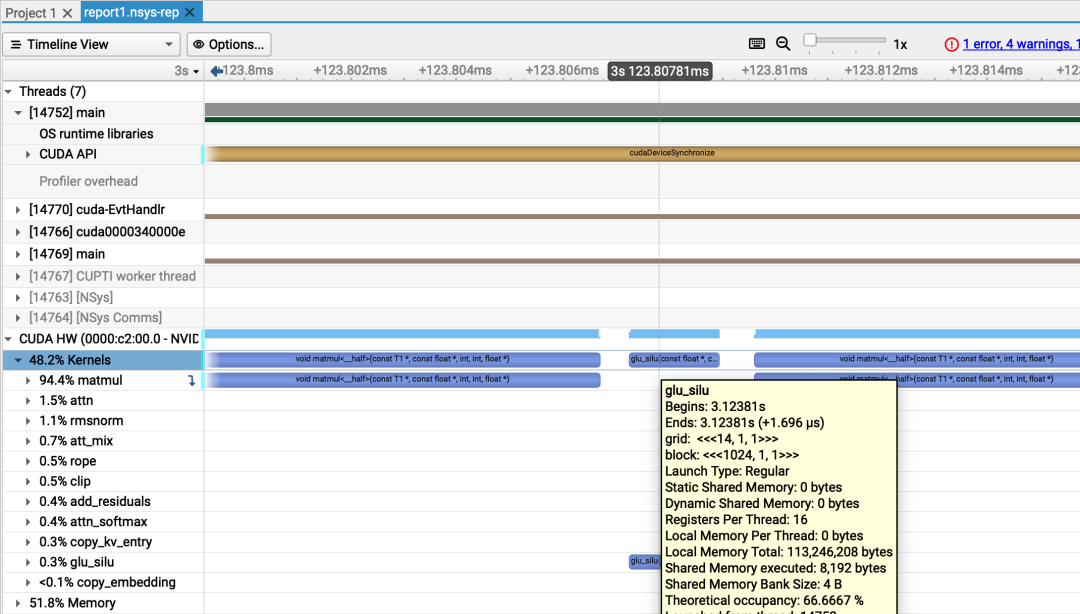
Section: Memory Workload Analysis--------------------------- ------------ ------------Metric Name Metric Unit Metric Value--------------------------- ------------ ------------Memory Throughput Gbyte/second 533.22Mem Busy % 24.82Max Bandwidth % 90.26L1/TEX Hit Rate % 65.94L2 Compression Success Rate % 0L2 Compression Ratio 0L2 Hit Rate % 2.03Mem Pipes Busy % 28.33--------------------------- ------------ ------------Section: Memory Workload Analysis Tables...----- --------------------------------------------------------------------------------------------------------------WRN The memory access pattern for stores from L1TEX to L2 is not optimal. The granularity of an L1TEX request toL2 is a 128 byte cache line. That is 4 consecutive 32-byte sectors per L2 request. However, this kernel onlyaccesses an average of 1.0 sectors out of the possible 4 sectors per cache line. Check the Source Counterssection for uncoalesced stores and try to minimize how many cache lines need to be accessed per memoryrequest.----- --------------------------------------------------------------------------------------------------------------...
__device__ inline float blocktranspose(float v, float def) {// Performs block-and-warp transpose operation:// For a block containing K warps where lane 0 contains val_k,// this function returns:// - For warp 0, lane K: val_k// - For all other warps and lanes: defint lane = threadIdx.x % warpSize;int warp = threadIdx.x / warpSize;// Will hold results of all warps.// Each lane of the warp accumulates across 1 head element at a time.// NOTE: Assumes warpSize is 32__shared__ float sm[32];if (lane == 0) sm[warp] = v;__syncthreads();return lane < blockDim.x / warpSize ? sm[lane] : def;}template <typename T>__global__void matmul_wide(const T* A, const float* x, int n, int d, float* out) {// A (d,n) @ x (n,) -> out (d,)// PRECOND: Block is 1-D and contains WPB warps.int i = (blockIdx.x * blockDim.x + threadIdx.x) / warpSize;if (i >= d) return;// Warp j computes sum for row at <blockIdx.x*WPB + j>// Lane 0 of each warp will hold resultint k = threadIdx.x % warpSize;float rowSum = matmul_row(&A[n * i], x, k, n);// Transpose values so lane k in warp 0 contains row at <blockIdx.x*WPB + k>// For WPB=32, this allows us to coalesce 32 float32 writes into a single 128-byte storerowSum = blocktranspose(rowSum, 1.0);if (threadIdx.x < blockDim.x / warpSize) {int block_start_i = blockIdx.x * blockDim.x / warpSize;out[block_start_i + k] = rowSum;}}
3.4 注意力与长上下文生成
dim到hidden_dim的矩阵乘法:每行有n_heads个点积,点积大小为head_dim,共有head_dim行
总共有n_heads * head_dim个点积,点积大小为head_dim
序列长度为seq_len的注意力机制:
总共有n_heads * seq_len个点积,点积大小为head_dim
序列长度为seq_len的注意力混合:
总共有n_heads * seq_len个乘加运算(对大小为head_dim的向量进行运算)
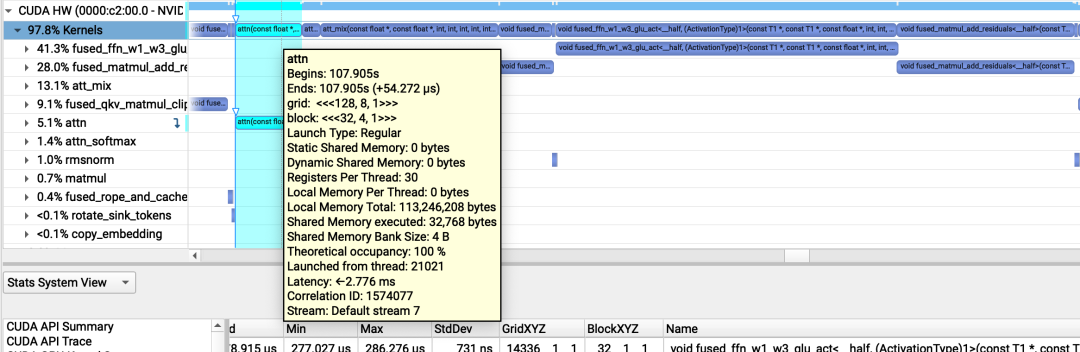
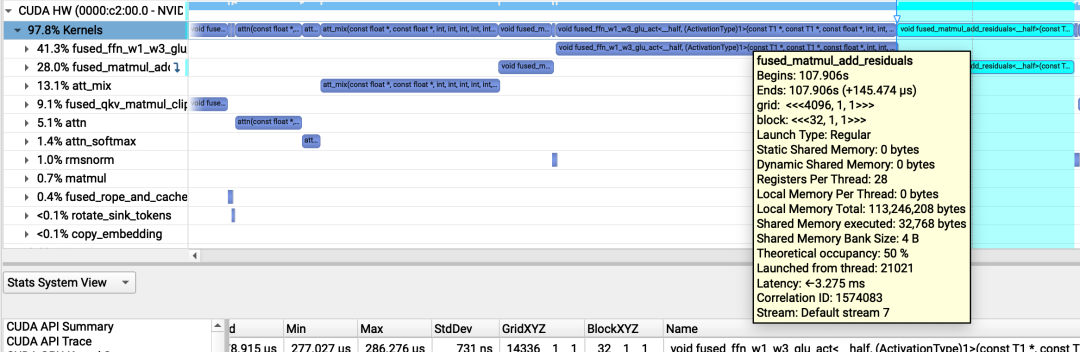
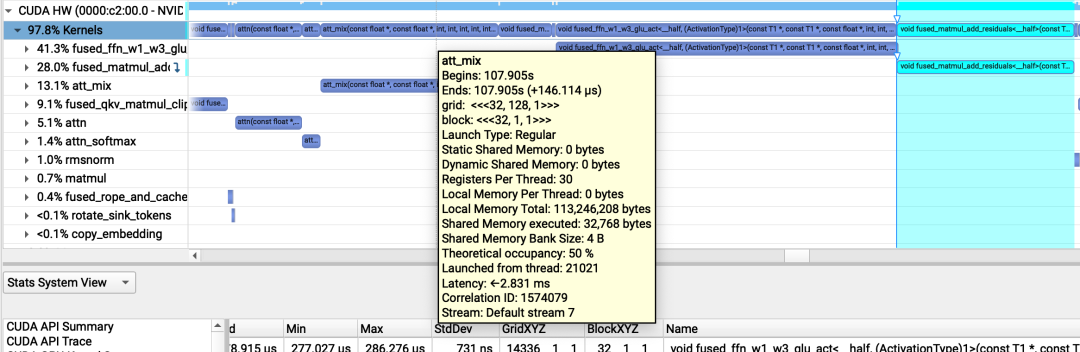
att_mix(const float *, const float *, int, int, int, int, int, float *) (32, 128, 1)x(32, 1, 1), Context 1, Stream 7, Device 0, CC 8.6Section: GPU Speed Of Light Throughput----------------------- ------------- ------------Metric Name Metric Unit Metric Value----------------------- ------------- ------------DRAM Frequency cycle/nsecond 6.27SM Frequency cycle/nsecond 1.33Elapsed Cycles cycle 5765045Memory Throughput % 8.81DRAM Throughput % 1.68Duration msecond 4.35L1/TEX Cache Throughput % 5.17L2 Cache Throughput % 8.81SM Active Cycles cycle 5685841.81Compute (SM) Throughput % 0.47----------------------- ------------- ------------WRN This kernel exhibits low compute throughput and memory bandwidth utilization relative to the peak performanceof this device. Achieved compute throughput and/or memory bandwidth below 60.0% of peak typically indicatelatency issues. Look at Scheduler Statistics and Warp State Statistics for potential reasons.
给定两个以行主序存储的张量:
att - 注意力分数,形状为 (n_heads, kv_len)
vb - 值向量,形状为 (max_seq_len, n_kv_heads, head_dim)
我们希望输出一个形状为 (n_heads, head_dim)的out张量,其中,out[q] = att[q, :] @ vb[:, q//G, :],其中 G = n_heads//n_kv_heads是分组查询注意力的组大小。
下面,我们假设KV缓存中的时间步数kv_len 等于 max_seq_len:
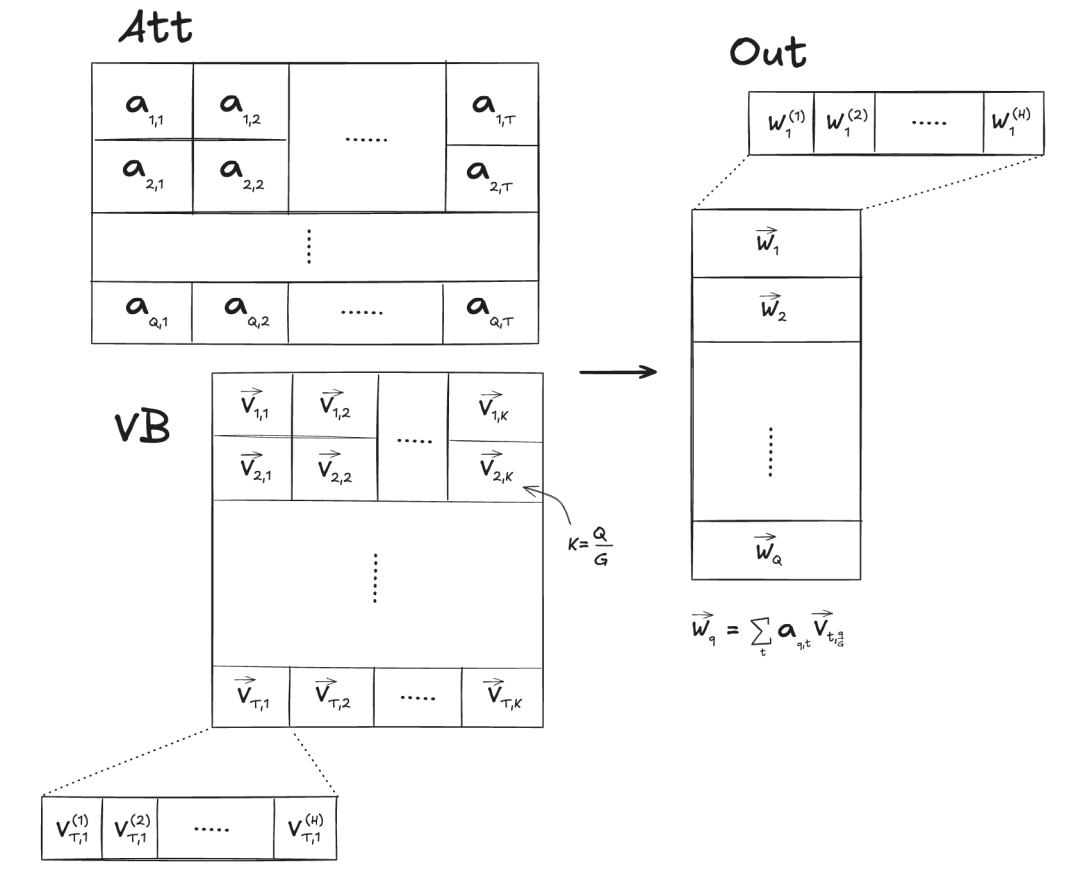
__device__inline float warp_reduce_sum(float val) {for (int offset = WARP_SIZE / 2; offset > 0; offset /= 2)val += __shfl_down_sync(0xffffffff, val, offset);return val;}__global__void att_mix(const float* vb, // (max_seq_len, n_kv_heads, head_dim)const float* att, // (n_heads, kv_len)int head_dim,int n_heads,int n_kv_heads,int seq_len,int max_seq_len,float* out // (n_heads, head_dim)) {// PRECOND: blocks are 1-D and blockDim.x == WARP_SIZEint h = blockIdx.x;int group_size = n_heads / n_kv_heads;int g = h / group_size;int i = blockIdx.y;int offset = threadIdx.x;int kv_stride = n_kv_heads * head_dim;const float* atth = att + max_seq_len * h;const float* vh = vb + head_dim * g;float* outh = out + head_dim * h;float sum = 0.0;for (int t = offset; t < seq_len; t += WARP_SIZE) {sum += vh[kv_stride * t + i] * atth[t];}sum = warp_reduce_sum(sum);if (offset == 0) outh[i] = sum;}/* usage */dim3 tpb;tpb.x = WARP_SIZE;dim3 blocks;blocks.x = n_heads;blocks.y = head_dim;att_mix<<<blocks, tpb>>>(vb, att,head_dim, n_heads, n_kv_heads,seq_len, max_seq_len, out);
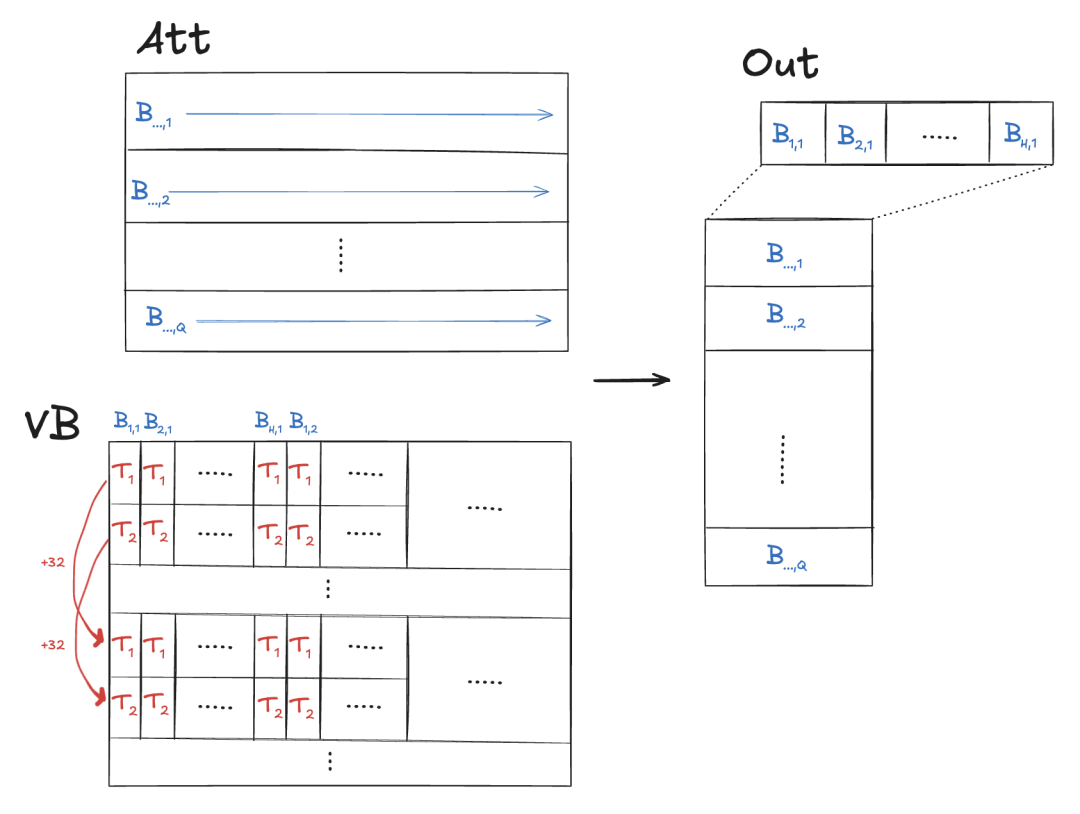
多个块写入单个输出元素out[h, i]。
将序列划分为每个块处理的连续时间块。这可以使用网格的y维度来完成。然而,我们仍然希望x维度对应于注意力头。
块应该处理多个输出元素。每个块1个线程束。i由线程束ID确定。这允许线程束合并加载。
线程使用atomicAdd将结果累加到out[h, i]。
__global__void att_mix(const float* vb, // (max_seq_len, n_kv_heads, head_dim)const float* att, // (n_heads, kv_len)int head_dim,int n_heads,int n_kv_heads,int seq_len,int max_seq_len,float* out // (n_heads, head_dim)) {// PRECOND: blocks are 1-D and `out` has been zeroedint h = blockIdx.x;int group_size = n_heads / n_kv_heads;int g = h / group_size;int kv_stride = n_kv_heads * head_dim;const float* atth = att + max_seq_len * h;const float* vh = vb + head_dim * g;float* outh = out + head_dim * h;int t_per_thread = seq_len / gridDim.y;int t_start = blockIdx.y * t_per_thread;for (int i = threadIdx.x; i < head_dim; i += blockDim.x) {float sum = 0.0;for (int t = t_start; t < t_start + t_per_thread; t++) {sum += vh[kv_stride * t + i] * atth[t];}atomicAdd(&outh[i], sum);}}int max_t_per_thread = 256;dim3 tpb;tpb.x = warp_size;dim3 blocks;blocks.x = c.n_heads;blocks.y = (kv_len + max_t_per_thread - 1) / max_t_per_thread;cudaMemset(s.xb2(), 0, c.n_heads * c.head_dim * sizeof(float));att_mix<<<blocks, tpb>>>(vb, s.att(),c.head_dim, c.n_heads, c.n_kv_heads,kv_len, c.max_seq_len, s.xb2());
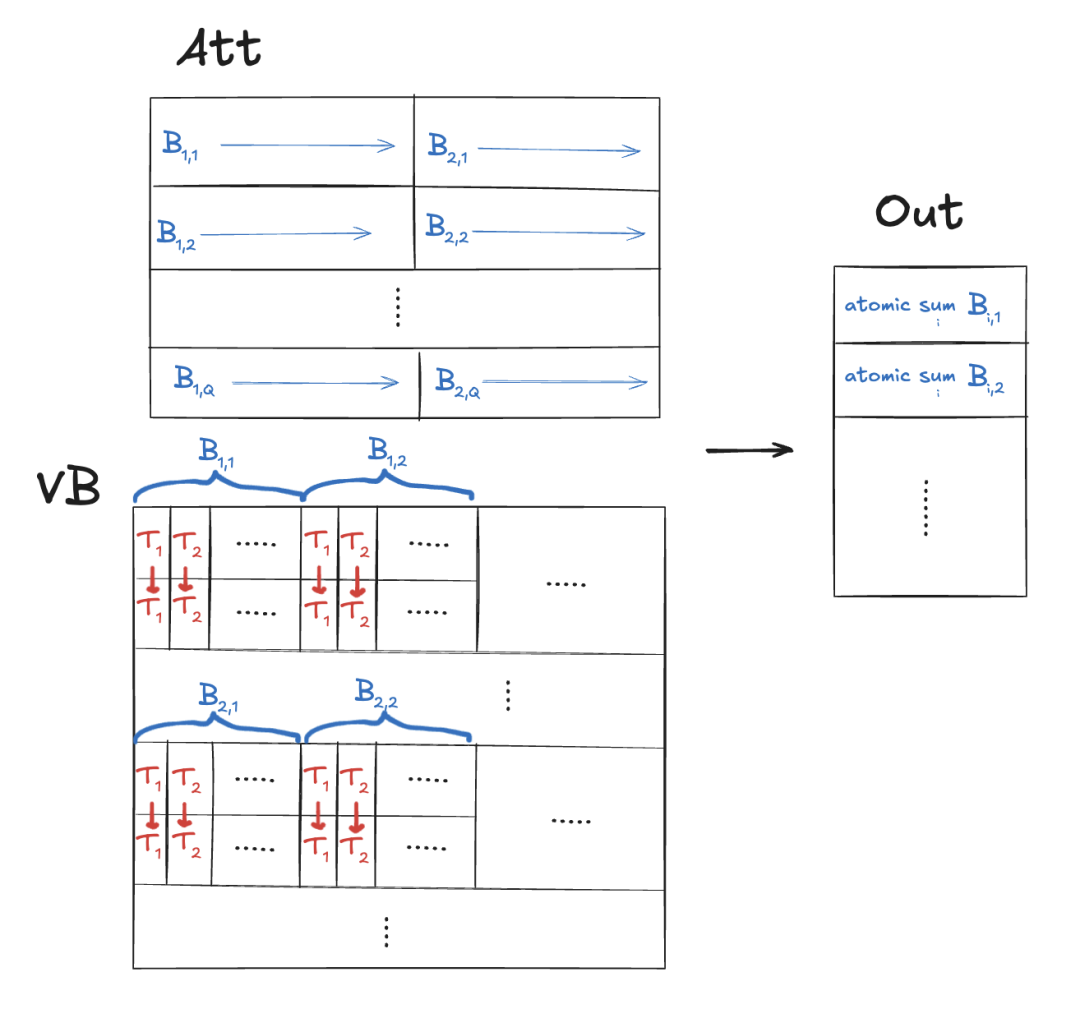
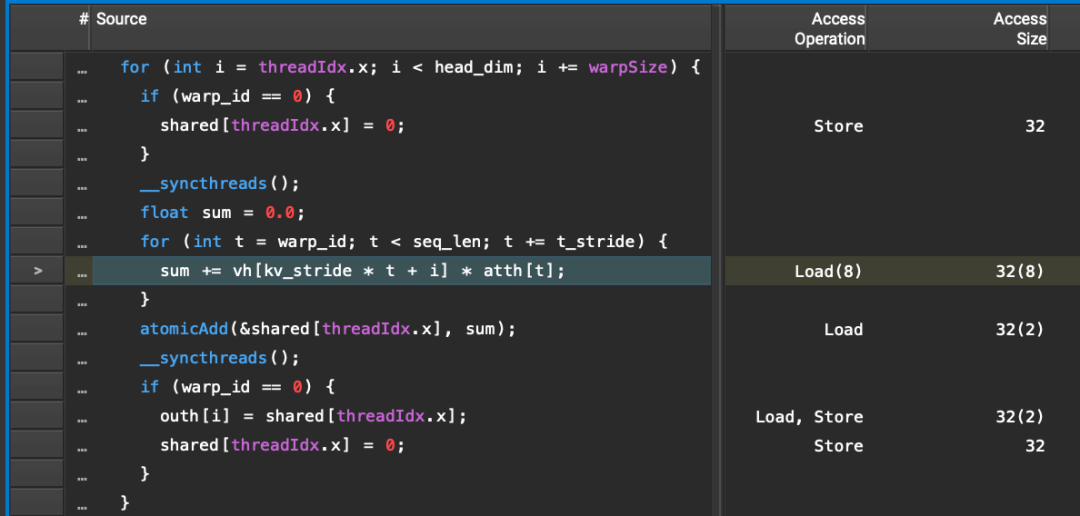
__global__void att_mix(const float* vb, // (max_seq_len, n_kv_heads, head_dim)const float* att, // (n_heads, kv_len)int head_dim,int n_heads,int n_kv_heads,int seq_len,int max_seq_len,float* out // (n_heads, head_dim)) {// PRECOND: blocks are 2-D (warp_size, t_stride)int h = blockIdx.x;int group_size = n_heads / n_kv_heads;int g = h / group_size;int kv_stride = n_kv_heads * head_dim;const float* atth = att + max_seq_len * h;const float* vh = vb + head_dim * g;float* outh = out + head_dim * h;int warp_id = threadIdx.y;int t_stride = blockDim.y;// Capacity 32 since there can be at most 32 warps in a block.__shared__ float shared[32];for (int i = threadIdx.x; i < head_dim; i += warpSize) {if (warp_id == 0) {shared[threadIdx.x] = 0;}__syncthreads();float sum = 0.0;for (int t = warp_id; t < seq_len; t += t_stride) {sum += vh[kv_stride * t + i] * atth[t];}atomicAdd(&shared[threadIdx.x], sum);__syncthreads();if (warp_id == 0) {outh[i] = shared[threadIdx.x];shared[threadIdx.x] = 0;}}}dim3 tpb;tpb.x = warp_size;tpb.y = min(kv_len, max_threads_per_block / warp_size);dim3 blocks;blocks.x = c.n_heads;att_mix<<<blocks, tpb>>>(vb, s.att(),c.head_dim, c.n_heads, c.n_kv_heads,kv_len, c.max_seq_len, s.xb2());
3.5 KV量化和编译器陷阱
在我们之前的基准测试设置中(§1.2),llama.cpp和calm实际上使用了FP16 KV缓存条目(因为这是它们的默认设置),我们也假设相同的设置来计算速度。
将KV缓存条目从FP32量化到FP16不会带来与量化权重相同的巨大收益,因为KV缓存占总内存的比例较小。但是,我们仍然期待会有一定的收益,因为每次前向传递的总内存读取量将从15.5 GB减少到15.0 GB。这种效果应该在长上下文和注意力kernel中最为明显,因为KV缓存只在注意力中使用。
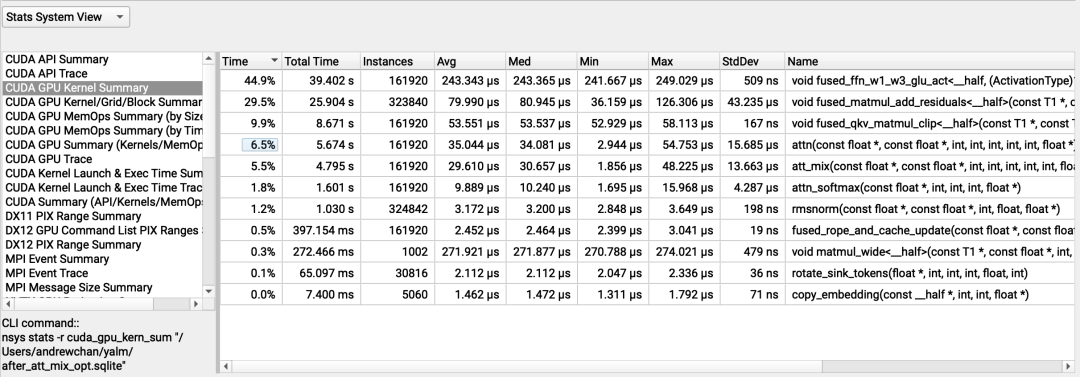
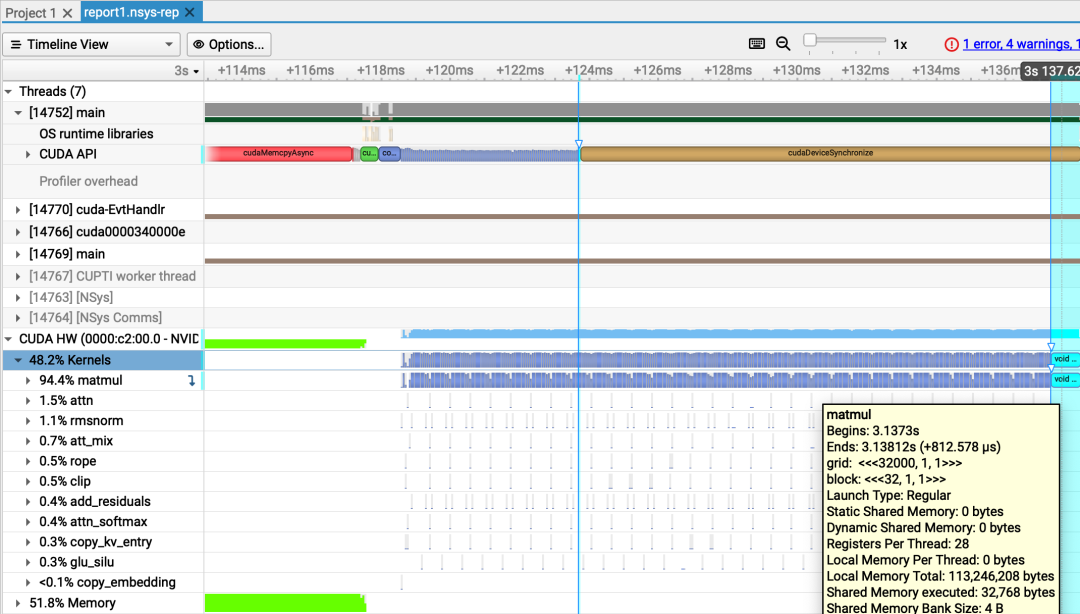
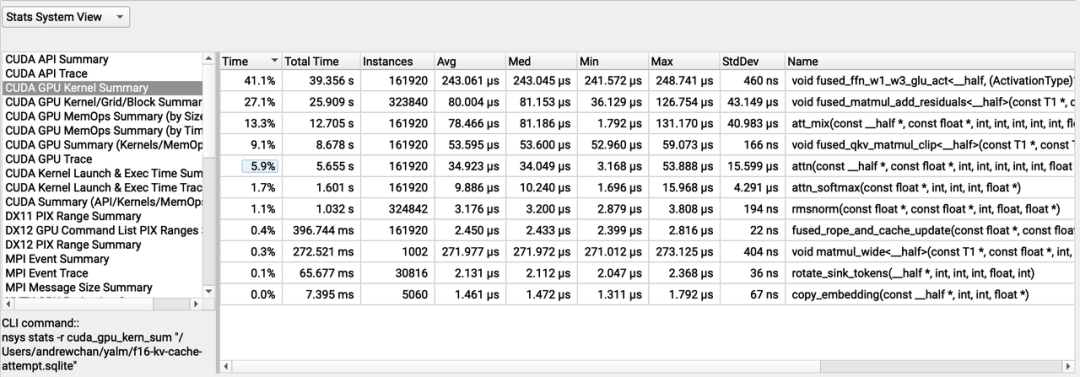 nsys分析:FP16 KV缓存的长上下文生成(原始补丁)
nsys分析:FP16 KV缓存的长上下文生成(原始补丁)float sum = 0.0;for (int t = warp_id; t < seq_len; t += t_stride) {sum += vh[kv_stride * t + i] * atth[t];}// atomicAdd `sum` when we're done
float sum = 0.0;for (int t = warp_id; t < seq_len; t += t_stride) {sum += __half2float(vh[kv_stride * t + i]) * atth[t];}// atomicAdd `sum` when we're done
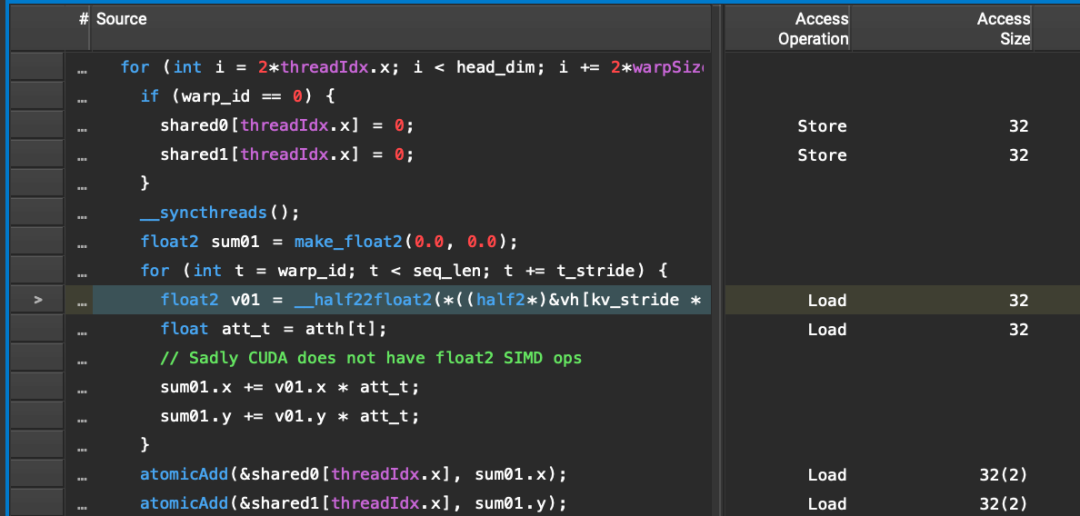
float2 sum01 = make_float2(0.0, 0.0);for (int t = warp_id; t < seq_len; t += t_stride) {float2 v01 = __half22float2(*((half2*)&vh[kv_stride * t + i]));float att_t = atth[t];// Sadly CUDA does not have float2 SIMD opssum01.x += v01.x * att_t;sum01.y += v01.y * att_t;}// atomicAdd both `sum01` lanes when we're done
float2 sum01 = make_float2(0.0, 0.0);constexpr int UNROLL = 16;half2 v01_0; float att_0;half2 v01_1; float att_1;half2 v01_2; float att_2;/* ... SNIP ... */half2 v01_15; float att_15;int t = warp_id;for (int ctr = 0; ctr < seq_len / t_stride; t += t_stride, ctr++) {int ctr_mod = ctr % UNROLL;if (ctr_mod == 0) {// prefetch every UNROLL iterationsv01_##j = *((half2*)&vh[kv_stride * (t + j*t_stride) + i]); \att_##j = atth[t + j*t_stride];PREFETCH(0)PREFETCH(1)PREFETCH(2)/* ... SNIP ... */PREFETCH(15)float2 v01;float att_t;switch (ctr_mod) {case j: v01 = __half22float2(v01_##j); att_t = att_##j; break;CASE(0)CASE(1)CASE(2)/* ... SNIP ... */CASE(15)sum01.x += v01.x * att_t;sum01.y += v01.y * att_t;}// Handle any loop remainder that can't be unrolledfor (; t < seq_len; t += t_stride) {float2 v01 = __half22float2(*((half2*)&vh[kv_stride * t + i]));float att_t = atth[t];sum01.x += v01.x * att_t;sum01.y += v01.y * att_t;}// atomicAdd both `sum01` lanes when we're done
4
下一步计划
在CPU上使用多线程和向量化
在GPU后端中使用矩阵乘法线程束归约、合并、kernel融合和更好的注意力机制
对于两个后端,权重和KV缓存量化
附录
import timefrom transformers import AutoModelForCausalLM, AutoTokenizerimport torchmistral_models_path = "../Mistral-7B-Instruct-v0.2"tokenizer = AutoTokenizer.from_pretrained(mistral_models_path)model = AutoModelForCausalLM.from_pretrained(mistral_models_path, torch_dtype=torch.float16)model.to("cuda")# short promptmodel_inputs = tokenizer(["Q: What is the meaning of life?"], return_tensors="pt").to("cuda")# do a warmup inferencegenerated_ids = model.generate(**model_inputs, max_new_tokens=1, do_sample=True)[0].tolist()# benchmarkstart_time = time.time()generated_ids = model.generate(**model_inputs, max_new_tokens=1000, do_sample=True)[0].tolist()# decode with mistral tokenizerresult = tokenizer.decode(generated_ids)end_time = time.time()elapsed_s = end_time - start_timeprint(result)num_prompt_tokens = model_inputs["input_ids"].shape[-1]num_generated_tokens = len(generated_ids) - num_prompt_tokensprint(f"Generation stats:\n" +f" prompt: {num_prompt_tokens} tokens\n" +f" generated: {num_generated_tokens} tokens\n" +f" throughput: {num_generated_tokens/elapsed_s}tok/s\n" +f" latency: {elapsed_s/num_generated_tokens}s/tok\n" +f" total: {elapsed_s}s\n")
尤其是当推理计算成为AI模型扩展的新维度时,模型越来越多地本地部署到边缘设备。
还有像 Mamba (https://arxiv.org/abs/2312.00752) 这样的状态空间模型,它们声称比Transformer更高效,可扩展到长序列,但它们似乎在低功耗ML和非离散数据域(如音频/视频)(https://www.cartesia.ai/)等细分市场之外并没有取得太大成功。
新的基础模型明确指出它们使用“标准架构”,附加值是训练。这导致了一些误解,例如参见 https://blog.eleuther.ai/nyt-yi-34b-response/#how-all-llms-are-similar
参见官方数据表(https://www.amd.com/content/dam/amd/en/documents/products/epyc/amd-epyc-7002-series-datasheet.pdf)。
参见维基百科(https://en.wikipedia.org/wiki/GeForce_40_series#Desktop)。
不幸的是,我无法测试calm CPU,因为我的机器不支持编译所需的扩展。
线程数量已调整。
请参阅附录(https://andrewkchan.dev/posts/yalm.html#appendix)中的基准代码。出于某种原因,这是所有代码中方差最大的。显示的结果为3次运行中的最佳结果。
更好的解决方案可能是使用流水线指令进行滚动预取。有关更多信息,请参阅上面链接的NVIDIA博客文章。
这通常在训练期间完成,其中我们必须保留大量激活,以便在所有层中进行梯度计算。对于单批次推理,它的好处较少,尤其是因为我们可以在层之间重用张量。

即刻体验DeepSeek-V2.5-1210
siliconflow.cn/zh-cn/siliconcloud
扫码加入用户交流群

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢